Command Palette
Search for a command to run...
ZAYA1-8B技術報告書
ZAYA1-8B技術報告書
概要
ZyphraのMoE++アーキテクチャに基づき、7億(700M)個のアクティブパラメータと80億(8B)個の総パラメータを備えた推論重視の混合エキスパート(MoE)モデル「ZAYA1-8B」を発表する。ZAYA1-8Bのコアとなる事前トレーニング、中間トレーニング、および教師ありファインチューニング(SFT)は、AMDのフルスタックなコンピュート、ネットワーク、およびソフトウェアプラットフォーム上で行われた。アクティブパラメータ数が10億未満であるZAYA1-8Bは、いくつかの難易度の高い数学およびコーディングベンチマークにおいて、DeepSeek-R1-0528と同等以上の性能を発揮し、はるかに大規模なオープンウェイトの推論モデルとも競合し得るレベルにある。ZAYA1-8Bは推論専用でスクラッチから訓練されており、事前トレーニングの段階からアンサー_preserving_ trimmingスキームを用いて推論データが組み込まれている。ポストトレーニングでは、4段階のRL(強化学習)カスケードが行われた。第1段階では数学およびパズルを用いた推論ウォームアップを実施し、第2段階では400のタスクからなるRLVE-Gymのカリキュラムを行った。第3段階では、競技プログラミングのリファレンスを基に構築された合成コード環境およびテスト時点のコンピュート(test-time compute)トレースを用いた数学およびコードのRLを実施し、第4段階ではチャットおよび指示従順性に関する行動RL(behavioral RL)を行った。また、並列の推論トレースを再帰的に集約しつつ、ラウンド間で有界長の推論テールのみを継承するテスト時点のコンピュート手法「Markovian RSA」も導入する。TTC(Time-to-Completion)評価において、Markovian RSAの適用により、ZAYA1-8BはAIME'25で91.9%、HMMT'25で89.6%のスコアを達成した。これは4Kトークンのテールのみを継承しながら、Gemini-2.5 Pro、DeepSeek-V3.2、GPT-5-Highを含むはるかに大規模な推論モデルとのギャップを縮小する結果となった。
One-sentence Summary
Built on Zyphra's MoE++ architecture and trained on a full-stack AMD compute, networking, and software platform, the ZAYA1-8B mixture-of-experts model, with 700M active and 8B total parameters, matches or exceeds DeepSeek-R1-0528 on challenging mathematics and coding benchmarks through a four-stage RL cascade, while Markovian RSA test-time compute achieves 91.9% on AIME'25 and 89.6% on HMMT'25 with a 4K-token tail, narrowing the gap to larger models including Gemini-2.5 Pro, DeepSeek-V3.2, and GPT-5-High.
Key Contributions
- This work introduces ZAYA1-8B, a reasoning-focused mixture-of-experts model with 700M active parameters built on Zyphra's MoE++ architecture. The system was trained from scratch on a full-stack AMD platform and matches the performance of larger models like DeepSeek-R1-0528 on mathematics and coding benchmarks.
- The paper presents Markovian RSA, a test-time compute method that recursively aggregates parallel reasoning traces while carrying forward only bounded-length reasoning tails. This technique raises performance to 91.9% on AIME'25 and 89.6% on HMMT'25 while maintaining capped attention costs and predictable throughput.
- The training pipeline integrates the method so the model learns to use the same workflow at inference by supplying verifier-free aggregation examples for supervised fine-tuning. This approach utilizes a four-stage RL cascade that includes reasoning warmup, curriculum learning, and behavioral reinforcement.
Introduction
Advanced reasoning capabilities in large language models typically demand substantial parameter counts and compute resources, creating barriers for efficiency-focused applications. Prior approaches often struggle with managing long reasoning traces during training and fail to integrate test-time compute strategies directly into the model learning process. The authors present ZAYA1-8B, a 700M active parameter Mixture-of-Experts model built on an enhanced MoE++ architecture and trained entirely on AMD hardware. To bridge the performance gap with larger systems, they introduce Markovian RSA, a test-time compute method that recursively aggregates parallel reasoning traces with bounded context, enabling the model to match or exceed significantly larger reasoning benchmarks.
Dataset
Dataset Composition and Sources
- The authors initialize the model from a broad web-crawl distribution containing code, math, multilingual, and reasoning data.
- Midtraining and SFT phases utilize coarse data categories with a heavy emphasis on long chain-of-thought reasoning traces.
