HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

Parrot:出力の真実性に対する説得および同意への頑健性評価——LLMsのための迎合性頑健性ベンチマーク
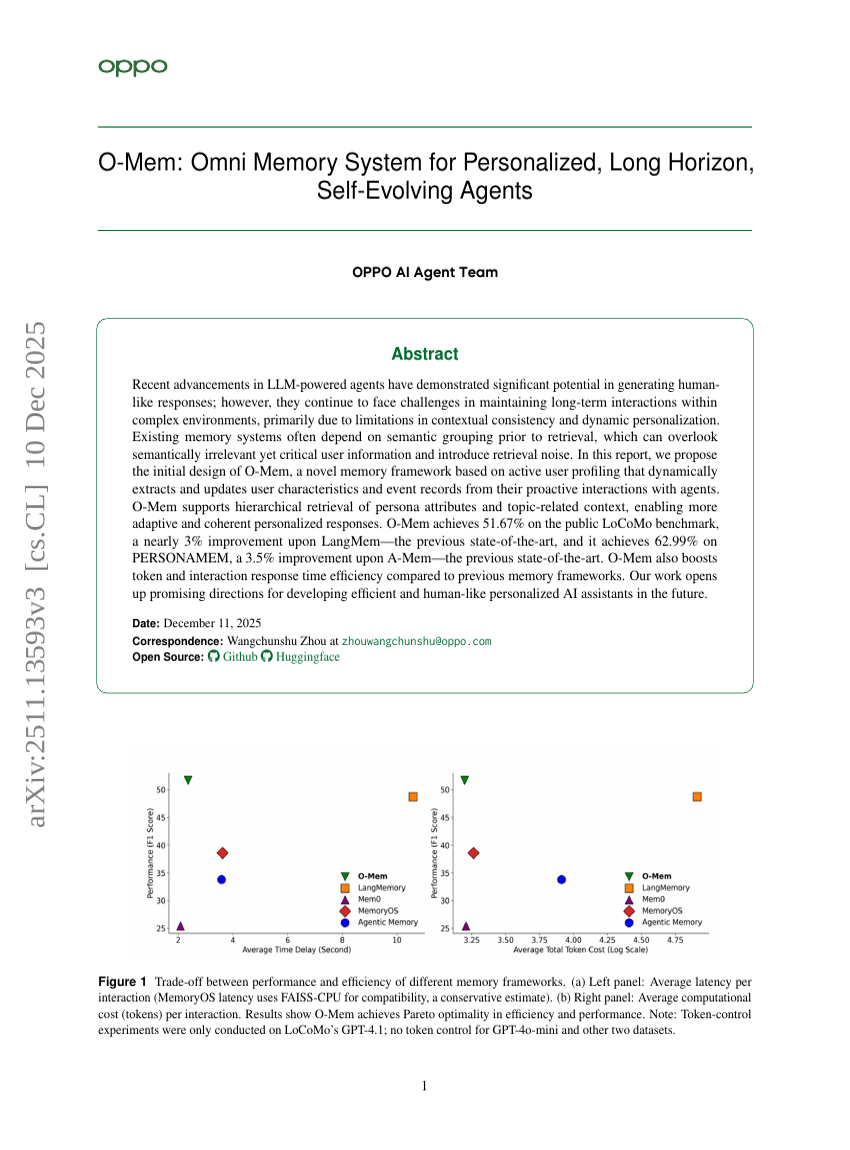
O-Mem: 個人化された長期自律進化するAgentのための包括的メモリシステム

























Parrot:出力の真実性に対する説得および同意への頑健性評価——LLMsのための迎合性頑健性ベンチマーク
O-Mem: 個人化された長期自律進化するAgentのための包括的メモリシステム
テキストの内在的次元の解明:学術要旨から創作物語まで
SAM 3:概念を用いたSegment Anything
GeoVista:地理的位置特定のためのWeb拡張型Agent視覚的推論
OpenMMReasoner:オープンかつ汎用的なレシピによるマルチモーダル推論のフロンティアの開拓
