HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

MAKIEVAL : Un cadre automatique multilingue basé sur WiKIdata pour l'évaluation de la sensibilisation culturelle des LLMs

GeneralVLA-2 : Reconstruction consciente de la géométrie et mémoire gouvernée pour la planification robotique







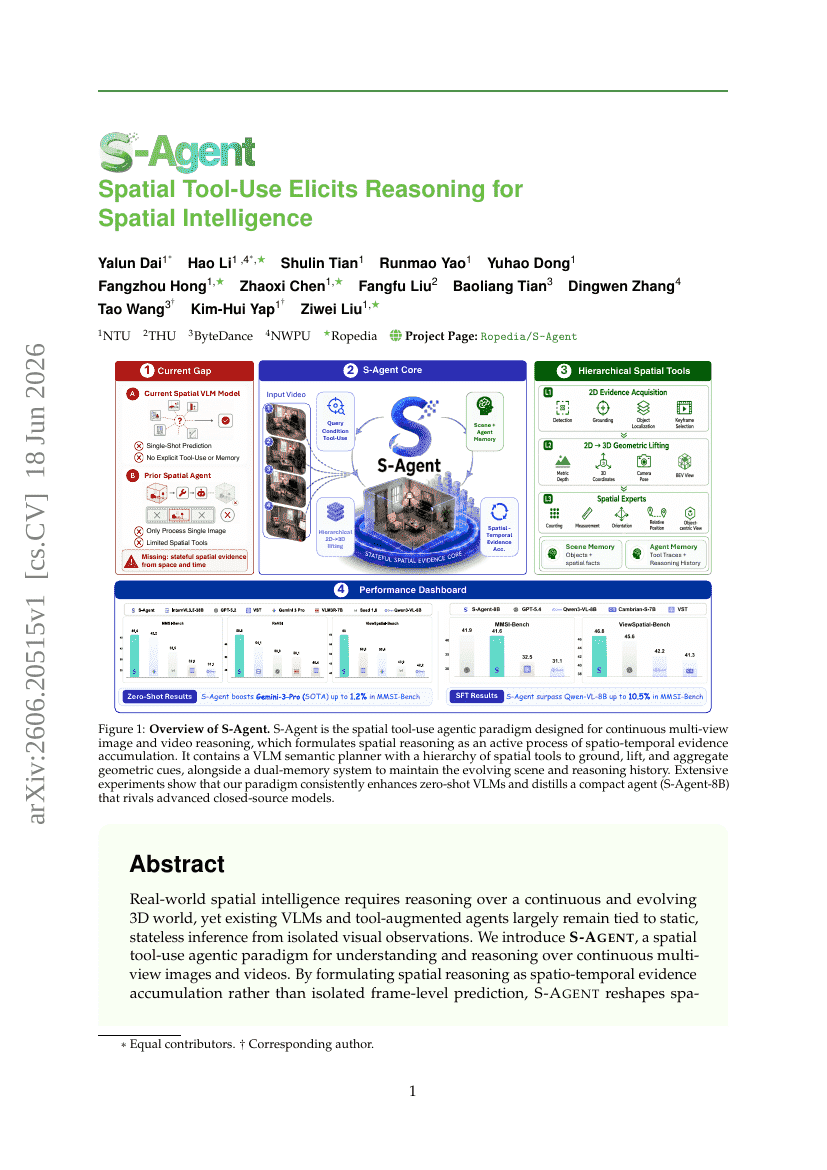















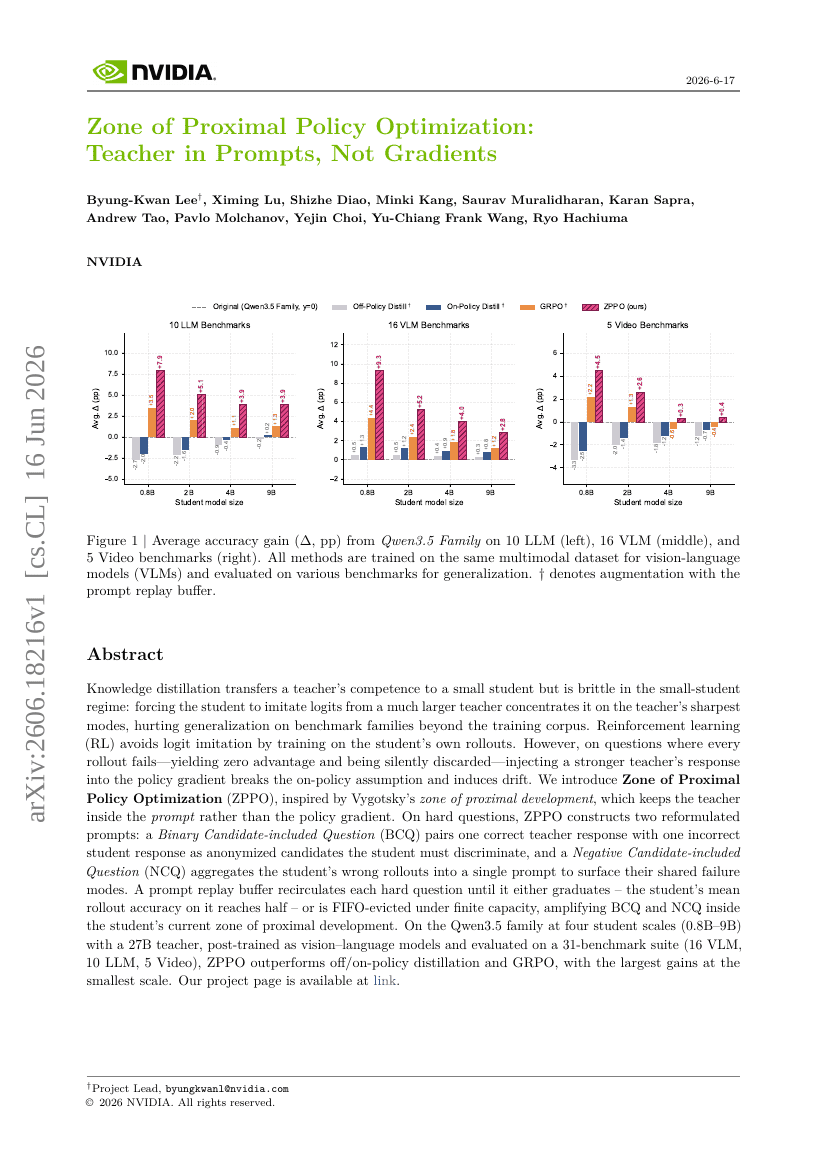


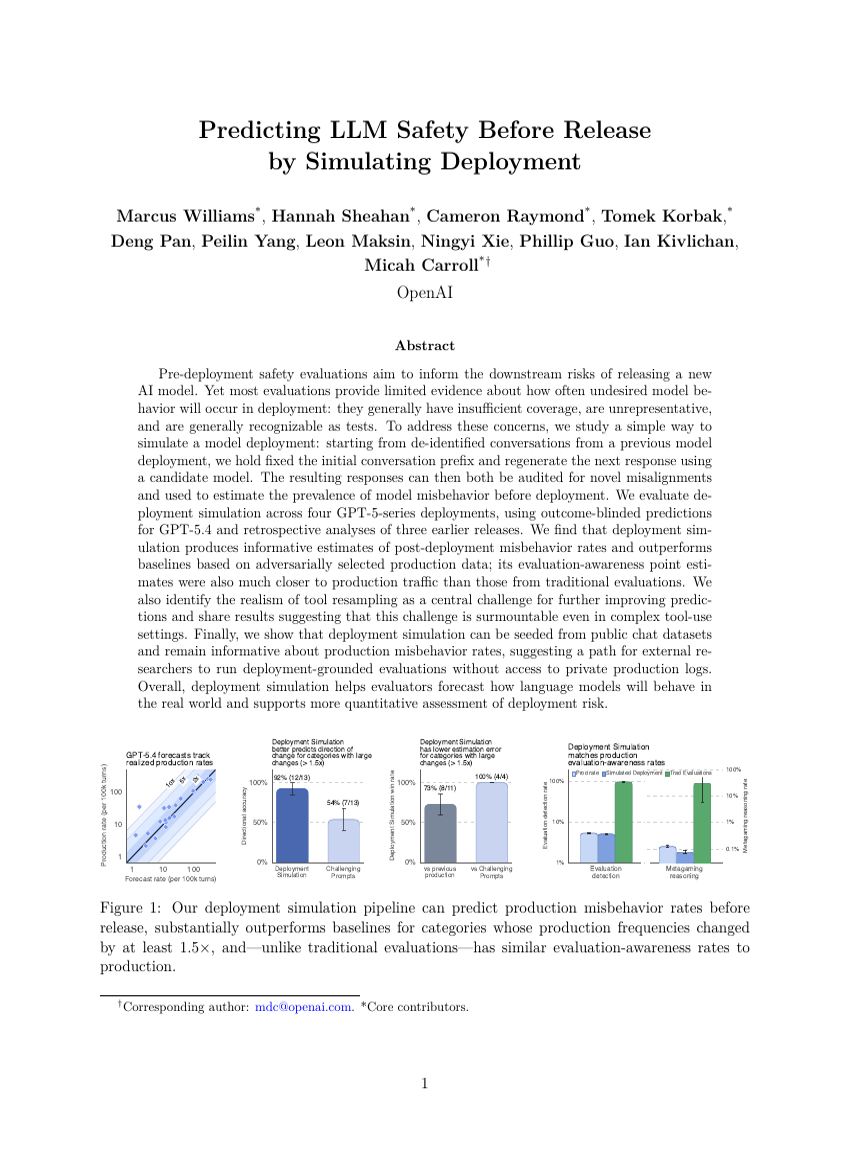



MAKIEVAL : Un cadre automatique multilingue basé sur WiKIdata pour l'évaluation de la sensibilisation culturelle des LLMs
GeneralVLA-2 : Reconstruction consciente de la géométrie et mémoire gouvernée pour la planification robotique
Masquage Réflexif Multi-Tour Élicite le Raisonnement dans les Modèles de Diffusion par Masquage
BrainG3N : Un Tokeniseur à Double Usage pour la Génération Contrôlée d'IRM Cérébrales 3D
GateMem : Évaluation de la gouvernance de la mémoire dans les Agents à mémoire partagée Multi-Principal
