Command Palette
Search for a command to run...
平均モードの発声:1000層拡散トランスフォーマーにおける平均・分散分割残差
平均モードの発声:1000層拡散トランスフォーマーにおける平均・分散分割残差
Pengqi Lu
概要
ディフュージョントランスフォーマー(DiTs)を数百層規模にスケールアップすると、構造的な脆弱性が導入される。具体的には、ネットワークが沈黙的な、平均値支配型の崩壊状態に陥る可能性があり、この状態では token の表現が均質化され、中心化された分散(centered variation)が抑制される。メカニズム監査(mechanistic auditing)を通じて、我々はこの崩壊の引き金となる事象を「MMS(Mean Mode Screaming)」と特定した。MMSは、トレーニングが安定しているように見える場合でも発生しうる。これは、残差ライター(residual writers)に対する平均一貫性のある逆伝播ショックによって引き起こされ、深い残差ブランチを開き、ネットワークを平均値支配型の状態へと駆り立てる。我々は、この挙動が、これらの勾配を平均一貫性成分と中心化成分に正確に分解すること、および値が均質化された後に、Softmaxのヤコビアン行列の零空間を通じて注意機構のロジット勾配が構造的に抑制されることと相まって生じることを示す。この問題を解決するため、我々は「Mean-Variance Split (MV-Split) Residuals」を提案する。これは、個別に獲得された中心化された残差更新と、リーキーなトランク平均値(trunk-mean)への置換を組み合わせたものである。400層のシングルストリームDiTにおいて、MV-Splitは不安定なベースラインで崩壊を引き起こす発散型崩壊を防ぎ、全体スケジュールを通じてtoken等方性ゲイティング手法(LayerScaleなど)よりも大幅に優れた性能を維持しつつ、崩壊前のベースラインの軌跡に近く追従する。最後に、境界スケールにおけるスケール検証ランとして1000層のDiTを紹介し、このアーキテクチャが極端な深さでも安定してトレーニング可能であることを確立した。
One-sentence Summary
The authors propose Mean-Variance Split (MV-Split) Residuals to prevent Mean Mode Screaming, a mean-dominated collapse that homogenizes token representations in Diffusion Transformers, by decomposing backward gradients into centered residual updates and leaky trunk-mean replacements to stabilize training on a 400-layer single-stream DiT.
Key Contributions
- A mechanistic audit identifies Mean Mode Screaming (MMS) as the trigger for silent, mean-dominated collapse states in ultra-deep Diffusion Transformers, demonstrating how exact gradient decomposition into mean-coherent and centered components systematically homogenizes token representations.
- This work introduces Mean-Variance Split (MV-Split) Residuals, a structural modification that decouples residual pathways to apply independent scaling to mean and centered gradient components. By damping only the mean path while preserving the centered update, the method circumvents the convergence slowdown caused by isotropic gating techniques like ReZero and LayerScale.
- Training experiments on a 400-layer single-stream Diffusion Transformer demonstrate that MV-Split Residuals prevent divergent collapse and stabilize optimization without sacrificing representation diversity across deep layers.
Introduction
Scaling laws establish model depth as a critical driver of generative performance, making ultra-deep Diffusion Transformers highly valuable but vulnerable to sudden, unexplained training collapses. Previous depth stabilization techniques address these failures by uniformly shrinking residual branches, which inadvertently dampens the centered signal needed for spatial feature learning and slows convergence. The authors identify this phenomenon as Mean Mode Screaming, where geometric asymmetries between token subspaces cause representations to homogenize and gradient updates to lock into a collapsed state. To overcome this limitation, the authors leverage MV-Split Residuals to decouple the mean and centered pathways, applying targeted gating that preserves the centered signal while stabilizing the mean path. This approach enables reliable training of ultra-deep architectures without sacrificing convergence speed.
