Command Palette
Search for a command to run...
OneVL: 시각-언어 설명을 통한 단일 단계 잠재 추론 및 계획 (One-Step Latent Reasoning and Planning with Vision-Language Explanation)
OneVL: 시각-언어 설명을 통한 단일 단계 잠재 추론 및 계획 (One-Step Latent Reasoning and Planning with Vision-Language Explanation)
초록
Chain-of-Thought (CoT) 추론은 VLA 기반 자율 주행의 경로 예측(trajectory prediction)을 가속화하는 강력한 동력이 되었으나, 그 자기회귀적(autoregressive) 특성으로 인해 발생하는 지연 시간(latency) 비용은 실시간 배포를 저해하는 요소가 되고 있습니다. Latent CoT 방식은 추론 과정을 연속적인 은닉 상태(hidden states)로 압축하여 이 격차를 줄이려 시도하지만, 명시적인(explicit) 방식의 성능에는 미치지 못하는 한계를 보입니다. 본 연구진은 이러한 성능 저하의 원인이 실제 주행을 지배하는 인과적 역학(causal dynamics)이 아닌, 세계의 상징적 추상화(symbolic abstraction)를 순수하게 언어적인 잠재 표현(latent representations)으로만 압축하려 했기 때문이라고 판단합니다.이에 따라, 본 논문에서는 이중 보조 디코더(dual auxiliary decoders)의 감독을 통해 압축된 latent tokens를 경유하여 추론을 수행하는 통합 VLA 및 월드 모델(World Model) 프레임워크인 OneVL(One-step latent reasoning and planning with Vision-Language explanations)을 제안합니다. 텍스트 CoT를 재구성하는 언어 디코더와 더불어, 미래 프레임의 tokens를 예측하는 시각적 월드 모델 디코더를 도입함으로써, 잠재 공간(latent space)이 도로 기하학(road geometry), agent motion, 그리고 환경 변화의 인과적 역학을 내재화하도록 강제합니다.3단계 학습 파이프라인은 이러한 잠재 표현들을 경로(trajectory), 언어, 그리고 시각적 목표에 따라 점진적으로 정렬하여 안정적인 공동 최적화(joint optimization)를 보장합니다. 추론 단계에서는 보조 디코더를 제거하고 모든 latent tokens를 단일 병렬 패스(single parallel pass)로 미리 채움(prefilled)으로써, 최종 답변만을 예측하는 방식과 동일한 속도를 구현합니다. 4개의 벤치마크 테스트 결과, OneVL은 명시적 CoT를 능가하는 최초의 latent CoT 방법론으로서, 답변 전용(answer-only) 지연 시간 내에 최첨단(state-of-the-art) 정확도를 달성했습니다. 이는 언어와 월드 모델 감독을 동시에 활용한 더 정밀한 압축이, 장황한 token-by-token 추론보다 더 일반화 가능한 표현을 생성한다는 직접적인 증거를 제공합니다.프로젝트 페이지: https://xiaomi-embodied-intelligence.github.io/OneVL
One-sentence Summary
The Xiaomi Embodied Intelligence Team proposes OneVL, a unified VLA and world model framework that employs dual auxiliary decoders to supervise compact latent tokens through language reconstruction and future-frame prediction, enabling one-step latent reasoning and planning that surpasses explicit chain-of-thought performance at answer-only latency across four benchmarks.
Key Contributions
- The paper introduces OneVL, a unified Vision-Language-Action (VLA) and World Model framework that utilizes compact latent tokens for reasoning and planning. This method routes reasoning through a compressed latent space that is supervised by dual auxiliary decoders to capture both linguistic reasoning and causal environmental dynamics.
- A three-stage training pipeline is presented to progressively align latent representations with trajectory, language, and visual objectives. This approach ensures stable joint optimization by using a language decoder to reconstruct text-based Chain-of-Thought and a visual world model decoder to predict future-frame tokens.
- The framework achieves state-of-the-art accuracy across four benchmarks by enabling a single parallel pass at inference time where auxiliary decoders are discarded. This design allows the model to match the speed of answer-only prediction while surpassing the performance of explicit Chain-of-Thought methods.