- Specific aggregation data sources include OpenMathReasoning, rStar-Coder, and internal reasoning gym and enigmata datasets.
Key Details for Each Subset
- Base pretraining includes a second phase that upweights code, math, reasoning, and instruction-formatted data at 4K context length.
- The reasoning-focused midtrain phase runs for 1.2T tokens at 32K context with a RoPE base frequency of 1M.
- Supervised fine-tuning occurs at 131K context for 660B tokens with a RoPE base frequency of 5M.
- Aggregation examples are built from problems containing multiple expert model rollouts, typically with n=8 samples per problem.
Data Usage and Mixture Ratios
- Data mixture percentages for midtrain and SFT are normalized over nonzero mixture weights rather than reporting individual dataset names.
- Markovian RSA examples are integrated into the standard prompt distribution during the reinforcement learning stage.
- Training employs Expert-aggregation using expert-model rollouts and Self-aggregation using traces from the current or prior checkpoint.
Processing and Construction Strategies
- Aggregation-based training examples are constructed offline by sampling C rollouts and extracting their reasoning tails.
- An aggregation prompt containing the problem and selected tails conditions the teacher to produce a new aggregated rollout as the target.
- Context extension uses all-gather KV context parallelism with two ranks at 32K and eight ranks at 131K.
- Compressed KV representation keeps activation and memory overhead low while handling convolution and value-shift boundary conditions.
Method
The ZAYA1-8B model utilizes a Mixture of Experts (MoE) architecture with specific modifications to improve efficiency and performance. The design incorporates Compressed Convolutional Attention (CCA) to perform sequence mixing in a compressed latent space. This module reduces compute requirements for training and prefill while maintaining competitive KV-cache compression rates. The internal structure of the attention mechanism involves projections for queries, keys, and values, followed by depthwise and headwise convolutions and time delays.
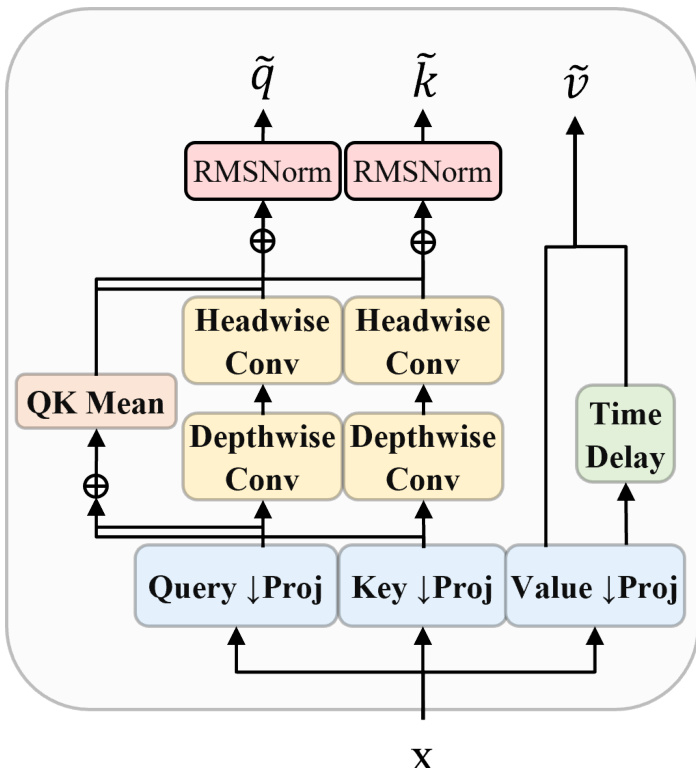
The routing mechanism replaces the standard linear router with an MLP-based design enhanced by Exponential Depth Averaging (EDA). This allows the router to combine the current layer's representation with the previous layer's routing representation using a learned coefficient. The router first down-projects the residual stream xl to a smaller dimension R via rl=Wdownxl. The overall framework features 16 experts and includes residual scaling to control information flow and residual-norm growth. The complete architecture integrates embedding layers, self-attention blocks, and the specialized router and CCA modules.
