Command Palette
Search for a command to run...
GeoVista:地理的位置特定のためのWeb拡張型Agent視覚的推論
GeoVista:地理的位置特定のためのWeb拡張型Agent視覚的推論
Yikun Wang Zuyan Liu Ziyi Wang Pengfei Liu Han Hu Yongming Rao
概要
以下は、提供された英文の日本語訳です。科技論文や技術レポートに適した、正式かつ専門的な文体で翻訳いたしました。エージェント型視覚推論に関する近年の研究は、深いマルチモーダル理解を可能にしていますが、主として画像操作ツールに焦点が当てられており、より汎用的なエージェント型モデルの実現には依然として隔たりがあります。本研究では、精緻な視覚的グラウンディング(Visual Grounding)だけでなく、推論プロセスにおいて仮説の検証や精緻化を行うためのWeb検索をも必要とする「地理位置特定(ジオローカリゼーション)」タスクを再考します。既存のジオローカリゼーション・ベンチマークは、高解像度画像の需要や、高度なエージェント型推論における位置特定の課題を満たせていないため、我々は『GeoBench』を構築しました。このベンチマークには、エージェント型モデルの位置特定能力を厳密に評価するために、世界各地の写真やパノラマ画像に加え、様々な都市の衛星画像のサブセットが含まれています。また、推論ループ内でのツール呼び出しをシームレスに統合したエージェント型モデル『GeoVista』を提案します。本モデルには、関心領域(RoI)を拡大するための画像ズームイン・ツールや、関連情報を取得するためのWeb検索ツールが組み込まれています。さらに、GeoVistaのために包括的な学習パイプラインを開発しました。これは、推論パターンとツール使用の事前知識(priors)を学習するためのコールドスタート・教師ありファインチューニング(SFT)段階と、推論能力をさらに強化するための強化学習(RL)段階から構成されます。また、多層的な地理情報を活用し、全体的な位置特定性能を向上させるために、階層的報酬(Hierarchical Reward)を採用しました。実験の結果、GeoVistaはジオローカリゼーションタスクにおいて他のオープンソース・エージェント型モデルを大幅に凌駕し、ほとんどの評価指標においてGemini-2.5-flashやGPT-5といったクローズドソースモデルに匹敵する性能を達成したことが示されました。
Summarization
Fudan University and Tsinghua University, jointly with Tencent Hunyuan, propose GeoVista, an agentic model that integrates tool invocation (image zooming and web searching) with a hierarchical reinforcement learning pipeline, alongside a new benchmark GeoBench, achieving geolocalization performance comparable to leading closed-source models.
Introduction
The rapid evolution of Vision-Language Models (VLMs) has enabled deep multimodal reasoning, where models like OpenAI o3 achieve "thinking with images" by interleaving textual Chain-of-Thought with tool usage. The authors focus on real-world geolocalization, a critical application that naturally demands both fine-grained visual clue extraction and external knowledge validation. However, existing open-source attempts often limit themselves to image manipulation tools (like zooming), forcing models to rely solely on internal knowledge without access to external information retrieval (like web search) to verify hypotheses.
To address this, the authors introduce GeoVista, an agentic multimodal model that seamlessly combines visual operations with web search within a dynamic reasoning loop. They also propose GeoBench, a rigorous benchmark featuring high-resolution global imagery, and establish a comprehensive training pipeline involving cold-start Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL).
Research Highlights:
- Holistic Agentic Framework: GeoVista integrates both visual tools (zoom-in) and information retrieval (web search) to enable dynamic, multi-step reasoning and hypothesis verification similar to advanced closed-source models.
- Challenging Benchmark Construction: The authors propose GeoBench, a dataset comprising high-resolution, globally diverse images designed to rigorously assess geolocalization capabilities through multi-level evaluation.
- Advanced Training Strategy: A complete training pipeline is presented, featuring a cold-start phase based on curated trajectories and an RL stage utilizing Group Relative Policy Optimization (GRPO) with a novel hierarchical reward system to exploit geological label structures.
Dataset
Based on the provided papers, here is a technical overview of the dataset construction and usage strategies employed by the authors:
-
Dataset Overview & Objectives The authors curated GeoBench and the training data for GeoVista with a focus on global distributional diversity. The data collection spans 6 continents, 66 countries, and 108 cities, designed to evaluate general geolocalization capabilities across different data modalities rather than fitting a single data type.
