Command Palette
Search for a command to run...
BioInstruct: 생물 의학 자연어 처리(Biomedical Natural Language Processing)를 위한 Large Language Models의 Instruction Tuning
BioInstruct: 생물 의학 자연어 처리(Biomedical Natural Language Processing)를 위한 Large Language Models의 Instruction Tuning
Hieu Tran Zhichao Yang Zonghai Yao Hong Yu
초록
본 연구의 목적은 도메인 특화 instruction dataset을 도입하고, 이를 multi-task learning 원리와 결합했을 때의 영향을 조사함으로써 생물 의학 자연어 처리(BioNLP) 분야에서 large language models(LLMs)의 성능을 향상시키는 것입니다. 연구팀은 LLM(LLaMA 1 및 2, 7B 및 13B 버전)을 instruction-tune하기 위해 25,005개의 instruction으로 구성된 BioInstruct를 구축하였습니다. 해당 instruction은 사람이 직접 선별한 80개의 instruction 중 무작위로 추출한 3-seed 샘플을 GPT-4 모델에 prompt로 제공하여 생성되었습니다. 파라미터 효율적 미세 조정(parameter-efficient fine-tuning)을 위해 Low-Rank Adaptation(LoRA)을 채택하였습니다.이후, instruction-tuned LLM을 질문 답변(QA), 정보 추출(IE), 텍스트 생성(SEN)의 세 가지 주요 범주로 분류되는 여러 BioNLP 태스크에 대해 평가하였습니다. 또한, instruction의 범주(예: QA, IE, generation)가 모델 성능에 미치는 영향도 조사하였습니다. instruction-tuning을 거치지 않은 LLM과 비교했을 때, 본 연구의 instruction-tuned LLM은 다음과 같이 괄목할 만한 성능 향상을 보였습니다: 평균 정확도(accuracy) 기준 QA에서 17.3%, 평균 F1 점수 기준 IE에서 5.7%, 그리고 평균 GPT4 점수 기준 Generation 태스크에서 96%의 향상을 기록했습니다. 특히, 7B-parameter 규모의 instruction-tuned LLaMA 1 모델은 방대한 도메인 특화 데이터나 다양한 태스크로 fine-tuning된 기존의 다른 생물 의학 분야 LLM들과 비교하여 대등하거나 오히려 능가하는 성능을 입증하였습니다.
One-sentence Summary
To enhance large language models for biomedical natural language processing, the authors propose BioInstruct, a domain-specific dataset of 25,005 instructions generated via GPT-4 that, when used to instruction-tune LLaMA 1 and 2 (7B and 13B) models using Low-Rank Adaptation (LoRA), significantly improves performance across question answering, information extraction, and text generation tasks.
Key Contributions
- The paper introduces BioInstruct, a domain-specific instruction dataset consisting of 25,005 instructions generated by prompting GPT-4 with samples drawn from human-curated biomedical tasks.
- This work implements parameter-efficient fine-tuning on LLaMA 1 and LLaMA 2 models using Low-Rank Adaptation (LoRA) to adapt large language models to the biomedical natural language processing domain.
- Experimental results demonstrate that the instruction-tuned models achieve significant performance gains across question answering, information extraction, and text generation tasks, with the 7B-parameter LLaMA 1 model performing competitively against other domain-specific models.
Introduction
Large language models (LLMs) are increasingly vital for biomedical natural language processing (BioNLP) tasks such as medical question answering and information extraction. While traditional fine-tuning on task-specific datasets can achieve high accuracy, it often requires massive amounts of high-quality annotated data and is prone to overfitting. The authors address these challenges by introducing BioInstruct, a domain-specific instruction tuning dataset consisting of 25,005 instructions generated via GPT-4. By applying parameter-efficient fine-tuning with Low-Rank Adaptation (LoRA) on LLaMA models, the authors demonstrate significant performance gains across question answering, information extraction, and text generation tasks.
Dataset

-
Dataset Composition and Sources: The authors introduce BioInstruct, a dataset consisting of 25,005 natural language instructions designed for biomedical and clinical NLP tasks. The dataset was generated using an automated "Self-Instruct" methodology, starting from 80 manually constructed seed tasks that cover diverse areas such as biomedical question answering, summarization, clinical trial eligibility, and differential diagnosis.