Introduction
Vision-Language-Action (VLA) models are increasingly used in autonomous driving to unify scene understanding, reasoning, and trajectory planning. While Chain-of-Thought (CoT) reasoning improves prediction accuracy by surfacing intermediate driving intents, its autoregressive nature creates high inference latency that is unsuitable for real-time, safety-critical deployment. Existing latent CoT methods attempt to compress reasoning into continuous hidden states to save time, but they often underperform explicit CoT because they rely on purely linguistic representations that capture symbolic abstractions rather than the actual causal dynamics of the driving environment.
The authors leverage a unified VLA and World Model framework called OneVL to bridge this gap. They introduce dual auxiliary decoders to supervise compact latent tokens: a language decoder to reconstruct text-based reasoning and a visual world model decoder to predict future-frame tokens. This dual supervision forces the latent space to internalize both semantic intent and the spatiotemporal causal dynamics of road geometry and agent motion. By using a three-stage training pipeline and a single-pass prefill inference method, OneVL achieves state-of-the-art accuracy at the speed of answer-only prediction.
Dataset

The authors evaluate OneVL using four complementary datasets designed to support Chain-of-Thought (CoT) reasoning and complex driving scenarios:
-
Dataset Composition and Sources
- NAVSIM: A large-scale autonomous driving benchmark derived from nuPlan driving logs, used for non-reactive simulation-based planning.
- ROADWork: A specialized dataset focusing on autonomous navigation in road construction zones, featuring hazards like temporary signage, barriers, and non-standard lane configurations.
- Impromptu: A large-scale vision-language-action benchmark distilled from eight open driving datasets, targeting unstructured corner-case scenarios.
- APR1: A dataset featuring Chain of Causation (CoC) annotations that provide decision-grounded reasoning traces for complex driving behaviors.
-
Annotation and Processing Details
- CoT Construction: The authors use various pipelines to generate reasoning traces for supervision. For NAVSIM, they leverage existing annotations from AdaThinkDrive. For ROADWork, they use an in-house pipeline to annotate work-zone hazards and lane interpretations. For Impromptu, they employ a VLM-centric pipeline to categorize unstructured scenarios and generate planning-oriented rationales. For APR1, they use a released model checkpoint to replicate CoC labels.
- Trajectory Subsampling: To make waypoint prediction suitable for autoregressive modeling, the authors apply a heuristic subsampling strategy to the APR1 waypoints, reducing the sequence from 64 points to 8 points while ensuring the final points are preserved.
