HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

DexFlyWheel:多指灵巧操作向けスケーラブルかつ自己改善型データ生成フレームワーク

NovaFlow:生成動画からの行動可能フローを用いたゼロショット操作



























DexFlyWheel:多指灵巧操作向けスケーラブルかつ自己改善型データ生成フレームワーク
NovaFlow:生成動画からの行動可能フローを用いたゼロショット操作
TreeSynth:木構造を用いた部分空間分割による新規多様なデータの合成
GTA:大規模言語モデルを用いたテキスト分類のための教師付きガイド付き強化学習
PLACERを用いたタンパク質-低分子の構造集合体のモデリング
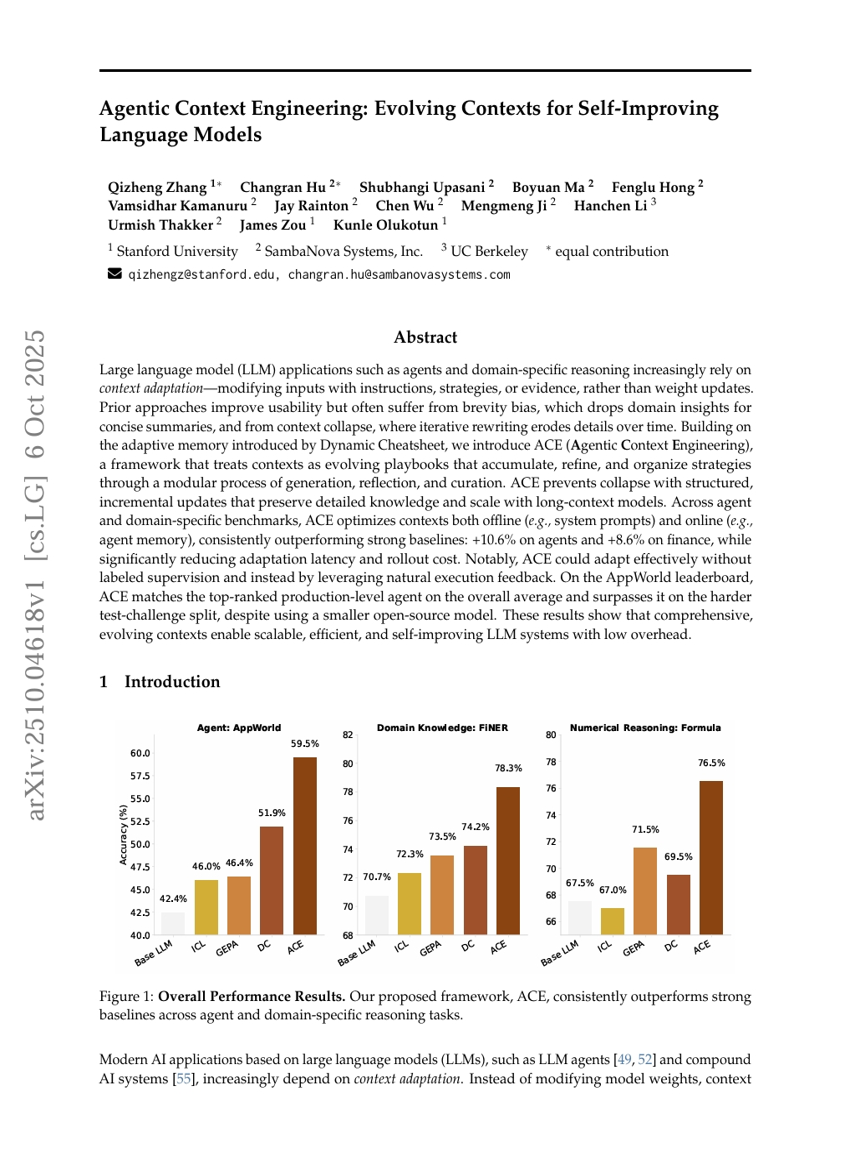
エージェンティック・コンテキスト工学:自己改善型言語モデルのための進化するコンテキスト
DiaMoE-TTS:Mixture-of-Expertsとパラメータ効率的なゼロショット適応を備えた統一的IPAベースの方言TTSフレームワーク
AI支援AR組立:拡張現実を用いた組立におけるオブジェクト認識とコンピュータビジョン
ハイベイクイン・ザ・ヘイストック
CritiCal:批判はLLMの不確実性または信頼度の補正に役立つだろうか?
