Command Palette
Search for a command to run...
DragMesh-2 : Interaction main-objet adroite physiquement plausible avec des objets articulés
DragMesh-2 : Interaction main-objet adroite physiquement plausible avec des objets articulés
Tianshan Zhang Yijia Duan Yanjun Li Zeyu Zhang Hao Tang
Résumé
L'interaction habile avec des objets articulés est importante pour la manipulation domestique, assistive et humanoïde, où les mains polydoigts peuvent fournir des schémas de contact conformes dépassant la préhension à mâchoires parallèles. Toutefois, la manipulation d'objets articulés diffère de celle d'objets statiques : la pièce cible ne peut être actionnée directement, et son mouvement doit émerger par un contact physique soutenu entre la main et la poignée. Cette transition, de la génération articulée centrée sur l'objet vers une interaction habile main-objet pilotée par la main, s'avère non triviale, car le rejeu de trajectoires géométriques ou l'exécution en boucle ouverte ne modélisent pas la dynamique de contact nécessaire au déplacement de la pièce articulée. Par ailleurs, les politiques entraînées exclusivement pour l'accomplissement de tâches dans des dynamiques fixes peuvent surajuster les charges de contact nominales, particulièrement en l'absence de retour tactile ou de force, et voir leurs performances se dégrader lorsque la charge de contact varie. Pour répondre à ces défis, nous présentons DragMesh-2, un cadre piloté par le contact pour l'interaction habile avec des objets articulés, qui étend l'interaction articulée de la génération centrée sur l'objet à une interaction habile main-objet pilotée par la main, où le mouvement articulé doit résulter d'un contact physique. Nous proposons par ailleurs PICA, un mécanisme d'entraînement conscient du contact et fondé sur des principes physiques, qui injecte des signaux physiques dans l'apprentissage des politiques sans recourir à un retour tactile ou de force, améliorant ainsi la robustesse et le succès des tâches face à des charges de contact variables. Enfin, nous réalisons une évaluation systématique sur plusieurs conditions d'amortissement et différentes catégories d'objets articulés afin d'étudier la robustesse face aux variations de charge de contact, et nous fournissons une ressource d'interaction habile purement géométrique pour soutenir les recherches futures en loco-manipulation et en interaction main-objet humanoïde. Sur sept objets GAPartNet, DragMesh-2 démontre une robustesse supérieure face aux variations de charge de contact par rapport aux méthodes comparées, tout en maintenant un taux de réussite élevé des tâches quelle que soit la condition d'amortissement.
One-sentence Summary
DragMesh-2 presents a contact-driven framework for dexterous hand-object interaction with articulated objects that replaces open-loop trajectory replay with sustained physical contact, utilizes the PICA training mechanism to inject physical signals without tactile or force feedback, and demonstrates robust manipulation across seven GAPartNet objects under varying damping conditions.
Key Contributions
- DragMesh-2 is a contact-driven framework that transitions articulated object manipulation from object-centric trajectory generation to hand-driven dexterous interaction where motion emerges through sustained physical contact. This approach explicitly models the contact dynamics required to actuate articulated parts without relying on geometric replay or open-loop execution.
- PICA is a physically informed training mechanism that leverages short-horizon interaction history to inject physical signals into policy learning without tactile or force feedback. By integrating task rewards with separate action-bound and contact-preserving regularization terms, the method stabilizes multi-finger coordination under fluctuating contact loads.
- Systematic evaluations across seven GAPartNet objects and multiple damping conditions demonstrate that the framework achieves stronger robustness to contact-load variation than competing methods while maintaining high task success. The release of a pure-geometry dexterous interaction dataset further supports future loco-manipulation and humanoid hand-object interaction research.
Introduction
Dexterous manipulation of articulated objects is essential for advanced robotics applications like household assistants and humanoid systems, as multi-finger hands enable compliant contact patterns that traditional grippers cannot achieve. However, prior approaches struggle because articulated parts cannot be directly controlled and must move through sustained physical interaction. Existing methods typically rely on open-loop trajectory replay or reinforcement learning trained under fixed dynamics, which causes policies to overfit nominal contact loads and fail when interaction conditions change. To address these limitations, the authors introduce DragMesh-2, a contact-driven framework that generates articulated motion exclusively through real-time hand-handle interaction. They further propose PICA, a physically informed training mechanism that injects contact-aware signals and dynamics randomization into policy learning, enabling robust manipulation under varying loads without requiring tactile or force sensors.
Dataset
-
Dataset Composition and Sources: The authors generate a reference contact trajectory dataset directly from the GAPartNet geometry library using a purely heuristic approach. The collection comprises 277 trajectories distributed across seven GAPartNet categories, preserving the original category proportions and heavily featuring StorageFurniture objects.
-
Subset Details and Structure: Each trajectory follows a four-phase interaction sequence: approach, grasp, drag, and release. The generation process filters for objects with valid part, handle, and joint-mobility annotations, then combines these geometric cues with a SMPL-X hand model to ensure all wrist and finger motions align with the target joint constraints.