- Test Set Construction: Due to the lack of an official test set for APR1, the authors subsample 700 examples from available video clips to create a custom evaluation set.
- Data Format: Training samples are structured to include visual latent tokens, language latent tokens, a trajectory answer, CoT reasoning steps, and future image tokens.
Method
The authors leverage a unified vision-language model architecture, built upon the Qwen3-VL-4B-Instruct foundation, to enable one-step latent reasoning, planning, and explainability in autonomous driving. The core framework integrates a vision encoder (ViT), a visual projector (MLP Aligner), and a large language model (LLM), forming a backbone that processes interleaved image and text inputs. To facilitate compact, interpretable reasoning, the model introduces two specialized latent token types: visual latent tokens (Zv) and language latent tokens (Zl). These tokens are inserted into the model's output sequence, with the visual latents preceding the language latents, to serve as compressed carriers of reasoning. During training, the hidden states corresponding to these latent token positions are extracted and fed into two auxiliary decoders. The visual auxiliary decoder predicts future-frame visual tokens, acting as a world model that validates the causal structure of the scene dynamics, while the language auxiliary decoder reconstructs human-readable chain-of-thought (CoT) reasoning. This dual-supervision mechanism ensures that the latent representations encode genuinely generalizable and causal information, grounding both semantic intent and physical dynamics. Refer to the framework diagram 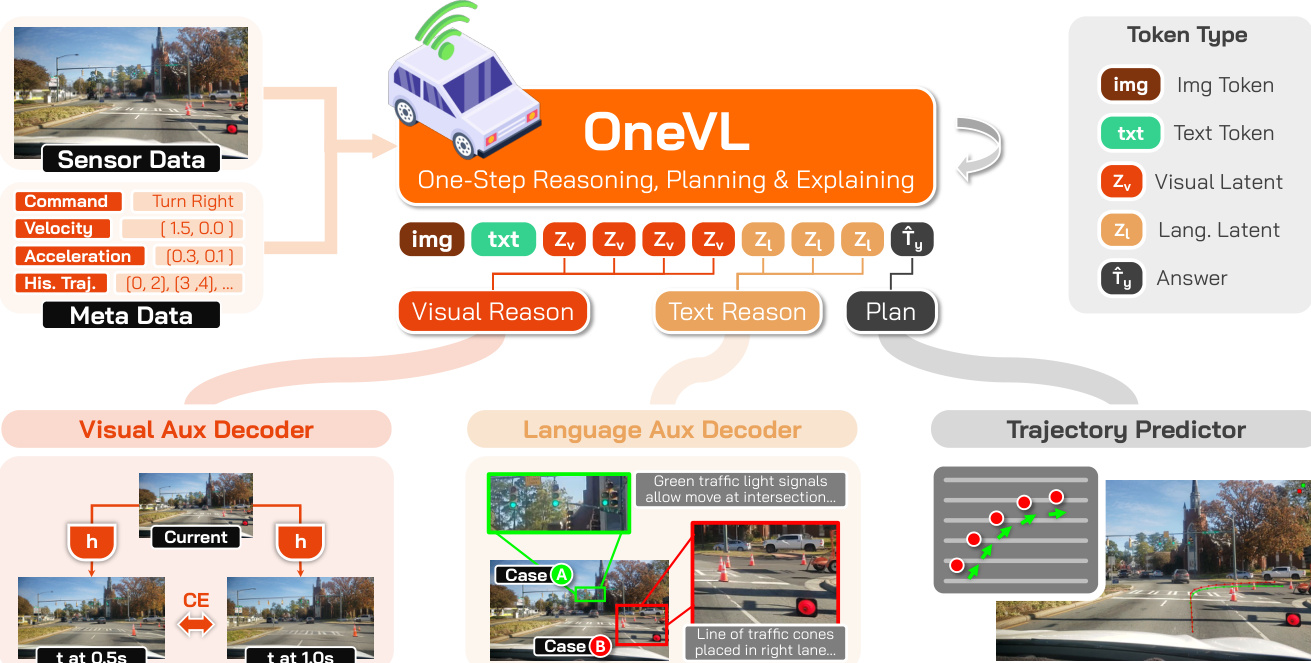 for a visual overview of this architecture.
for a visual overview of this architecture.
The language auxiliary decoder is designed to recover explicit reasoning text from the language latent hidden states. It takes as input the hidden states from the language latent tokens (Hl) and the current-frame ViT patch embeddings (V), concatenates them after projecting both into the decoder's embedding space, and then predicts the ground-truth CoT text. The visual auxiliary decoder, meanwhile, performs future-frame prediction conditioned on both the current visual context and the visual latent hidden states (Hv). To represent images as discrete sequences, the model employs the IBQ visual tokenizer, which uses a large codebook of 131,072 discrete visual codes, extending the base model's vocabulary. The visual decoder is trained to predict the concatenated discrete visual token sequences for future frames at 0.5s and 1.0s. The total training objective is a weighted sum of the main model's cross-entropy loss for trajectory and latent token prediction (Lc), the language explanation loss (Ll), and the visual explanation loss (Lv), with a lower weight for the visual task to prevent it from dominating the training signal.
