Command Palette
Search for a command to run...
EfficientRollout : Décodage auto-spéculatif conscient du système pour les rollouts RL
EfficientRollout : Décodage auto-spéculatif conscient du système pour les rollouts RL
Minseo Kim Minjae Lee Seunghyuk Oh Kevin Galim Donghoon Kim Coleman Hooper Harman Singh Amir Gholami Hyung Il Koo Wonjun Kang
Résumé
L'apprentissage par renforcement (RL) est devenu un paradigme post-entraînement représentatif pour les LLM, permettant des capacités de raisonnement et agentic solides. Cependant, la génération de rollout demeure un goulot d'étranglement dominant en termes de latence, car l'échantillonnage autoregressif décode les réponses de manière séquentielle et un petit nombre de générations à queue longue détermine souvent le temps de complétion. Le décodage spéculatif (SD) offre une voie naturelle pour résoudre ce goulot d'étranglement, car il s'agit d'une technique bien établie pour le déploiement de LLM fixes qui réduit la latence en rédigeant rapidement des tokens et en les acceptant par vérification parallèle, tout en préservant la distribution du modèle cible. Cependant, ses accélérations pratiques ne se transposent pas directement aux rollouts RL : (i) la politique cible évolutive rend tout drafteur fixe de plus en plus désynchronisé par rapport à la distribution de sortie de la politique ; et (ii) les tailles de lot actives diminuent tout au long du décodage de rollout, déplaçant le décodage de régimes limités par le calcul vers des régimes limités par la mémoire, où la vérification parallèle peut exploiter une puissance de calcul sous-utilisée. Par conséquent, l'accélération des rollouts RL nécessite à la fois un drafteur qui reste efficace lors de générations longues et à haute température provenant d'une politique évolutive, ainsi qu'une utilisation du SD consciente du système qui évite les régimes limités par le calcul. Nous présentons EfficientRollout, un cadre auto-SD conscient du système conçu pour combler cette lacune pour les rollouts RL. EfficientRollout induit un drafteur quantifié à partir du modèle cible (c'est-à-dire un décodage spéculatif auto), le maintenant couplé à la politique évolutive sans pré-entraînement séparé du drafteur ni adaptation en ligne. Il coordonne en outre une politique de basculement SD consciente du système avec une adaptation de la longueur de draft sensible à l'acceptation, permettant la spéculation uniquement dans les régimes bénéfiques tout en alignant le budget de rédaction sur la qualité évolutive du drafteur. EfficientRollout réduit la latence de rollout et la latence de bout en bout jusqu'à 19,6% et 12,7%, respectivement, par rapport à une ligne de base de rollout AR accélérée, tout en préservant la qualité finale du modèle.
One-sentence Summary
EfficientRollout is a system-aware self-speculative decoding framework that accelerates large language model reinforcement learning rollouts by dynamically adapting drafters to evolving policies and optimizing verification for memory-bound execution, thereby overcoming the latency bottlenecks of autoregressive sampling and fixed-drafter speculative decoding.
Key Contributions
- This work introduces EfficientRollout, a system-aware self-speculative decoding framework that induces a weight-quantized drafter directly from the evolving target policy at every training step to maintain high block efficiency.
- The framework incorporates a system-aware speculative decoding toggle that restricts execution to favorable memory-bound regimes and an adaptive draft-length policy that dynamically scales the drafting budget to match real-time token acceptance rates.
- Empirical evaluations demonstrate that the framework reduces rollout latency by up to 19.6% and end-to-end training latency by up to 12.7% compared to standard reinforcement learning stacks.