Method
The authors leverage a minimal single-stream Diffusion Transformer (DiT) architecture to study the failure dynamics of ultra-deep models. The backbone consists of a Post-Norm residual chain, where each layer applies RMSNorm to the sum of the input and the output of a transformer block. The model processes a concatenated sequence of VAE-encoded image tokens and text embeddings, relying on self-attention to handle all multimodal interactions. Positional encoding is applied using a 2D extension of RoPE to image tokens, while text tokens are left unencoded. The residual writers, specifically the attention output projection WO and the feed-forward network (FFN) output projection W2, are zero-initialized, a standard practice that isolates the failure dynamics to the residual propagation path. Training is performed using a Rectified Flow matching objective, which predicts the vector field from noise to data along a linear interpolation path. 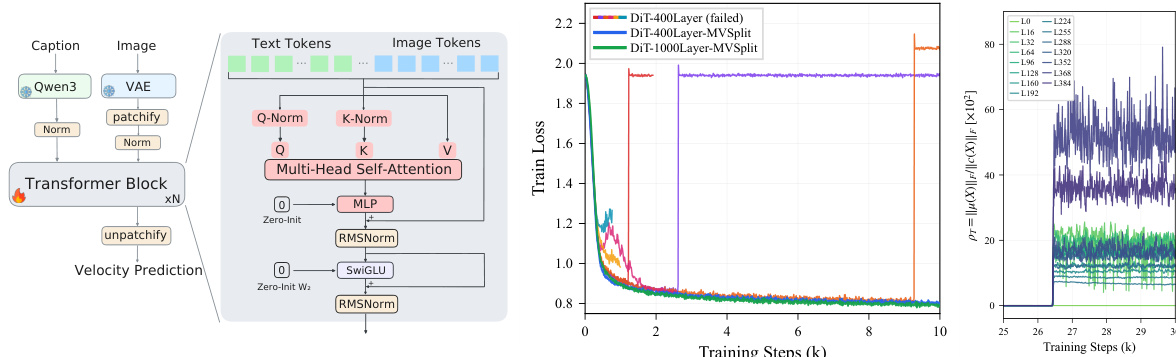
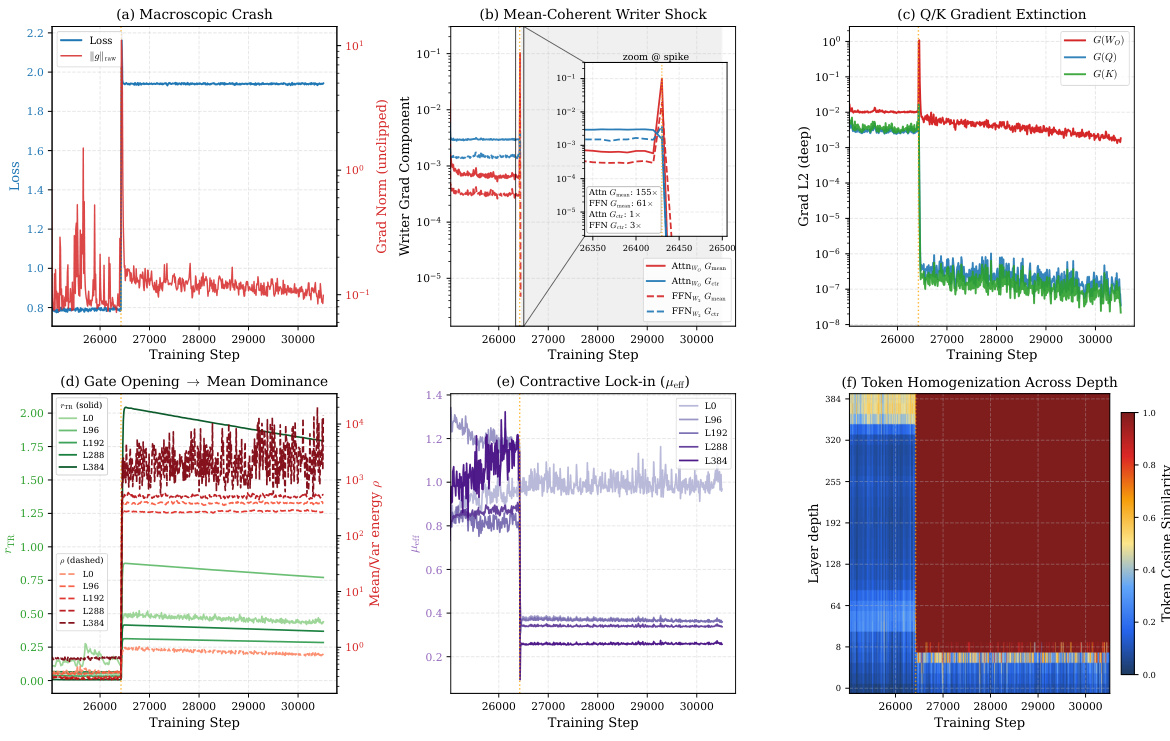
The core failure mode identified is a mean-dominated collapse, triggered by a phenomenon termed Mean Mode Screaming (MMS). This occurs when the gradients on the residual writers become dominated by a mean-coherent component, which scales as O(T) when token representations and their adjoints align. The authors show that the gradient on a token-wise linear map W decomposes exactly into a mean-coherent rank-1 component, ΔWμ=Tδˉyˉ⊤, and a centered component, ΔWc=∑tδ~ty~t⊤. The mean-coherent component grows when representations and adjoints become aligned, leading to a sharp spike in the gradient norm. This spike is followed by a forward collapse where the token representations homogenize, and the attention logit gradients are suppressed through the null space of the Softmax Jacobian, as the value vectors become constant. 