Command Palette
Search for a command to run...
VibeThinker-3B : Explorer la frontière du raisonnement vérifiable dans les petits modèles de langage
VibeThinker-3B : Explorer la frontière du raisonnement vérifiable dans les petits modèles de langage
Sen Xu Shixi Liu Wei Wang Jixin Min Yingwei Dai Zhibin Yin Yirong Chen Xin Zhou Junlin Zhang
Résumé
Ce rapport technique présente VibeThinker-3B, un modèle dense et compact de 3B paramètres conçu pour étudier jusqu'où le raisonnement vérifiable peut être poussé dans un régime strictement dédié aux petits modèles. S'appuyant sur le paradigme post-entraînement Spectrum-to-Signal, nous améliorons systématiquement le modèle via un pipeline optimisé comprenant un ajustement fin supervisé basé sur un curriculum, un apprentissage par renforcement multi-domaines et une auto-distillation hors ligne. Les évaluations expérimentales montrent que VibeThinker-3B atteint des performances de pointe sur des tâches vérifiables particulièrement exigeantes. Plus précisément, il obtient un score de 94,3 sur AIME26 (s'élevant à 97,1 avec le test-time scaling au niveau des affirmations), un Pass@1 de 80,2 sur LiveCodeBench v6, et démontre une forte généralisation hors distribution avec un taux d'acceptation de 96,1 % sur des concours LeetCode récents et inédits. Cela le place effectivement dans la fourchette de performance des systèmes de raisonnement de premier plan, rivalisant avec ou dépassant des modèles phares plusieurs ordres de grandeur plus volumineux, tels que DeepSeek V3.2, GLM-5 et Gemini 3 Pro. Par ailleurs, un score de 93,4 sur IFEval confirme que cette amélioration extrême du raisonnement ne compromet pas la stricte contrôlabilité des instructions. En prolongeant nos travaux précédents sur un modèle de 1,5B paramètres, ces résultats étayent l'Hypothèse de Compression-Couverture Paramétrique, qui considère le raisonnement vérifiable comme compressible au sein de noyaux de raisonnement compacts, tandis que les connaissances en domaine ouvert et les compétences à usage général nécessitent une couverture paramétrique étendue couvrant les faits, les concepts et les scénarios à longue traîne. Cette perspective suggère que les modèles compacts ne constituent pas de simples substituts optimisés pour le déploiement, mais représentent une voie complémentaire vers des performances de pointe dans des régimes de capacités denses en paramètres.
One-sentence Summary
VibeThinker-3B, a 3B-parameter model optimized through curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation, achieves frontier-level verifiable reasoning by scoring 94.3 on AIME26, 80.2 Pass@1 on LiveCodeBench v6, and 96.1% acceptance on unseen LeetCode contests, thereby demonstrating that specialized reasoning capabilities can be efficiently compressed into compact architectures to rival parameter-dense flagship models.
Key Contributions
- This report introduces VibeThinker-3B, a 3-billion parameter dense model optimized through a pipeline integrating curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation to advance verifiable reasoning in a strictly small-model regime.
- Evaluations demonstrate that the model achieves frontier-level performance on demanding benchmarks, scoring 94.3 on AIME26, 80.2 Pass@1 on LiveCodeBench v6, and 96.1% acceptance on out-of-distribution LeetCode contests. A 93.4 score on IFEval further confirms that this reasoning enhancement preserves strict instruction controllability.
- The analysis establishes the Parametric Compression-Coverage Hypothesis, which categorizes verifiable reasoning as a parameter-dense capability that compresses into reusable cores rather than requiring the expansive coverage needed for general knowledge. This framework positions compact model development as a complementary trajectory to traditional parameter scaling laws.
Introduction
The authors leverage reinforcement learning to advance logical reasoning in language models, a domain where frontier performance currently relies on scaling laws that demand models with hundreds of billions of parameters. Small language models present a compelling alternative due to their deployment efficiency, yet they face persistent challenges in mastering complex mathematical derivations and long-horizon reasoning, often being dismissed as insufficient substitutes for larger systems. To overcome these limitations, the authors develop VibeThinker-3B, a 3B parameter model that achieves competitive performance against top-tier LLMs by applying an optimized post-training pipeline built on the Spectrum-to-Signal paradigm. This approach integrates curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation to compress verifiable reasoning into a dense core, ultimately proposing the Parametric Compression-Coverage Hypothesis to demonstrate that compact models offer a distinct and complementary path toward high-density reasoning capabilities.