-
Data Processing and Storage: A geometry-guided synthesis procedure creates the dataset, with all outputs saved as JSON files containing per-frame wrist poses and finger configurations. This storage format decouples the data from any specific policy or physics backend, making the trajectories fully regenerable for any compatible GAPartNet model.
-
Usage in the Model: The authors utilize this unified dataset in three capacities within their DragMesh-2 framework. It initializes the expert grasp states and sets the target motion scales for the contact-driven reinforcement learning task, serves as a fixed non-learned baseline for trajectory tracking evaluation, and is publicly released as a geometry-only interaction resource for future loco-manipulation studies.
Experiment
The evaluation benchmarks learned contact-driven policies against trajectory replay and geometric primitives across multiple articulated objects under nominal, mild, and strong out-of-distribution damping conditions. Ablation and diagnostic studies validate that robust manipulation requires the synergistic combination of explicit physical regularization and temporal contact-response modeling, as nominal success metrics frequently mask underlying action saturation and stability collapse. Furthermore, experiments demonstrate that extended training or broader damping distributions alone cannot overcome strong-load failures, establishing that reliable checkpoint selection must prioritize out-of-distribution robustness and that sustained progress will depend on enriching the contact interface with direct force feedback.
The training-length study reveals that extending base policy optimization improves nominal performance but severely compromises robustness under strong damping conditions. As training epochs increase, the policy drives toward action saturation, causing a sharp decline in task success and progress when facing high contact loads. Applying physical-structure fine-tuning modules effectively mitigates this collapse, preserving high success rates and stable action distributions across both execution modes. Prolonged base training leads to severe performance collapse under strong damping as action saturation metrics approach their upper bounds. Combining physical fine-tuning modules maintains high success rates and prevents the action saturation that plagues longer-trained base policies. Both deterministic and stochastic evaluations show that fine-tuned variants outperform extended base policies in robustness and progress metrics.
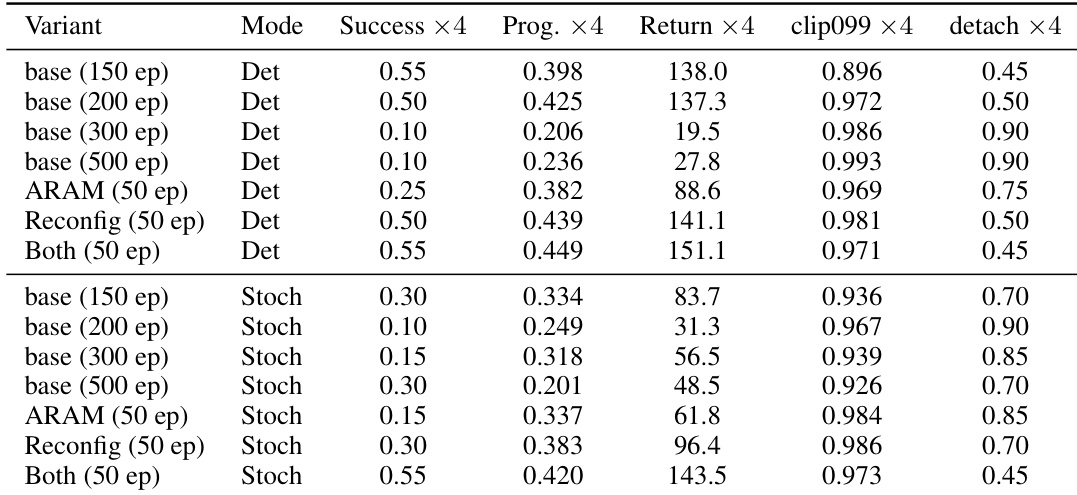
The authors examine how training duration influences policy robustness under different contact load conditions. They find that while longer training improves success rates under nominal damping, it causes a sharp decline in performance when damping is increased. This performance drop correlates with rising action saturation, suggesting that extended training pushes the policy into a saturated state that lacks robustness. Extended training improves nominal performance but reduces robustness under strong damping. Action saturation increases consistently as training continues. Nominal success metrics can be misleading regarding a policy's ability to handle high contact loads.
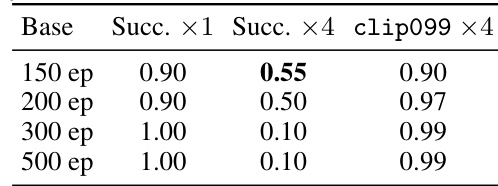
The authors investigate the effects of extending fine-tuning duration on policy robustness under varying damping conditions. Results show that while nominal success rates remain high and training rewards increase, performance under higher damping levels degrades significantly. This indicates that prolonged training drives the policy into a saturated regime that compromises out-of-distribution stability. Extending fine-tuning leads to a collapse in robustness under higher damping conditions, despite maintaining high nominal success rates. Action saturation metrics increase steadily with training epochs, indicating a drift toward a saturated, low-robustness policy. Selecting checkpoints based solely on training reward is insufficient for out-of-distribution robustness, as the reward-best checkpoint exhibits degraded performance.