-
Raw Data Composition & Sources To ensure generalizability, the authors collected three distinct types of high-resolution raw data:
- Normal Photos: High-quality images collected from the internet depicting diverse scenarios (e.g., libraries, supermarkets), with a minimum resolution of 1600×1200.
- Panoramas: 360∘ street-view scenes retrieved via the Mapillary API. These were stitched locally into planar panoramas with a fixed resolution of 4096×2048 to suit multimodal LLM inputs.
- Satellite Images: Sentinel-2 Level-2A imagery retrieved from the Microsoft Planetary Computer. The authors mosaicked low-cloud scenes within city bounding boxes, typically sized at 2000×2000.
-
Data Filtering Strategy The authors implemented a Localizability Filtering mechanism to ensure meaningful difficulty by removing two specific categories of data:
- Non-localizable images: Generic scenes lacking geographical clues (e.g., close-up food, indoor rooms, plain landscapes).
- Easily localizable landmarks: Iconic sites likely encountered during VLM pretraining, which would trivialize the reasoning task.
-
Benchmark Statistics The final GeoBench dataset comprises a balanced set of samples sampled from the raw data:
- 512 Standard Photos
- 512 Panoramas
- 108 Satellite Images
-
Metadata & Evaluation Framework
- Automated Labeling: Each sample is paired with precise geolocalization metadata (latitude and longitude).
- Multi-level Annotation: The authors developed labels for Country, Province/State, and City levels to support a hybrid verification pipeline using both rule-based matching and model-based verification (via GPT-4o-mini).
- Nuanced Evaluation: For fine-grained assessment, the authors utilize geocoding services to convert predicted text into coordinates, calculating the Haversine distance between the prediction and ground truth.
Method
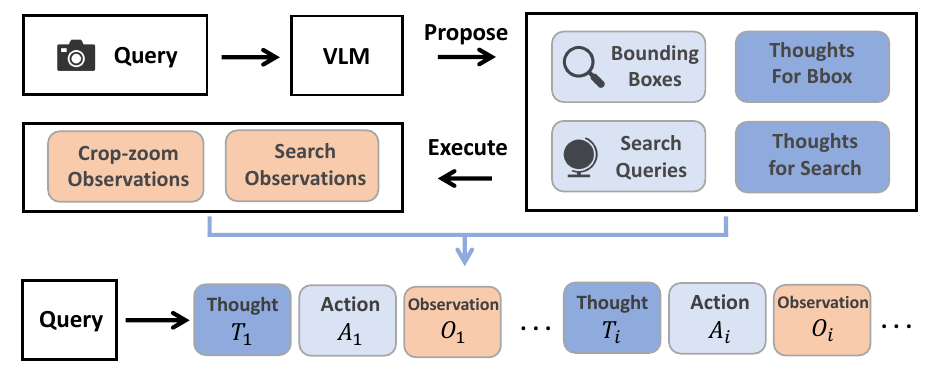
The proposed system, GeoVista, employs an agentic pipeline to perform real-world geolocalization by iteratively reasoning and interacting with the environment. Given a user query and an input image, the policy model generates a sequence of thoughts and actions, which are executed to obtain new observations. These observations are then fed back into the model, forming a continuous thought–action–observation loop. The process terminates when the model decides to output its final geolocation prediction or reaches the maximum number of interaction turns. The policy model has access to two types of tools: a crop-and-zoom tool, which allows it to magnify regions of interest by specifying a bounding box in pixel coordinates, and a web-search tool, which enables it to retrieve up to 10 relevant information sources from the internet based on a generated query. This enables the model to refine its understanding through both visual inspection and external knowledge retrieval. The agentic pipeline is illustrated in the framework diagram, where the policy model processes the user query and iteratively generates actions and observations, with the environment providing feedback through the execution of these actions.

To facilitate the training of the policy model, the authors introduce a cold-start phase that curates reasoning trajectories to provide the model with a prior for multi-turn tool use. Inspired by human geolocalization strategies—where individuals first identify candidate regions and then consult external sources—the authors use a vision-language model (Seed-1.6-vision) to generate multiple bounding boxes and intermediate reasoning steps. After identifying salient geographic cues, the model is prompted to generate web-search queries along with rationales, and finally, to produce a reasoning path leading to a final judgment. These reasoning steps, bounding boxes, and search queries are then assembled into a coherent thinking trajectory with tool calls. This curated dataset of 2,000 examples serves as a supervised fine-tuning signal to encourage the model to engage in multi-turn reasoning and tool use. The process of curating these thinking trajectories is depicted in the figure, where the left panel shows the generation of tool calls and rationales, and the right panel compares the performance of GeoVista with and without the hierarchical reward.
