Command Palette
Search for a command to run...
AnyRecon: Video Diffusion Model을 이용한 임의 시점 3D Reconstruction
AnyRecon: Video Diffusion Model을 이용한 임의 시점 3D Reconstruction
Yutian Chen Shi Guo Renbiao Jin Tianshuo Yang Xin Cai Yawen Luo Mingxin Yang Mulin Yu Linning Xu Tianfan Xue
초록
Sparse-view 3D reconstruction은 일상적인 촬영(casual captures)을 통해 장면을 모델링하는 데 필수적이지만, 비생성적(non-generative) 재구성 방식에서는 여전히 도전적인 과제로 남아 있습니다. 기존의 diffusion 기반 접근 방식은 새로운 시점(novel views)을 합성함으로써 이 문제를 완화하지만, 대개 한두 개의 캡처 프레임에만 의존하기 때문에 기하학적 일관성(geometric consistency)이 제한되고 대규모 또는 다양한 장면에 대한 확장성(scalability)이 떨어진다는 단점이 있습니다.본 논문에서는 임의의 순서가 없는 sparse input으로부터 재구성을 수행하며, 유연한 conditioning cardinality를 지원하는 동시에 명시적인 기하학적 제어(explicit geometric control)를 유지할 수 있는 확장 가능한 프레임워크인 AnyRecon을 제안합니다. 장거리 conditioning을 지원하기 위해, 본 방법론은 앞에 배치된 capture view cache를 통해 지속적인 전역 장면 메모리(persistent global scene memory)를 구축하며, 큰 시점 변화(viewpoint changes) 환경에서도 프레임 수준의 대응 관계(frame-level correspondence)를 유지하기 위해 시간적 압축(temporal compression)을 제거했습니다.또한, 더 나은 생성 모델을 넘어, 생성(generation)과 재구성(reconstruction) 사이의 상호작용이 대규모 3D 장면에서 매우 중요하다는 점을 발견했습니다. 이에 따라, 우리는 명시적인 3D 기하학적 메모리와 기하학 기반의 capture-view 검색(geometry-driven capture-view retrieval)을 통해 생성과 재구성을 결합하는 '기하학 인지형 conditioning 전략(geometry-aware conditioning strategy)'을 도입합니다. 효율성을 보장하기 위해, 4단계 diffusion distillation과 context-window sparse attention을 결합하여 이차 복잡도(quadratic complexity)를 줄였습니다. 광범위한 실험을 통해 불규칙한 입력, 큰 시점 차이, 그리고 긴 궤적(long trajectories)에 대해서도 견고하고 확장 가능한 재구성 성능을 입증하였습니다.
One-sentence Summary
AnyRecon is a scalable framework for 3D reconstruction from arbitrary and unordered sparse views that utilizes a persistent global scene memory and a geometry-aware conditioning strategy to maintain long-range geometric consistency and frame-level correspondence, overcoming the scalability and consistency limitations of existing diffusion-based methods.
Key Contributions
- The paper introduces AnyRecon, a scalable framework for 3D reconstruction from arbitrary and unordered sparse inputs that utilizes a video diffusion architecture with a global scene memory cache to maintain frame-level correspondence across large viewpoint changes.
- A geometry-aware conditioning strategy is presented to couple generation and reconstruction through a closed-loop system involving an explicit 3D geometric memory and a geometry-driven capture-view retrieval mechanism.
- The method incorporates 4-step diffusion distillation combined with context-window sparse attention to ensure computational efficiency, with experiments demonstrating superior performance in view interpolation, extrapolation, and large-scale scene consistency compared to existing baselines.
Introduction
Sparse-view 3D reconstruction is essential for transforming casual, irregular captures into immersive digital environments. While recent diffusion-based methods attempt to bridge the gap by synthesizing novel views, they often rely on only one or two reference frames, which limits their ability to maintain global geometric consistency and scale to large scenes. Furthermore, existing video diffusion frameworks are typically designed for sequential data, making them ill-suited for the unordered and non-sequential nature of arbitrary sparse inputs.
The authors leverage a scalable framework called AnyRecon to enable high-quality reconstruction from an arbitrary number of unordered views. They introduce a video diffusion architecture that utilizes a global scene memory cache and removes temporal compression to maintain frame-level correspondence across large viewpoint gaps. To support large-scale environments, the authors implement a geometry-aware conditioning strategy that creates a closed loop between generation and reconstruction through an explicit 3D geometry memory and geometry-driven view retrieval.
Dataset

The authors utilize the DL3DV-10K dataset, a large-scale collection of high-quality 3D indoor and outdoor scenes, to train AnyRecon. The dataset processing and usage are summarized below:
- Dataset Composition and Partitioning: Original video sequences are partitioned into clips consisting of 40 frames each. Each frame is processed at a resolution of 512 by 896.
- Conditioning Strategy: To enhance generative priors and simulate irregular input scenarios, the authors implement a randomized conditioning sampling strategy. For every clip, the first frame is fixed as a base reference, while an additional N views (where N is between 2 and 4) are randomly selected.