To ensure effective training of this complex architecture, the authors employ a three-stage pipeline. The process begins with a preliminary self-supervised pretraining of the visual auxiliary decoder to learn a strong unconditional prior for future-frame prediction from the current frame alone. This is followed by Stage 0, a main model warmup where the backbone is trained on trajectory prediction with the latent tokens embedded, allowing the model to learn to generate meaningful latent representations. Stage 1 then focuses on training the auxiliary decoders while keeping the main model frozen, ensuring they align with stable latent features. Finally, Stage 2 performs joint end-to-end fine-tuning of all components, enabling a virtuous cycle where the auxiliary decoders' supervisory signals refine the latent representations, which in turn improve the model's overall performance. At inference time, the auxiliary decoders are discarded, and the latent tokens are prefilled into the prompt context, enabling single-pass generation of the trajectory answer with inference speed comparable to answer-only prediction while retaining the interpretability of the reasoning process. 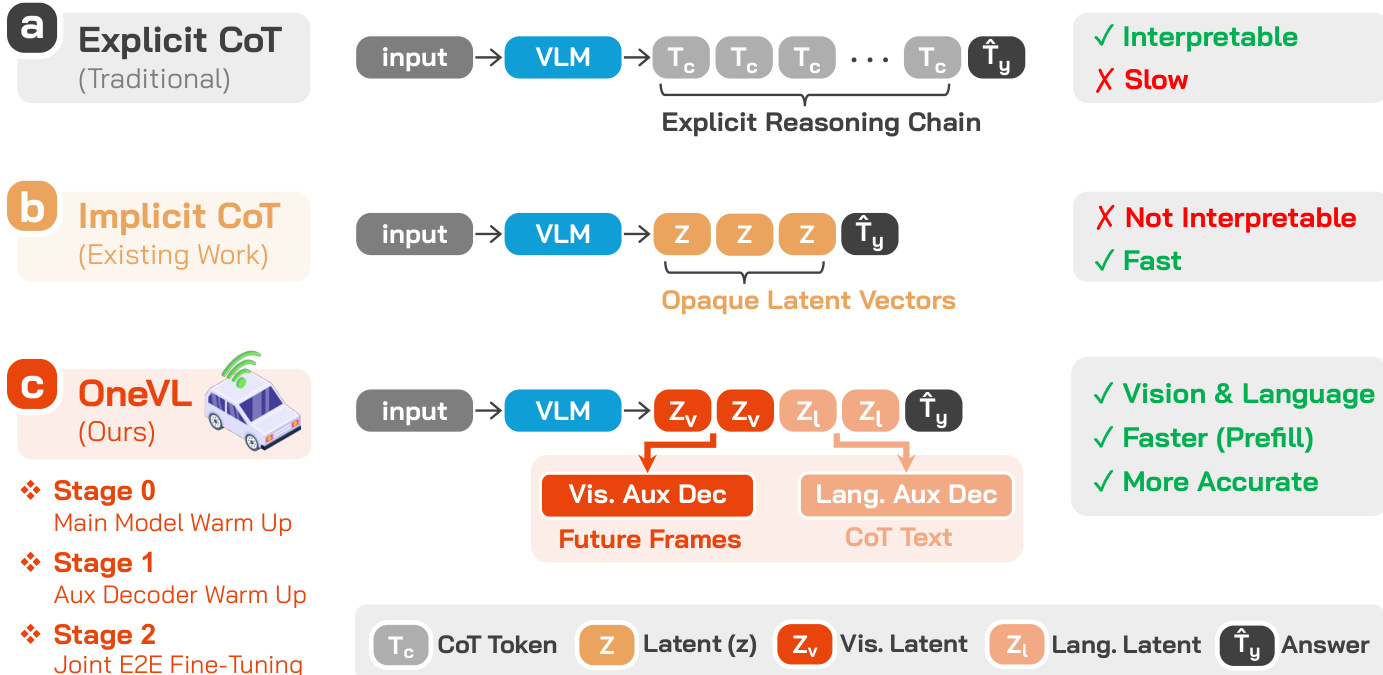
Experiment
The evaluation assesses the OneVL framework across four benchmarks, including NAVSIM, ROADWork, Impromptu, and APR1, to validate its trajectory prediction accuracy, explanation quality, and inference efficiency. By comparing OneVL against autoregressive and latent chain-of-thought baselines, the experiments demonstrate that combining linguistic reasoning with visual world-model supervision significantly improves planning performance. The results conclude that OneVL achieves state-of-the-art accuracy and provides human-interpretable explanations while maintaining the low latency required for real-world autonomous driving deployment.