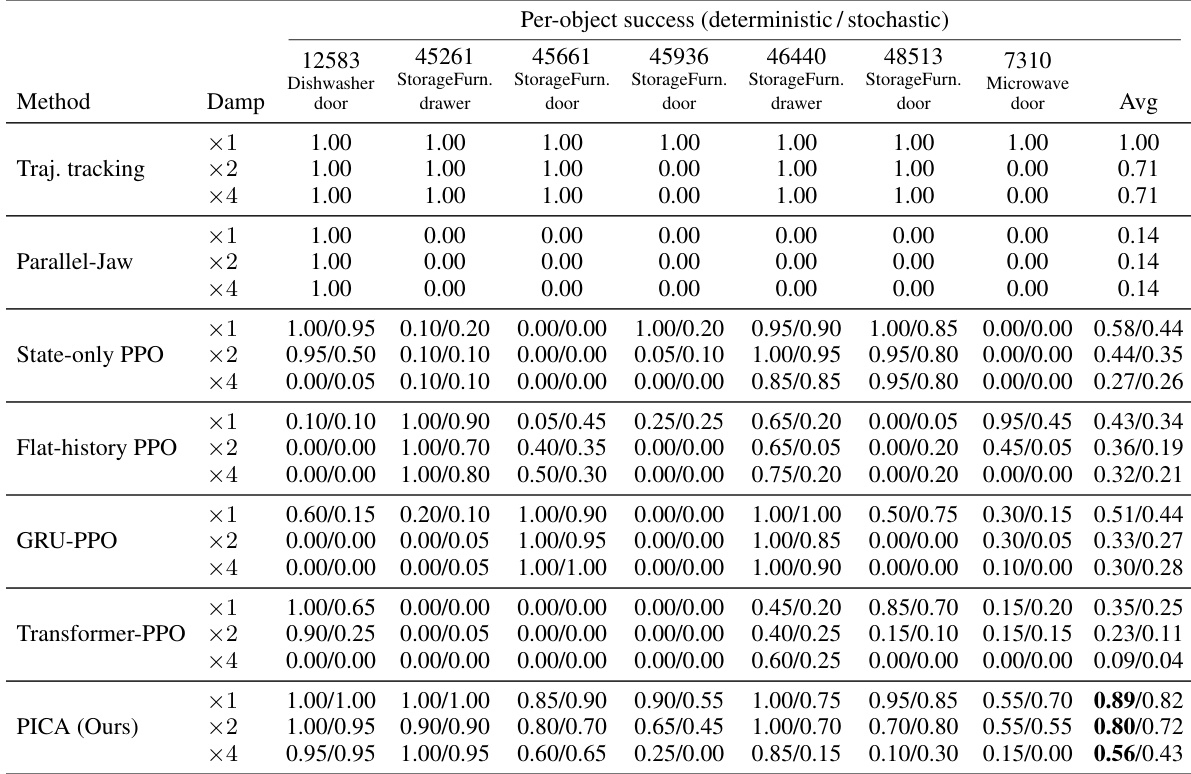
The authors evaluate contact-driven articulated object manipulation across varying damping levels and find that their proposed method consistently achieves the highest success rates compared to trajectory replay, geometric primitives, and standard learned baselines. Results demonstrate that combining physical structure signals with temporal encoders yields superior robustness under strong contact loads, whereas relying on nominal performance or extended training alone often leads to action saturation and performance collapse. The proposed method maintains the highest mean success across all damping multipliers and execution modes, outperforming open-loop and learned baselines. Temporal encoders alone are insufficient for robust contact control, as physical signals and temporal modeling must be combined to prevent saturation under strong damping. Nominal success metrics can be misleading, as extended training and broader damping ranges often degrade out-of-distribution robustness without explicit contact-aware regularization.
The authors evaluate whether expanding the training damping distribution enhances out-of-distribution robustness during fine-tuning. The results indicate that broadening the damping range fails to produce stable gains under strong damping conditions. Instead, this adjustment leads to noticeable performance degradation across nominal and mild damping settings. Expanding the training damping range fails to produce stable gains under strong damping conditions. The modified training distribution causes noticeable performance degradation across nominal and mild damping settings. Adjusting the training damping interval alone provides limited benefit within the current control framework.

The experiments evaluate the impact of extended training duration, prolonged fine-tuning, and expanded damping distributions on policy stability, revealing that longer optimization consistently degrades out-of-distribution robustness despite improving nominal success rates. This performance collapse is driven by action saturation, which renders reward-based checkpoint selection and broader training ranges ineffective for handling high contact loads. In contrast, integrating physical structure signals with temporal encoders successfully prevents saturation and maintains high success rates across all execution modes. Ultimately, the study demonstrates that explicit contact-aware regularization is essential for robust manipulation, as relying on extended training or nominal metrics alone compromises stability under strong damping.