MemSlides : Un cadre d'agent hiérarchique piloté par la mémoire pour la génération de diapositives personnalisée avec révision locale multi-tours
PerceptionDLM : Perception parallèle de régions avec des modèles de langage de diffusion multimodaux
Modèles mondiaux du code pour le jeu généraliste de jeux
Au-delà des classements statiques : validité prédictive pour l'évaluation des agents LLM
S-Agent : Utilisation d'outils spatiaux élicite le raisonnement pour l'intelligence spatiale
Multi-LCB : Extension de LiveCodeBench à plusieurs langages de programmation
Apprentissage Robotique Agentic Ludique
DragMesh-2 : Interaction main-objet adroite physiquement plausible avec des objets articulés
Moebius : cadre léger d'inpainting d'images de 0.2B avec des performances de niveau 10B
EfficientRollout : Décodage auto-spéculatif conscient du système pour les rollouts RL
Faites confiance au bon enseignant : Auto-distillation consciente de la qualité pour l'ancrage GUI
Renforcement du raisonnement à double voie dans les modèles de langage visuel spatiaux
Les interventions SAE sont peu fiables : Récupération post-intervention des comportements supprimés
Kairos: Une pile de modèles du monde native pour l'IA physique
Guava : Un harnais efficace et universel pour la manipulation incarnée
Au-delà de l'observation actuelle : Évaluation des grands modèles de langage multimodaux dans les jeux non-markoviens contrôlables
LifeSciBench : Évaluer les Language Models sur des tâches réalistes et de niveau expert en sciences de la vie
TRIAGE : Raisonnement dialectique pour la prédiction de risque explicable sur des séries temporelles médicales à échantillonnage irrégulier avec des LLM
LectūraAgents : Un cadre Multi-Agent pour l'apprentissage personnalisé adaptatif assisté par IA et l'enseignement incarné
GameCraft-Bench : Les Agents peuvent-ils construire des jeux jouables de bout en bout dans un moteur de jeu réel ?
