Command Palette
Search for a command to run...
변별적 텍스트 표현(Discriminative Text Representation)을 통한 클래스 레이블 기반의 원스텝 이미지 생성을 텍스트로 확장하기
변별적 텍스트 표현(Discriminative Text Representation)을 통한 클래스 레이블 기반의 원스텝 이미지 생성을 텍스트로 확장하기
Chenxi Zhao Chen Zhu Xiaokun Feng Aiming Hao Jiashu Zhu Jiachen Lei Jiahong Wu Xiangxiang Chu Jufeng Yang
초록
Few-step generation은 오랫동안 지속되어 온 목표였으며, 최근 MeanFlow로 대표되는 one-step generation 방식이 놀라운 성과를 거두고 있습니다. MeanFlow에 관한 기존 연구는 주로 class-to-image generation에 집중되어 왔습니다. 그러나 고정된 class label에서 유연한 text input으로 조건을 확장하여 더욱 풍부한 콘텐츠 생성을 가능하게 하는 직관적이면서도 아직 탐구되지 않은 방향이 존재합니다. 제한된 class label과 비교했을 때, text condition은 모델의 이해 능력에 더 큰 도전 과제를 제기하며, 강력한 text encoder를 MeanFlow 프레임워크에 효과적으로 통합할 것을 요구합니다.놀랍게도 text condition을 통합하는 과정은 매우 간단해 보임에도 불구하고, 기존의 학습 전략을 사용하여 강력한 LLM 기반 text encoder를 통합할 경우 만족스럽지 못한 성능을 보인다는 것을 확인했습니다. 근본적인 원인을 밝히기 위해 상세한 분석을 수행한 결과, MeanFlow generation의 refinement step이 단 한 단계(one step)와 같이 극도로 제한적이기 때문에, text feature representation이 충분히 높은 판별력(discriminability)을 갖추어야 한다는 사실을 발견했습니다. 이는 왜 MeanFlow 프레임워크 내에서 이산적이고 쉽게 구별 가능한 class feature가 우수한 성능을 보이는지를 설명해 줍니다.이러한 통찰을 바탕으로, 본 연구에서는 필요한 의미론적 특성(semantic properties)을 갖춘 것으로 검증된 강력한 LLM 기반 text encoder를 활용하고, MeanFlow generation 프로세스를 해당 프레임워크에 맞게 조정함으로써 최초로 효율적인 text-conditioned synthesis를 구현했습니다. 나아가, 널리 사용되는 diffusion model에 본 접근 방식을 적용하여 검증한 결과, 생성 성능이 유의미하게 향상됨을 입증했습니다. 본 연구가 향후 text-conditioned MeanFlow generation 연구에 있어 일반적이고 실용적인 참고 자료가 되기를 기대합니다. 코드는 https://github.com/AMAP-ML/EMF 에서 확인할 수 있습니다.
One-sentence Summary
To extend MeanFlow from class-to-image to text-to-image generation, this work introduces a discriminative text representation approach that overcomes the challenges of single-step generation by ensuring text features possess sufficient discriminability for high-quality content creation from flexible linguistic inputs.
Key Contributions
- This work provides the first systematic exploration and implementation of extending the MeanFlow framework from fixed class-label conditioning to flexible text-to-image conditioning.
- The paper identifies that few-step generation requires text representations with high semantic discriminability and disentanglement, explaining why conventional training strategies with LLM-based encoders often fail in one-step settings.
- By integrating the BLIP3o-NEXT LLM-based text encoder into the MeanFlow framework, the proposed approach achieves competitive one-step text-to-image synthesis with significantly improved generation quality.
Introduction
Efficient text-to-image generation is critical for reducing the high computational costs associated with multi-step diffusion models. While MeanFlow has emerged as a principled framework for achieving high-quality one-step generation, existing research is largely limited to class-label conditioning rather than flexible text inputs. Previous attempts to integrate powerful LLM-based text encoders into the MeanFlow framework often resulted in poor performance because standard training strategies fail to account for the unique requirements of limited denoising steps. The authors address this by identifying that successful few-step generation requires text representations with high semantic discriminability and disentanglement to reduce the semantic burden on the model. By leveraging an LLM-based text encoder with these specific properties, the authors introduce EMF, the first framework to effectively enable text-conditioned MeanFlow generation.