Dataset

-
Dataset composition and sources: The authors construct a multi-domain supervised dataset tailored for the Supervised Fine-Tuning (SFT) phase. The collection spans mathematics, competitive programming, STEM reasoning, general chat, and instruction following. Seed queries are drawn from existing high-quality datasets, specifically selecting mathematical problems with explicit final answers or clear solving rationales, and programming tasks with reliable unit tests or executable evaluation rules.
-
Key details for each subset: Mathematical and programming subsets drive an automated query expansion pipeline where seed samples are rewritten across multiple dimensions including concept composition, problem-solving skeletons, constraints, and evaluation objectives. Reasoning-intensive subsets (math, code, STEM) adopt a multi-path distillation strategy that retains complete intermediate reasoning steps rather than single standard solutions. All expanded queries receive pseudo-labels generated through independent sampling by strong teacher models, with final labels determined via majority voting.
-
How the paper uses the data: The authors employ this curated dataset to establish a stable cold-start policy for subsequent reinforcement learning. Instead of applying fixed mixture ratios, the data is stratified by reasoning chain length and problem difficulty to facilitate a curriculum-based SFT schedule. This structure explicitly preserves a multi-solution spectrum, giving the model exposure to diverse decomposition methods and verification strategies before on-policy sampling begins.
-
Additional processing and metadata: A three-tier quality control pipeline filters the dataset before training. N-gram analysis removes repetitive segments, templated degeneration patterns, and benchmark contamination. Capable LLMs then evaluate query quality to eliminate incomplete descriptions, flawed logic, or poorly defined knowledge targets. Finally, trace correctness is verified through answer validation, code sandbox execution, and LLM majority voting to discard invalid reasoning paths. The authors organize the final filtered data by difficulty and chain length to support structured curriculum learning.
Method
The authors present a staged post-training pipeline for VibeThinker-3B, built upon the Qwen2.5-Coder-3B base model. The framework is designed to systematically elicit and consolidate reasoning capabilities through data synthesis, diversity-oriented supervised fine-tuning, multi-domain reinforcement learning, offline self-distillation, and instruction-oriented alignment. This approach continues the Spectrum-to-Signal Principle, where SFT constructs a diverse solution space and Reinforcement Learning amplifies high-value reasoning signals.
As shown in the framework diagram below:
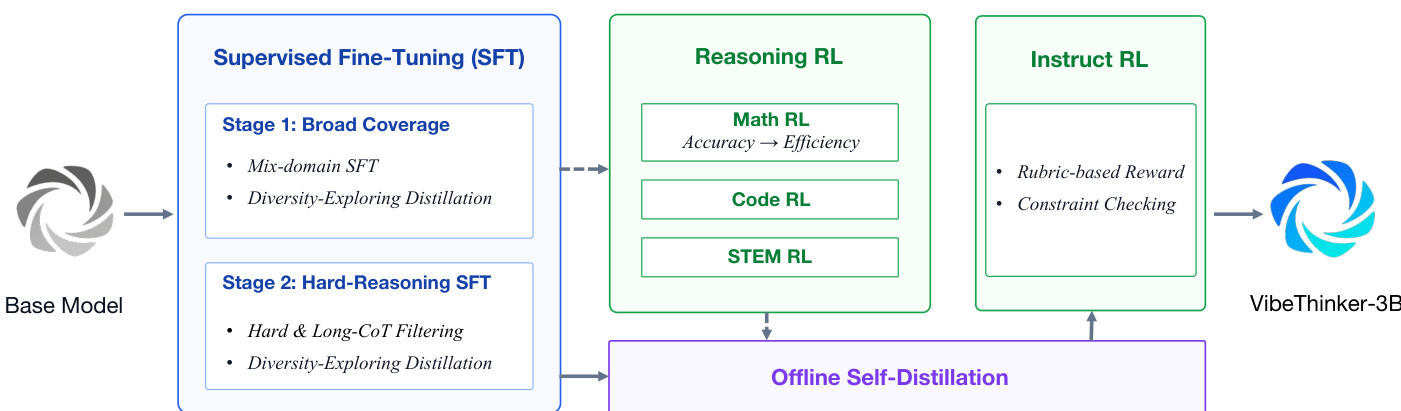
The pipeline begins with a two-stage Supervised Fine-Tuning process. The first stage focuses on broad coverage using mix-domain SFT and diversity-exploring distillation. The second stage targets hard reasoning through hard and long-chain-of-thought filtering, again utilizing diversity-exploring distillation to transition the model from broad capability coverage to deep, long-horizon reasoning.