Zone d'optimisation de la politique proximale : enseignant dans les invites, pas dans les gradients
ACE-Ego-0 : Unification des données egocentriques humaines et robotiques pour le pré-entraînement VLA
LoopCoder-v2 : Ne boucler qu'une seule fois pour une mise à l'échelle efficace du calcul en phase de test
Prédire la sécurité des LLM avant leur mise en service grâce à la simulation du déploiement
FastContext : Entraînement d'un Explorateur de Dépôt Efficace pour les Agents de Codage
VibeThinker-3B : Explorer la frontière du raisonnement vérifiable dans les petits modèles de langage
DreamX-World 1.0 : Un modèle du monde interactif à usage général
Masquage Réflexif Multi-Tour Élicite le Raisonnement dans les Modèles de Diffusion par Masquage
BrainG3N : Un Tokeniseur à Double Usage pour la Génération Contrôlée d'IRM Cérébrales 3D
GateMem : Évaluation de la gouvernance de la mémoire dans les Agents à mémoire partagée Multi-Principal
MemSlides : Un cadre d'agent hiérarchique piloté par la mémoire pour la génération de diapositives personnalisée avec révision locale multi-tours
PerceptionDLM : Perception parallèle de régions avec des modèles de langage de diffusion multimodaux
Modèles mondiaux du code pour le jeu généraliste de jeux
Au-delà des classements statiques : validité prédictive pour l'évaluation des agents LLM
S-Agent : Utilisation d'outils spatiaux élicite le raisonnement pour l'intelligence spatiale
Multi-LCB : Extension de LiveCodeBench à plusieurs langages de programmation
Apprentissage Robotique Agentic Ludique
DragMesh-2 : Interaction main-objet adroite physiquement plausible avec des objets articulés
Moebius : cadre léger d'inpainting d'images de 0.2B avec des performances de niveau 10B
EfficientRollout : Décodage auto-spéculatif conscient du système pour les rollouts RL
Faites confiance au bon enseignant : Auto-distillation consciente de la qualité pour l'ancrage GUI
Renforcement du raisonnement à double voie dans les modèles de langage visuel spatiaux
Les interventions SAE sont peu fiables : Récupération post-intervention des comportements supprimés
Kairos: Une pile de modèles du monde native pour l'IA physique
Guava : Un harnais efficace et universel pour la manipulation incarnée
Au-delà de l'observation actuelle : Évaluation des grands modèles de langage multimodaux dans les jeux non-markoviens contrôlables
LifeSciBench : Évaluer les Language Models sur des tâches réalistes et de niveau expert en sciences de la vie
TRIAGE : Raisonnement dialectique pour la prédiction de risque explicable sur des séries temporelles médicales à échantillonnage irrégulier avec des LLM
LectūraAgents : Un cadre Multi-Agent pour l'apprentissage personnalisé adaptatif assisté par IA et l'enseignement incarné
GameCraft-Bench : Les Agents peuvent-ils construire des jeux jouables de bout en bout dans un moteur de jeu réel ?
Zone d'optimisation de la politique proximale : enseignant dans les invites, pas dans les gradients
ACE-Ego-0 : Unification des données egocentriques humaines et robotiques pour le pré-entraînement VLA
LoopCoder-v2 : Ne boucler qu'une seule fois pour une mise à l'échelle efficace du calcul en phase de test
Prédire la sécurité des LLM avant leur mise en service grâce à la simulation du déploiement
FastContext : Entraînement d'un Explorateur de Dépôt Efficace pour les Agents de Codage
VibeThinker-3B : Explorer la frontière du raisonnement vérifiable dans les petits modèles de langage
DreamX-World 1.0 : Un modèle du monde interactif à usage général