Command Palette
Search for a command to run...
Docling: AI駆動のドキュメント変換のための効率的なオープンソースツールキット
Docling: AI駆動のドキュメント変換のための効率的なオープンソースツールキット
ドキュメント解析ツールDoclingのワンクリックデプロイメント
概要
タイトル:Docling:文書変換のための使いやすい、自己完結型、MITライセンスのオープンソースツールキット
抄録:私たちは、Doclingを紹介します。これは、使いやすい、自己完結型、MITライセンスのオープンソースツールキットで、複数の一般的な文書フォーマットを統一されたリッチな構造化表現に変換することができます。Doclingは、レイアウト分析(DocLayNet)および表構造認識(TableFormer)のための最先端の専門AIモデルによって駆動され、限られたリソース予算でコモディティハードウェア上で効率的に動作します。DoclingはPythonパッケージとして公開されており、Python APIまたはCLIツールとして使用できます。Doclingのモジュラーアーキテクチャと効率的な文書表現により、拡張機能、新機能、モデル、カスタマイズの実装が容易です。Doclingはすでに他の人気のあるオープンソースフレームワーク(例:LangChain、LlamaIndex、spaCy)に統合されており、文書の処理やハイエンドアプリケーションの開発に自然に適しています。オープンソースコミュニティはDoclingの使用、促進、開発に積極的に参加しており、わずか1ヶ月でGitHubで1万スターを獲得し、2024年11月には世界中でGitHubで最もトレンドの上位にランクインしたリポジトリとして報告されました。
One-sentence Summary
Docling is an open-source Python toolkit that converts popular document formats into a unified, richly structured representation by leveraging the DocLayNet and TableFormer models for layout analysis and table structure recognition, respectively, while its modular architecture enables efficient execution on commodity hardware within a small resource budget and direct integration with LangChain, LlamaIndex, and spaCy.
Key Contributions
- Introduces Docling, an open-source Python toolkit that parses PDF, Office, image, and HTML documents into a unified DoclingDocument representation.
- Integrates specialized AI models, including DocLayNet for layout analysis and TableFormer for table structure recognition, into a modular architecture that executes entirely locally on commodity hardware with optional GPU acceleration.
- Validates conversion efficiency and structural accuracy through architectural comparisons, while demonstrating practical utility through native integrations with LangChain and LlamaIndex and achieving over 10,000 GitHub stars.
Introduction
The proliferation of large language models and retrieval-augmented generation has made it essential to extract structured data from highly variable document formats like PDFs, Office files, and scanned images. Decades of weak standardization and print-optimized layouts have historically complicated this task, while existing commercial and cloud-based solutions remain costly, opaque, and incompatible with local or privacy-sensitive deployments. The authors leverage specialized AI models for layout analysis, optical character recognition, and table structure recognition to power Docling, an open-source Python library that performs high-fidelity document conversion entirely on local hardware. This toolkit delivers a transparent, extensible, and framework-ready alternative that bridges the quality gap between proprietary systems and limited open-source offerings.
Dataset
- Composition and sources: The authors assembled a benchmark test set of 89 PDF files drawn primarily from the DocLayNet collection, with additional samples integrated from CCpdf to maximize stylistic and structural diversity.
- Subset details: The combined dataset spans 4,008 pages containing 56,246 text items, 1,842 tables, and 4,676 images. The authors curated this specific volume to balance comprehensive feature coverage with manageable benchmarking durations.
- Data usage and processing: Rather than supporting model training, the dataset serves exclusively as an evaluation benchmark. The authors use it to measure document conversion accuracy and computational overhead across various AI models and system setups.
- Conditional processing strategy: To optimize efficiency, the pipeline applies processing only where relevant. The OCR module runs exclusively on pages containing bitmap images, while table structure recognition is triggered solely for pages with tabular layouts. This targeted approach ensures accurate per-page timing metrics without redundant computation.
Method
The authors leverage a modular architecture in Docling, centered around three core components: pipelines, parser backends, and the DoclingDocument data model. This design enables the system to process diverse document formats into a unified, richly structured representation suitable for downstream applications. The DoclingDocument, a Pydantic-based data model, serves as the central data structure, encapsulating text, tables, figures, lists, and other elements, along with their hierarchical relationships, layout information (bounding boxes), and provenance details. It provides APIs for construction, inspection, and export to various formats, including lossless JSON and lossy Markdown or HTML. The model also supports integration with chunking abstractions, allowing users to generate structured document segments for applications like retrieval-augmented generation (RAG).