Following SFT, the model undergoes multi-domain Reasoning RL using the MaxEnt-Guided Policy Optimization (MGPO) algorithm. MGPO dynamically selects prompts near the model's capability boundary. For each prompt q, the system samples G responses and computes empirical group accuracy. Prompts with intermediate correctness are assigned higher weights to focus updates on uncertain regions. The optimization objective is defined as:
IMGPO(θ)=Eq,{yi}G1i=1∑G∣yi∣1t=1∑∣yi∣min(ρi,t(θ)w(q)Ai,clip(ρi,t(θ),1−ε,1+ε)w(q)Ai)The authors apply this to Math, Code, and STEM domains. Notably, the Math RL phase includes a Long2Short stage to optimize reasoning efficiency without compromising accuracy by redistributing rewards based on response length.
After the core reasoning RL, the pipeline proceeds to an Offline Self-Distillation phase. The authors extract high-quality reasoning trajectories from the Math, Code, and STEM RL checkpoints. They employ a learning-potential filtering mechanism to estimate the distillation value of each trajectory for the student model. This involves computing a length-normalized negative log-likelihood to identify traces that are verified by the teacher but not yet well-modeled by the student.
The final stage is Instruct RL, which aligns the reasoning-enhanced model with user instructions. This stage utilizes a mixed instruction dataset and applies rubric-based rewards for open-ended prompts and rule-based validators for samples with explicit constraints. This ensures strict adherence to complex, multi-step instructions while preserving the elicited reasoning capabilities.
Experiment
The evaluation utilizes standard reasoning benchmarks, a claim-level reliability assessment strategy, and out-of-distribution coding contests to validate whether compact models can achieve top-tier logical performance without relying on massive parameter counts. The results demonstrate that the 3B model successfully enters the first-tier reasoning band on verifiable tasks, maintains robust instruction-following alignment, and generalizes effectively to novel algorithmic problems. While a clear capability gap persists on knowledge-intensive benchmarks, the experiments collectively confirm that reasoning proficiency and parametric memory are only partially coupled. Ultimately, the findings establish that optimized post-training and targeted test-time verification can effectively elevate compact models to competitive levels, proving that advanced reasoning is not strictly constrained by raw model size.
