HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

SAC Flow:速度再パラメータ化による逐次モデル化を用いたサンプル効率の良い流れに基づく方策の強化学習

特徴最適アライメントを用いたクローズドソースMLLMに対する敵対的攻撃

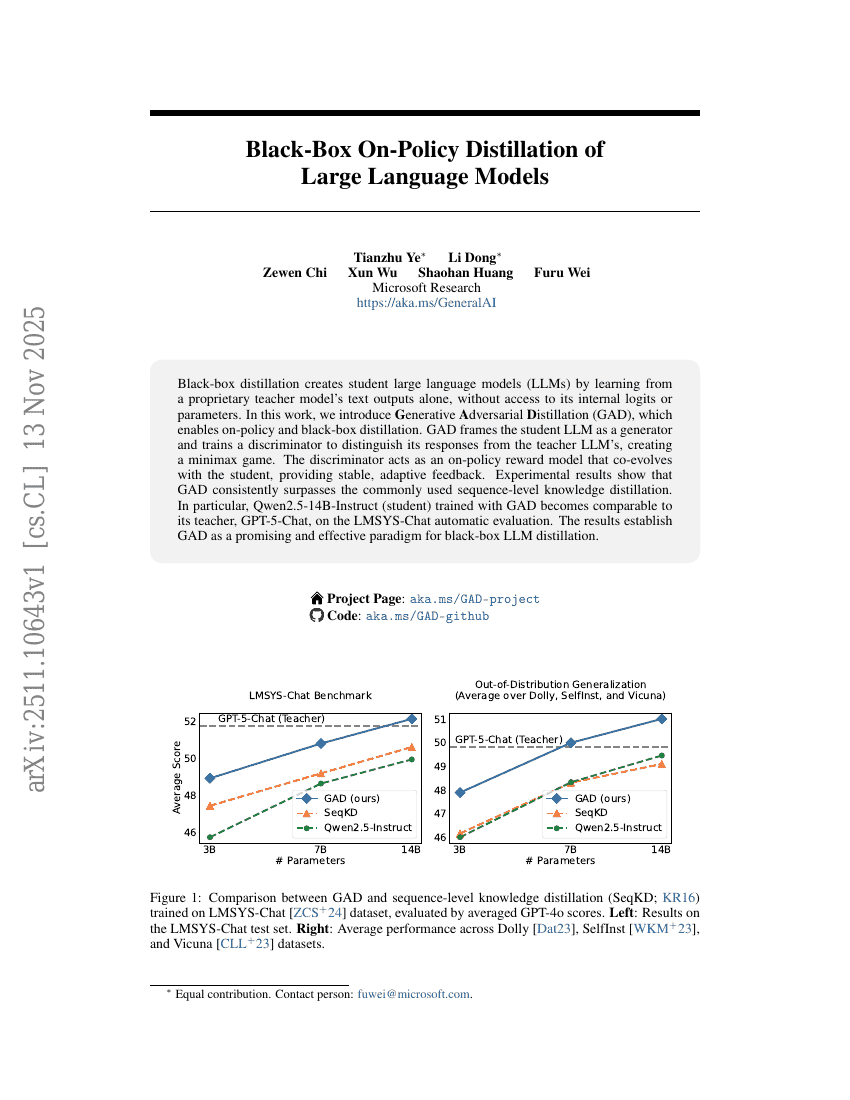



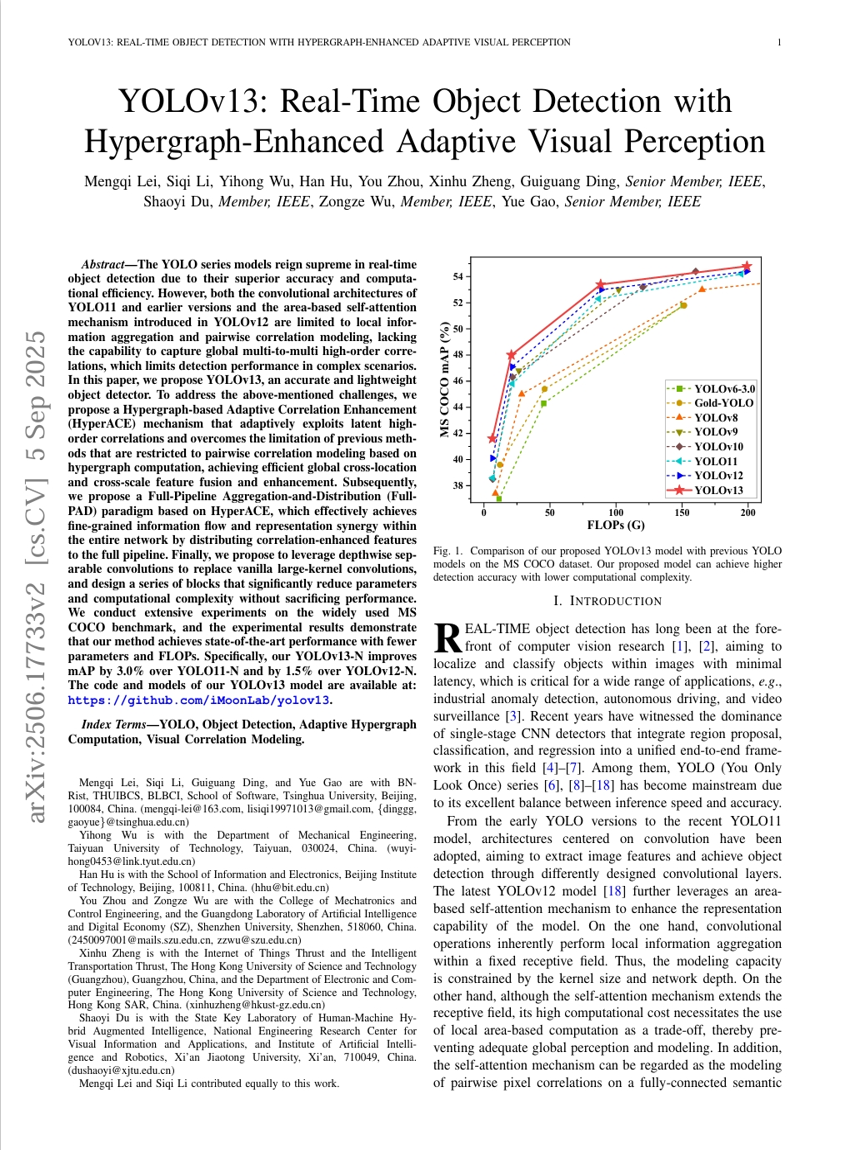
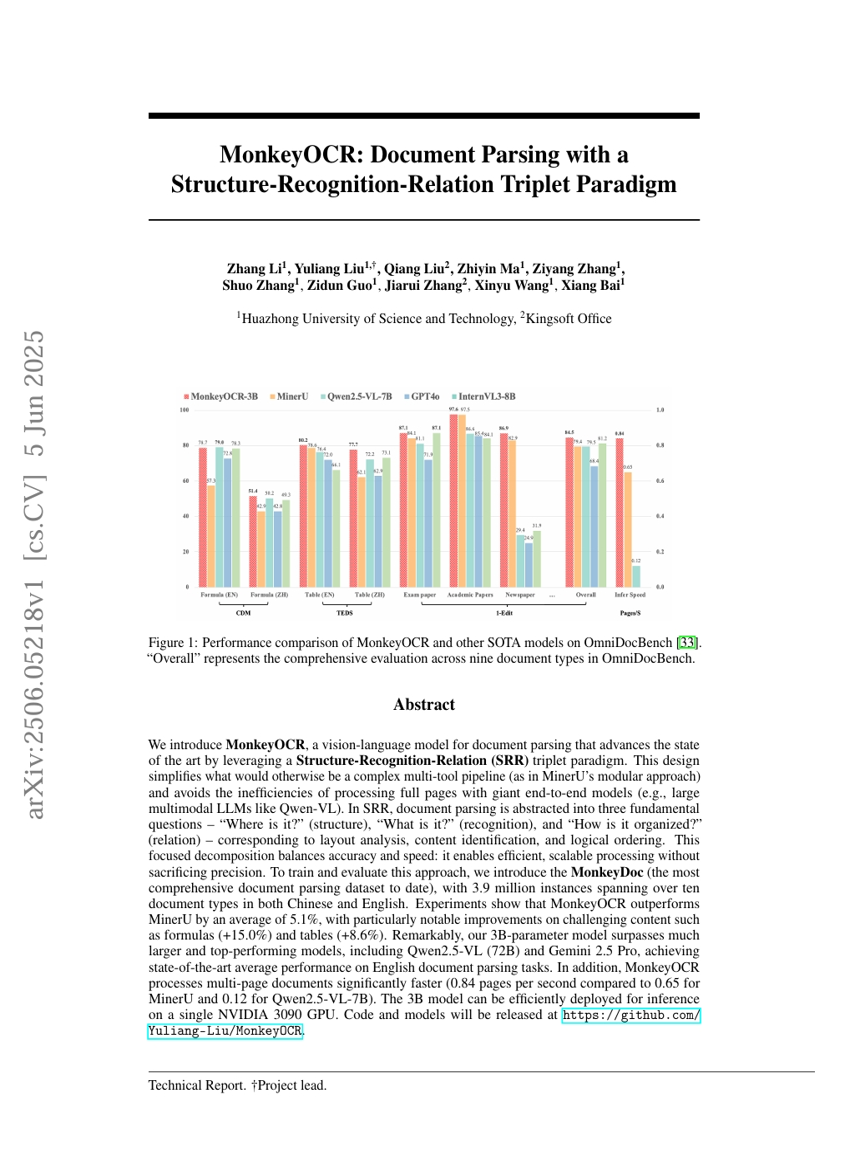