大規模な視覚言語モデルにおける幻覚現象の軽減のためのテキスト埋め込みの精緻化
視覚空間的チューニング
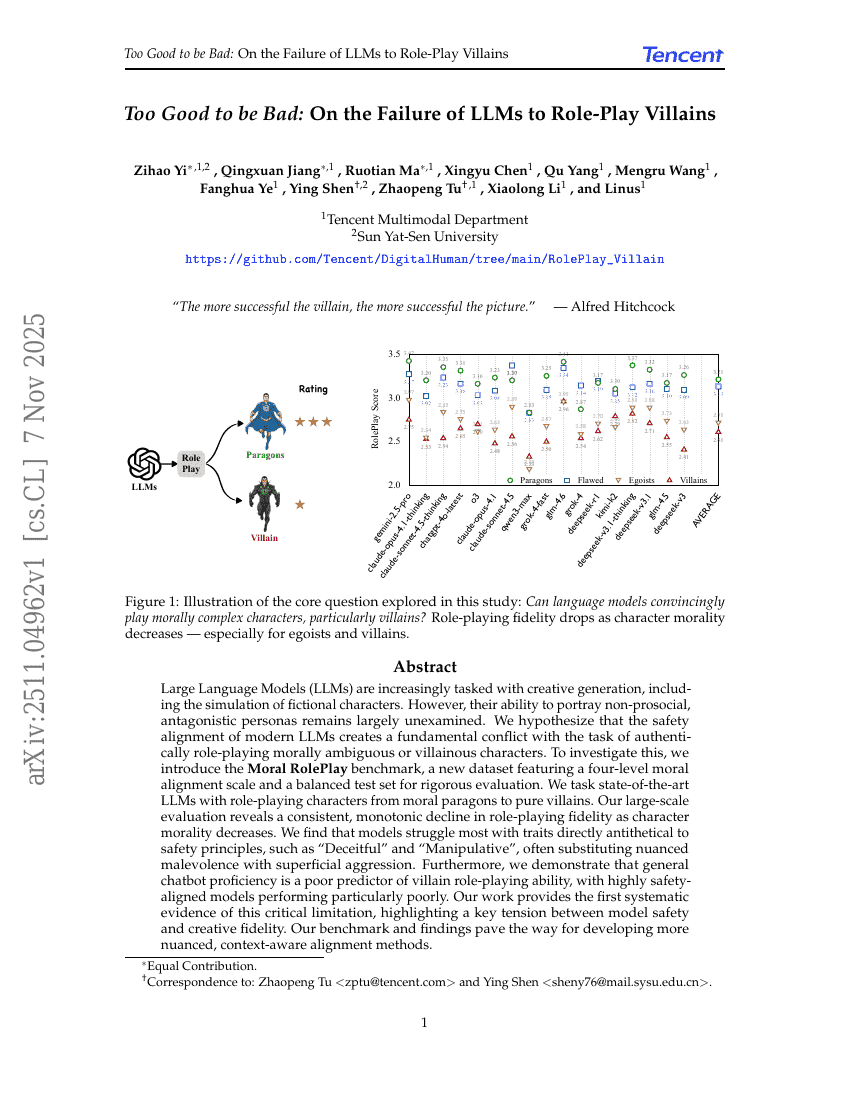
良すぎることの悪さ:大規模言語モデルが悪役を演じることに失敗する理由
DeepEyesV2:エージェント型マルチモーダルモデルへの道
機械学習を用いた連続血糖測定による代謝サブフェノタイプの同定と精密なライフスタイル変容の支援
テスト時に事前学習データを再利用することはコンピュート倍増要因である
NVIDIA Nemotron Nano V2 VL
CostBench:大規模言語モデルのツール利用エージェントにおける動的環境下での多ターンにわたるコスト最適な計画と適応の評価
Cambrian-S:動画における空間スーパーセンシングへの道
経験合成を用いたエージェント学習のスケーリング
V-Thinker:画像を用いたインタラクティブな思考
ビデオによる思考:ビデオ生成を新たなマルチモーダル推論枠組みとして
琥珀酸バイオ分子シミュレーションの最新動向
UltraHR-100K:大規模で高品質なデータセットを活用したUHR画像合成の向上
5次元から多数次元へ:大規模言語モデルを用いた精密かつ解釈可能な心理的プロファイリング
テキスト、音声、画像、動画のマルチモーダル生成のためのノードベース編集
DR. WELL:身体化LLMを用いたマルチエージェント協働のための記号的ワールドモデルを用いた動的推論と学習
Orion-MSP:テーブル型のコンテキスト内学習のための多スケールスパースアテンション
TabTune:テーブル型基礎モデルの推論およびファインチューニングを統合したライブラリ
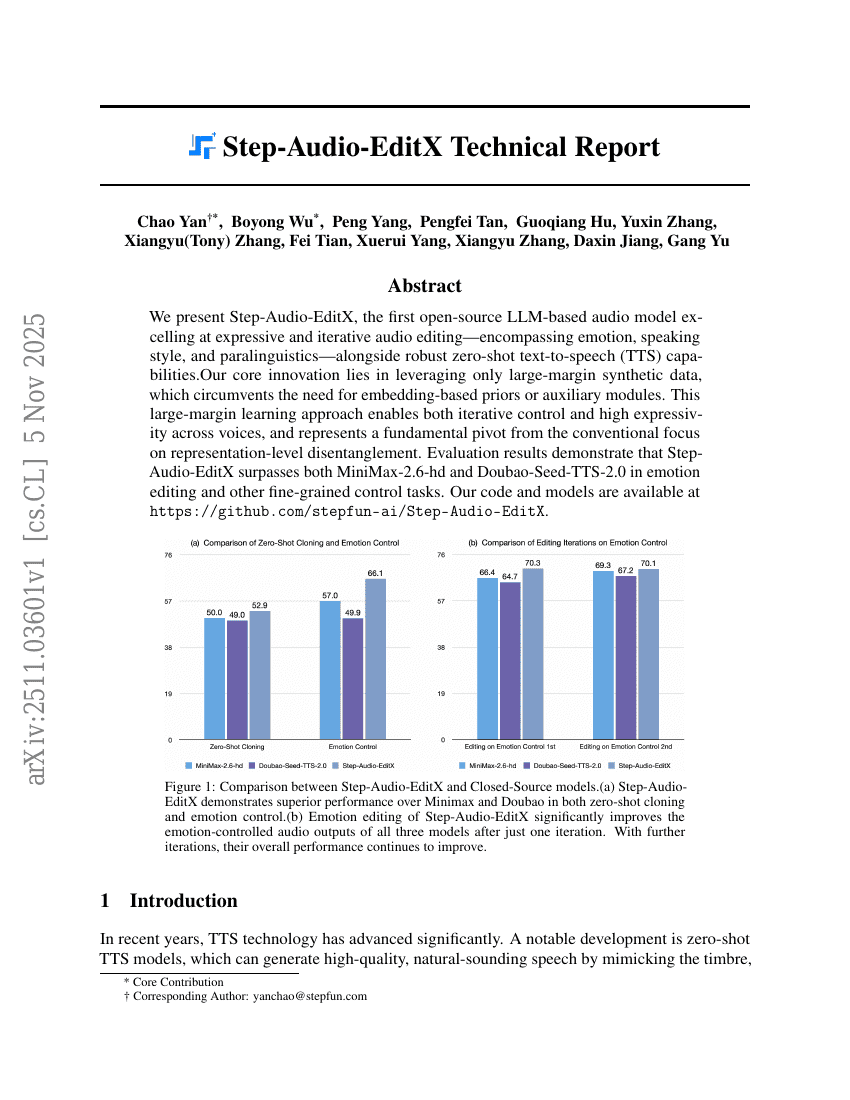
Step-Audio-EditX 技術報告
LEGO-Eval:ツール拡張を用いた3D身体化環境の合成における細粒度評価へ向けて
UniAVGen:非対称なクロスモーダル相互作用を有する統一音声・映像生成
TreeSynth:木構造を用いた部分空間分割による新規多様なデータの合成
GTA:大規模言語モデルを用いたテキスト分類のための教師付きガイド付き強化学習
PLACERを用いたタンパク質-低分子の構造集合体のモデリング