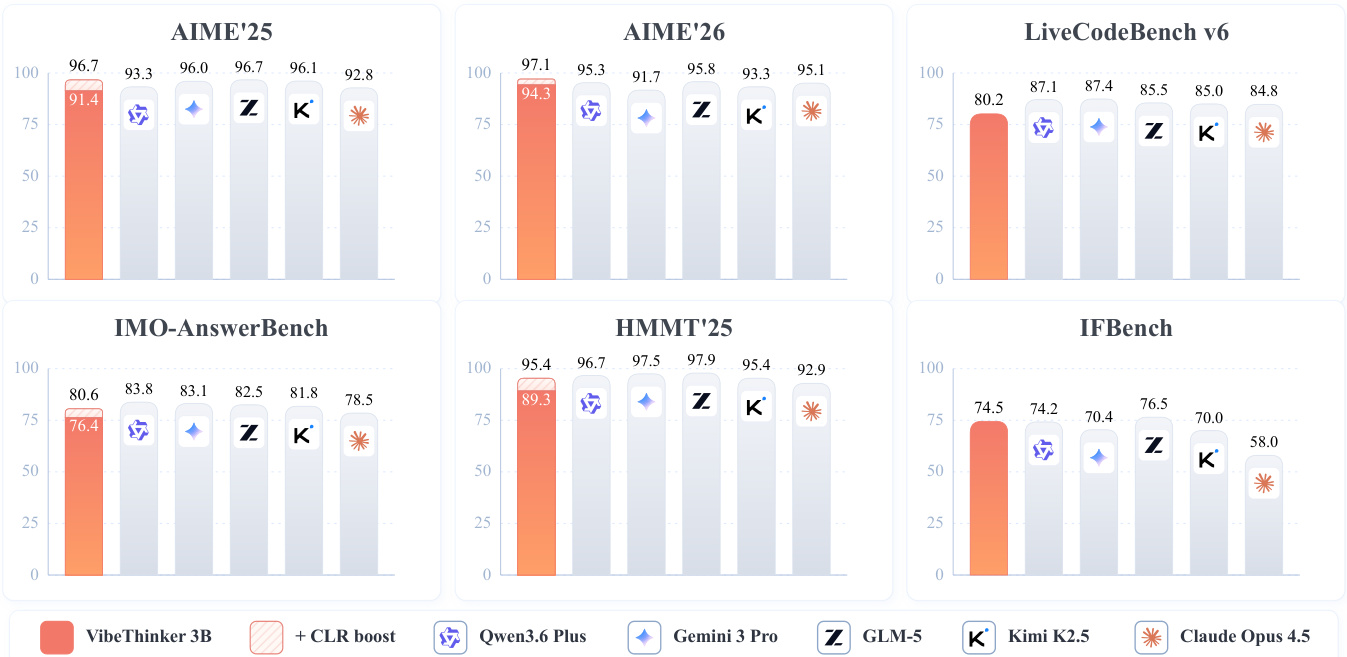
The experiment evaluates the reasoning performance of the compact VibeThinker-3B model against significantly larger systems on the IMO-AnswerBench benchmark. Despite having a fraction of the parameters of competitors, the model demonstrates superior base performance and, when enhanced with a test-time scaling strategy, achieves scores comparable to frontier models. VibeThinker-3B significantly outperforms much larger models such as MiniMax M2.7 and GPT-OSS-20B on the IMO-AnswerBench benchmark. Applying the CLR test-time scaling strategy boosts the model's performance to enter the frontier score band, matching the capabilities of top-tier systems like GLM-5 and Kimi K2.5. The results indicate that a compact model can rival or exceed the reasoning capabilities of systems with hundreds of billions of parameters on complex mathematical tasks.

The authors evaluate VibeThinker-3B, a compact model with a small parameter budget, against a diverse set of open-source and proprietary systems that are significantly larger. The results indicate that this smaller model achieves performance comparable to much larger systems on mathematical reasoning, coding, and instruction-following tasks. Furthermore, the integration of a test-time scaling strategy called Claim-Level Reliability Assessment (CLR) allows the model to close the gap with top-tier flagship models, particularly on verifiable reasoning benchmarks. VibeThinker-3B demonstrates competitive performance against models with parameter counts ranging from tens to hundreds of billions across mathematical and coding benchmarks. The addition of Claim-Level Reliability Assessment (CLR) significantly enhances the model's reasoning capabilities, enabling it to match or exceed the performance of leading proprietary and open-source systems on key benchmarks. The results suggest that compact models can achieve high-tier reasoning performance on verifiable tasks without requiring the massive parameter scales typically associated with such capabilities.
