HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

iMontage:統合的で多様性に富み、非常に動的な多対多画像生成

Agent0-VL:ツール統合型視覚言語推論における自己進化型エージェントの探求




























iMontage:統合的で多様性に富み、非常に動的な多対多画像生成
Agent0-VL:ツール統合型視覚言語推論における自己進化型エージェントの探求
MedSAM3:医療概念を用いたSegment Anythingの探求
SteadyDancer:最初フレーム保持を伴う調和的で一貫性のある人間画像アニメーション
GigaEvo:LLM および進化アルゴリズムによって駆動されるオープンソース最適化フレームワーク
確率的経路積分を用いた忠実度を考慮した推薦説明
推薦システムにおけるインタラクションを考慮した単義的概念の抽出
MSRNet:偽装物体検出のためのマルチスケール再帰的ネットワーク
予算考慮型のツール利用は効果的なAgentスケーリングを可能にする
動画内指示:生成制御としての視覚信号
DR Tulu:深層リサーチのための進化的ルーブリックを用いた強化学習
AICC:HTML解析の精緻化とモデル性能の向上 —— モデルベースのHTMLパーサーにより構築された7.3TのAI-Readyコーパス
UltraFlux:多様なアスペクト比に対応した高品質なネイティブ4Kテキスト画像生成のためのデータ・モデル協調設計
DeCo:エンドツーエンド画像生成のための周波数分離ピクセル拡散
生成的ユーザーインターフェースの判定者としてのComputer-Use Agent
AutoEnv:環境横断的なAgent学習を測定するための自動化環境
ディープ・リサーチに基づく一般的なエージェント型メモリ
VIRAL:人型ロボットの運動操作におけるスケールアップ型視覚シミュレーションから現実への展開