エージェンティック・コンテキスト工学:自己改善型言語モデルのための進化するコンテキスト
DiaMoE-TTS:Mixture-of-Expertsとパラメータ効率的なゼロショット適応を備えた統一的IPAベースの方言TTSフレームワーク
AI支援AR組立:拡張現実を用いた組立におけるオブジェクト認識とコンピュータビジョン
ハイベイクイン・ザ・ヘイストック
CritiCal:批判はLLMの不確実性または信頼度の補正に役立つだろうか?
大規模な視覚言語モデルにおける幻覚現象の軽減のためのテキスト埋め込みの精緻化
視覚空間的チューニング
良すぎることの悪さ:大規模言語モデルが悪役を演じることに失敗する理由
DeepEyesV2:エージェント型マルチモーダルモデルへの道
機械学習を用いた連続血糖測定による代謝サブフェノタイプの同定と精密なライフスタイル変容の支援
テスト時に事前学習データを再利用することはコンピュート倍増要因である
NVIDIA Nemotron Nano V2 VL
CostBench:大規模言語モデルのツール利用エージェントにおける動的環境下での多ターンにわたるコスト最適な計画と適応の評価
Cambrian-S:動画における空間スーパーセンシングへの道
経験合成を用いたエージェント学習のスケーリング
V-Thinker:画像を用いたインタラクティブな思考
ビデオによる思考:ビデオ生成を新たなマルチモーダル推論枠組みとして
琥珀酸バイオ分子シミュレーションの最新動向
UltraHR-100K:大規模で高品質なデータセットを活用したUHR画像合成の向上
5次元から多数次元へ:大規模言語モデルを用いた精密かつ解釈可能な心理的プロファイリング
テキスト、音声、画像、動画のマルチモーダル生成のためのノードベース編集
DR. WELL:身体化LLMを用いたマルチエージェント協働のための記号的ワールドモデルを用いた動的推論と学習
Orion-MSP:テーブル型のコンテキスト内学習のための多スケールスパースアテンション
TabTune:テーブル型基礎モデルの推論およびファインチューニングを統合したライブラリ
Step-Audio-EditX 技術報告
LEGO-Eval:ツール拡張を用いた3D身体化環境の合成における細粒度評価へ向けて
UniAVGen:非対称なクロスモーダル相互作用を有する統一音声・映像生成