Command Palette
Search for a command to run...
Large Language Model Inference를 위한 Fast NF4 Dequantization Kernels
Large Language Model Inference를 위한 Fast NF4 Dequantization Kernels
Xiangbo Qi Chaoyi Jiang Murali Annavaram
초록
Large language models (LLMs)의 규모가 단일 GPU 장치의 메모리 용량을 초과함에 따라, 실질적인 배포를 위한 양자화(quantization) 기술이 필수적으로 요구되고 있습니다. NF4(4-bit NormalFloat) 양자화를 사용하면 메모리 사용량을 4배 절감할 수 있지만, 현재의 NVIDIA GPU(예: Ampere A100)에서 추론을 수행할 때 FP16 형식으로 다시 복구하는 고비용의 역양자화(dequantization) 과정이 필요하며, 이는 심각한 성능 병목 현상을 야기합니다.본 논문에서는 기존 생태계와의 완전한 호환성을 유지하면서, 원칙적인 메모리 계층 구조(memory hierarchy) 활용을 통해 이러한 문제를 해결하는 경량 공유 메모리(shared memory) 최적화 기법을 제안합니다. 본 연구에서는 오픈 소스인 BitsAndBytes 구현체와 비교 분석을 수행하였으며, 그 결과 세 가지 모델(Gemma 27B, Qwen3 32B, Llama3.3 70B) 전반에서 2.02.2배의 커널(kernel) 속도 향상을 달성했습니다. 또한, global memory 액세스 대비 1215배 빠른 shared memory의 지연 시간(latency) 이점을 활용하여 최대 1.54배의 end-to-end 성능 개선을 이루어냈습니다.본 최적화 기술은 인덱싱 로직(indexing logic)을 단순화하여 명령어 수(instruction counts)를 줄이는 동시에, 스레드 블록(thread block)당 단 64바이트의 shared memory만을 사용하여, 경량 최적화만으로도 최소한의 엔지니어링 노력으로 상당한 성능 향상을 이끌어낼 수 있음을 입증했습니다. 본 연구는 HuggingFace 생태계를 위한 plug-and-play 솔루션을 제공함으로써, 기존 GPU 인프라에서도 고급 모델에 대한 접근성을 대중화하는 데 기여합니다.
One-sentence Summary
By utilizing a lightweight shared memory optimization to replace expensive global memory access, this method achieves up to 2.2x kernel speedup and 1.54x end-to-end improvement across the Gemma 27B, Qwen3 32B, and Llama3.3 70B models while maintaining full compatibility with the HuggingFace ecosystem.
Key Contributions
- The paper introduces a lightweight shared memory optimization that exploits the memory hierarchy of the Ampere architecture to address dequantization bottlenecks in NF4 quantized models.
- This method transforms redundant per-thread global memory accesses into efficient per-block loading, reducing lookup table traffic by 64x per thread block and simplifying indexing logic to reduce instruction counts by 71%.
- Experimental evaluations on Gemma 27B, Qwen3 32B, and Llama3.3 70B demonstrate 2.0 to 2.2x kernel speedups and up to 1.54x end-to-end performance improvements while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Introduction
As large language models grow beyond the memory capacity of single GPUs, NF4 quantization has become essential for reducing memory footprints by 4x. However, because current NVIDIA Ampere architectures lack native 4-bit compute support, weights must be dequantized to FP16 during every matrix multiplication. This process creates a major performance bottleneck, with dequantization accounting for up to 40% of end-to-end latency due to redundant and expensive global memory accesses. The authors leverage a lightweight shared memory optimization to address this inefficiency by transforming per-thread global memory loads into efficient per-block loads. This approach exploits the significant latency advantage of on-chip memory to achieve a 2.0 to 2.2x kernel speedup while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Experiment
The evaluation uses a single NVIDIA A100 GPU to test optimized NF4 dequantization kernels against baseline implementations across three models: Gemma 27B, Qwen3 32B, and Llama3.3 70B. The experiments validate that the original dequantization process creates a significant bottleneck due to high memory overhead and warp divergence caused by complex tree-based decoding. Results demonstrate that the shared memory optimization consistently accelerates kernel execution, leading to substantial end-to-end latency and throughput improvements that are particularly pronounced in larger models.
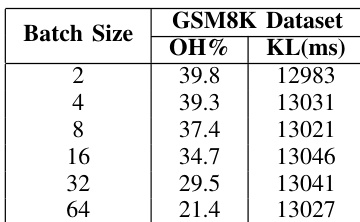
The authors analyze the dequantization overhead and kernel latency for the Qwen3-32B model using the GSM8K dataset. The results show that dequantization remains a significant portion of total inference time across various batch sizes. Dequantization overhead percentage decreases as the batch size increases Kernel latency remains relatively consistent regardless of the batch size The dequantization process represents a substantial bottleneck in end-to-end inference
The authors evaluate the kernel-level speedup of their optimized NF4 dequantization implementation across different model architectures and batch sizes. Results show that the optimization provides consistent performance gains regardless of the specific model or workload scale. The optimization achieves a consistent speedup across all tested models and batch sizes. Larger models and different batch configurations all experience similar levels of kernel-level improvement. The performance gains remain stable across varying batch sizes from small to large workloads.
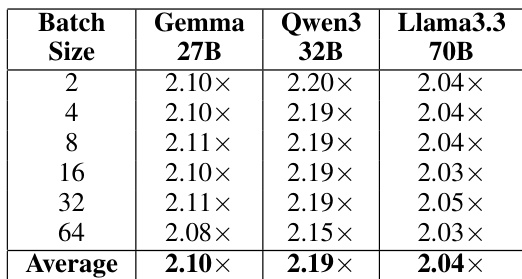
The authors evaluate dequantization overhead and the effectiveness of an optimized NF4 implementation using the Qwen3-32B model and various architectures. While dequantization is identified as a significant bottleneck in end-to-end inference, the optimized kernel provides consistent performance gains across different models and batch sizes. These results demonstrate that the optimization maintains stable speedups regardless of the specific workload scale or model architecture.