MIST:教師あり学習による相互情報量
マルチエージェント深層調査:M-GRPOによるマルチエージェントシステムのトレーニング
データなしのフローマップ蒸留
Docling: AI駆動のドキュメント変換のための効率的なオープンソースツールキット
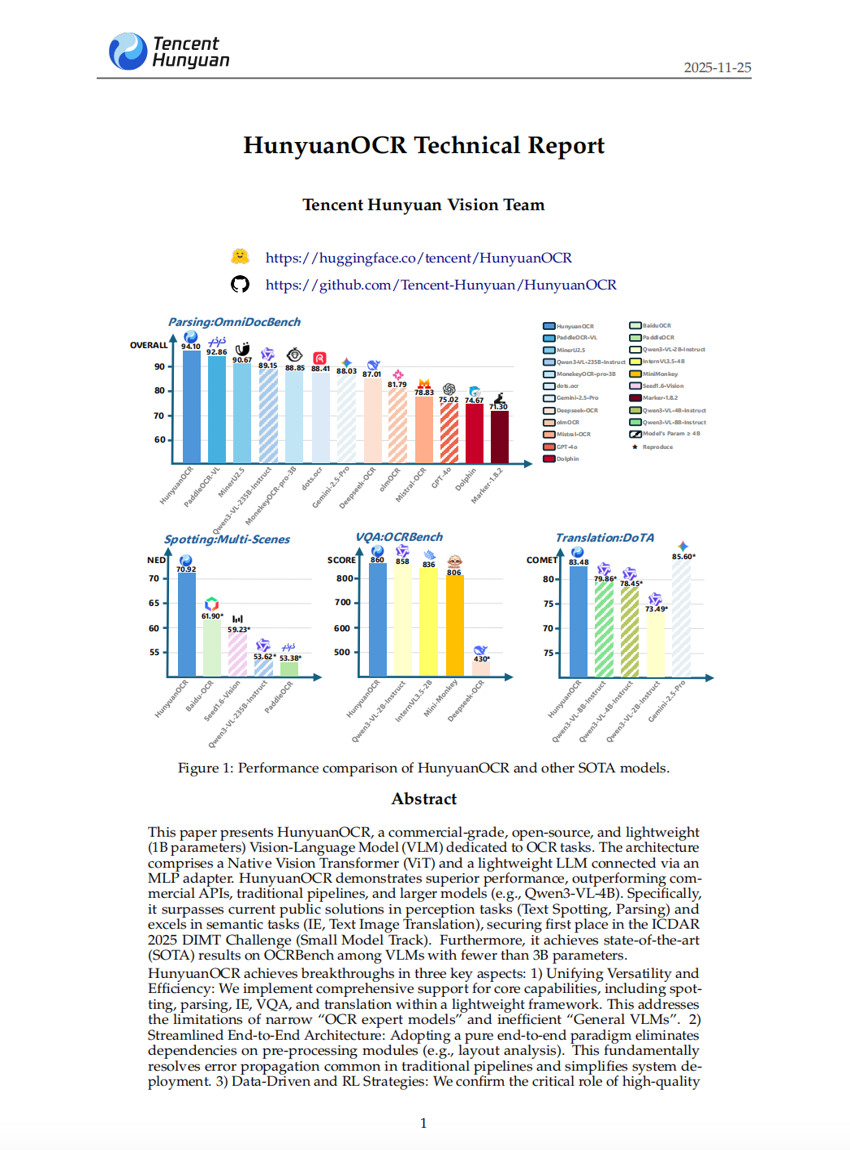
フニエンOCR 技術報告
PhysToolBench:MLLMsにおける物理ツール理解のベンチマーク
ハクスリー・ゲーデル機械:最適自己改善機械の近似による人間レベルのコーディングエージェントの開発
空間的超感応を用いずに空間的超感応を解く
Parrot:出力の真実性に対する説得および同意への頑健性評価——LLMsのための迎合性頑健性ベンチマーク
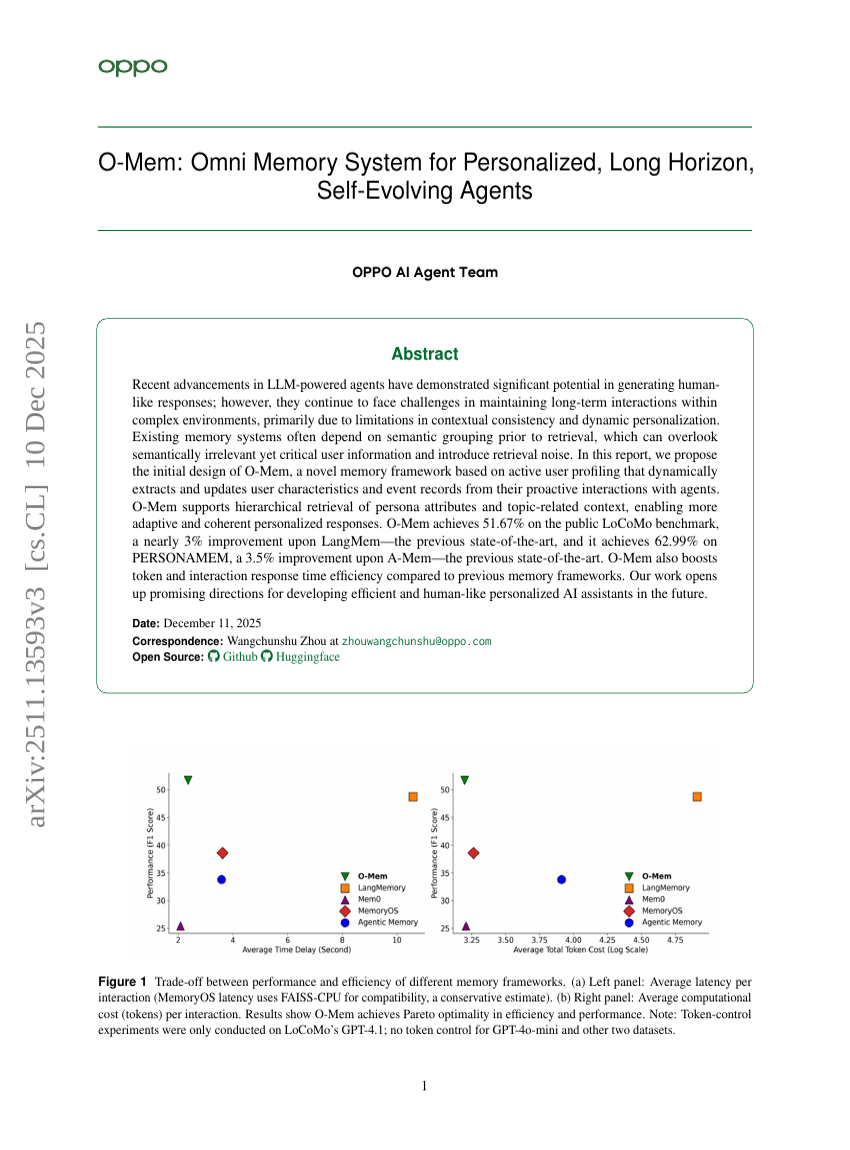
O-Mem: 個人化された長期自律進化するAgentのための包括的メモリシステム
テキストの内在的次元の解明:学術要旨から創作物語まで
SAM 3:概念を用いたSegment Anything
GeoVista:地理的位置特定のためのWeb拡張型Agent視覚的推論
OpenMMReasoner:オープンかつ汎用的なレシピによるマルチモーダル推論のフロンティアの開拓
MedSAM3:医療概念を用いたSegment Anythingの探求
SteadyDancer:最初フレーム保持を伴う調和的で一貫性のある人間画像アニメーション
GigaEvo:LLM および進化アルゴリズムによって駆動されるオープンソース最適化フレームワーク
確率的経路積分を用いた忠実度を考慮した推薦説明
推薦システムにおけるインタラクションを考慮した単義的概念の抽出
MSRNet:偽装物体検出のためのマルチスケール再帰的ネットワーク
予算考慮型のツール利用は効果的なAgentスケーリングを可能にする