- Sampling Distribution: To balance narrow-baseline interpolation with wide-baseline synthesis, the additional conditioning views are sampled using a dual-probability approach. There is a 50% probability that indices are selected from the first 20 frames and a 50% probability they are selected from the full 40-frame window.
- Data Processing and Training Pairs: The selected conditioning views are passed through a feed-forward reconstruction module to establish an initial 3D geometry memory. The authors then project the resulting point-cloud observations onto target novel viewpoints to generate rendered images and visibility masks, which constitute the final training pairs for the geometry-controlled generative model.
Method
The AnyRecon framework operates as a closed-loop system for sparse-view 3D reconstruction, designed to handle arbitrary and unordered input sequences while maintaining geometric consistency across long trajectories. The overall architecture consists of three primary stages: initial geometry construction, novel view generation, and geometry updating, which collectively form an iterative refinement loop. As illustrated in the framework diagram, the process begins with the construction of an initial 3D geometry memory Mgeo from the input views, which are organized into a captured view bank Icap. This initial geometry is established using a feed-forward point map estimation method such as VGGT or π3, providing a foundational representation of the scene.
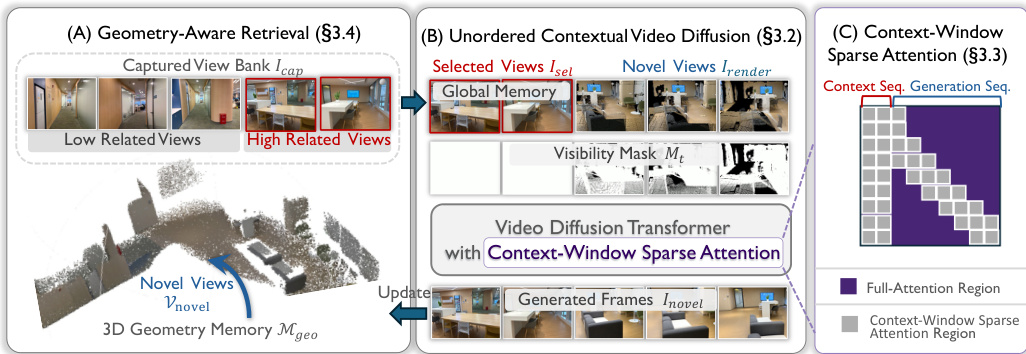
The second stage involves the synthesis of novel views along a user-specified trajectory Vnovel. To manage computational complexity, the trajectory is segmented, and for each segment, a geometry-aware retrieval process selects a subset of relevant views Isel from Icap. This retrieval is guided by the current 3D geometry memory Mgeo, ensuring that only views with significant geometric contribution to the target perspective are considered. The selected views, along with point-cloud renderings Irender and visibility masks Mt derived from Mgeo, serve as contextual inputs to the unordered contextual video diffusion model. This diffusion module, as detailed in Section 3.2, employs a global scene memory to store and query the retrieved reference views, enabling flexible context injection independent of temporal order. This mechanism decouples the generation process from strict temporal dependencies, allowing for robust synthesis across arbitrary viewpoint gaps. Furthermore, the model uses non-compressive latent encoding, where a frame-wise 2D VAE preserves the one-to-one mapping between latent tokens and pixel coordinates, avoiding the feature entanglement that arises from temporal compression in standard video diffusion models.

To ensure computational efficiency, the framework incorporates two key optimizations. First, a context-window sparse attention mechanism limits the receptive field of each frame in the target trajectory to a local temporal window and a selectively retrieved subset of geometry-aligned reference views Isel. This reduces the quadratic complexity associated with long sequences by focusing the model's attention on visually relevant regions. Second, a 4-step diffusion sampling strategy accelerates inference by distilling the pre-trained model into a student network capable of high-quality generation in just four steps. This is achieved through distribution matching distillation, which minimizes the Kullback-Leibler divergence between the student's and teacher's distributions, using a pseudo-regression objective with a stop-gradient operator to stabilize training.

The final stage is the geometry updating process, where the 3D geometry reconstructed from the newly synthesized views is used to update the global memory Mgeo. This update is critical for maintaining scene-level consistency, as it ensures that newly generated trajectory segments are integrated into the global scene representation. Without this update, the reconstructed geometry becomes incomplete and inconsistent across trajectory segments, leading to visual mismatches. The explicit memory update mechanism prevents error accumulation and geometric drift, anchoring each new segment to the evolving global structure. This recursive loop—where novel views inform geometry and updated geometry guides subsequent generation—enables scalable processing of long trajectories and large-scale inputs. The geometry-aware retrieval strategy, which selects conditioning views based on their geometric contribution to the target perspective, further enhances the robustness of the system under occlusion and complex spatial layouts.