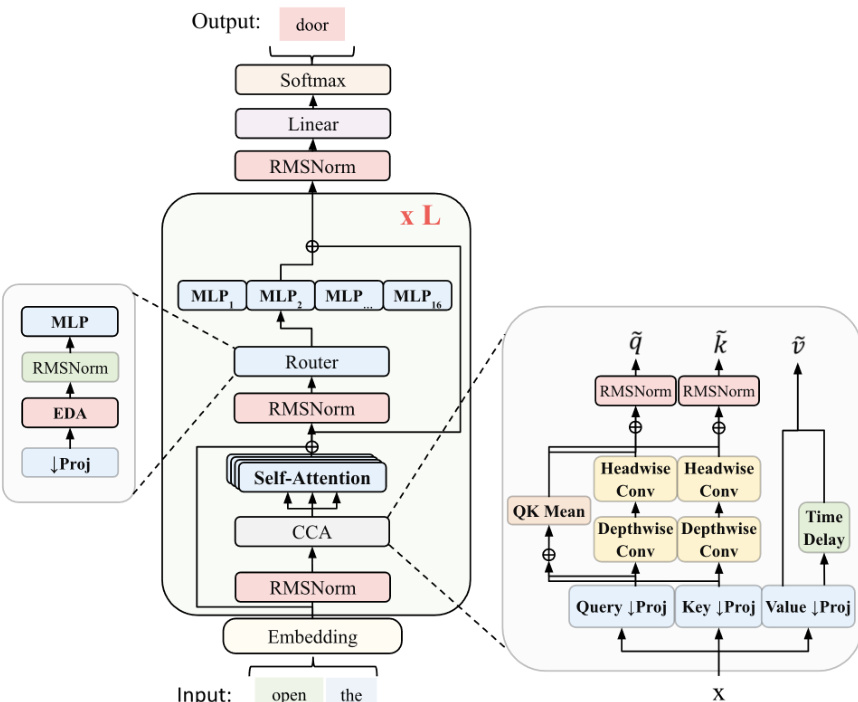
The training process begins with supervised fine-tuning and pretraining phases that employ answer-preserving trimming. This strategy manages long chain-of-thought data by truncating the tail of reasoning traces while keeping the final answer intact. This ensures the model learns from coherent reasoning sequences even when context lengths are shorter than the full trace. During this phase, the model is optimized to maintain high probability on correct tokens within the preserved answer sections.
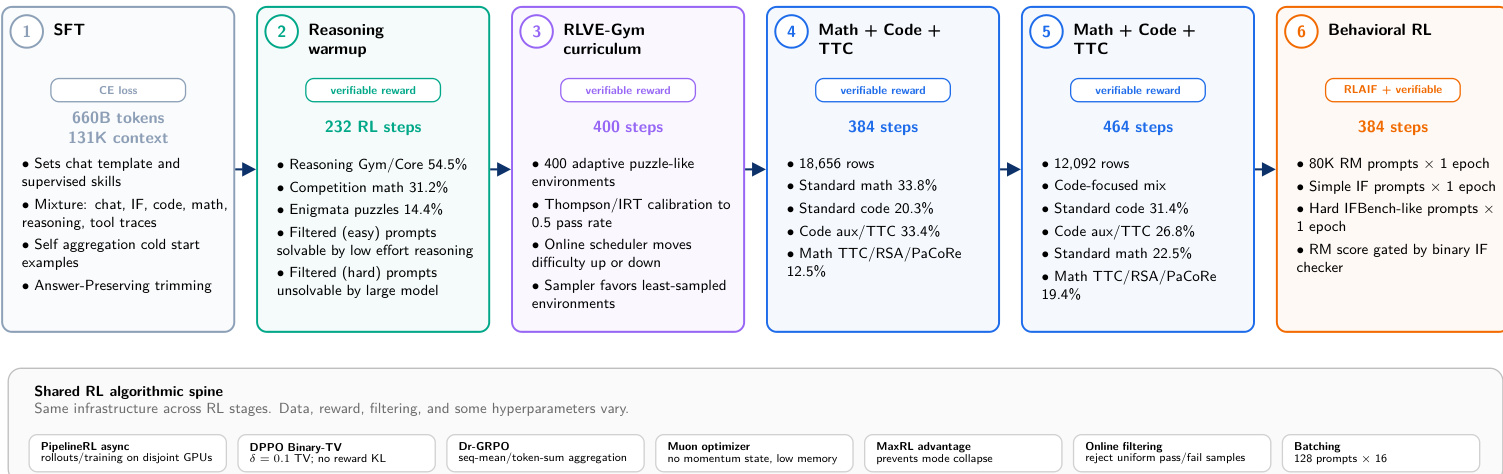
Post-training proceeds through a structured reinforcement learning cascade consisting of six stages. The pipeline starts with SFT and moves through reasoning warmup, RLVE-Gym curriculum, and math and code tasks before concluding with behavioral RL. A shared algorithmic spine underpins the RL stages, utilizing asynchronous rollout generation and specific optimization techniques like momentum-free Muon. This progression prioritizes verifiable reasoning capabilities before tuning for general chat and instruction following.