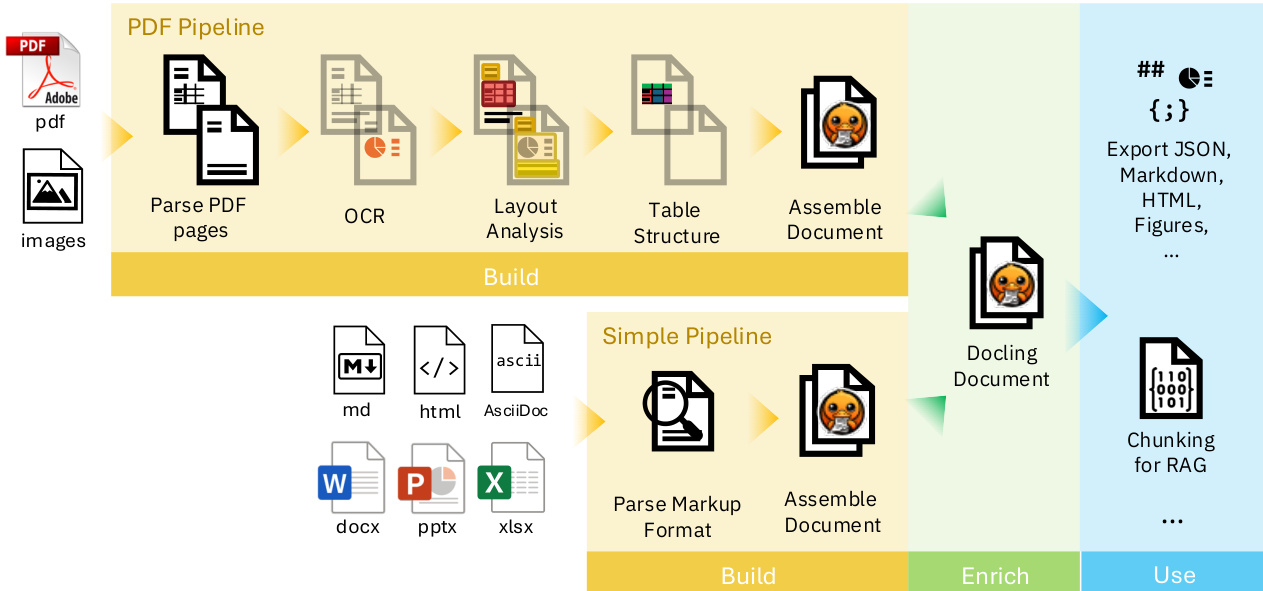
Refer to the framework diagram, which illustrates the overall architecture. Document conversion begins with a parser backend, which is selected based on the input format. For low-level formats such as PDFs and scanned images, the backend extracts text tokens with their geometric coordinates and renders the visual representation of each page. For markup-based formats like HTML, Markdown, and Office documents, the backend directly constructs a DoclingDocument representation by parsing the semantic structure. The extracted data is then processed by a pipeline. The Standard-PdfPipeline handles PDF and image inputs, applying a sequence of AI models to each page to recover layout and table structures. The SimplePipeline processes markup-based formats, potentially enriching them with additional models. Both pipelines ultimately assemble the results into a complete DoclingDocument.

The PDF pipeline, detailed in the diagram, is a multi-stage process. After parsing the input and rendering pages, it applies AI models independently on each page. The layout analysis model, derived from RT-DETR and trained on DocLayNet, detects and classifies page elements, predicting bounding boxes for items like paragraphs, figures, and tables. This model's output is post-processed and intersected with text tokens to form coherent content units. For tables, the TableFormer model, a vision-transformer, is used to recognize the logical structure by predicting row and column boundaries and identifying headers and body cells. OCR is employed to transcribe text from scanned images, with integration provided for libraries like EasyOCR and Tesseract. The final stage assembles all predictions into a DoclingDocument and applies post-processing to enhance features like reading order and figure-caption matching. The system's extensibility allows for custom pipelines and the integration of new models, such as those for figures, equations, or code, and its modular design facilitates adoption by frameworks like LangChain and LlamaIndex.
Experiment
The evaluation benchmarks Docling against three open-source PDF conversion tools across x86 CPU, Apple M3 Max, and Nvidia L4 GPU configurations to assess processing speed under standardized resource constraints. Separate experiments validate how document complexity influences conversion time and profile individual AI pipeline components to identify computational bottlenecks. Qualitative analysis reveals that processing duration scales with content density rather than page count, with optical character recognition emerging as the most resource-intensive operation. While GPU acceleration substantially reduces processing times for AI-driven tasks, performance gains vary across models, and Docling consistently ranks among the fastest CPU-based converters while remaining highly competitive on GPU hardware.
The authors compare the performance of Docling with other open-source tools for PDF conversion across different system configurations, including CPU-only, GPU-accelerated, and Apple Silicon environments. Results show that Docling achieves competitive conversion speeds on CPU and Apple Silicon systems, while MinerU demonstrates superior performance with GPU acceleration. The the the table outlines the specific versions and configuration options used for each tool in the benchmark. Docling achieves faster conversion speeds than other tools on CPU and Apple Silicon systems, but MinerU outperforms others with GPU acceleration. The configuration options for each tool vary significantly, with differences in OCR engines, layout models, and the the table detection methods. GPU acceleration provides substantial speed improvements for some tools, but not all, indicating varying levels of optimization for GPU use.

The evaluation benchmarks several open-source PDF conversion tools across CPU-only, GPU-accelerated, and Apple Silicon environments to assess their cross-platform efficiency. Results indicate that Docling delivers competitive conversion speeds on CPU and Apple Silicon systems, while MinerU achieves superior performance when leveraging GPU acceleration. The benchmark also highlights significant variations in underlying configurations, which contribute to inconsistent hardware optimization and demonstrate that conversion performance is highly dependent on both the target environment and specific tool implementations.