Command Palette
Search for a command to run...
근미래 정책 최적화 (Near-Future Policy Optimization)
근미래 정책 최적화 (Near-Future Policy Optimization)
Chuanyu Qin Chenxu Yang Qingyi Si Naibin Gu Dingyu Yao Zheng Lin Peng Fu Nan Duan Jiaqi Wang
초록
검증 가능한 보상을 활용한 강화학습(Reinforcement learning with verifiable rewards, RLVR)은 이제 핵심적인 사후 학습(post-training) 레시피로 자리 잡았습니다. 온폴리시(on-policy) 탐색 과정에 적절한 오프폴리시(off-policy) 궤적(trajectories)을 도입하면 RLVR의 수렴을 가속화하고 성능의 한계치(performance ceiling)를 높일 수 있지만, 이러한 궤적의 소스를 찾는 것이 여전히 핵심 과제로 남아 있습니다. 기존의 혼합 폴리시(mixed-policy) 방법론들은 외부 teacher로부터 궤적을 가져오거나(고품질이지만 분포가 멀음), 과거의 학습 궤적을 재현(distribution이 가깝지만 품질이 제한적임)하는 방식을 취합니다. 그러나 이 두 방식 모두 유효 학습 신호 S=Q/V를 극대화하는 데 필요한 '충분히 강하고(higher Q, 더 많은 새로운 지식 습득)' 그리고 '충분히 가까운(lower V, 더 용이한 흡수)' 조건을 동시에 만족시키지 못합니다.본 논문에서는 정책(policy) 자신의 '가까운 미래(near-future)'로부터 학습하는 단순한 혼합 폴리시 체계인 Near-Future Policy Optimization (NPO)를 제안합니다. 동일한 학습 과정의 이후 체크포인트(later checkpoint)는 현재의 policy보다 강력하면서도 외부 소스보다 훨씬 가까운 보조 궤적의 자연스러운 소스가 되며, 이를 통해 궤적의 품질과 분산 비용(variance cost) 사이의 균형을 직접적으로 조절할 수 있습니다. 저희는 초기 단계의 부트스트래핑(early-stage bootstrapping)과 후기 단계의 정체기 돌파(late-stage plateau breakthrough)라는 두 가지 수동 개입을 통해 NPO를 검증하였습니다. 나아가, 온라인 학습 신호로부터 개입을 자동으로 트리거하고 S를 극대화하는 가이드 체크포인트를 선택하는 적응형 변형 모델인 AutoNPO를 제안합니다. GRPO를 적용한 Qwen3-VL-8B-Instruct 모델 실험 결과, NPO는 평균 성능을 57.88에서 62.84로 향상시켰으며, AutoNPO는 이를 63.15까지 끌어올려 수렴을 가속화하는 동시에 최종 성능의 한계치를 높였습니다.
One-sentence Summary
To accelerate reinforcement learning with verifiable rewards, researchers propose Near-Future Policy Optimization (NPO), a mixed-policy scheme that maximizes the effective learning signal by utilizing a model's own later checkpoints as auxiliary trajectories to balance trajectory quality against variance cost.
Key Contributions
- The paper introduces Near-Future Policy Optimization (NPO), a mixed-policy scheme that utilizes trajectories from a later checkpoint in the same training run to guide the current policy. This approach provides auxiliary trajectories that are stronger than historical replay while remaining closer to the current distribution than external teacher models, effectively balancing trajectory quality against variance.
- This work presents AutoNPO, an adaptive variant that automates the timing and selection of guidance by monitoring online training signals such as reward stagnation and entropy decline. The framework automatically triggers interventions and selects the specific guide checkpoint that maximizes an empirical estimate of the effective learning signal.
- Experimental results demonstrate the effectiveness of NPO through successful manual interventions in early-stage bootstrapping and late-stage plateau breakthrough scenarios. The method shows the ability to bridge mixed-policy RLVR and self-taught approaches by using optimization time as privileged information to improve convergence and performance.
