HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

GroupRank:強化学習によって駆動されるグループワイドな再ランク付け枠組み

MMaDA-Parallel:思考認識型編集・生成のためのマルチモーダル大規模拡散言語モデル



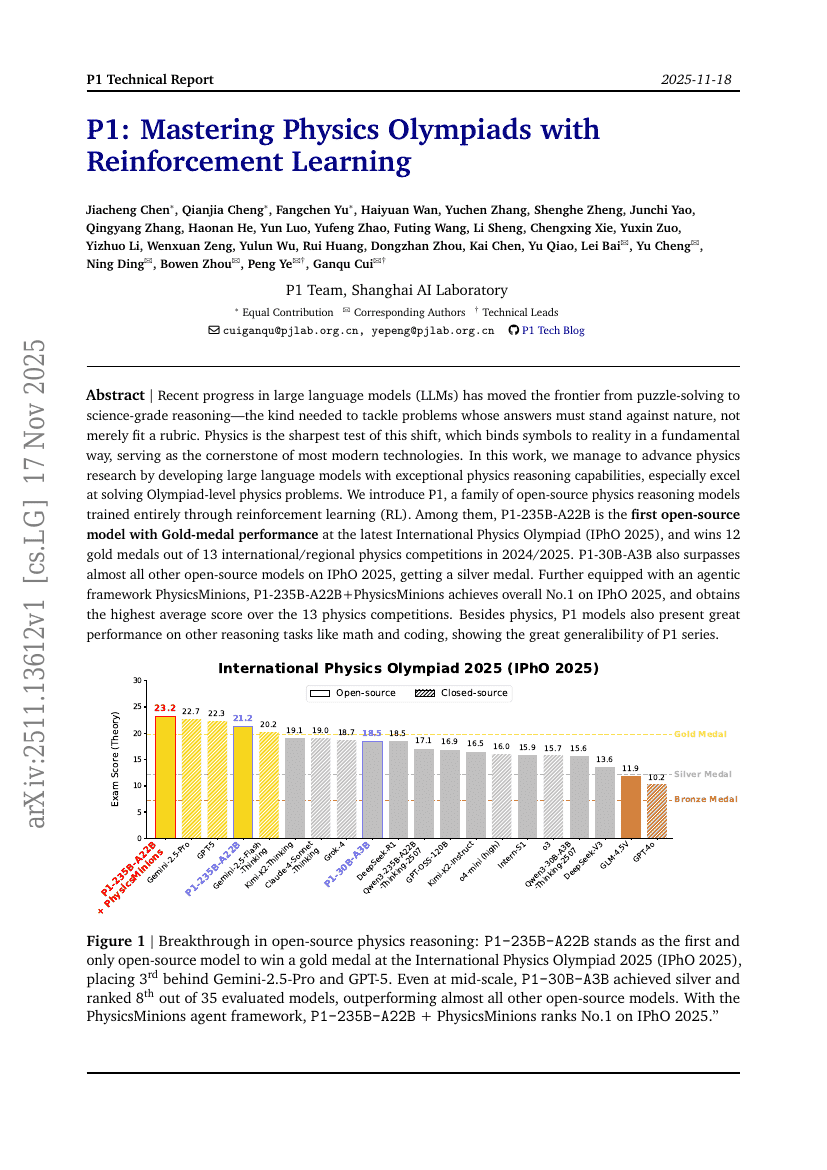

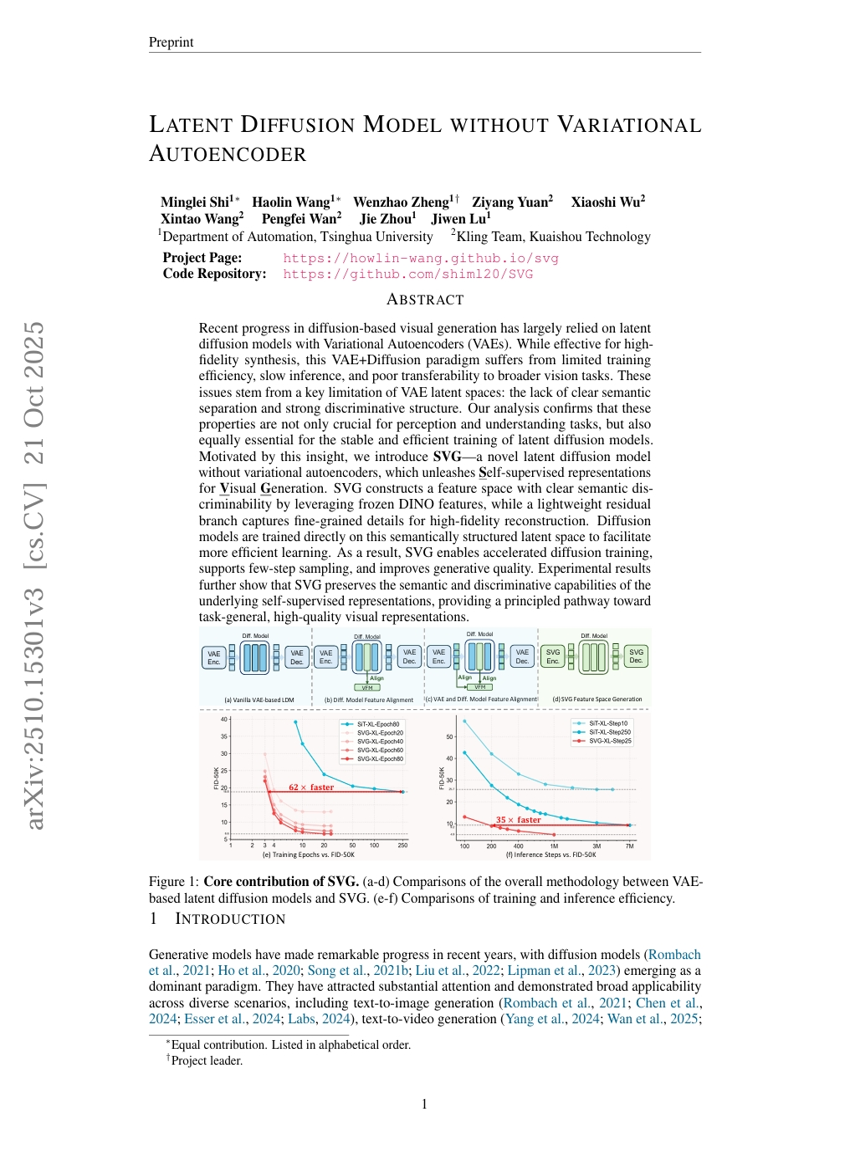



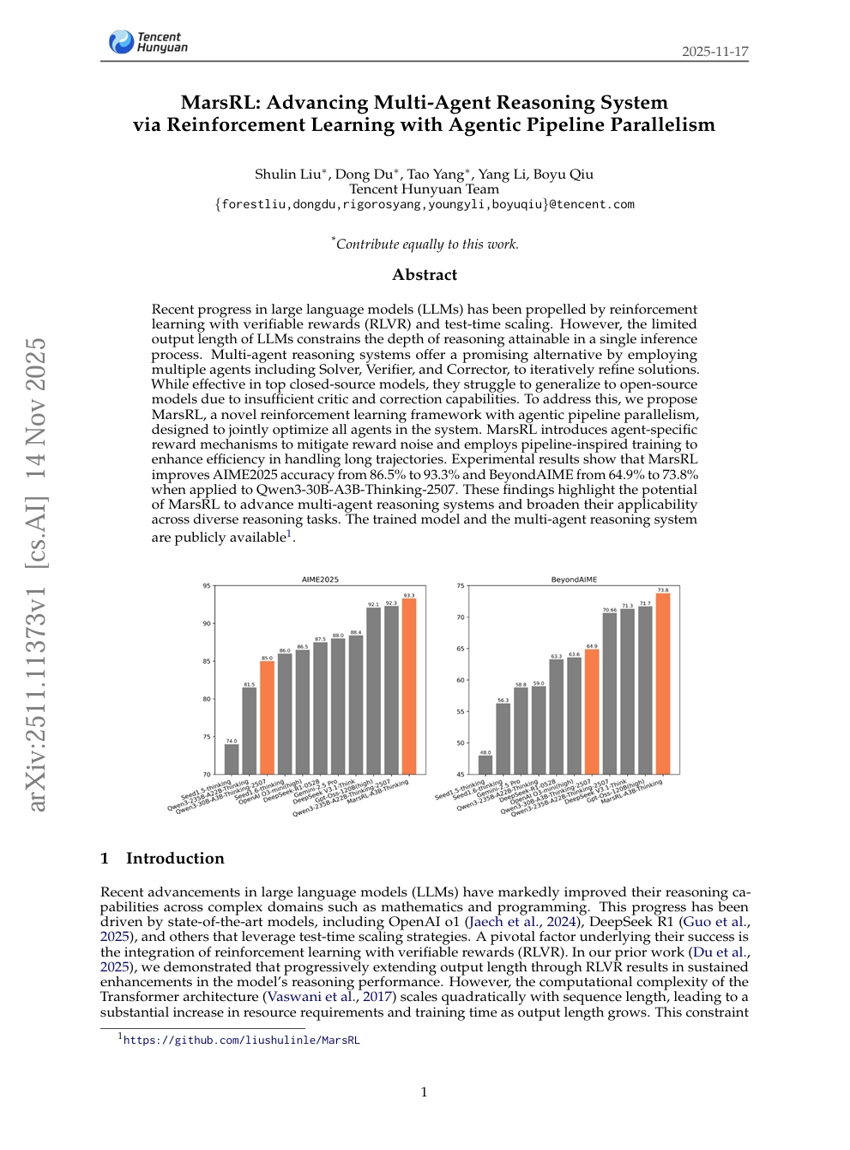
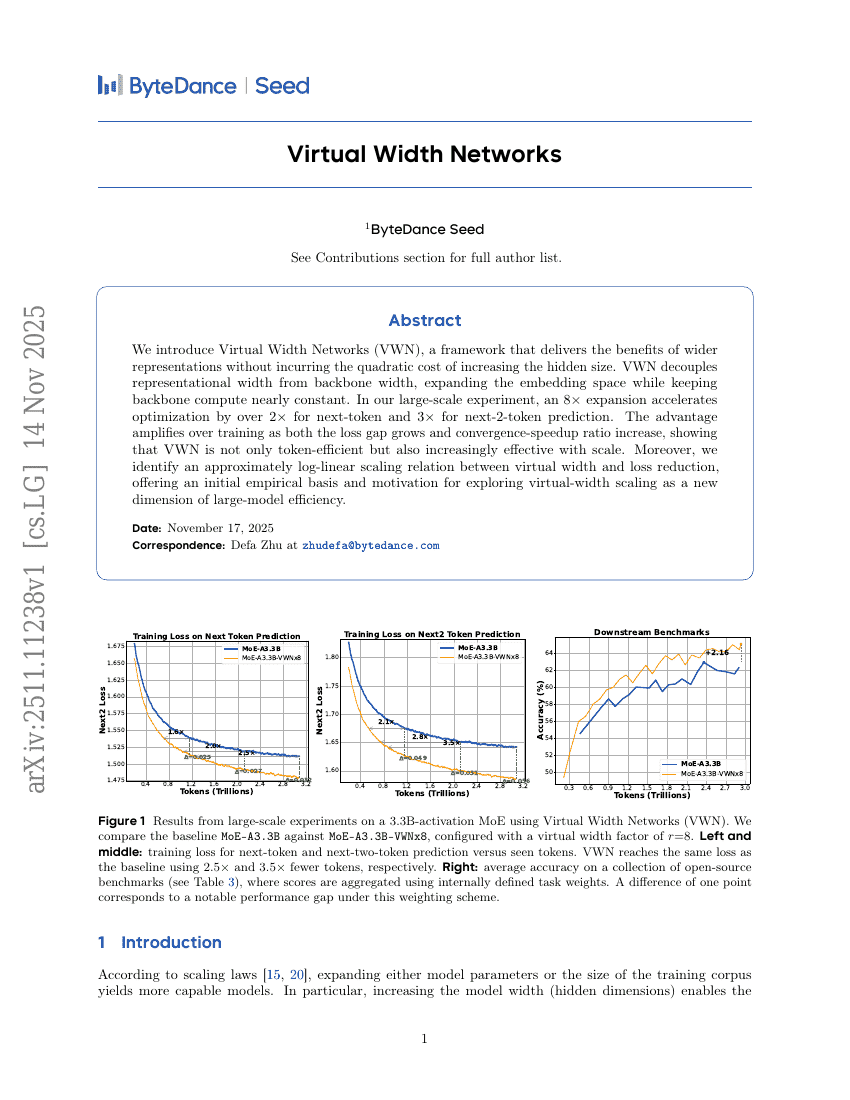
















GroupRank:強化学習によって駆動されるグループワイドな再ランク付け枠組み
MMaDA-Parallel:思考認識型編集・生成のためのマルチモーダル大規模拡散言語モデル