Experiment
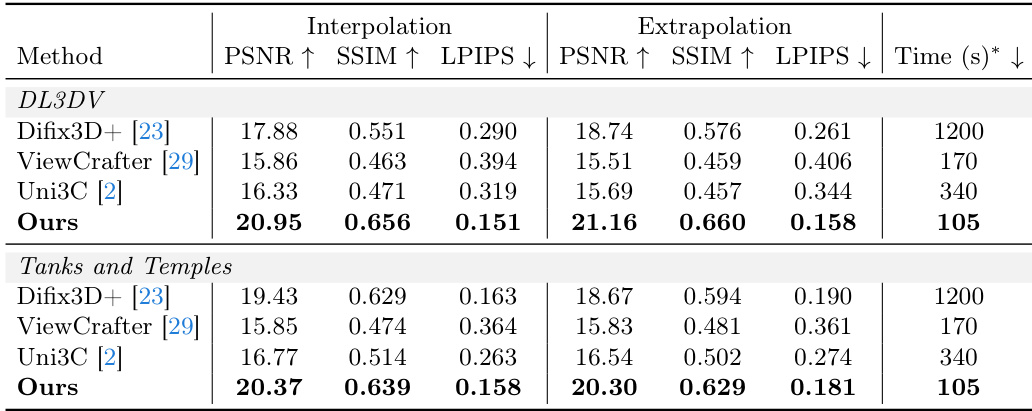
The evaluation compares AnyRecon against state-of-the-art diffusion-based methods using interpolation and extrapolation tasks on the DL3DV and Tanks and Temples datasets to assess reconstruction fidelity and generative capability. Results demonstrate that AnyRecon achieves superior structural integrity and appearance consistency by leveraging global scene memory to suppress geometric artifacts and hallucinate plausible content. Ablation studies further validate that avoiding temporal compression preserves essential high-frequency details, while the combination of model distillation and sparse attention significantly enhances inference efficiency without compromising competitive visual quality.
The authors evaluate their method against state-of-the-art diffusion-based 3D reconstruction models on two datasets, assessing performance in interpolation and extrapolation settings. Results show that the proposed method achieves superior quality across all metrics and significantly faster inference times compared to baselines, which exhibit structural inconsistencies and higher latency. The proposed method outperforms all baselines in both interpolation and extrapolation tasks, achieving higher quality across all evaluation metrics. The method demonstrates significantly faster inference times compared to other approaches, with the lowest latency observed in both datasets. Baselines exhibit structural inconsistencies and lower quality, particularly in handling large viewpoint gaps and maintaining cross-view coherence.
The authors conduct an ablation study to evaluate the impact of global scene memory on reconstruction quality. Results show that incorporating global scene memory leads to improvements across all metrics, with higher PSNR and SSIM values and lower LPIPS scores, indicating better pixel-level accuracy, structural integrity, and perceptual quality. The presence of global scene memory enhances the model's ability to preserve fine details and reduce artifacts in synthesized views. Incorporating global scene memory improves PSNR and SSIM while reducing LPIPS, indicating enhanced reconstruction quality. The model with global scene memory achieves better structural integrity and perceptual quality compared to the version without it. Global scene memory helps preserve fine-grained details and reduces artifacts in synthesized views.

The authors conduct an ablation study to evaluate the impact of different temporal compression strategies, inference efficiency techniques, and the role of global scene memory on reconstruction quality and speed. Results show that full temporal compression degrades visual fidelity, while the combination of distillation and sparse attention significantly reduces inference time with minimal quality loss, and maintaining raw captured views in global memory improves structural and textural accuracy. The study highlights trade-offs between efficiency and quality, emphasizing the importance of preserving high-frequency details and using memory-based conditioning for robust 3D reconstruction. Full temporal compression leads to a noticeable degradation in visual fidelity, particularly in fine-grained structural details. The integration of distillation and sparse attention reduces inference time substantially while maintaining competitive reconstruction quality. Maintaining raw captured views in global memory improves structural integrity and texture recovery compared to baselines relying on rendered point-cloud maps.
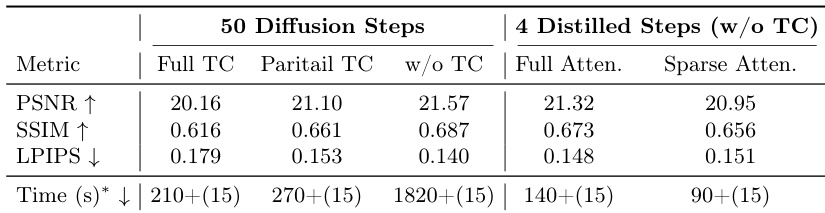
The authors evaluate their method against state-of-the-art diffusion-based models through comparative testing on interpolation and extrapolation tasks, alongside ablation studies on scene memory and temporal compression strategies. The results demonstrate that the proposed approach provides superior reconstruction quality and faster inference times while maintaining better cross-view coherence than existing baselines. Furthermore, the findings highlight that utilizing global scene memory and combining distillation with sparse attention optimizes the balance between computational efficiency and the preservation of fine-grained structural details.