The policy model is trained using reinforcement learning, specifically a vanilla GRPO (Generalized Reward Policy Optimization) setting. In this setup, each question is passed to the policy model, which generates a group of outputs. Rewards are computed based on the correctness of the response, with the optimization objective defined as a clipped surrogate objective that maximizes the expected reward while maintaining policy stability. The reward function is designed to leverage the hierarchical structure of the geolocalization task, where correct answers at finer administrative levels (e.g., city) receive higher rewards than those at coarser levels (e.g., country). Specifically, the reward is defined as ri=β2 for city-level correctness, β for provincial/state-level correctness, 1 for country-level correctness, and 0 otherwise, with β>1. This hierarchical reward structure ensures that the model is incentivized to make precise predictions. The authors empirically set β=2 to balance the reward gaps and prevent excessive or collapsed rewards. The reinforcement learning process is computationally expensive due to the need for multiple response rollouts and web search API usage, which limits the exploration of different β values. The overall training process involves the policy model generating a sequence of thoughts, actions, and observations, which are then used to update the model parameters through reinforcement learning.
Experiment
- Conducted comprehensive evaluations on the GeoBench dataset, comparing GeoVista-7B against leading closed-source systems (e.g., Gemini-2.5-pro, GPT-5) and open-source vision-reasoning models (e.g., Qwen2.5-VL, Mini-o3) to verify geolocalization capabilities.
- Achieved state-of-the-art performance among open-source models, recording 92.64% country-level, 79.60% provincial-level, and 72.68% city-level accuracy, significantly outperforming the base model Qwen2.5-VL-7B (32.57% city accuracy) and narrowing the gap with closed-source counterparts.
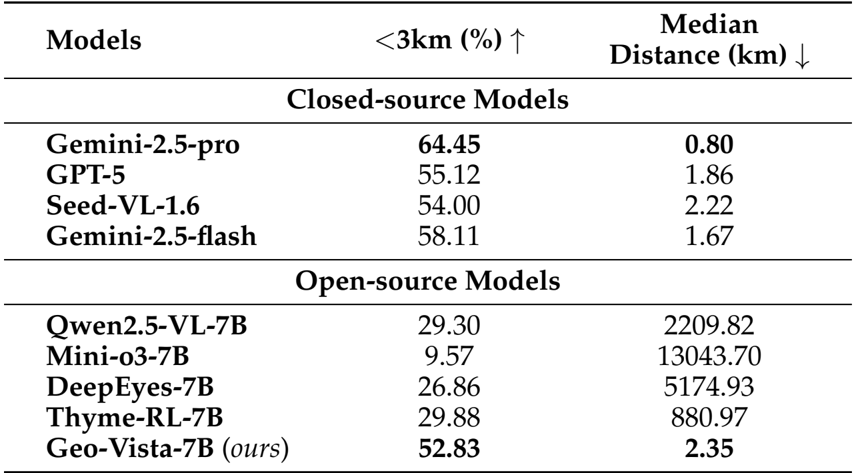
- Demonstrated high-precision reasoning with a median haversine distance of 2.35 km and a 52.83% success rate for predictions within 3 km, vastly superior to other open-source baselines (e.g., Qwen2.5-VL with >2000 km median error).
- Validated the training methodology through ablation studies, confirming the critical necessity of Cold-Start SFT, Reinforcement Learning, and Hierarchical Reward, while observing a consistent log-linear performance improvement as RL training data scaled from 1.5k to 12k samples.