TiViBench:Video生成モデルにおけるThink-in-Video推論のベンチマーク
Part-X-MLLM:部位認識型3Dマルチモーダル大規模言語モデル
Uni-MoE-2.0-Omni:高度なMoE、トレーニングおよびデータを用いた言語中心型オムニモーダル大規模モデルのスケーリング
P1:強化学習を用いた物理学オリンピックの習得
ランスロット:完全準同型暗号内における効率的かつプライバシー保護型のバシニンス耐性フェデレーテッドラーニングのためのアプローチ
変分自己符号化器を用いない潜在拡散モデル
RewardMap:マルチステージ強化学習を活用した詳細視覚推論におけるスパース報酬の克服
ReinFlow:オンライン強化学習を用いたフローマッチング方策のファインチューニング
推論能力の音声評価:モダリティに起因するパフォーマンス格差の診断
MarsRL:エージェントパイプライン並列化を用いた強化学習によるマルチエージェント推論システムの進展
バーチャル幅ネットワーク
AIonopedia:マルチモーダル学習を統合するLLMエージェントによるイオン液体の発見
UI2CodeextN:テスト時スケーラビリティを備えたインタラクティブなUIからCode生成のための視覚言語モデル
GGBench:統一型マルチモーダルモデル向けの幾何学的生成推論ベンチマーク
WEAVE:文脈内インタリーブド理解および生成の解放とベンチマーク
DoPE:ノイズ除去回転位置埋め込み
BRFL:ブロックチェーンベースのバジリスク耐性ファederated学習モデル
指数ガウス混合ネットワークを用いた動画視聴時間予測のためのマルチグレイン分布モデリング
SAC Flow:速度再パラメータ化による逐次モデル化を用いたサンプル効率の良い流れに基づく方策の強化学習
特徴最適アライメントを用いたクローズドソースMLLMに対する敵対的攻撃
Hail to the Thief: 分散型GRPOにおける攻撃と防御の探求
