HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

幾何制約付きエージェントによる空間推論
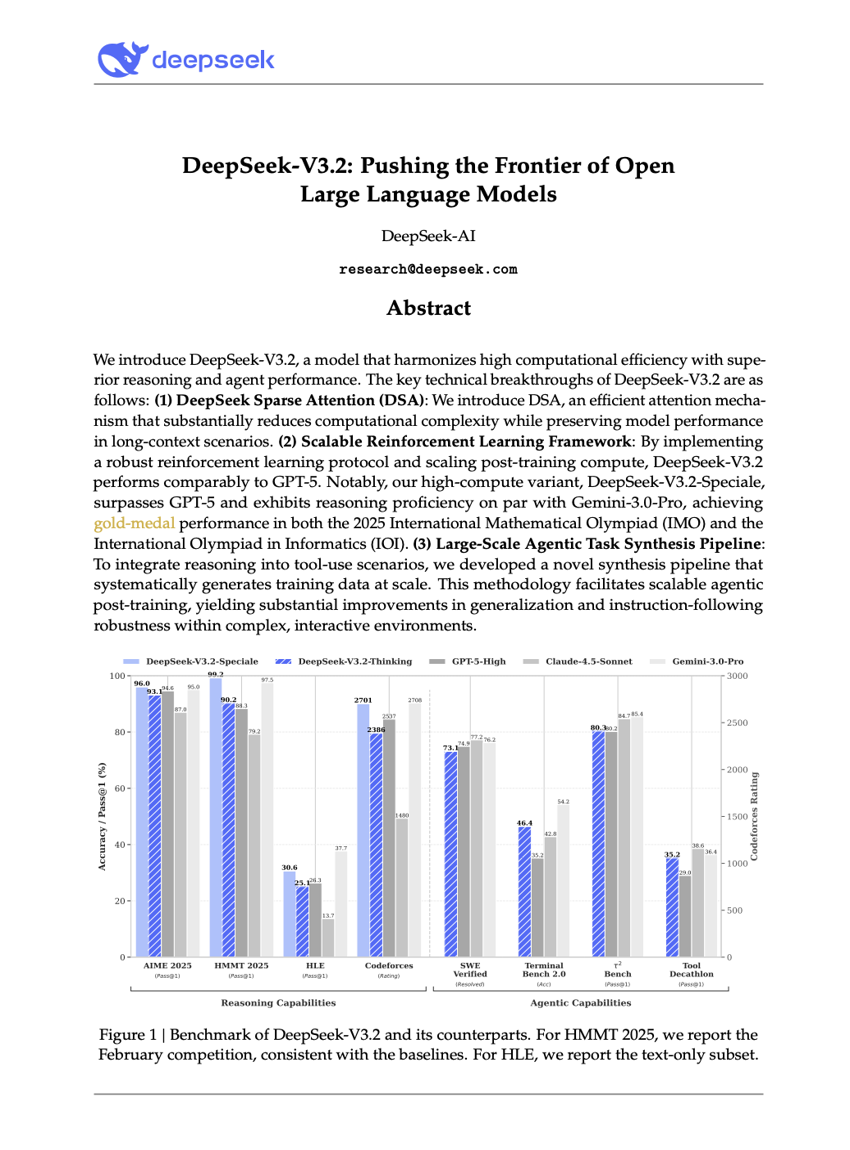
DeepSeek-V3.2:オープン型大規模言語モデルの限界を押し広げる





























幾何制約付きエージェントによる空間推論
DeepSeek-V3.2:オープン型大規模言語モデルの限界を押し広げる
DiP:ピクセル空間における拡散モデルの制御
アーキテクチャの分離は、統合型マルチモーダルモデルにとって必要なすべてではない
スケールにおけるビジョンブリッジトランスフォーマー
AnyTalker:インタラクティビティ精 refinement を用いたマルチペルソントーキング動画生成のスケーラビリティ向上
REASONEDIT:推論強化型画像編集モデルへの道標
OpenApps:環境変動のシミュレーションによるUIエージェントの信頼性評価
Qwen3-VL 技ical Report
G2VLM:統一的3D再構成と空間推論を備えた幾何学的根拠付き視覚言語モデル
マルチクリット:多様な基準に従うためのマルチモーダル・ジャッジのベンチマーク評価