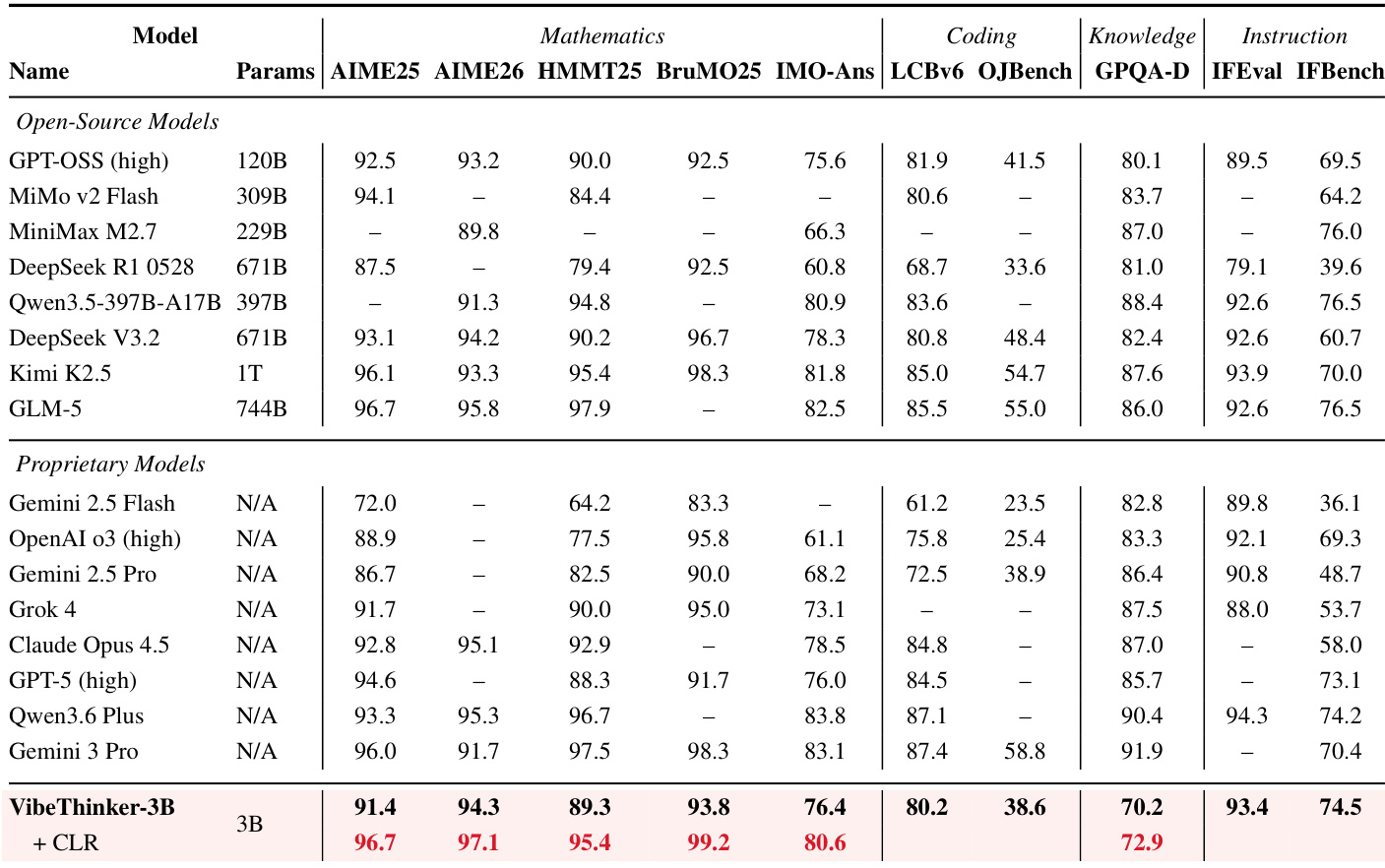
The authors evaluate VibeThinker-3B against a broad spectrum of smaller and significantly larger reasoning systems to determine the parameter capacity needed for first-tier performance. The results demonstrate that this compact model achieves superior performance across mathematics, coding, and instruction-following benchmarks, frequently outperforming models with significantly more parameters. The model achieves the highest scores in mathematics and coding benchmarks, surpassing competitors with significantly more parameters. It demonstrates robust instruction-following abilities, leading in instruction benchmarks while maintaining alignment with user constraints. The performance gap between the compact model and the largest systems is less pronounced on reasoning-heavy tasks compared to broad knowledge benchmarks.