Method
The authors leverage the MeanFlow framework to enable efficient and accurate text-to-image generation by adapting its core architecture for bidirectional time conditioning and integrating a discriminative text representation space. The central component of this approach is a velocity network that predicts the flow map uθ(zt,t,r), which directly maps a latent state zt at time t to a state zr at time r through the transition zr=zt+(r−t)uθ(zt,t,r) for r>t. This formulation avoids the computationally expensive ODE integration required by standard flow matching during inference. The target for training this network is derived from a self-consistent relation obtained by differentiating the transition equation along the trajectory, yielding a target velocity field u~(zt,t,r)=v(zt,t)+(r−t)dtduθ(zt,t,r), where the total derivative is computed efficiently via Jacobian-vector products. The model is trained to minimize the MeanFlow loss LMF(θ)=Et,zt,r[∥uθ(zt,t,r)−sg(u~(zt,t,r))∥2], with the stop-gradient operator applied to the target to stabilize optimization.
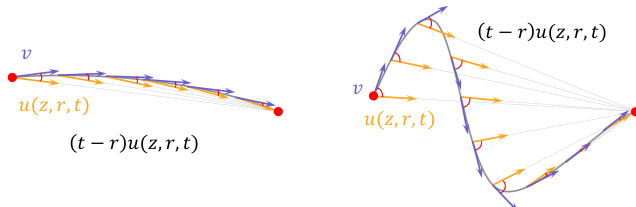
As shown in the figure below, the MeanFlow framework models the transition between latent states using a flow map u(z,r,t) that approximates the average velocity over the interval [r,t]. The velocity field v represents the instantaneous rate of change, while the term (t−r)u(z,r,t) represents the cumulative displacement over the interval. The figure illustrates that for a smooth trajectory, the flow map u(z,r,t) closely aligns with the average velocity, but in more complex cases, such as those involving text conditioning, the path becomes tortuous, leading to a significant divergence between the instantaneous and average velocities. This divergence is a primary source of semantic drift and necessitates additional corrective iterations for convergence.
To adapt MeanFlow for text-to-image generation, the authors modify the standard flow matching architecture to support bidirectional time conditioning. In contrast to the single temporal embedding ϕtime(t) used in conventional models, the adapted framework introduces two distinct temporal embedding layers: ϕinterval(⋅), which encodes the interval length t−r, and ϕend(⋅), which encodes the segment end time t. The combined conditional temporal embedding is constructed as ϕcond(t,r)=ϕinterval(t−r)+ϕend(t). This embedding, along with the text features ψtext(xtext) produced by a discriminative text encoder, jointly conditions the velocity network, which is defined as νθ(zt,t,r,ψtext)=fθ(zt,ϕcond(t,r),ψtext).

The training procedure employs an adaptive sampling strategy for timesteps (t,r), drawing from either a uniform or logit-normal distribution with parameters μ(p) and σ(p) interpolated over training progress p∈[0,1]. The ratio of non-equal timesteps (t=r) is increased adaptively to ensure balanced exposure to both short- and long-range segments, promoting stable learning of the mean velocity field. The full training objective minimizes the standard MeanFlow loss with the target utgt defined as νtgt=vθ(zt,t,ψtext)+(r−t)dtduθ(zt,t,r,ψtext), where the derivative term is computed via Jacobian-vector products and the stop-gradient operator is applied to utgt. This adaptation enables the model to handle the increased complexity of textual conditioning, achieving accurate and semantically faithful generation even in the one-step regime.
Experiment
The researchers evaluate the effectiveness of adapting the MeanFlow framework to text-to-image generation by comparing various text encoders and sampling step configurations. Through benchmarks such as GenEval and DPG-Bench, the experiments demonstrate that high-quality text representations with strong discriminability and disentanglement are essential for maintaining semantic integrity during few-step generation. The results show that the proposed method achieves superior instruction following and visual detail in as few as four steps, effectively rivaling much slower baseline models while scaling gracefully as more sampling steps are added.