SAC Flow:速度再パラメータ化による逐次モデル化を用いたサンプル効率の良い流れに基づく方策の強化学習
特徴最適アライメントを用いたクローズドソースMLLMに対する敵対的攻撃
Hail to the Thief: 分散型GRPOにおける攻撃と防御の探求
ブラックボックス・オンポリシー distillation による大規模言語モデルの学習
UniVA:オープンソース次世代動画汎用型エージェントへの道
PAN:汎用的、インタラクティブな、長期ホライゾン世界シミュレーションを実現する世界モデル
潜在空間における一歩、ピクセルにおける飛躍的進歩:あなたの拡散モデル向け高速潜在上位化アダプタ
YOLOv13:ハイパーグラフ強化型適応型視覚認識を用いたリアルタイム物体検出
MonkeyOCR:構造認識関係三重項パラダイムを用いたドキュメント解析
安全な生成AIのためのコンセンサスサンプリング
Argus:エンドツーエンドADS向けレジリエンス指向型セーフティアサランスフレームワーク
WMPO:視覚言語行動モデルにおける世界モデルに基づく方策最適化
LoopTool:堅牢なLLMツール呼び出しのためのデータ-トレーニングループの閉じ方
事実検索を超えて:生成的意味空間を用いたRAGにおけるエピソード記憶
TiDAR:拡散で考える、自己回帰で話す
Time-to-Move:二時計同期ノイズ除去を用いた訓練不要なモーション制御動画生成
ルミネ:3Dオープンワールドにおける汎用エージェント構築のためのオープンレシピ
1,000語から画像を生成する:構造化キャプションを用いたテキストから画像生成の向上
KLASS:マスク付き拡散モデルにおけるKLガイド付き高速推論
人間の示範に基づくコンピュータ利用エージェントの基盤化
Wasm:構造化アラビア語混合マルチモーダルコーパス構築のためのパイプライン
会話システムにおける適応型マルチエージェント応答精緻化
SPAN:モノクローラル3次元オブジェクト検出のための空間投影アライメント
高次元システムにおけるボルテラ級数の効率的近似
SofT-GRPO:Gumbel再パラメータ化によるソフト・シンキング方策最適化を用いた離散トークンLMM強化学習の超越
RedOne 2.0:ソーシャルネットワーキングサービスにおけるドメイン固有LLMのポストトレーニングの再考
ステーション:AI駆動型発見のためのオープンワールド環境
DRIVE:競争的コード生成における検証可能報酬を用いた強化学習のためのデータ管理最適実践
IterResearch:マコフ型状態再構成による長期視野エージェントの再考
HaluMem:エージェントの記憶システムにおける幻覚の評価
GVPO:大規模言語モデル微調整のためのグループ分散方策最適化
ReCA:リアルタイムかつ効率的な協調型身体的自律エージェントのための統合的加速手法
Hail to the Thief: 分散型GRPOにおける攻撃と防御の探求
ブラックボックス・オンポリシー distillation による大規模言語モデルの学習
UniVA:オープンソース次世代動画汎用型エージェントへの道
PAN:汎用的、インタラクティブな、長期ホライゾン世界シミュレーションを実現する世界モデル
潜在空間における一歩、ピクセルにおける飛躍的進歩:あなたの拡散モデル向け高速潜在上位化アダプタ
YOLOv13:ハイパーグラフ強化型適応型視覚認識を用いたリアルタイム物体検出
MonkeyOCR:構造認識関係三重項パラダイムを用いたドキュメント解析
安全な生成AIのためのコンセンサスサンプリング
Argus:エンドツーエンドADS向けレジリエンス指向型セーフティアサランスフレームワーク
WMPO:視覚言語行動モデルにおける世界モデルに基づく方策最適化
LoopTool:堅牢なLLMツール呼び出しのためのデータ-トレーニングループの閉じ方
事実検索を超えて:生成的意味空間を用いたRAGにおけるエピソード記憶
TiDAR:拡散で考える、自己回帰で話す
Time-to-Move:二時計同期ノイズ除去を用いた訓練不要なモーション制御動画生成
ルミネ:3Dオープンワールドにおける汎用エージェント構築のためのオープンレシピ
1,000語から画像を生成する:構造化キャプションを用いたテキストから画像生成の向上
KLASS:マスク付き拡散モデルにおけるKLガイド付き高速推論
人間の示範に基づくコンピュータ利用エージェントの基盤化
Wasm:構造化アラビア語混合マルチモーダルコーパス構築のためのパイプライン
会話システムにおける適応型マルチエージェント応答精緻化
SPAN:モノクローラル3次元オブジェクト検出のための空間投影アライメント
高次元システムにおけるボルテラ級数の効率的近似
SofT-GRPO:Gumbel再パラメータ化によるソフト・シンキング方策最適化を用いた離散トークンLMM強化学習の超越
RedOne 2.0:ソーシャルネットワーキングサービスにおけるドメイン固有LLMのポストトレーニングの再考
ステーション:AI駆動型発見のためのオープンワールド環境
DRIVE:競争的コード生成における検証可能報酬を用いた強化学習のためのデータ管理最適実践
IterResearch:マコフ型状態再構成による長期視野エージェントの再考
HaluMem:エージェントの記憶システムにおける幻覚の評価
GVPO:大規模言語モデル微調整のためのグループ分散方策最適化
ReCA:リアルタイムかつ効率的な協調型身体的自律エージェントのための統合的加速手法