-
Data Structure and Metadata: Each entry in BioInstruct follows a structured format containing three fields: a natural language instruction, an input argument, and the expected textual output. To organize the data, the authors used GPT-4 to classify instructions into four major categories: Question Answering (22.8%), Information Extraction (33.8%), Generation (33.5%), and Other tasks (10%). This classification was validated through human inter-rater reliability analysis, achieving a Krippendorff's alpha of 0.83.
-
Processing and Filtering Rules: To ensure high quality and diversity, the authors applied several filtering constraints during the generation process:
- Diversity: New instructions were only added to the pool if their ROUGE-L similarity to existing instructions was below 0.7.
- Keyword Filtering: Instructions containing terms like "image," "picture," or "graph" were removed as they are typically unsuitable for language models.
- Heuristic Filtering: Invalid generations were discarded if the instruction was too long (over 150 words), too short (under 3 words), or if the output was a repetition of the input.
-
Model Usage and Evaluation: The authors used BioInstruct for fine-tuning models to explore multi-task performance. They conducted ablation studies by training on specific subsets of tasks to determine their contribution to benchmark performance. For evaluation, they utilized several specialized biomedical benchmarks, including MedQA-USMLE, MedMCQA, PubMedQA, and BioASQ MCQA for question answering, as well as Conv2note and ICliniq for clinical generation tasks.
Method
The proposed methodology is structured around two fundamental stages: the construction of a specialized dataset named BioInstruct and the subsequent fine-tuning of various Large Language Models (LLMs).
The authors first focus on the development of the BioInstruct dataset, which serves as the foundational knowledge base for the model. This dataset is designed to bridge the gap between general linguistic capabilities and specialized biological expertise. By curating high-quality, domain-specific instructions, the authors ensure that the subsequent training process targets the nuances of biological reasoning and terminology.