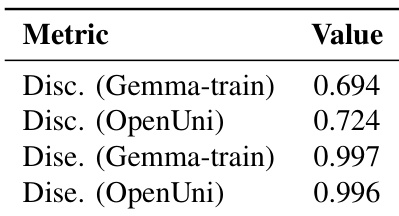
The authors compare different text encoders for their ability to support few-step image generation, focusing on discriminability and disentanglement. Results show that BLIP3o-NEXT achieves the highest score among the evaluated models, indicating superior performance in aligning text and image representations. The analysis highlights that models with strong discriminative capabilities are more effective in few-step generation scenarios. BLIP3o-NEXT outperforms other text encoders in generating high-quality images with few steps. Discriminability is a key factor in determining the effectiveness of text representations for few-step image generation. The evaluation reveals that models with stronger text-image alignment achieve better results in low-step inference settings.

The authors evaluate text encoders based on discriminability and disentanglement properties, using metrics derived from image-text retrieval and subsequence similarity. The results indicate that certain text encoders exhibit strong discriminability and disentanglement, with some showing higher performance in specific aspects such as discriminability or disentanglement, which may influence their effectiveness in few-step image generation. Text encoders vary in discriminability and disentanglement, with some showing stronger alignment between text and image representations. Disentanglement performance is high for certain encoders, suggesting better preservation of linguistic structure in embeddings. Discriminability metrics differ across encoders, indicating varying levels of image-text alignment and retrieval quality.
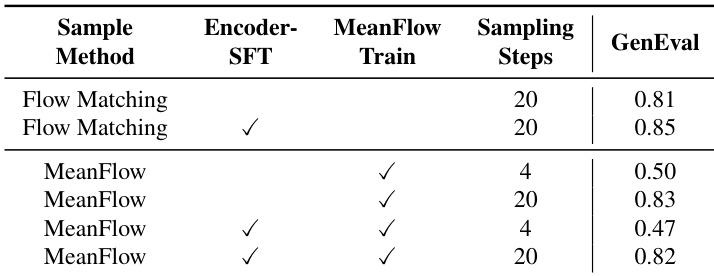
The authors compare different training and sampling configurations for image generation models, focusing on the impact of MeanFlow training and sampling steps on generation quality. Results show that MeanFlow training improves performance with fewer sampling steps, but the combination of SFT and MeanFlow training leads to higher quality outputs across various step settings. The model achieves a balance between inference speed and visual fidelity, with better results at higher sampling steps. MeanFlow training improves generation quality with fewer sampling steps compared to standard Flow Matching. The combination of SFT and MeanFlow training yields better results across different sampling step settings. Higher sampling steps lead to improved visual fidelity and performance in the MeanFlow framework.
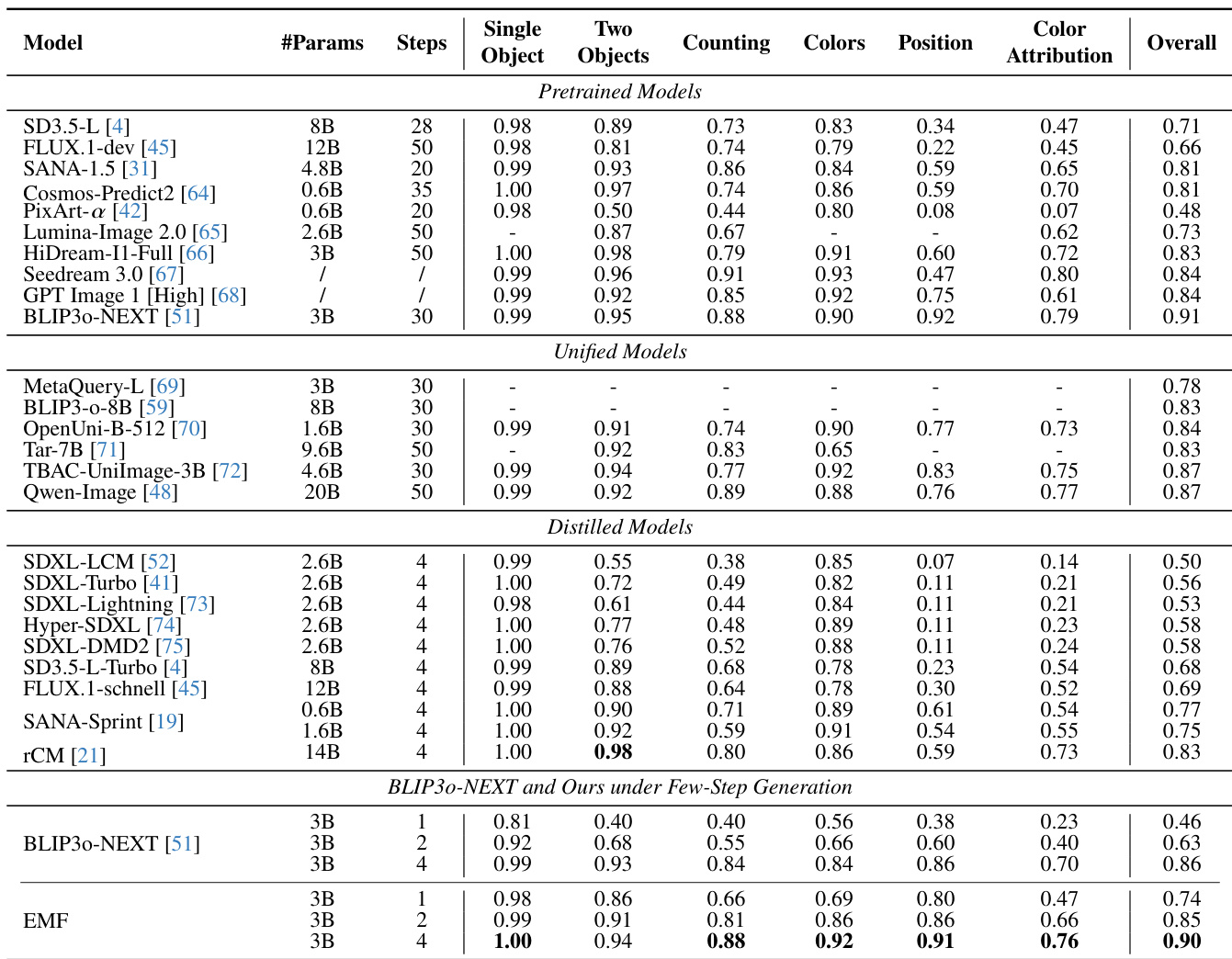