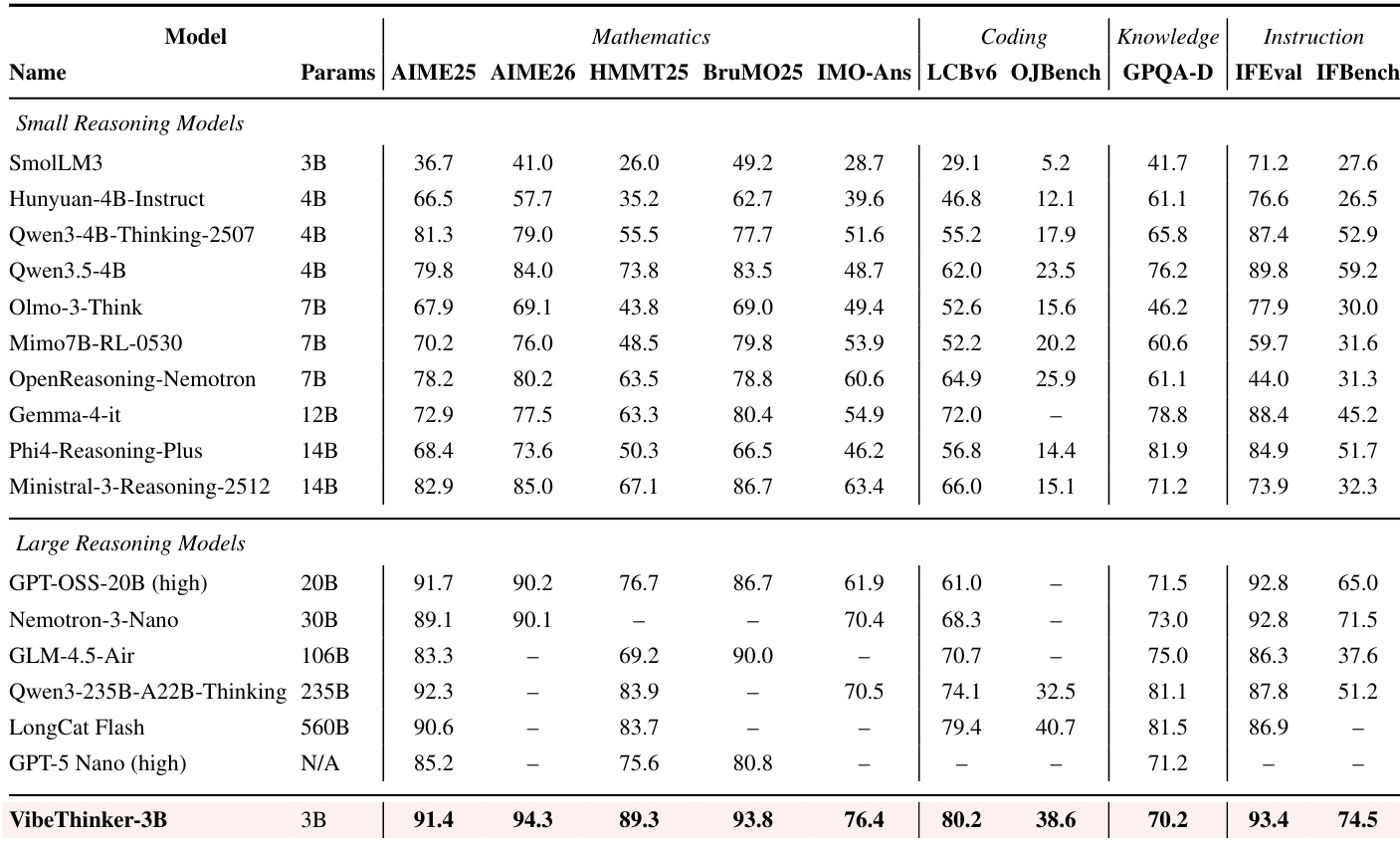
The authors evaluate VibeThinker-3B on recent LeetCode weekly and biweekly contests to assess its ability to solve unseen algorithmic problems. The model achieves a high aggregate success rate, demonstrating robust out-of-distribution generalization. Its performance is competitive with top-tier systems, outperforming several large models while closely matching the best-performing entries. VibeThinker-3B achieves a high aggregate success rate on recent LeetCode contests, outperforming models such as GPT-5.2 and Qwen3-Max. The model demonstrates robust generalization on fresh algorithmic problems, closely matching the performance of top-tier systems like Gemini 3 Flash. Evaluation on one-shot Python generation confirms the model's ability to handle complex, execution-verified coding tasks without specific fine-tuning on the test distribution.