Introduction
Reinforcement learning with verifiable rewards (RLVR) is a critical post-training method for enhancing reasoning capabilities in large language models. While pure on-policy exploration is standard, it often suffers from sparse correct trajectories in early training or hits performance plateaus in later stages. Existing mixed-policy approaches attempt to solve this by either using external teachers, which introduce high distributional variance, or replaying past trajectories, which are limited by the quality of older checkpoints. The authors leverage a temporal approach called Near-Future Policy Optimization (NPO) to bridge this gap. By using a later checkpoint from the same training run as a source of auxiliary trajectories, NPO provides a learning signal that is both stronger than the current policy and closer in distribution than external models. This effectively balances signal quality against variance cost, allowing for accelerated convergence and higher performance ceilings.
Method
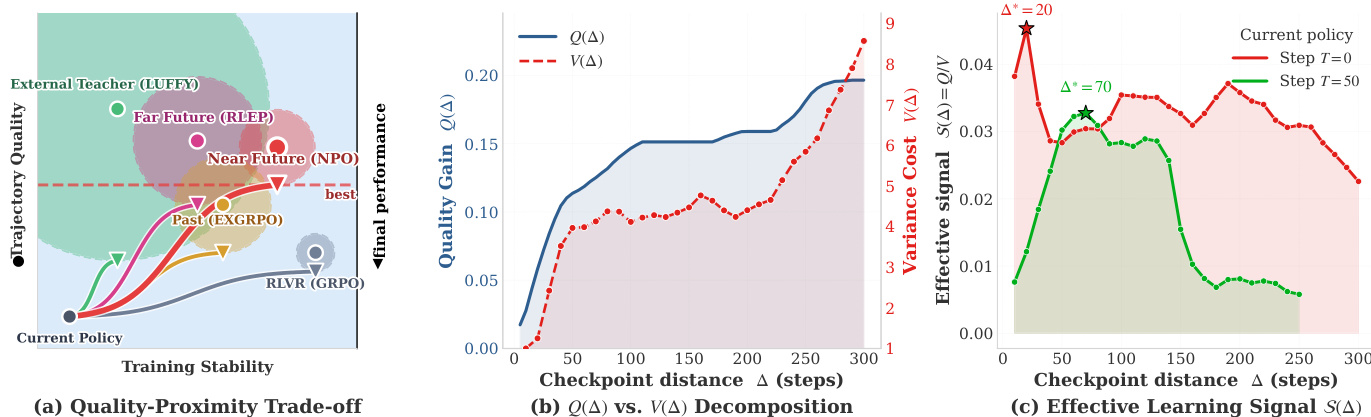
The authors propose Near-Future Policy Optimization (NPO), a method that enhances reinforcement learning with verification (RLVR) by leveraging trajectories from a near-future checkpoint of the same training run to guide the current policy. The core insight is that the effectiveness of off-policy guidance is governed by a trade-off between trajectory quality and variance cost. Trajectory quality Q(Δ), which measures the fraction of prompts the source policy can solve correctly, increases with the checkpoint distance Δ from the current policy. In contrast, variance cost V(Δ), which arises from importance weighting when combining trajectories from different policies, grows approximately exponentially with Δ. The effective learning signal S(Δ)=Q(Δ)/V(Δ) thus exhibits a U-shape, peaking at an optimal checkpoint distance Δ∗ that balances these competing factors. As shown in the figure below, existing approaches such as far-future replay, past-trajectory replay, and external teachers occupy suboptimal regions of the quality-stability trade-off plane, while NPO targets the high-S region by using a near-future policy that is both strong and close in distribution to the current policy.
The NPO framework modifies the standard RLVR training loop by introducing a selective guidance mechanism. At a training step t with current policy π(t), the method trains an additional Δ steps to obtain a near-future checkpoint π(t+Δ). It then rolls back to step t and uses π(t+Δ) to supply guidance trajectories for prompts where the current policy struggles. Specifically, for a prompt x, the current policy samples a group of n on-policy trajectories {oi}i=1n. The on-policy pass-rate p^(x) is computed, and if p^(x) is below a threshold τgate and a verified-correct guidance trajectory ox′ exists in a pre-computed cache, the n-th slot of the rollout group is replaced by ox′. The resulting group GNPO(x) is used to compute group-relative advantages and update the policy via a clipped objective, with importance sampling correction applied only to the guidance slot. This process is implemented in a way that incurs no extra rollout cost during the NPO segment, as the guidance trajectories are cached offline.