The authors compare their method with various pretrained, unified, and distilled models across multiple benchmarks, focusing on few-step generation performance. Results show that their approach achieves competitive or superior performance to state-of-the-art models, particularly in few-step settings, while maintaining high-quality image generation. The method demonstrates strong semantic fidelity and visual detail even with very few sampling steps, outperforming distilled models and rivaling larger models that require more steps. The proposed method achieves high performance with very few sampling steps, matching or exceeding the results of models that require significantly more steps. The method outperforms distilled models on challenging benchmarks, particularly in preserving fine-grained details and adhering to complex text instructions. The approach demonstrates robustness and stability across different sampling step configurations, maintaining high-quality generation even at low step counts.
The authors evaluate their model against several state-of-the-art text-to-image generation models using user studies and PickScore metrics to assess instruction-following and semantic fidelity. Results show that their method outperforms other models in both metrics, indicating superior alignment with textual prompts and stronger visual detail preservation under few-step generation. The performance gap widens as the number of sampling steps decreases, highlighting the robustness of their approach in low-step regimes. the model achieves the highest PickScore and User Study scores, outperforming other models in instruction-following and semantic fidelity. The performance advantage of the method becomes more pronounced in low-step generation, indicating robustness under constrained sampling. the model produces more accurate and detailed images compared to distilled models, particularly in complex text prompts.
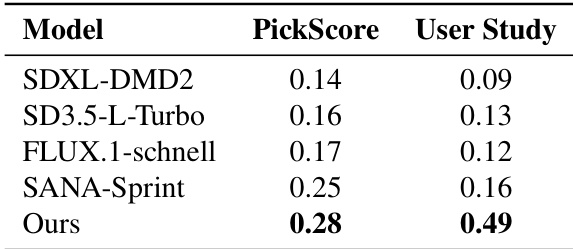
The authors evaluate various text encoders, training configurations, and generation methods to optimize few-step image generation through metrics of discriminability, disentanglement, and semantic fidelity. The results demonstrate that superior text-image alignment and the combination of SFT with MeanFlow training are critical for maintaining high visual quality during low-step inference. Ultimately, the proposed method outperforms existing distilled and state-of-the-art models by providing robust instruction-following and fine-grained detail preservation even under highly constrained sampling settings.