Introduction
Reinforcement learning post-training is essential for enhancing large language model reasoning and agentic capabilities, yet rollout generation remains a dominant latency bottleneck because sequential autoregressive decoding struggles to keep pace with the long responses these models produce. While speculative decoding can reduce inference latency, it faces significant hurdles in RL rollouts where the continuously evolving target policy causes fixed drafters to mismatch and shrinking batch sizes shift computation from compute-bound to memory-bound regimes where parallel verification yields diminishing returns. Prior solutions either employ history-based drafting with low block efficiency or rely on auxiliary drafters that necessitate separate pretraining and online adaptation, adding substantial system complexity. The authors propose EfficientRollout, a system-aware self-speculative decoding framework that induces a quantized drafter directly from the evolving target model to maintain alignment without external training overhead. This approach combines a regime-aware toggle that activates speculation only in beneficial conditions with adaptive draft-length control to match the drafting budget to acceptance behavior, achieving up to 19.6% reduction in rollout latency while preserving model quality.
Method
The authors propose EfficientRollout, a system-aware self-speculative decoding (SD) framework designed to accelerate reinforcement learning rollouts. This method addresses three specific challenges inherent to RL training: evolving target policies, shrinking active batch dynamics, and latency bottlenecks in the rollout tail. The framework integrates a target-induced quantized drafter, a dynamic SD toggle policy, and adaptive drafting budgets.
To handle the evolving policy, the method employs a self-SD drafter derived directly from the current target model. This ensures the drafter remains synchronized with the policy without requiring separate pretraining or online adaptation. Specifically, the authors apply lightweight Round-to-Nearest (RTN) quantization to the FFN and QKVO projection layers. This targets the dense projection time, which dominates the decoding latency in the rollout tail, thereby reducing the drafter-to-target latency ratio.
The framework also incorporates a regime-aware SD toggle policy to determine when speculative decoding is beneficial. In the early phases of rollout, the active batch size is large, often saturating compute resources and making SD slower than standard autoregressive decoding. The authors utilize a calibrated roofline model to predict speedup based on the current batch size and sequence length. SD is activated only when the predicted speedup exceeds a safety margin, typically occurring in the "rollout tail" where the batch size shrinks and the system becomes memory-bound.
Furthermore, the system features an adaptive draft-length policy. As RL training progresses, the target policy sharpens, increasing the agreement between the target and the quantized drafter. The method monitors the block efficiency and adjusts the draft length accordingly, increasing the length when acceptance is high and decreasing it when acceptance drops.
As shown in the figure below, the overall architecture integrates these components into a unified pipeline that manages rollout generation, reward calculation, and policy updates.
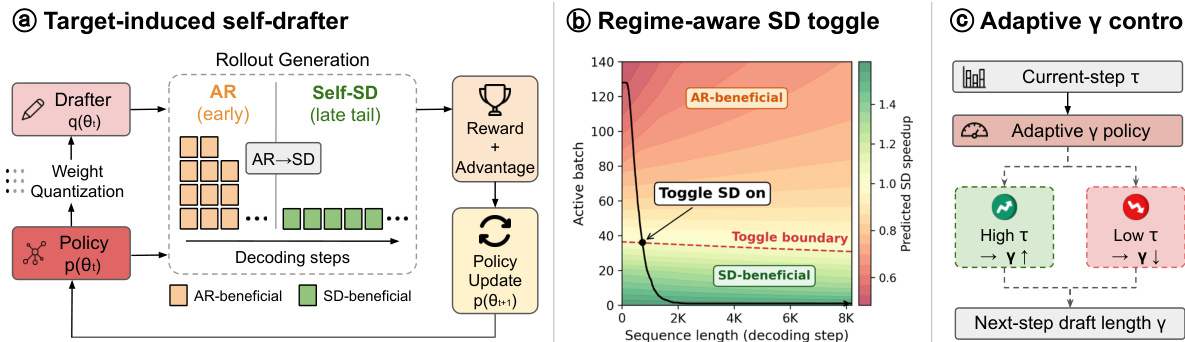
The detailed decoding process follows a draft-and-verify cycle. The process begins with the drafter generating a sequence of tokens. The target model then verifies these tokens in parallel.