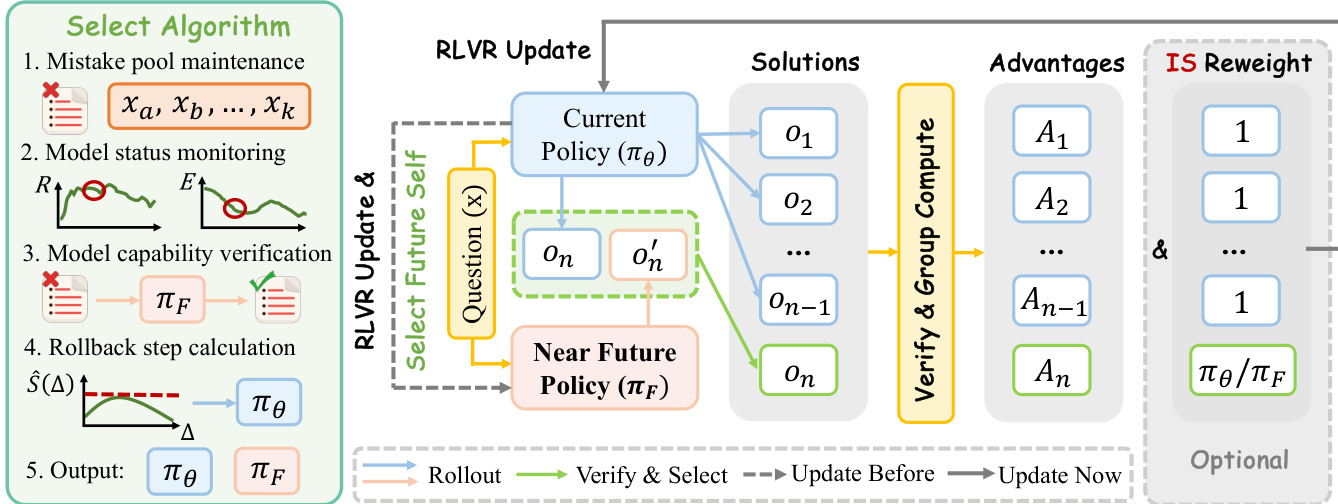
To validate the approach, the authors introduce two manual interventions: early-stage bootstrapping and late-stage plateau breakthrough. The early intervention uses a short scout segment to generate a near-future checkpoint that guides the initial training phase, accelerating convergence from a cold-start regime. The late intervention uses a checkpoint from beyond a performance plateau to guide the replay of the plateaued segment, enabling the policy to break through its on-policy ceiling. These interventions demonstrate that near-future guidance is beneficial across different training stages. Building on this, the authors propose AutoNPO, an adaptive variant that automates the intervention process. AutoNPO maintains a mistake pool of prompts failed by the current policy and uses online signals from training logs to determine when to intervene and how far to roll back. The intervention trigger is based on a combination of reward stagnation and entropy drop, while the rollback distance is selected by maximizing an empirical estimate of the effective learning signal S^(Δ)=Q^(Δ)/V^(Δ), where Q^(Δ) is the pass-rate of the current policy on prompts failed during the segment starting at t−Δ, and V^(Δ) is a variance proxy estimated from the per-token KL divergence between the current and the rollback policy. This adaptive controller reuses existing training signals and avoids substantial overhead, enabling a plug-and-play, objective-preserving improvement over standard RLVR.
Experiment
The researchers evaluated NPO and its variants against several reinforcement learning baselines across eight multimodal reasoning benchmarks to validate the effectiveness of targeted trajectory interventions. The results demonstrate that NPO, particularly the automated version, outperforms existing methods by providing timely guidance that prevents premature policy collapse and maintains healthy exploration. By strategically injecting high-quality trajectories, the approach successfully breaks through performance plateaus and achieves superior reasoning depth without requiring complex importance-sampling corrections.