For inference, the system employs Markovian RSA to leverage test-time compute for improved accuracy. This method generates multiple candidate reasoning traces and aggregates them by subsampling tails from the population. The process creates aggregation prompts that combine the original question with candidate tails, allowing the model to synthesize a single improved solution. This approach bounds the context size for aggregation while enabling deep reasoning across multiple rounds.
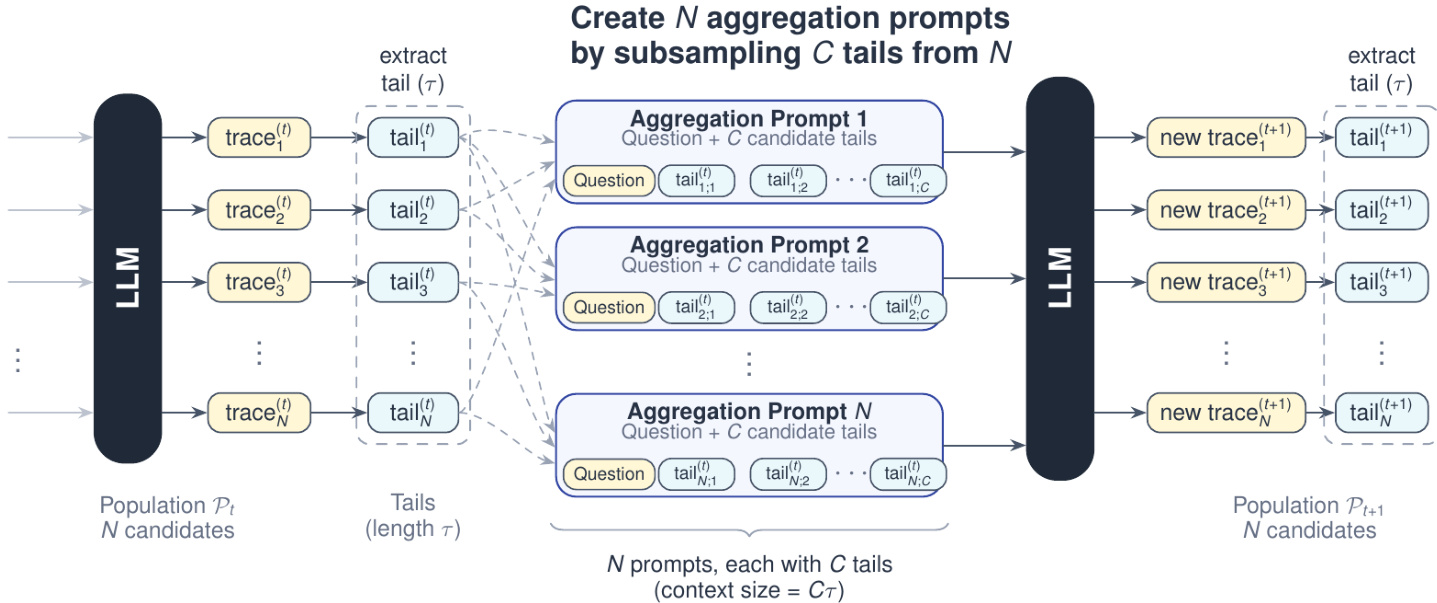
Experiment
Evaluations utilizing the Zyphra harness compare ZAYA1-8B against significantly larger open-weight models to assess reasoning capabilities under standard and test-time compute settings. Results demonstrate that Markovian RSA enables efficient inference scaling, allowing the compact model to approach frontier math performance while maintaining bounded context lengths. Post-training experiments reveal that reinforcement learning yields substantial gains over supervised fine-tuning with minimal optimization steps, highlighting the model's sample efficiency. Ultimately, the study concludes that small active-parameter models can rival larger systems on reasoning tasks when augmented with structured test-time compute, despite remaining gaps in agentic and factual benchmarks.