Following the dataset preparation, the methodology transitions to the fine-tuning phase. During this stage, several LLM architectures are subjected to supervised fine-tuning using the BioInstruct corpus. This process aims to align the pre-trained models with the specific requirements of the biomedical domain, enhancing their ability to follow complex biological instructions and provide accurate, context-aware responses.
Experiment
The study evaluates the effectiveness of BioInstruct, a newly introduced automated instruction-tuning dataset, by fine-tuning LLaMA models across question answering, information extraction, and text generation tasks. The experiments validate that instruction tuning significantly enhances model performance in the biomedical domain, often outperforming established domain-specific baselines. Findings indicate that while increasing data volume generally improves capabilities, the specific combination of tasks that yields the best results varies depending on the target application.
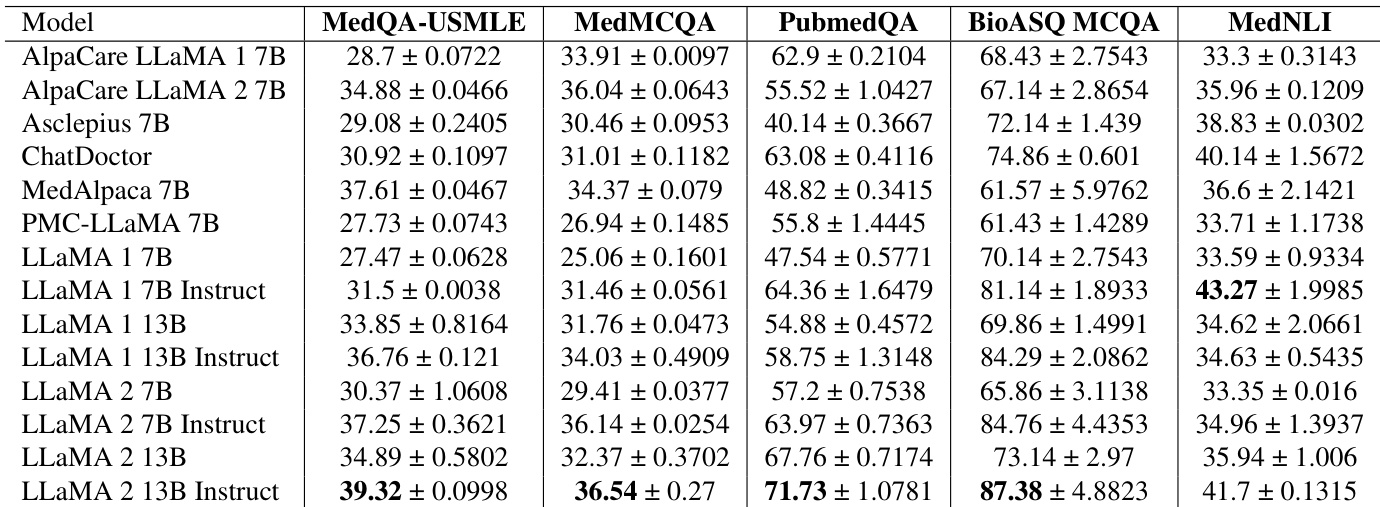
The authors evaluate several large language models on multiple-choice question answering and natural language inference tasks within the biomedical domain. Results show that instruction-tuned LLaMA models generally achieve higher performance across these benchmarks compared to their non-instructed versions and several specialized baseline models. Instruction-tuned LLaMA models demonstrate superior performance in medical question answering and inference tasks compared to base models The LLaMA 2 13B Instruct model achieves the highest scores across most evaluated biomedical question answering benchmarks Specialized baselines such as ChatDoctor and MedAlpaca show competitive results but are often surpassed by the instruction-tuned LLaMA variants
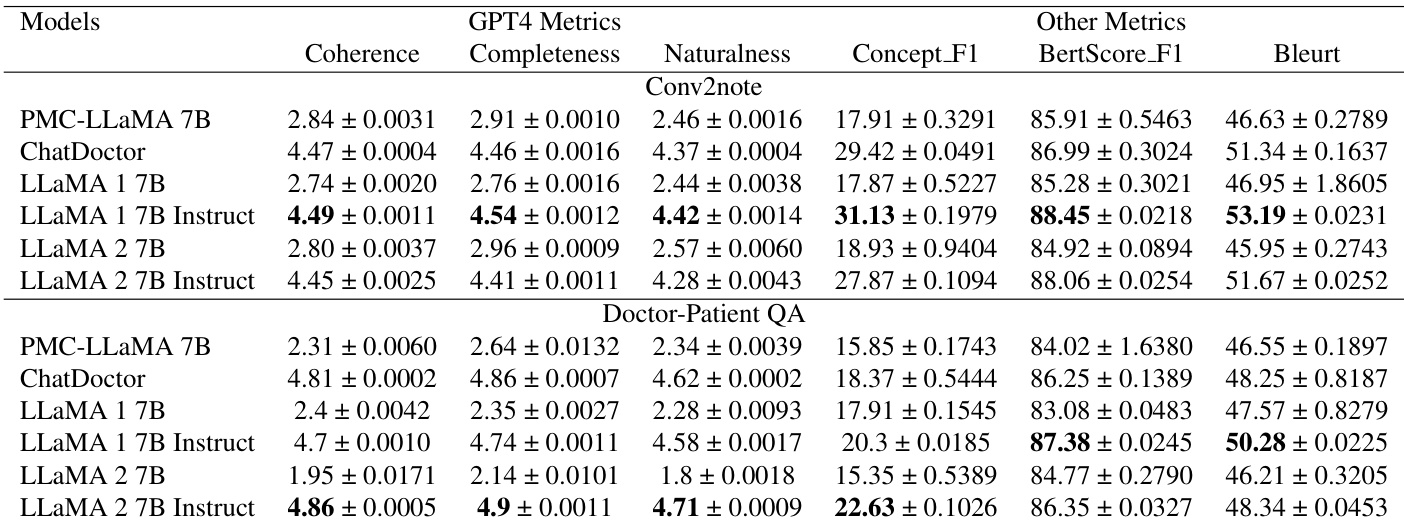
The authors evaluate several models on two text generation tasks, Conv2note and Doctor-Patient QA, using metrics such as GPT-4 based scores and semantic similarity measures. Results show that instruction-tuned LLaMA models generally achieve higher scores in coherence, completeness, and naturalness compared to their non-instructed versions and several baseline models. Instruction-tuned LLaMA 1 7B achieves superior performance in coherence and completeness for the Conv2note task compared to other models. For Doctor-Patient QA, the instruction-tuned LLaMA 2 7B model demonstrates higher coherence and naturalness scores than the baseline models. The instruction-tuned LLaMA 1 7B model shows improved semantic similarity and concept overlap in the Conv2note task relative to the original LLaMA 1 7B.