MIRA:画像編集のための多モーダル反復推論エージェント
ENACT:エゴセントリックな相互作用のワールドモデリングを用いた身体化認知の評価
キャンバスから画像へ:マルチモーダル制御を用いた構成画像生成
ビデオ生成モデルは優れた潜在報酬モデルである
DeepSeekMath-V2:自己検証可能な数学的推論へ向けて
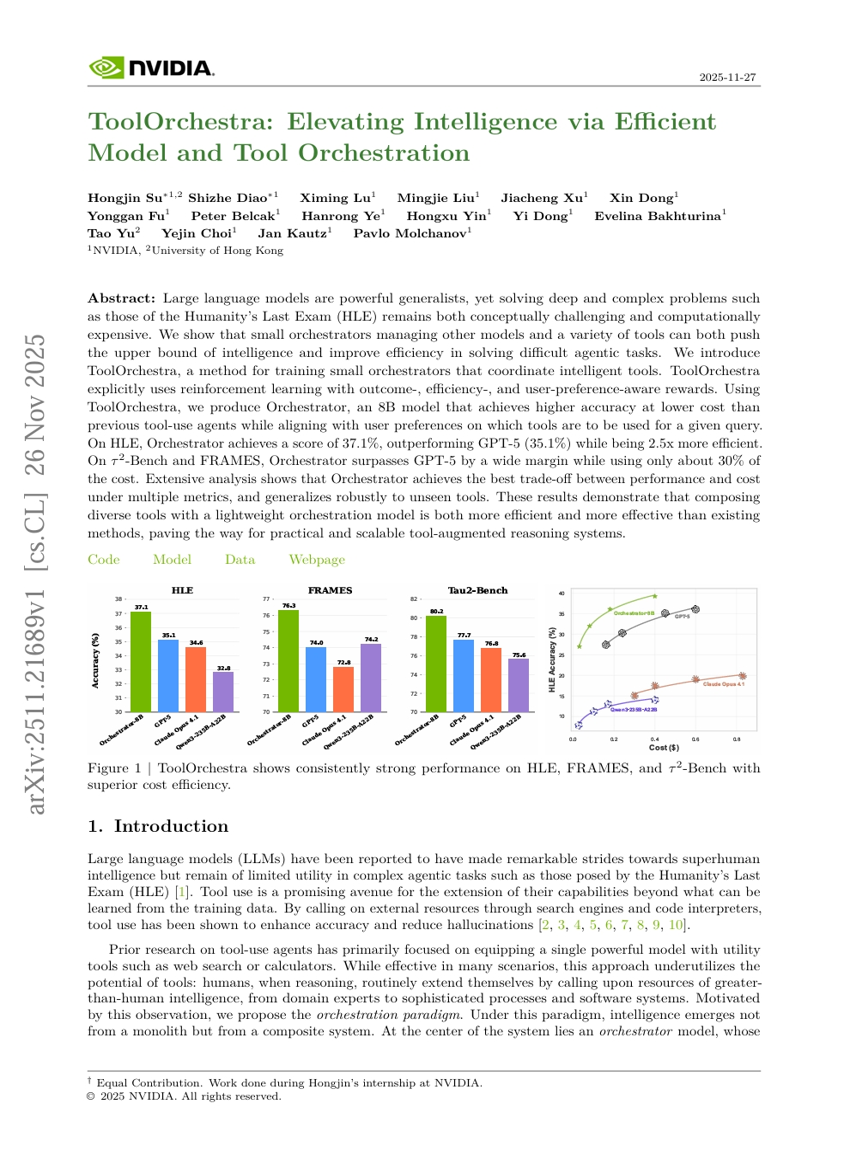
ToolOrchestra:効率的なモデルおよびツールのオーケストレーションによる知能の向上
視覚的に考える、文章的に推論する:ARCにおける視覚言語連携
ハーモニー:クロストラスクシンエジーによる音声と動画生成の調和
Inferix:世界シミュレーション向け次世代推論エンジンとしてのブロックディフュージョンベースのアーキテクチャ
マルチエージェントシステムにおける潜在的協働
ロシア語アーキテクチャのマルチモーダル評価
ROOT: ニューラルネットワーク学習のためのロバスト直交化最適化手法
重ね合わせが堅牢なニューラルスケーリングをもたらす
伝達型オンライン学習における最適な誤りバウンド
強化学習は、ベースモデルを超えて大規模言語モデルの推論能力を本当にインセンティブ化するのか?