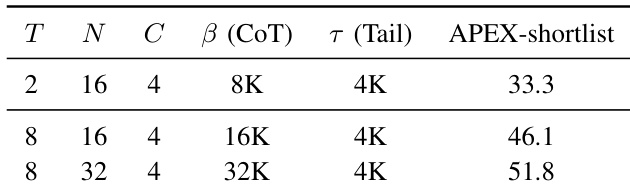
The authors compare the SFT checkpoint against the final ZAYA1-8B model to measure the aggregate effect of the post-training RL cascade. The results indicate a universal performance boost across all evaluated benchmarks, with the most pronounced improvements occurring in mathematical reasoning and coding tasks. Mathematical reasoning benchmarks exhibit the largest performance gains relative to the SFT baseline. Coding tasks show significant improvement, while instruction-following benchmarks also register strong gains. General knowledge and agentic benchmarks demonstrate consistent positive growth, though to a lesser extent than reasoning tasks.
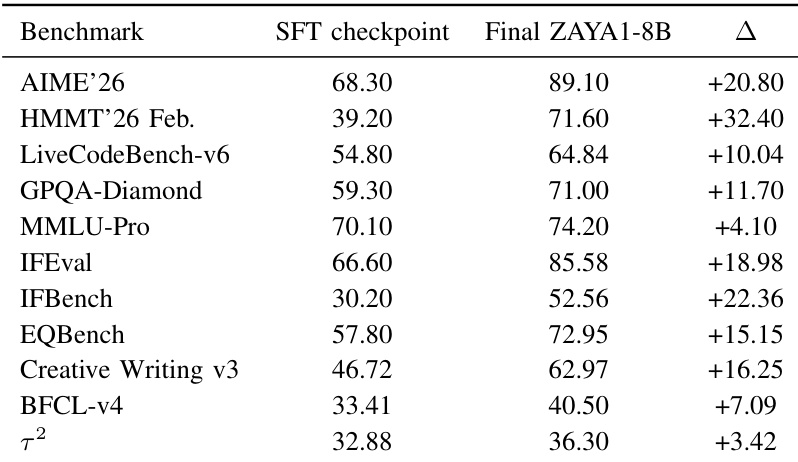
The the the table compares the data composition between the 32K midtraining phase and the 131K SFT phase. Long-CoT reasoning traces dominate the midtraining dataset, whereas the SFT phase diversifies the training mix by increasing the share of natively long-context data and web-based content. Long-CoT reasoning traces make up the majority of the midtraining dataset but decrease in the SFT phase. Natively long-context data sees a notable increase in the SFT phase compared to midtraining. The SFT phase includes a higher proportion of web, synthetic, and multilingual data than the midtraining phase.
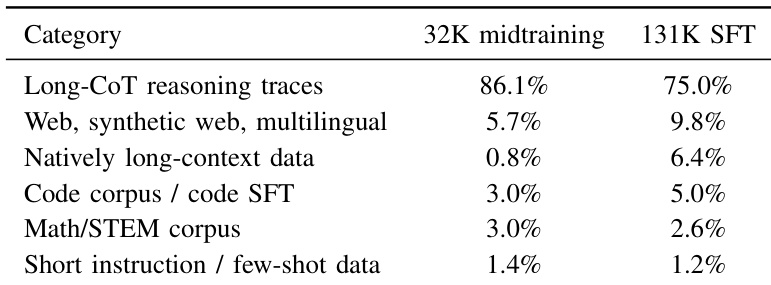
The authors assess how varying inference-time compute parameters affects performance on the APEX-shortlist benchmark using Markovian RSA. By adjusting aggregation rounds, population size, and reasoning budgets, they observe a clear positive correlation between compute intensity and model accuracy. The most resource-intensive configuration yields the highest performance, demonstrating the effectiveness of scaling test-time compute for difficult reasoning tasks. Increasing aggregation rounds and population size significantly boosts performance on the benchmark. The strongest configuration utilizes the largest reasoning budget and deepest aggregation depth. Performance scales positively with higher compute allocations across all tested parameters.