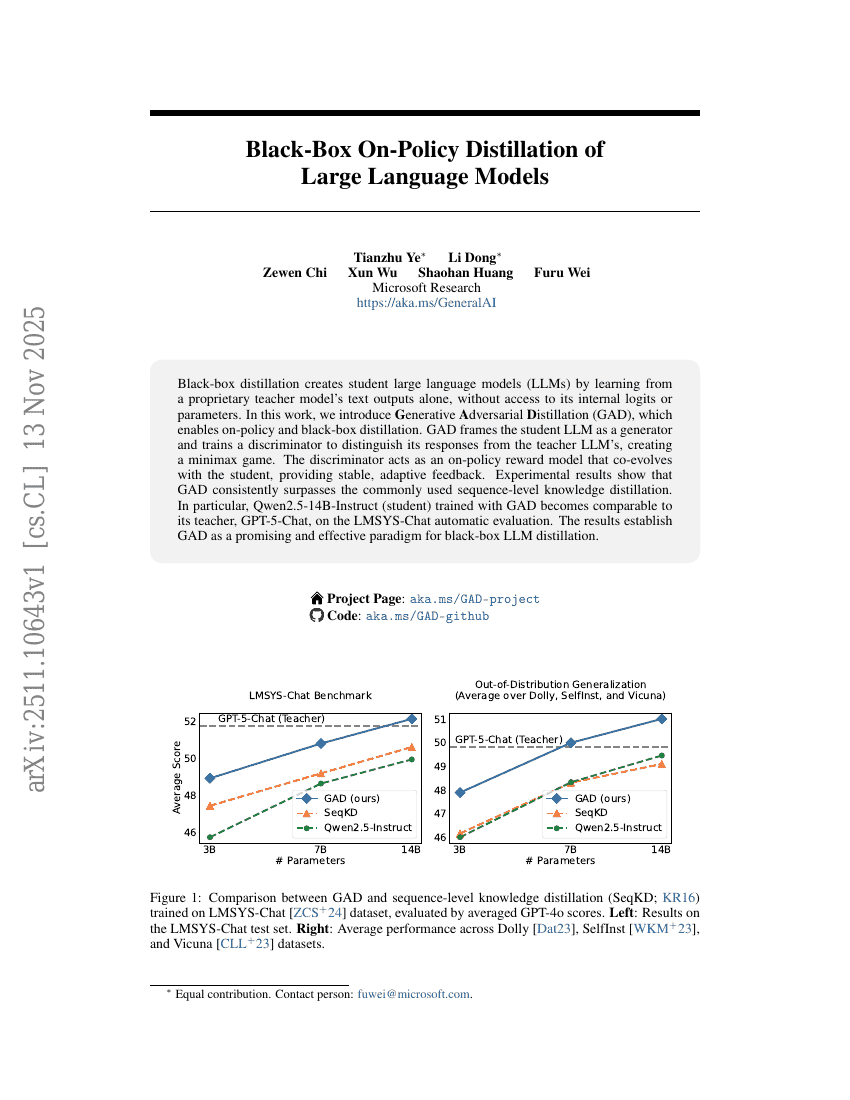
ブラックボックス・オンポリシー distillation による大規模言語モデルの学習
UniVA:オープンソース次世代動画汎用型エージェントへの道
PAN:汎用的、インタラクティブな、長期ホライゾン世界シミュレーションを実現する世界モデル
潜在空間における一歩、ピクセルにおける飛躍的進歩:あなたの拡散モデル向け高速潜在上位化アダプタ
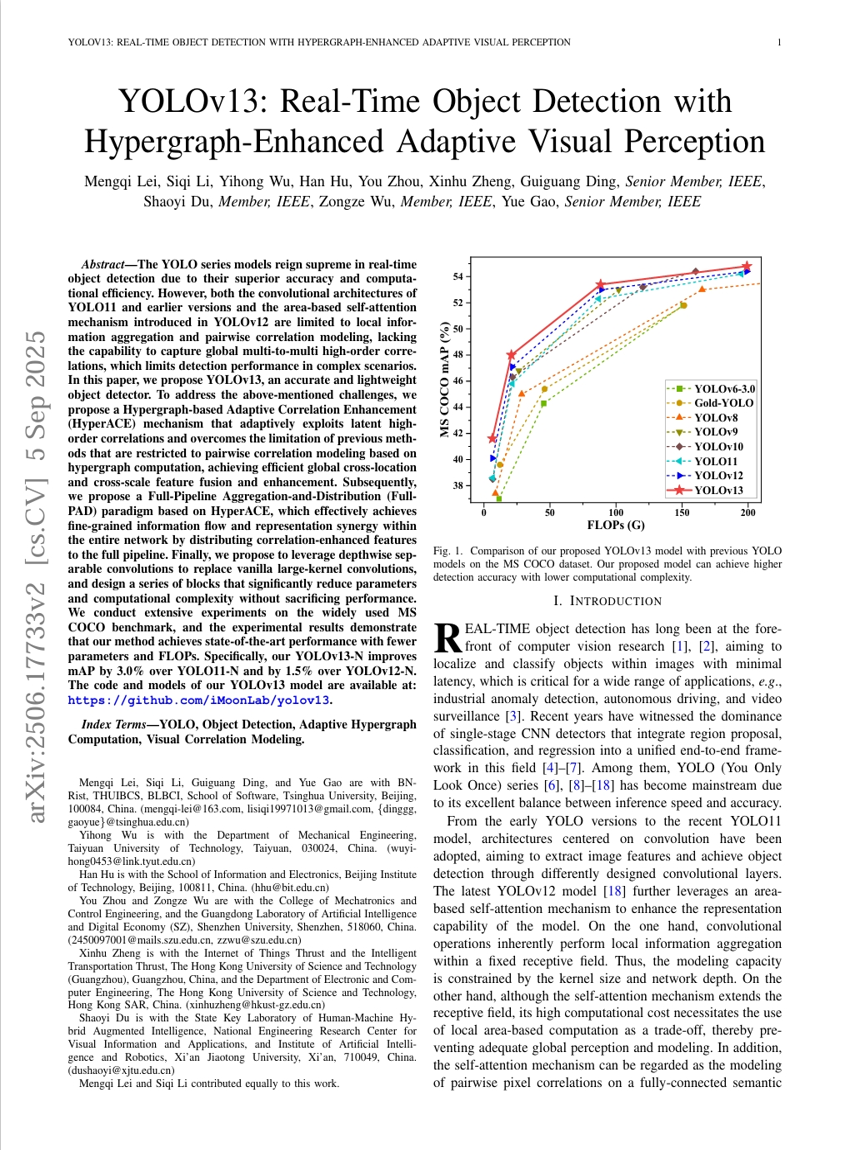
YOLOv13:ハイパーグラフ強化型適応型視覚認識を用いたリアルタイム物体検出
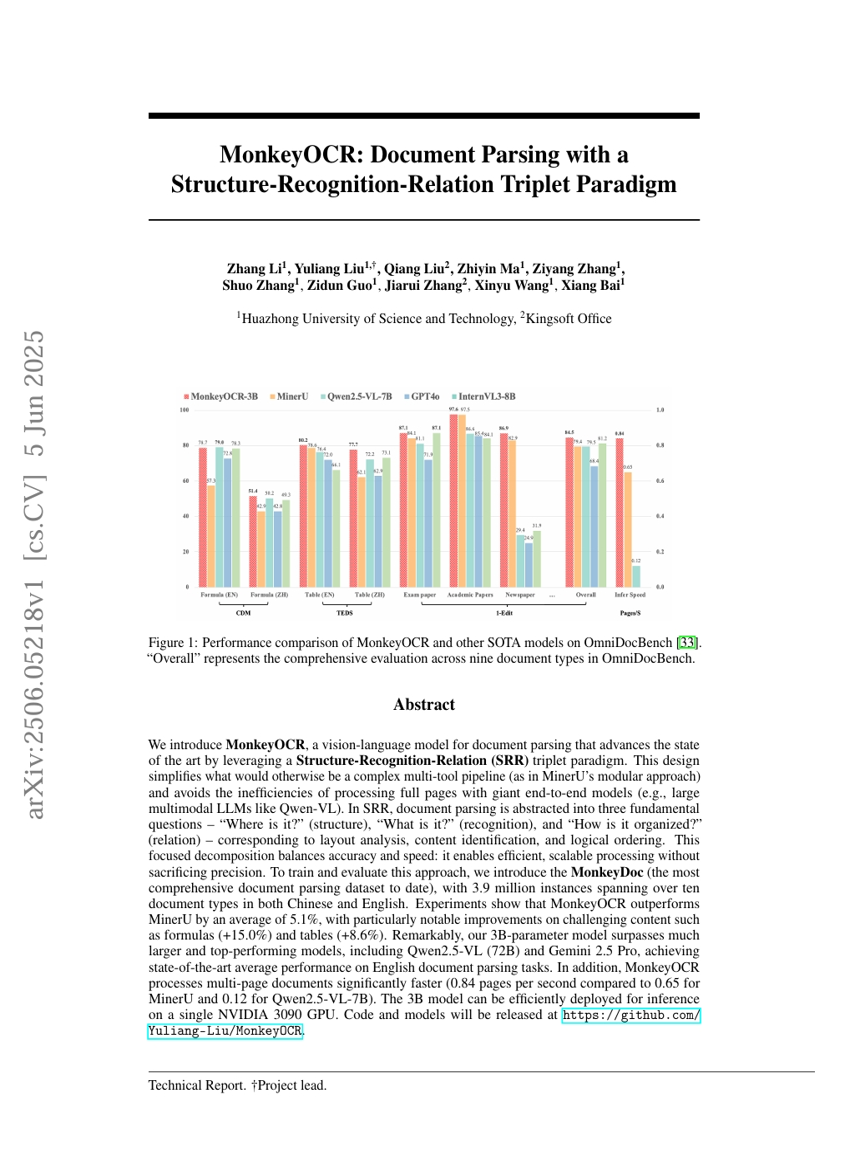
MonkeyOCR:構造認識関係三重項パラダイムを用いたドキュメント解析
安全な生成AIのためのコンセンサスサンプリング