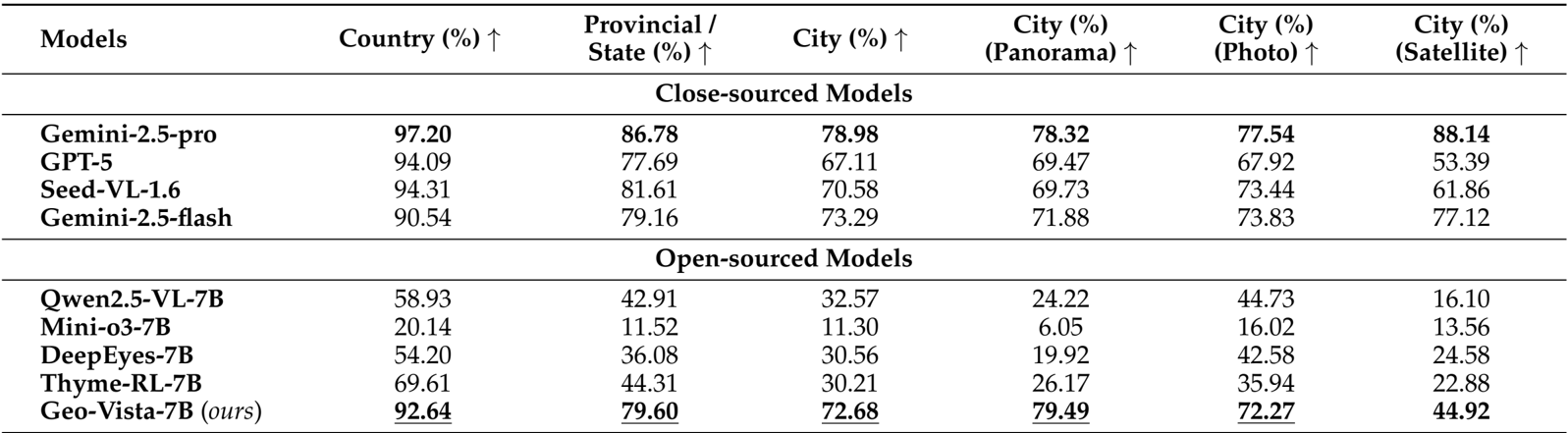
The experimental results on GeoBench demonstrate that GeoVista achieves state-of-the-art performance among open-source models, significantly outperforming other 7B-parameter models across all evaluation metrics. It attains high accuracy at country, provincial, and city levels, with particularly strong performance on panoramas and photos, while also showing competitive nuanced geolocation precision, as measured by the proportion of predictions within 3 km and median haversine distance.
Authors compare GeoVista with both closed-source and open-source models on GeoBench, showing that GeoVista achieves state-of-the-art performance among open-source models, with accuracy surpassing all other open-source counterparts in country, provincial, and city-level geolocalization tasks. It also outperforms most open-source models on city-level accuracy across panorama, photo, and satellite image types, demonstrating strong generalization and reasoning capabilities despite having fewer parameters than closed-source models.
Authors present a nuanced evaluation of model performance on GeoBench, reporting the proportion of predictions within 3 km and the median haversine distance. Results show that GeoVista achieves the highest accuracy within 3 km (52.83%) and the lowest median distance (2.35 km) among open-source models, significantly outperforming others. While still behind Gemini-2.5-pro in both metrics, GeoVista demonstrates strong geolocalization precision, indicating effective reasoning and tool use despite its smaller size.
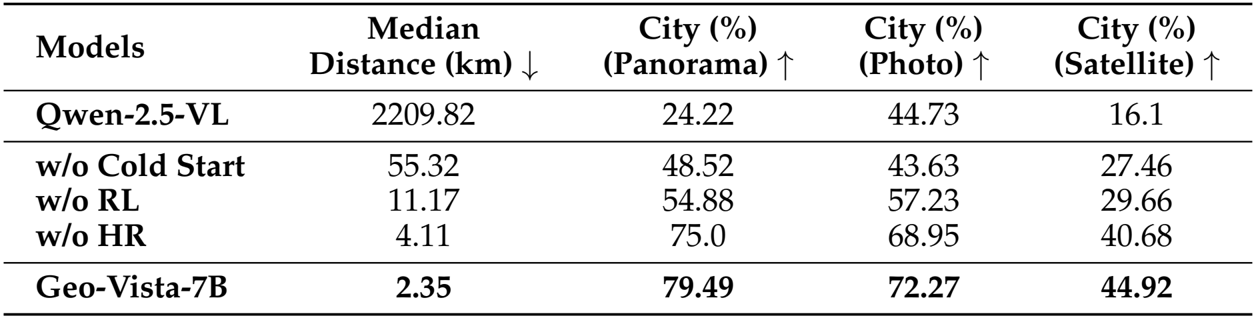
Authors conducted an ablation study to evaluate the impact of key components in the training pipeline, with results presented in the table. The model without cold-start SFT shows a significant drop in performance, indicating its necessity for enabling multi-turn tool use. Removing reinforcement learning leads to a substantial increase in median distance and a decrease in city-level accuracy, demonstrating that SFT alone is insufficient for effective reasoning. Disabling the hierarchical reward further degrades performance, highlighting its importance in guiding the model toward accurate geolocalization. The full Geo-Vista-7B model achieves the best results across all metrics, with a median distance of 2.35 km and high city-level accuracy on panoramas, photos, and satellite images.