HiPO:大規模言語モデルにおける動的推論向けハイブリッド方策最適化
SERES:スパースな視点からの意味認識型ニューラル再構成
SDAR:スケーラブルなシーケンス生成のための相乗効果を持つ拡散-自己回帰パラダイム
MultiPL-MoE:ハイブリッドMixture-of-Expertsによる大規模言語モデルの多プログラミング・多言語拡張
CapRL:強化学習を用いた密集画像記述能力の促進
離散拡散発散指令による超高速言語生成
DisCO:識別的制約最適化を用いた大規模推論モデルの強化
QSVD:低精度視覚言語モデルにおける統合的クエリ・キー・バリュー重み圧縮のための効率的低ランク近似
ネストド・ラーニング:ディープラーニングアーキテクチャの錯覚
SAM 3D:画像内の何でも3D化
Video-as-Answer:Joint-GRPOを用いた次に発生する動画イベントの予測と生成
最初のフレームがビデオコンテンツカスタマイズの最適な場所である
マルチモーダル基礎モデルによる空間知能のスケーリング
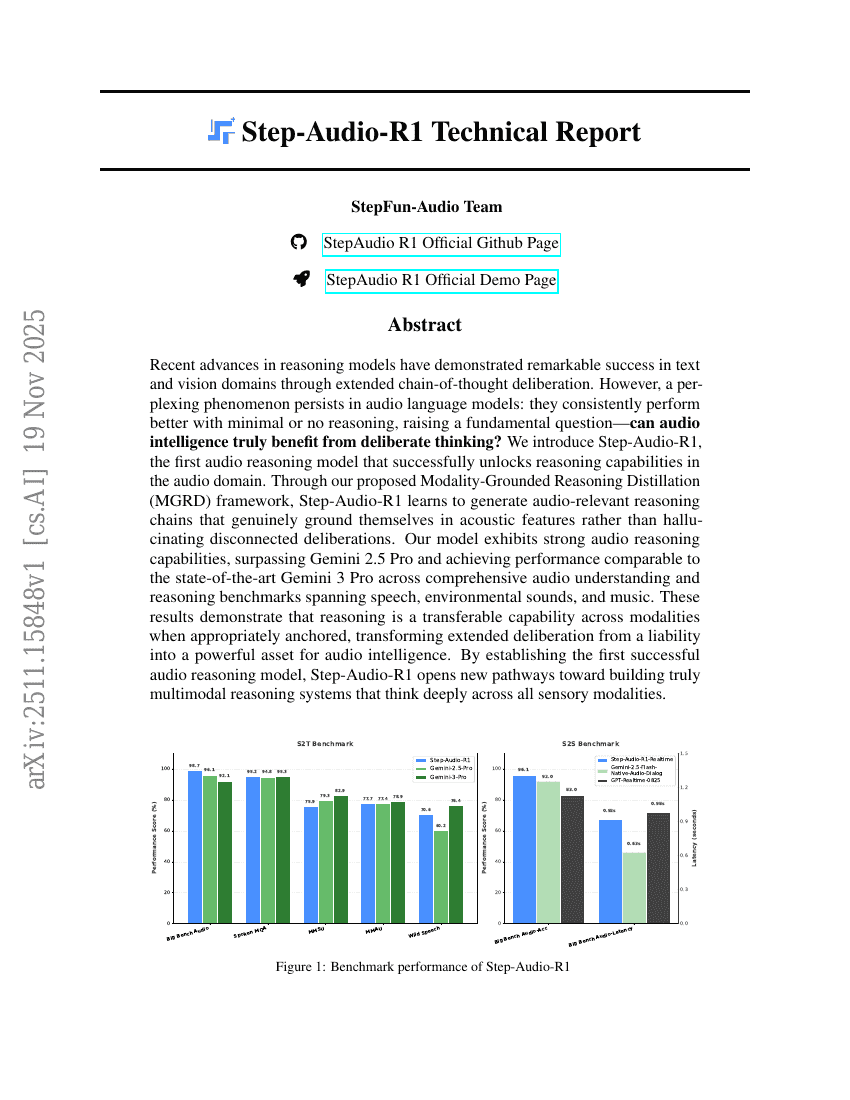
Step-Audio-R1 技術報告
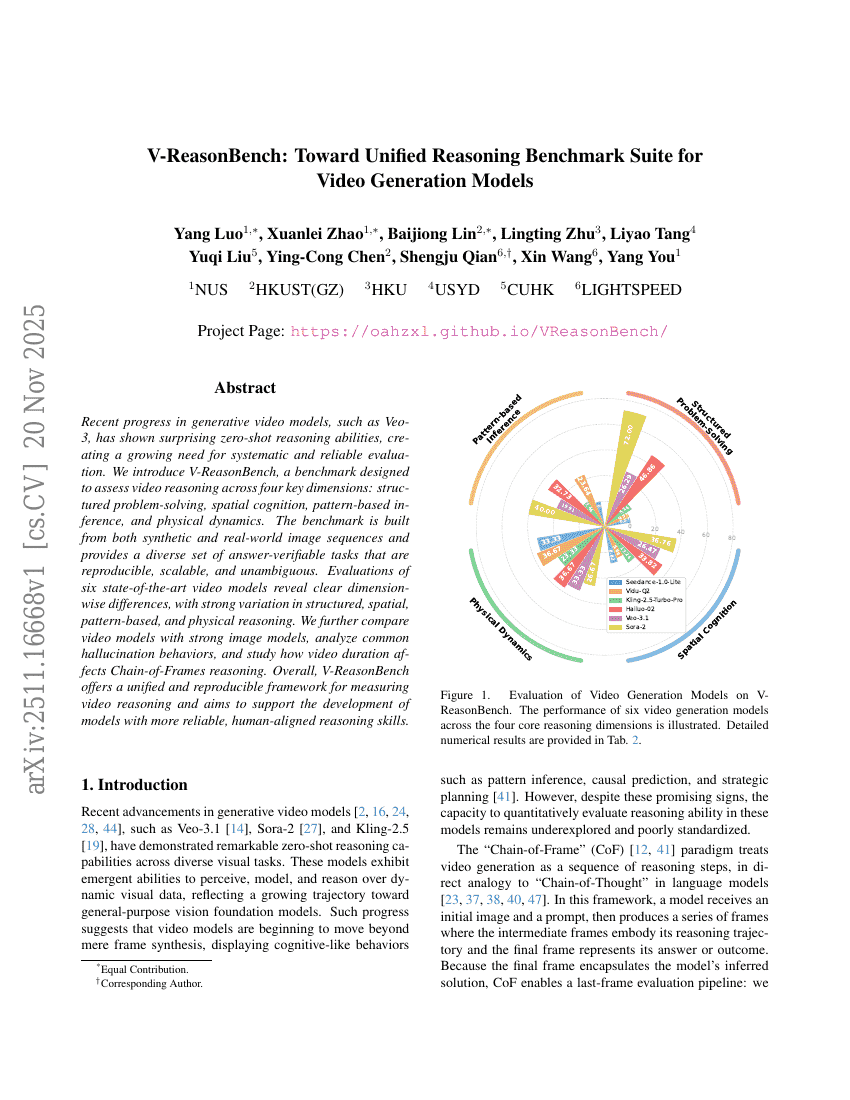
V-ReasonBench:動画生成モデル向け統合推論ベンチマークセットへの道
オルモ3
GPT-5を用いた初期の科学加速実験
医療画像における人工知能のバイアスに対する客観的かつ体系的な評価に向けて
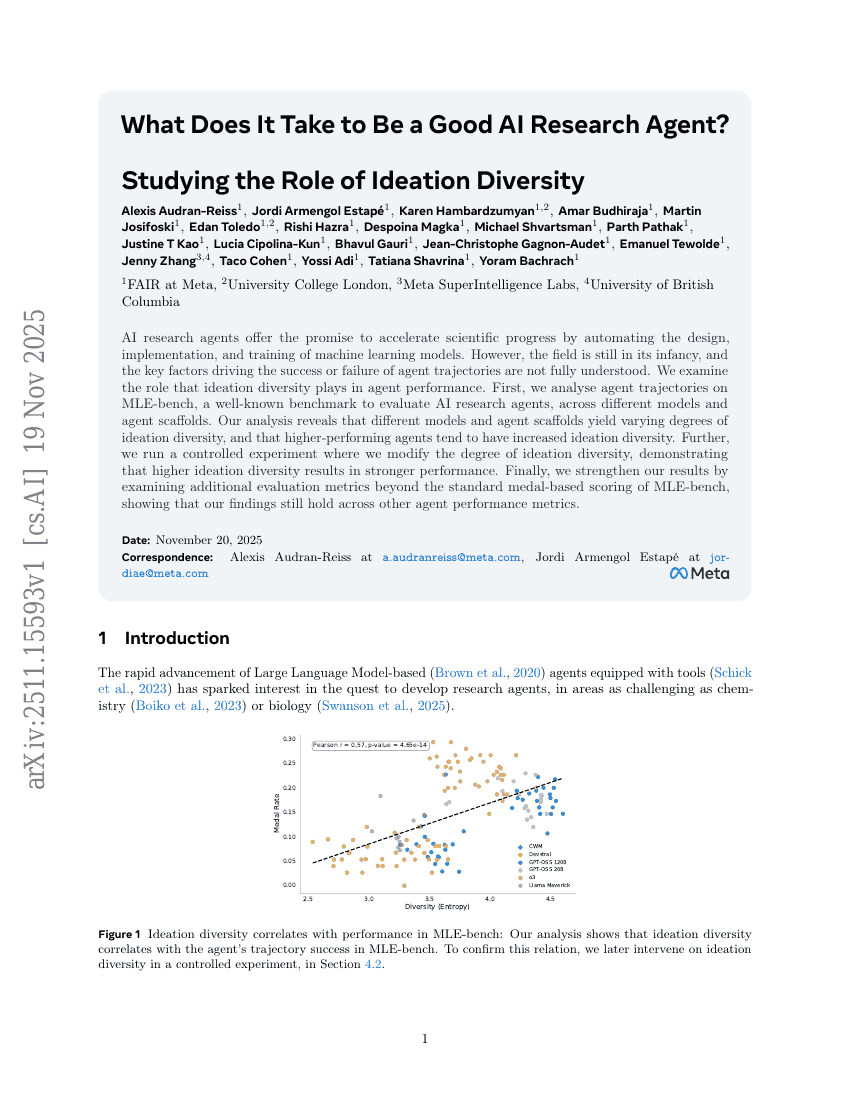
優れたAI研究エージェントとなるために必要なものとは何か?アイデーション多様性の役割を検討する
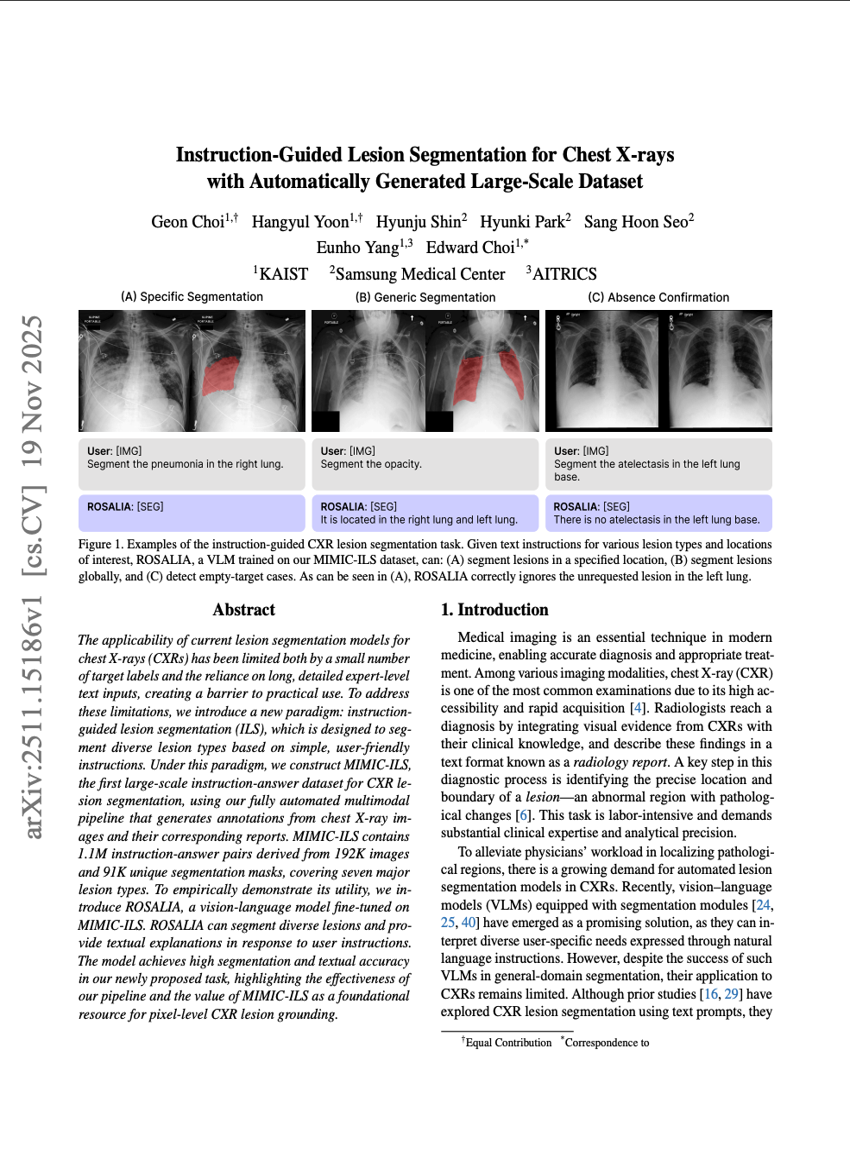
LLMを用いた自動生成大規模データセットを活用した、指示に従う胸部X線画像における病変セグメンテーション