If a token is rejected during verification, the system performs a KV cache rollback to the last accepted state. This ensures that the policy updates are based on valid trajectories while maintaining the efficiency gains from speculative decoding. The authors leverage this mechanism to reduce both rollout and end-to-end latency without altering the underlying RL distribution.
Experiment
3%) even with shorter γˉ, reflecting limited auxiliary-drafter effectiveness in long, high-temperature RL rollouts (Sec. 5.3).
Training dynamics and quality preservation. EfficientRollout accelerates training while preserving training dynamics. the figure shows that EfficientRollout closely tracks the veRL (AR) reward trajectory on Qwen2.5-7B. This aligns with the lossless nature of SD, which preserves the target distribution [6, 29] and is especially important in RL where rollout-distribution shifts can affect training stability [15, 63]. Full reward and validation-accuracy trajectories across all evaluated models are provided in Sec. F.2.
- 5.3 Further Analysis of Rollout Acceleration
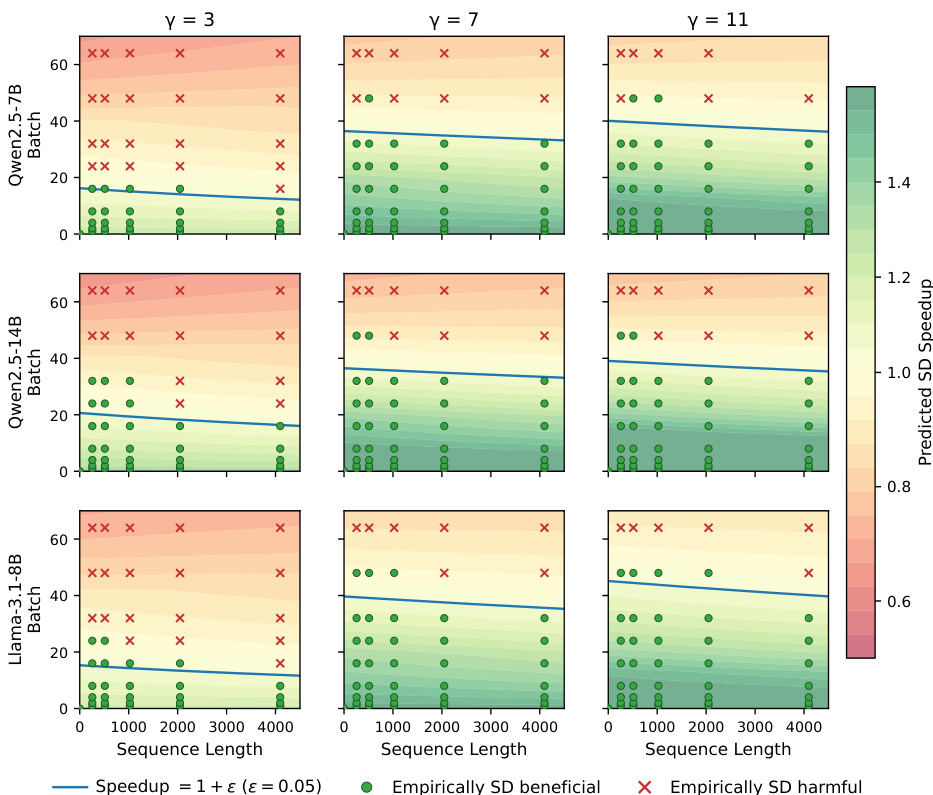
Regime-aware SD toggle policy. High τ alone is insufficient for realized speedup, and SD must be activated only in system-beneficial regimes via the toggle policy πSD. the figure validates the calibrated roofline boundary of πSD by showing that the predicted speedup correctly separates SD-beneficial and SD-harmful coordinates in the (B,S) plane. the figure isolates the effect of πSD by comparing rollout latency with the same quantized self-drafter when SD is always enabled versus enabled according to πSD. By disabling SD during only the early 6–11% of decoding steps, the πSD policy yields consistently larger rollout-generation latency reductions relative to AR than always-on SD, despite slightly lower τ. These gains therefore cannot be attributed to better draft quality; they come from avoiding verification in the initial large-batch regime,
the figure: Block efficiency across pretrained auxiliary drafters. On DAPO-Math-17K, the evaluated pretrained auxiliary drafters achieve lower block efficiency than quantized self-drafters.
where TV/Tp is high. Full validation results for πSD are provided in Sec. D.3.