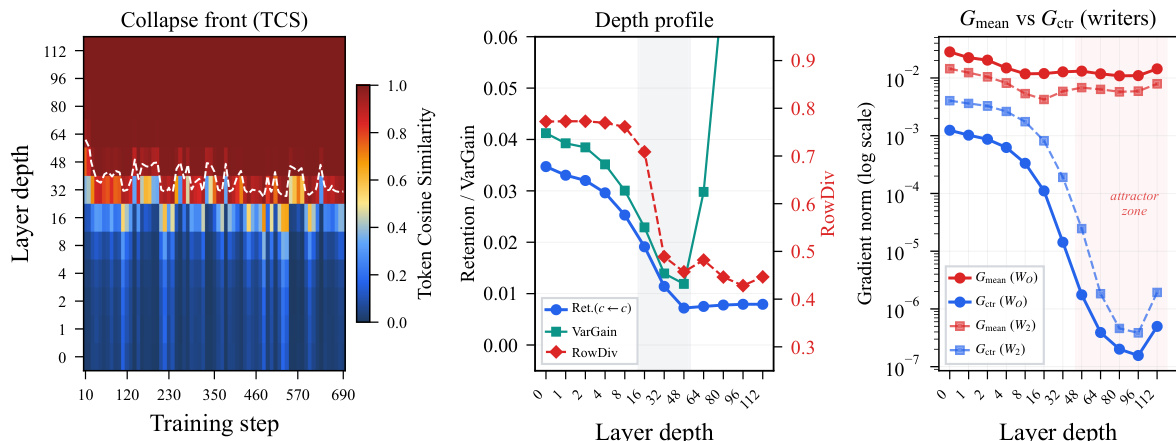
To address this, the authors propose Mean-Variance Split (MV-Split) Residuals. This method decouples the residual merge into two separate pathways: a centered path and a mean path. The standard Post-Norm merge Xl+1=RMSNorm(Xl+Fl) is replaced with a subspace-routed merge: Zl=Xl+β⊙(PFl)+α⊙J(Fl−Xl), followed by RMSNorm. Here, J and P are the projection operators onto the sequence mean and centered variation subspaces, respectively, and α,β are per-feature learnable vectors. The centered path, with gain β, updates the token-specific variation, while the mean path, with gain α, acts as a leaky integrator for the trunk mean, contracting it by 1−αd before adding the new mean correction. This design ensures that the mean-coherent gradient component is damped independently of the centered update, interrupting the self-reinforcing amplification loop. The gradient flowing back into the branch is also split, with the mean and centered components receiving independent gains. 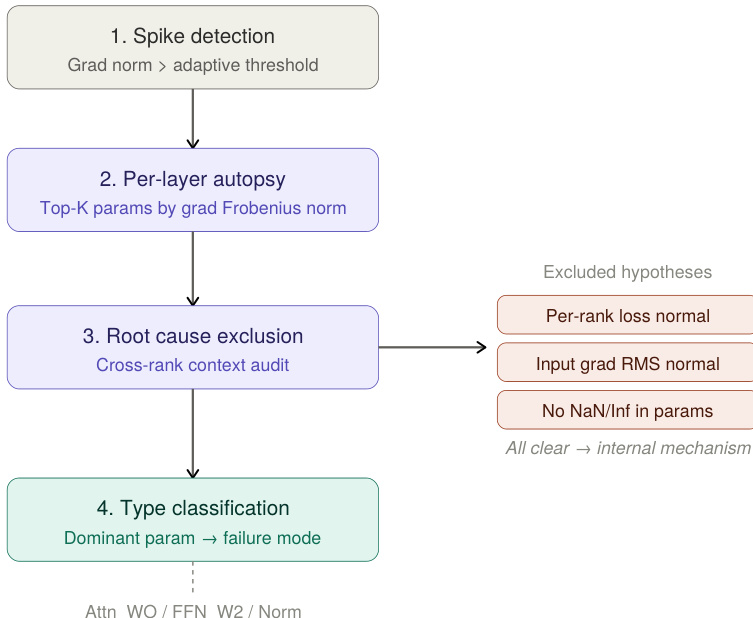
Experiment
The experiments evaluate a 400-layer and 1000-layer DiT architecture trained on ImageNet latents, comparing an un-stabilized baseline, LayerScale, and the proposed MV-Split method under explicit stability constraints. Mechanistic tracing and gradient decomposition validate that training collapse originates from a structural subspace imbalance where residual writers lose signed cancellation, allowing mean-coherent updates to dominate and homogenize tokens. MV-Split successfully addresses this by selectively bounding the problematic mean-coherent gradient mode while preserving centered variation, thereby shifting the stability-constrained quality frontier without uniformly suppressing learning signals. Subsequent controls confirm this divergence mechanism is independent of initialization schemes, while timestep probing justifies the method's targeted gain-limiting design, and the 1000-layer run demonstrates that this geometric intervention remains robust and effective at greater depths.
The authors analyze a 400-layer model's divergence event, focusing on the gradient spike that occurs during training. The analysis reveals a mode-selective amplification of the mean-coherent component of the writer gradients, leading to a collapse in token variation across depth. The results show that a residual design with separate gain control for mean and centered components maintains stable gradient behavior and preserves token variation, enabling deeper training without collapse. The gradient spike amplifies the mean-coherent component of writer gradients while suppressing the centered component, leading to token homogenization. A residual design with separate gain control for mean and centered components maintains stable gradient behavior and avoids the collapse seen in other designs. The model maintains stable training over deep layers, with the mean-coherent gradient component remaining bounded while the centered component stays in a higher stable band.