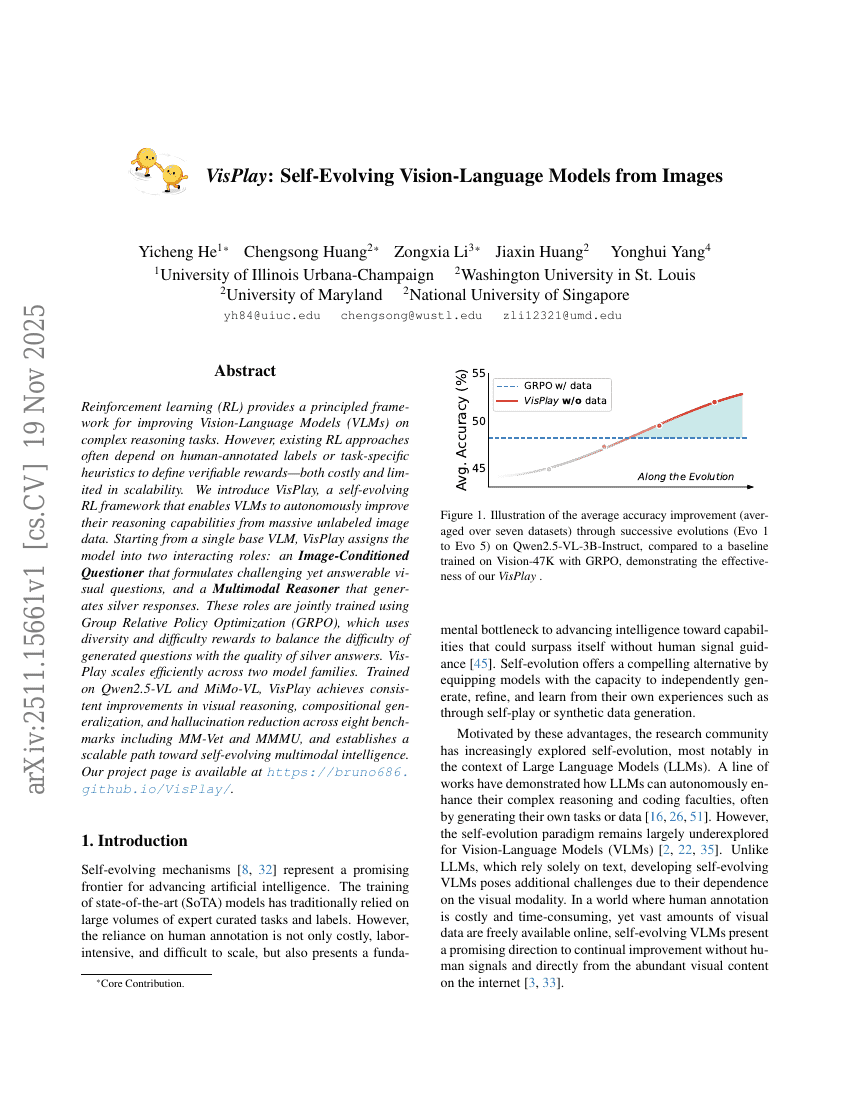
VisPlay:画像から自己進化する視覚言語モデル
ビデオを用いた推論:迷路解法タスクを用いたビデオモデルの推論能力の初めての評価
VIDEOP2R:認知から推論への動画理解
Kandinsky 5.0:画像および動画生成のためのファミリーファウンデーションモデル
JAM-2:高い成功率を示す薬物様抗体の完全計算設計
PathMind:大規模言語モデルを用いた知識グラフ推論のためのRetrieve-Prioritize-Reasonフレームワーク
テキストの内在的次元の解明:学術要旨から創作物語まで
SAM 3:概念を用いたSegment Anything
GeoVista:地理的位置特定のためのWeb拡張型Agent視覚的推論
OpenMMReasoner:オープンかつ汎用的なレシピによるマルチモーダル推論のフロンティアの開拓
HiPO:大規模言語モデルにおける動的推論向けハイブリッド方策最適化