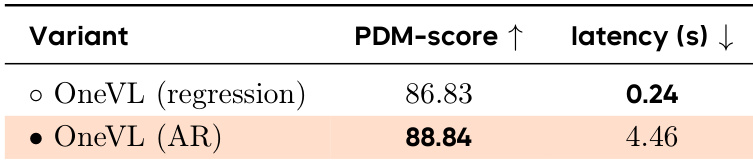
The authors compare a regression-based variant of OneVL with its autoregressive counterpart, showing that the regression version achieves a slightly lower PDM-score but significantly reduced inference latency. The results indicate that the regression approach maintains competitive performance while enabling much faster inference, supporting real-time deployment. OneVL regression achieves lower latency than OneVL AR while maintaining competitive performance. The regression variant of OneVL shows a minor drop in PDM-score compared to the autoregressive version. The regression approach enables significantly faster inference, making it suitable for real-time deployment.
The authors evaluate the quality of text explanations generated by different methods on the NAVSIM benchmark, focusing on how well the predicted reasoning aligns with ground-truth annotations. OneVL with a language auxiliary decoder achieves competitive results in explanation quality, showing strong performance across multiple metrics while maintaining efficiency. The comparison highlights that explicit reasoning methods outperform latent CoT approaches in explanation quality, but OneVL's latent framework still provides a strong balance between interpretability and performance. OneVL with language auxiliary decoder achieves competitive explanation quality compared to explicit reasoning methods on NAVSIM. Explicit reasoning methods outperform latent CoT methods in all evaluation metrics for text explanation quality. OneVL's latent framework provides a balance between explanation quality and inference efficiency.

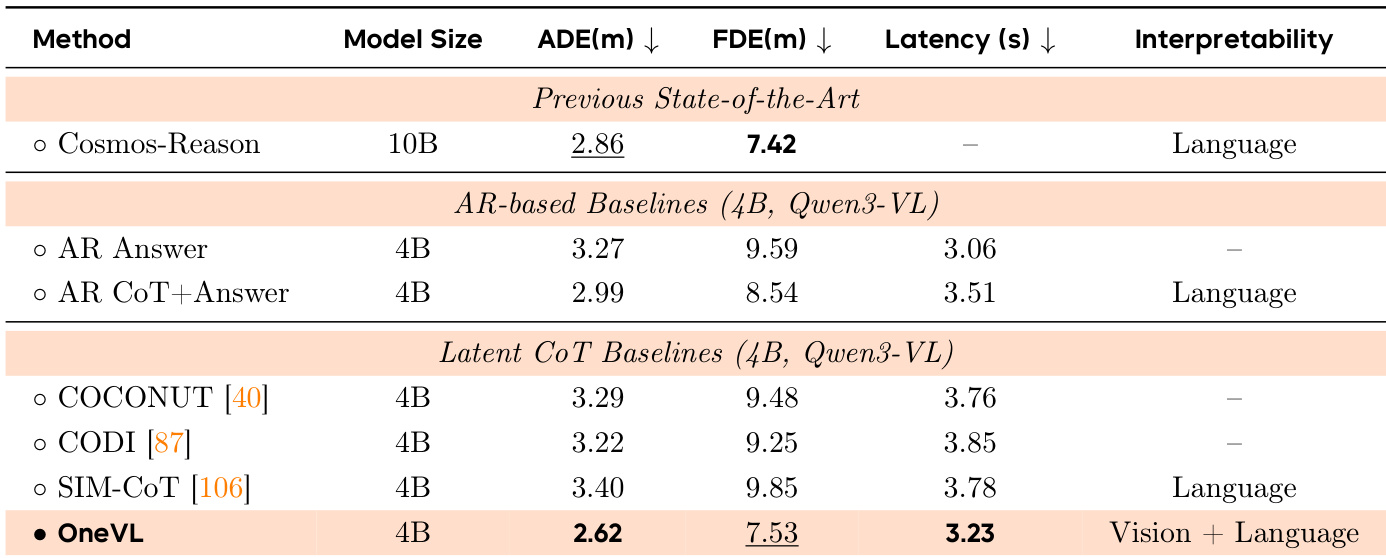
The authors compare various methods for autonomous driving trajectory prediction, focusing on performance, latency, and interpretability. Results show that OneVL achieves competitive accuracy with lower latency compared to previous state-of-the-art methods and outperforms other latent CoT approaches, particularly in trajectory prediction metrics. OneVL also provides interpretable outputs through both visual and language-based reasoning. OneVL achieves competitive trajectory prediction accuracy with lower latency than previous state-of-the-art methods. OneVL outperforms other latent CoT methods, especially in trajectory prediction metrics, while providing interpretable outputs. The visual auxiliary decoder contributes more to performance than the language decoder, indicating the importance of spatial-temporal grounding in reasoning.