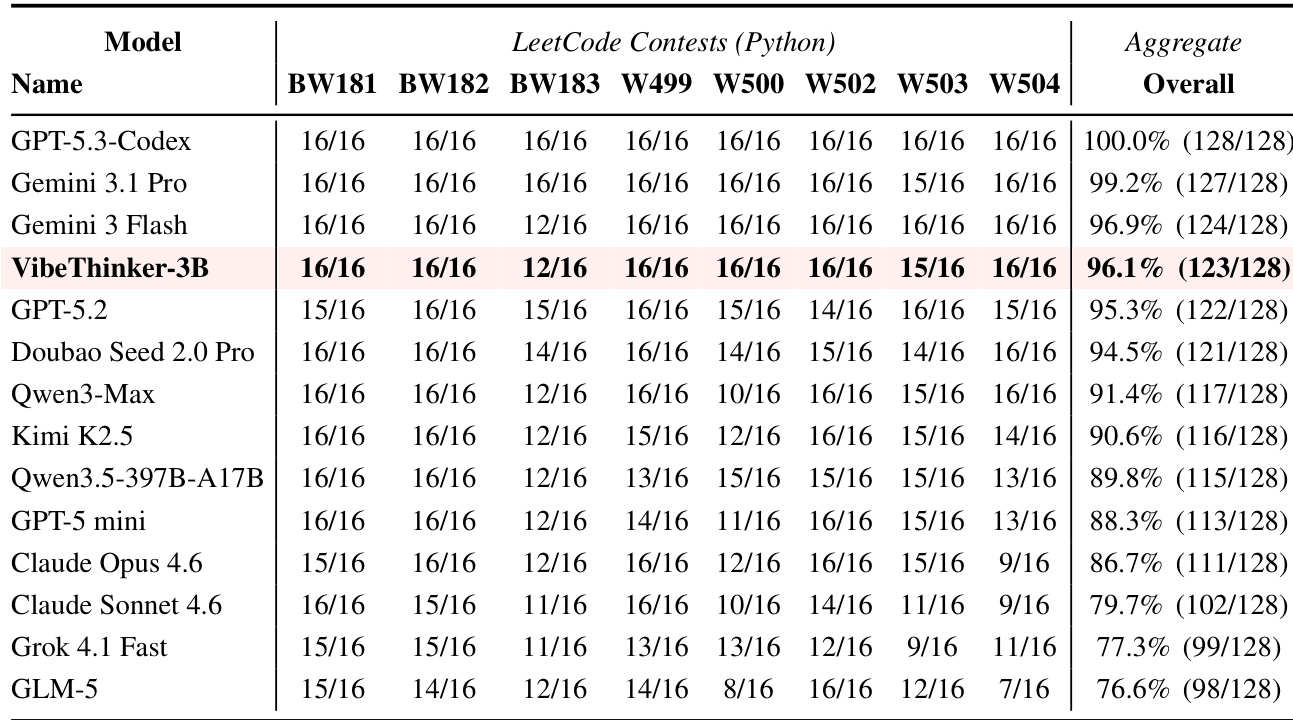
The experiments evaluate the compact VibeThinker-3B model against significantly larger open-source and proprietary systems across mathematical reasoning, coding, and instruction-following benchmarks to assess its parameter efficiency and reasoning capabilities. Base evaluations demonstrate that the model already matches or outperforms much larger competitors on structured tasks, while additional testing on fresh algorithmic problems confirms its strong out-of-distribution generalization. Incorporating a test-time scaling strategy further elevates performance to frontier levels, effectively closing the gap with top-tier flagship models. These findings collectively indicate that compact architectures can achieve high-tier reasoning performance on verifiable tasks without relying on massive parameter scales.