動画内指示:生成制御としての視覚信号
DR Tulu:深層リサーチのための進化的ルーブリックを用いた強化学習
AICC:HTML解析の精緻化とモデル性能の向上 —— モデルベースのHTMLパーサーにより構築された7.3TのAI-Readyコーパス
UltraFlux:多様なアスペクト比に対応した高品質なネイティブ4Kテキスト画像生成のためのデータ・モデル協調設計
DeCo:エンドツーエンド画像生成のための周波数分離ピクセル拡散
生成的ユーザーインターフェースの判定者としてのComputer-Use Agent
AutoEnv:環境横断的なAgent学習を測定するための自動化環境
ディープ・リサーチに基づく一般的なエージェント型メモリ
VIRAL:人型ロボットの運動操作におけるスケールアップ型視覚シミュレーションから現実への展開
MIST:教師あり学習による相互情報量
マルチエージェント深層調査:M-GRPOによるマルチエージェントシステムのトレーニング
データなしのフローマップ蒸留
Docling: AI駆動のドキュメント変換のための効率的なオープンソースツールキット
フニエンOCR 技術報告
PhysToolBench:MLLMsにおける物理ツール理解のベンチマーク
ハクスリー・ゲーデル機械:最適自己改善機械の近似による人間レベルのコーディングエージェントの開発
空間的超感応を用いずに空間的超感応を解く
Parrot:出力の真実性に対する説得および同意への頑健性評価——LLMsのための迎合性頑健性ベンチマーク
O-Mem: 個人化された長期自律進化するAgentのための包括的メモリシステム
テキストの内在的次元の解明:学術要旨から創作物語まで
SAM 3:概念を用いたSegment Anything
GeoVista:地理的位置特定のためのWeb拡張型Agent視覚的推論
OpenMMReasoner:オープンかつ汎用的なレシピによるマルチモーダル推論のフロンティアの開拓