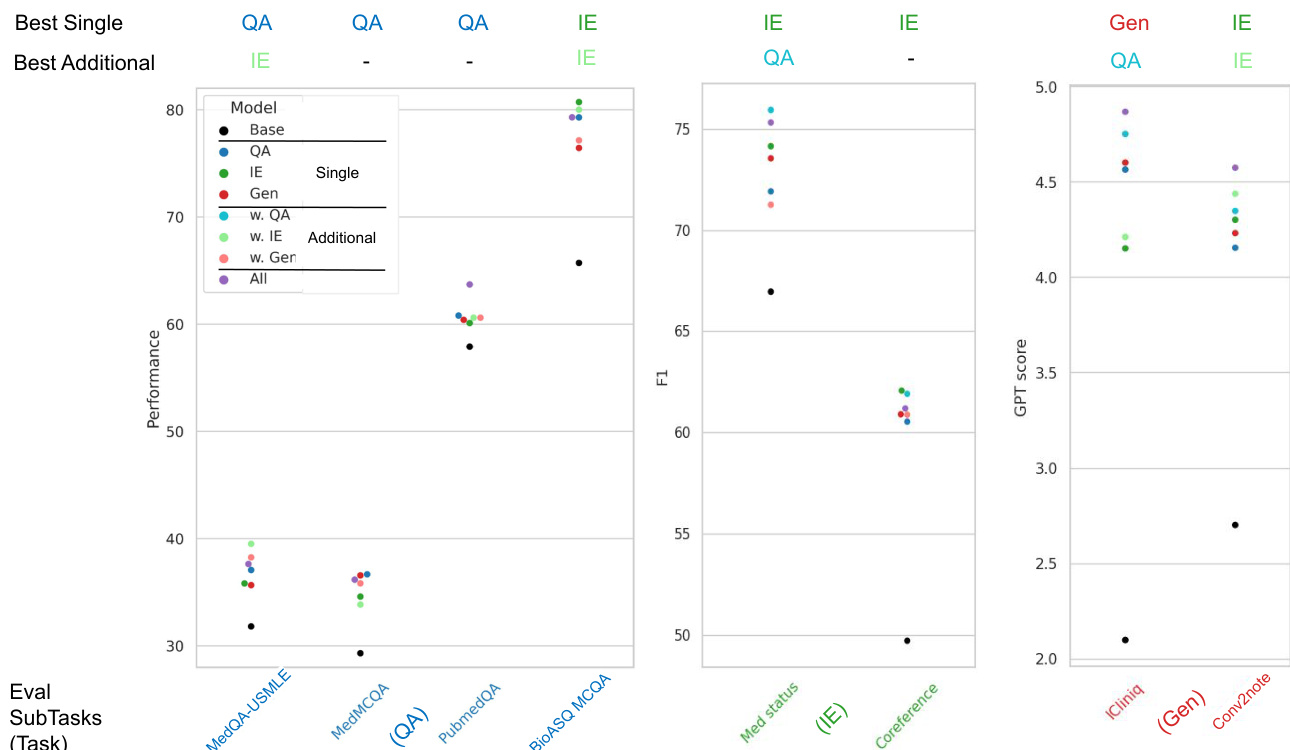
The authors evaluate the impact of multi-task instruction tuning by examining how training on specific task categories affects performance across different evaluation tasks. Results show that while certain task combinations provide synergistic benefits, the effectiveness of additional training tasks depends on the specific evaluation objective. Training with additional question answering tasks provides a performance boost for both information extraction and generation tasks. Information extraction tasks show a slight performance benefit when supplemented with question answering training. The performance gains from multi-task tuning are task-dependent, as some task combinations can lead to performance decreases in certain evaluation categories.

The the the table compares the performance of several biomedical language models on medication status extraction and coreference resolution tasks. Results demonstrate that instruction-tuned models generally achieve higher performance levels compared to their non-instructed counterparts and several domain-specific baselines. The instruction-tuned LLaMA 2 7B model achieves the highest precision and F1 scores for medication status extraction. For coreference resolution, the instruction-tuned LLaMA 2 7B model shows superior performance in precision, recall, and F1 scores compared to all other listed models. Instruction tuning provides notable improvements in recall for medication status extraction across different model versions.

The authors evaluate various LLaMA models across biomedical multiple-choice questions, natural language inference, text generation, and information extraction tasks to assess the impact of instruction tuning. The results demonstrate that instruction-tuned models consistently outperform their base versions and several specialized baselines in terms of coherence, naturalness, and extraction accuracy. Furthermore, while multi-task instruction tuning can provide synergistic benefits for information extraction and generation, the effectiveness of adding specific training tasks remains highly dependent on the target evaluation objective.