拡散モデルが記憶しない理由:トレーニングにおける陰伏的ダイナミカル正則化の役割
自己教師付き強化学習における1000層ネットワーク:深さの拡張が新たなゴール到達能力を可能にする
ゲート付きアテンションによる大規模言語モデル:非線形性、スパース性、およびアテンションシンクフリー
人工ハーモニクス:言語モデルの無限に続く均質性(それ以上)
超大規模における進化戦略
統一型マルチモーダルモデルにおける理解が生成に与える影響は何か?分析から先進的な道筋へ
DiP:ピクセル空間における拡散モデルの制御
アーキテクチャの分離は、統合型マルチモーダルモデルにとって必要なすべてではない
スケールにおけるビジョンブリッジトランスフォーマー
AnyTalker:インタラクティビティ精 refinement を用いたマルチペルソントーキング動画生成のスケーラビリティ向上
REASONEDIT:推論強化型画像編集モデルへの道標
OpenApps:環境変動のシミュレーションによるUIエージェントの信頼性評価
Qwen3-VL 技ical Report
G2VLM:統一的3D再構成と空間推論を備えた幾何学的根拠付き視覚言語モデル
マルチクリット:多様な基準に従うためのマルチモーダル・ジャッジのベンチマーク評価
MIRA:画像編集のための多モーダル反復推論エージェント
ENACT:エゴセントリックな相互作用のワールドモデリングを用いた身体化認知の評価
キャンバスから画像へ:マルチモーダル制御を用いた構成画像生成
ビデオ生成モデルは優れた潜在報酬モデルである
DeepSeekMath-V2:自己検証可能な数学的推論へ向けて
ToolOrchestra:効率的なモデルおよびツールのオーケストレーションによる知能の向上
視覚的に考える、文章的に推論する:ARCにおける視覚言語連携
ハーモニー:クロストラスクシンエジーによる音声と動画生成の調和
Inferix:世界シミュレーション向け次世代推論エンジンとしてのブロックディフュージョンベースのアーキテクチャ
マルチエージェントシステムにおける潜在的協働
ロシア語アーキテクチャのマルチモーダル評価
ROOT: ニューラルネットワーク学習のためのロバスト直交化最適化手法
重ね合わせが堅牢なニューラルスケーリングをもたらす
伝達型オンライン学習における最適な誤りバウンド
強化学習は、ベースモデルを超えて大規模言語モデルの推論能力を本当にインセンティブ化するのか?
拡散モデルが記憶しない理由:トレーニングにおける陰伏的ダイナミカル正則化の役割
自己教師付き強化学習における1000層ネットワーク:深さの拡張が新たなゴール到達能力を可能にする
ゲート付きアテンションによる大規模言語モデル:非線形性、スパース性、およびアテンションシンクフリー
人工ハーモニクス:言語モデルの無限に続く均質性(それ以上)
超大規模における進化戦略
統一型マルチモーダルモデルにおける理解が生成に与える影響は何か?分析から先進的な道筋へ