Argus:エンドツーエンドADS向けレジリエンス指向型セーフティアサランスフレームワーク
WMPO:視覚言語行動モデルにおける世界モデルに基づく方策最適化
TiViBench:Video生成モデルにおけるThink-in-Video推論のベンチマーク
Part-X-MLLM:部位認識型3Dマルチモーダル大規模言語モデル
Uni-MoE-2.0-Omni:高度なMoE、トレーニングおよびデータを用いた言語中心型オムニモーダル大規模モデルのスケーリング
P1:強化学習を用いた物理学オリンピックの習得
ランスロット:完全準同型暗号内における効率的かつプライバシー保護型のバシニンス耐性フェデレーテッドラーニングのためのアプローチ
変分自己符号化器を用いない潜在拡散モデル
RewardMap:マルチステージ強化学習を活用した詳細視覚推論におけるスパース報酬の克服
ReinFlow:オンライン強化学習を用いたフローマッチング方策のファインチューニング
推論能力の音声評価:モダリティに起因するパフォーマンス格差の診断
MarsRL:エージェントパイプライン並列化を用いた強化学習によるマルチエージェント推論システムの進展
バーチャル幅ネットワーク
AIonopedia:マルチモーダル学習を統合するLLMエージェントによるイオン液体の発見
UI2CodeextN:テスト時スケーラビリティを備えたインタラクティブなUIからCode生成のための視覚言語モデル
GGBench:統一型マルチモーダルモデル向けの幾何学的生成推論ベンチマーク
WEAVE:文脈内インタリーブド理解および生成の解放とベンチマーク
DoPE:ノイズ除去回転位置埋め込み
BRFL:ブロックチェーンベースのバジリスク耐性ファederated学習モデル
指数ガウス混合ネットワークを用いた動画視聴時間予測のためのマルチグレイン分布モデリング
SAC Flow:速度再パラメータ化による逐次モデル化を用いたサンプル効率の良い流れに基づく方策の強化学習
特徴最適アライメントを用いたクローズドソースMLLMに対する敵対的攻撃
Hail to the Thief: 分散型GRPOにおける攻撃と防御の探求
ブラックボックス・オンポリシー distillation による大規模言語モデルの学習
UniVA:オープンソース次世代動画汎用型エージェントへの道
PAN:汎用的、インタラクティブな、長期ホライゾン世界シミュレーションを実現する世界モデル
潜在空間における一歩、ピクセルにおける飛躍的進歩:あなたの拡散モデル向け高速潜在上位化アダプタ
YOLOv13:ハイパーグラフ強化型適応型視覚認識を用いたリアルタイム物体検出
MonkeyOCR:構造認識関係三重項パラダイムを用いたドキュメント解析
安全な生成AIのためのコンセンサスサンプリング
Argus:エンドツーエンドADS向けレジリエンス指向型セーフティアサランスフレームワーク
WMPO:視覚言語行動モデルにおける世界モデルに基づく方策最適化