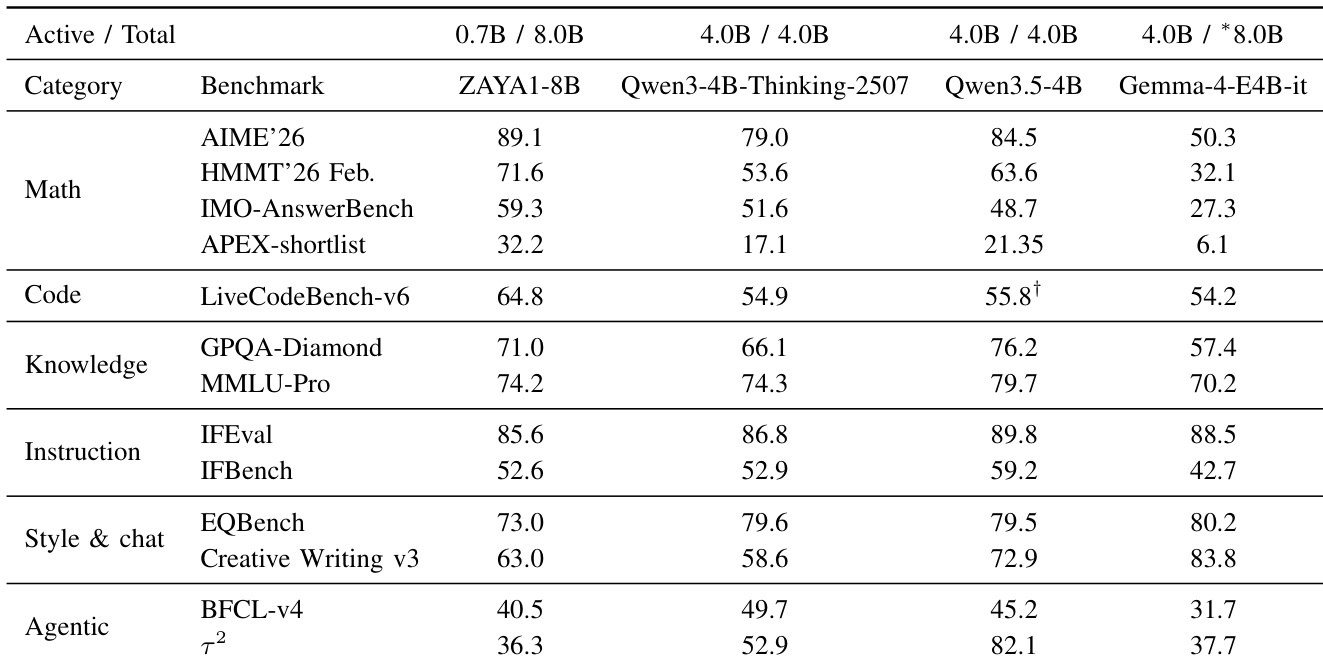
The data illustrates the distribution of prompt categories across two distinct reinforcement learning phases. While the general phase features a higher proportion of standard math and auxiliary code prompts, the code-focused phase shifts towards standard code and advanced reasoning prompts. Standard code prompts saw a notable increase in the second phase. The share of standard math prompts dropped significantly in the code-focused phase. Advanced reasoning prompts like Math TTC and RSA became more common in the later stage.
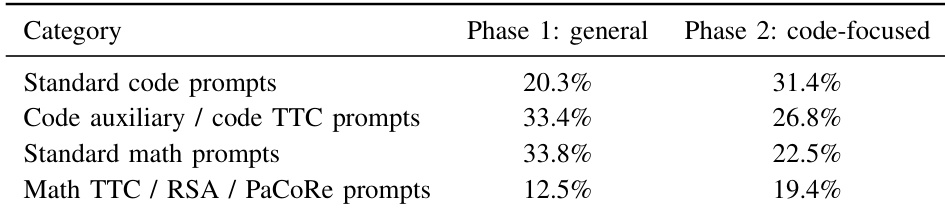
The authors compare ZAYA1-8B against open-weight reasoning models at a comparable scale, focusing on active and total parameter counts. Results show that ZAYA1-8B achieves leading performance in mathematics and coding tasks despite utilizing fewer active parameters than the comparator models. Conversely, the model exhibits lower scores on knowledge-heavy and instruction-following benchmarks relative to the 4B active-parameter baselines. ZAYA1-8B surpasses comparators on all listed mathematics benchmarks including AIME and HMMT. The model achieves the highest score on the LiveCodeBench-v6 coding evaluation. Qwen3.5-4B generally outperforms ZAYA1-8B on knowledge and instruction following metrics.
The authors evaluate the ZAYA1-8B model by comparing its final state against an SFT baseline and analyzing data composition shifts across training phases. Results confirm that the post-training RL cascade delivers universal performance improvements, particularly in mathematical reasoning and coding tasks, and scaling test-time compute parameters correlates positively with accuracy. Although the model achieves leading scores in math and coding against comparators despite using fewer active parameters, it exhibits lower performance on knowledge-heavy and instruction-following benchmarks relative to baselines with higher active parameter counts.