The authors evaluate their NPO method against several baselines on multimodal reasoning benchmarks, showing that both manual and automated NPO variants consistently outperform existing reinforcement learning approaches. AutoNPO achieves the highest average accuracy and leads on multiple individual tasks, demonstrating that targeted interventions improve training dynamics without requiring exact importance-sampling correction. The results indicate that NPO's near-policy guidance enables effective, stable improvements while preserving exploration and avoiding premature policy collapse. AutoNPO achieves the highest average accuracy and leads on multiple benchmarks, outperforming all baselines including GRPO and replay-based methods. NPO maintains higher policy entropy throughout training, preventing premature collapse and supporting a higher late-stage performance ceiling. The importance-sampling correction is not necessary for NPO due to its near-policy guidance, simplifying the method without sacrificing gains.
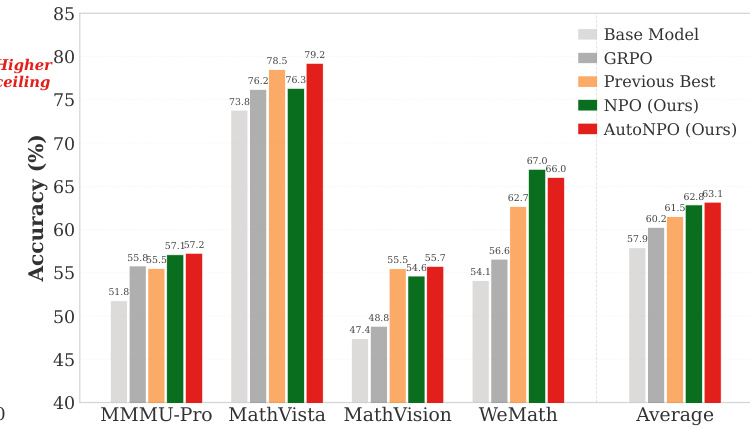
The authors evaluate NPO and its variants against several baselines on multimodal reasoning benchmarks, using Qwen3-VL-8B-Instruct as the base model. Results show that NPO methods, particularly AutoNPO, achieve higher average performance than all baselines, with improvements driven by targeted interventions that enhance training dynamics and maintain policy exploration. NPO variants outperform all baselines across multiple benchmarks, with AutoNPO achieving the highest overall score. AutoNPO improves training dynamics by maintaining higher policy entropy and avoiding premature collapse through targeted interventions. The importance-sampling correction is found to be unnecessary in NPO due to its near-policy guidance, simplifying implementation without sacrificing performance.
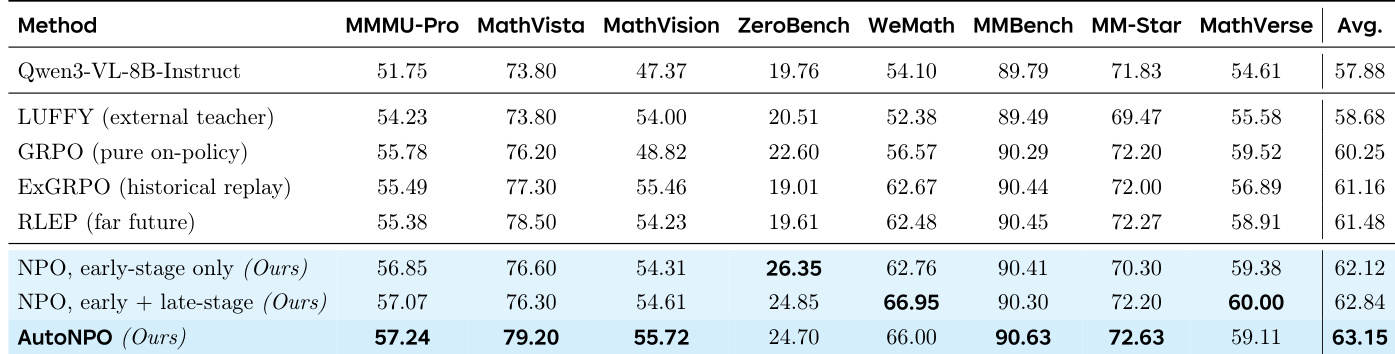
The authors evaluate the NPO method and its variants against several reinforcement learning baselines using multimodal reasoning benchmarks with a Qwen3-VL base model. The experiments demonstrate that NPO, particularly the automated AutoNPO variant, consistently outperforms existing approaches by enhancing training dynamics through targeted interventions. These results suggest that near-policy guidance effectively maintains policy entropy and prevents premature collapse, allowing for stable improvements without the need for complex importance-sampling corrections.