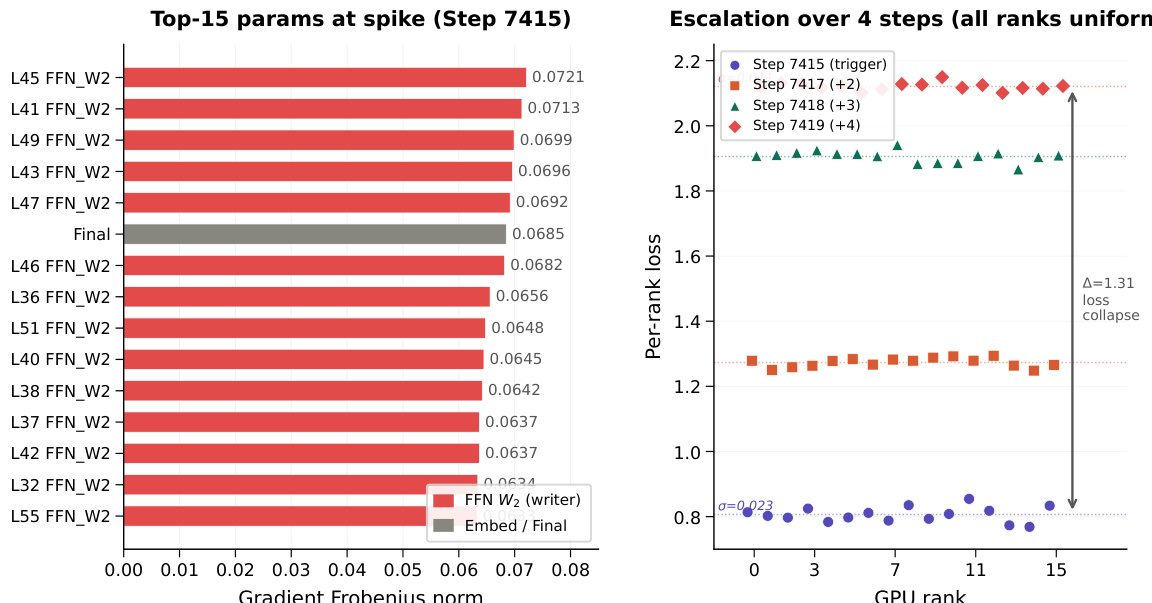
The authors analyze the behavior of different residual stabilization methods in deep models, focusing on gradient dynamics during training. Results show that while un-stabilized baselines exhibit a sharp spike in mean-coherent writer gradients followed by divergence, MV-Split effectively bounds this component while preserving centered gradients, leading to stable training. LayerScale also bounds the mean-coherent gradient but at the cost of suppressing centered gradients, resulting in slower convergence. MV-Split bounds the mean-coherent writer gradient while preserving a higher level of centered gradient activity compared to LayerScale. Un-stabilized baselines show a sharp spike in mean-coherent writer gradients, leading to divergence, whereas MV-Split avoids this collapse. LayerScale reduces both mean-coherent and centered gradients uniformly, resulting in slower convergence compared to MV-Split.
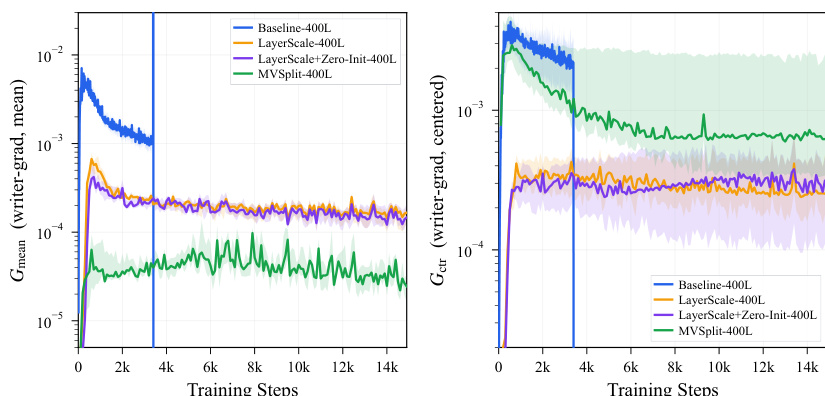
The authors compare multiple deep transformer models on ImageNet-2012 latents, focusing on stability and convergence under ultra-deep training. Results show that un-stabilized baselines diverge during training, while MV-Split maintains stable gradient norms and achieves better quality metrics over time compared to LayerScale. The analysis highlights that MV-Split effectively controls the mean-coherent gradient mode without suppressing centered variation, enabling sustained training at 1000 layers. Un-stabilized baselines diverge during training, while MV-Split maintains stable gradient norms and avoids divergence. MV-Split achieves better quality metrics over time compared to LayerScale, preserving early convergence speed without collapse. MV-Split bounds the mean-coherent gradient component while preserving a higher stable band for centered gradients, supporting its mechanism for stability control.