The authors compare the performance of OneVL against Impromptu VLA on a trajectory prediction task, focusing on prediction accuracy over time. Results show that OneVL achieves significantly lower trajectory prediction errors across all time steps, indicating improved accuracy in predicting future vehicle paths compared to the baseline. The performance gap widens over time, suggesting that OneVL's predictions remain more consistent and accurate as the prediction horizon extends. OneVL achieves substantially lower trajectory prediction errors across all time steps compared to Impromptu VLA. The performance gap between OneVL and the baseline increases with longer prediction horizons. OneVL demonstrates superior accuracy in predicting future vehicle trajectories over time, especially at later time points.

The authors evaluate OneVL on multiple autonomous driving benchmarks, demonstrating superior performance compared to both autoregressive and latent chain-of-thought baselines. The model achieves state-of-the-art results while maintaining inference speeds comparable to answer-only prediction, highlighting the effectiveness of its multimodal auxiliary supervision and staged training approach. Key findings indicate that visual world model supervision and a three-stage training pipeline are essential for effective latent reasoning in trajectory prediction. OneVL outperforms all baselines on NAVSIM, ROADWork, Impromptu, and APR1, achieving state-of-the-art results across multiple metrics. The model matches the inference speed of answer-only prediction, demonstrating that prefilling latent tokens incurs negligible latency overhead. Visual auxiliary supervision and the three-stage training pipeline are critical, as their absence leads to significant performance degradation and failure in learning causal scene dynamics.
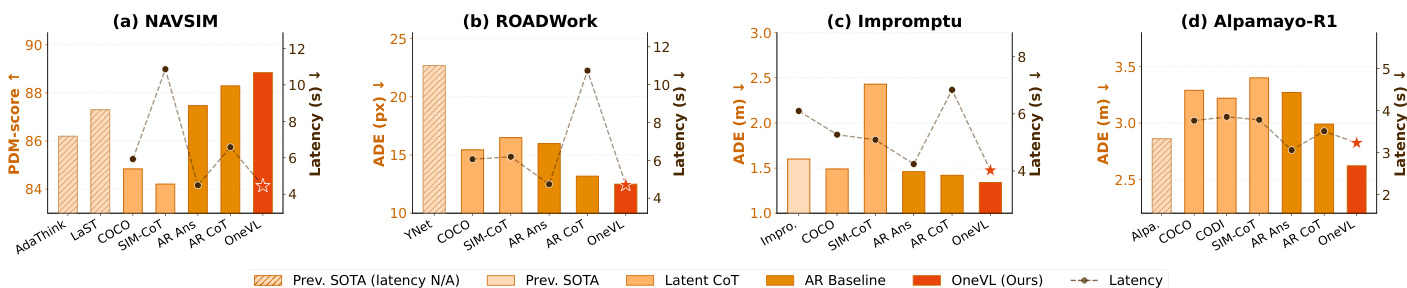
The authors evaluate OneVL through various comparative experiments focusing on inference efficiency, explanation quality, and trajectory prediction accuracy across multiple autonomous driving benchmarks. The results demonstrate that OneVL achieves state-of-the-art performance and superior long-term prediction consistency while maintaining inference speeds comparable to answer-only models. Ultimately, the findings highlight that the model's multimodal auxiliary supervision and staged training approach are essential for effective latent reasoning and real-time deployment.