SERES:スパースな視点からの意味認識型ニューラル再構成
SDAR:スケーラブルなシーケンス生成のための相乗効果を持つ拡散-自己回帰パラダイム
MultiPL-MoE:ハイブリッドMixture-of-Expertsによる大規模言語モデルの多プログラミング・多言語拡張
CapRL:強化学習を用いた密集画像記述能力の促進
離散拡散発散指令による超高速言語生成
DisCO:識別的制約最適化を用いた大規模推論モデルの強化
QSVD:低精度視覚言語モデルにおける統合的クエリ・キー・バリュー重み圧縮のための効率的低ランク近似
ネストド・ラーニング:ディープラーニングアーキテクチャの錯覚
SAM 3D:画像内の何でも3D化
Video-as-Answer:Joint-GRPOを用いた次に発生する動画イベントの予測と生成
最初のフレームがビデオコンテンツカスタマイズの最適な場所である
マルチモーダル基礎モデルによる空間知能のスケーリング
Step-Audio-R1 技術報告
V-ReasonBench:動画生成モデル向け統合推論ベンチマークセットへの道
オルモ3
GPT-5を用いた初期の科学加速実験
医療画像における人工知能のバイアスに対する客観的かつ体系的な評価に向けて
優れたAI研究エージェントとなるために必要なものとは何か?アイデーション多様性の役割を検討する
LLMを用いた自動生成大規模データセットを活用した、指示に従う胸部X線画像における病変セグメンテーション
VisPlay:画像から自己進化する視覚言語モデル
ビデオを用いた推論:迷路解法タスクを用いたビデオモデルの推論能力の初めての評価
VIDEOP2R:認知から推論への動画理解
Kandinsky 5.0:画像および動画生成のためのファミリーファウンデーションモデル
JAM-2:高い成功率を示す薬物様抗体の完全計算設計
PathMind:大規模言語モデルを用いた知識グラフ推論のためのRetrieve-Prioritize-Reasonフレームワーク