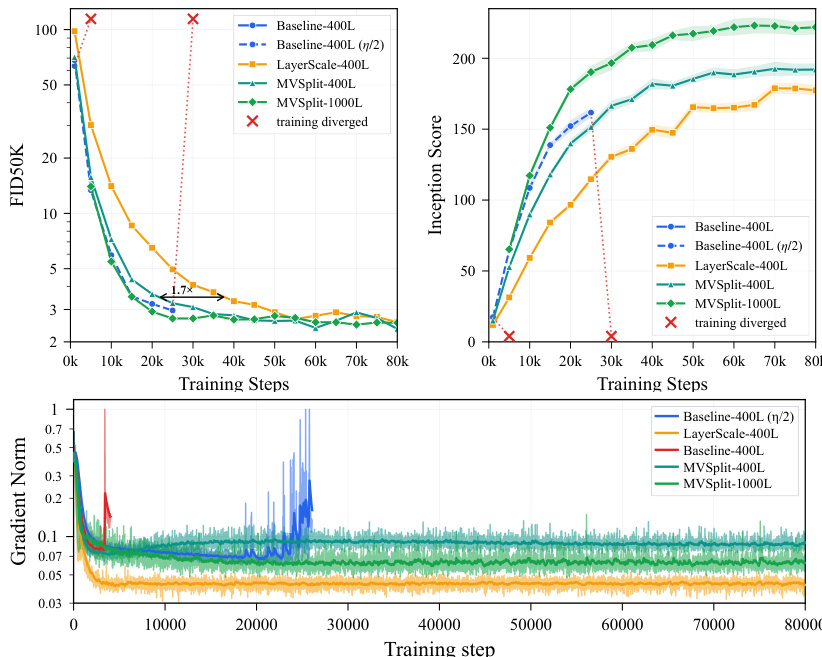
The authors analyze the divergence behavior in ultra-deep models, identifying a mode-selective gradient shock that amplifies in the mean-coherent direction while Q/K gradients collapse, leading to token homogenization and a mean-dominated failure state. They evaluate stabilization methods, showing that MV-Split maintains higher gradient stability and better convergence than baseline approaches without sacrificing early learning speed, and demonstrate that this stabilization extends to 1000-layer models while preserving text-conditioned generation quality. A gradient shock selectively amplifies in the mean-coherent writer direction, causing Q/K gradients to collapse and leading to token homogenization across depth. MV-Split stabilizes the model by bounding the mean-coherent gradient component while preserving a higher stable centered gradient band, improving convergence without sacrificing early speed. The stabilization mechanism extends to 1000-layer models, maintaining stable training and usable text-conditioned generation quality beyond the depth where other methods fail.
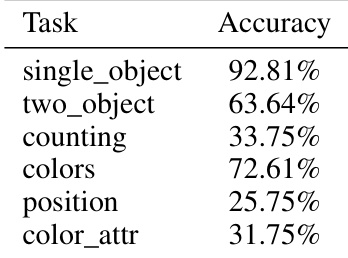
{"summary": "The authors evaluate the text-conditioned generation performance of a 1000-layer MV-Split model using GenEval and DPG-Bench tasks. Results show strong accuracy on single-object and counting tasks, with moderate performance on color and position tasks, and lower accuracy on color attribute recognition. The model demonstrates robust generation across diverse categories, as shown in visual samples.", "highlights": ["The model achieves high accuracy on single-object and counting tasks, indicating strong performance on basic visual understanding.", "Performance is moderate on color and position tasks, suggesting limitations in handling more complex visual attributes.", "The model shows lower accuracy on color attribute recognition, highlighting challenges in fine-grained attribute prediction."]
The experiments evaluate training stability and generation quality in ultra-deep transformer models by comparing un-stabilized baselines, LayerScale, and the proposed MV-Split method across hundreds to thousands of layers. Analysis reveals that un-stabilized architectures diverge due to gradient spikes that homogenize token representations, while LayerScale curbs instability at the cost of suppressed gradient variation and slower convergence. MV-Split successfully isolates and bounds problematic mean-coherent gradients while preserving essential centered gradient activity, enabling robust training at extreme depths without compromising early learning dynamics or text-conditioned generation capabilities.