Adaptive draft-length policy. The adaptive γ policy effectively tracks the latency-reducing γ as the evolving target policy shifts over training. the paper isolate this effect by replacing only the adaptive γ policy in EfficientRollout with fixed-γ variants throughout training. As shown in the figure, the adaptive γ policy achieves an overall 19.6% reduction in rollout-generation latency, compared with 13.5% and 11.8% for fixed γ=γlow=5 and γ=γhigh=11, respectively. This improvement comes from leveraging larger latency reductions at different stages of training, as smaller and larger γ values are
more effective early and later in training, respectively. Rather than selecting a single fixed γ through post-hoc sweeps, the adaptive γ policy moves within the pre-specified Γ using observed τ feedback
Learned auxiliary drafting in RL workloads. The lower τ and α of learned auxiliary drafting in the table reflect the practical difficulty of obtaining an auxiliary drafter aligned with long, high-temperature RL rollouts. Under the prior RL-SD setup of Iso et al. [24], the paper further evaluate auxiliary drafters on DAPO-Math-17K [63], the rollout workload used in that setup. As shown in the figure, the evaluated auxiliary drafters [41, 43] achieve only τ=1.2–2.4 over the first 30 steps, whereas the quantized self-drafter consistently reaches τ=3.6–3.9 under the same setting. These results suggest that directly reusing public checkpoints or drafters pretrained with fixed-target LLM-serving recipes [32, 71] is insufficient to reliably obtain high τ in RL rollouts. Realizing effective speedups with learned auxiliary drafting may require a more specialized auxiliary-drafter training pipeline [24, 74], such as collecting in-distribution rollouts, training drafters on target-generated synthetic data, and possibly using more aggressive online adaptation. Detailed evaluation settings and analyses with additional auxiliary-drafter checkpoints are presented in Sec. F.6.
The authors validate a roofline-based toggle policy by comparing predicted speedup regions against empirical measurements across different models and draft lengths. The results demonstrate that the predicted boundary effectively distinguishes between configurations where speculative decoding is beneficial and those where it is harmful. As the draft length increases, the operational regime where speculative decoding provides a speedup expands significantly, covering most tested batch sizes and sequence lengths. The predicted speedup boundary accurately separates empirically beneficial and harmful configurations across all evaluated models. Increasing the draft length significantly expands the region where speculative decoding yields speedups, reducing the number of harmful configurations. The toggle policy successfully identifies and avoids high-batch regimes where speculative decoding overhead outweighs computational gains.
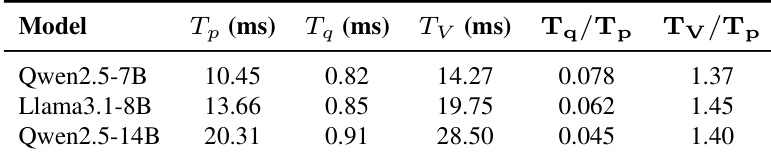
The authors analyze the latency breakdown of the EfficientRollout method across three open-source models of varying sizes. The results indicate that both prediction and verification times increase with model scale, while the quantization overhead remains stable. The verification time consistently exceeds prediction time by a similar margin across all configurations, and the relative cost of quantization overhead becomes smaller for larger models. Verification latency is consistently higher than prediction latency across all evaluated models. Quantization overhead remains low and independent of the target model's size. The relative impact of quantization overhead decreases as the target model size increases.
The authors evaluate the block efficiency of weight-quantized self-drafters across varying draft lengths. Results show that block efficiency increases as the draft length grows, with the 8-bit quantized drafter consistently achieving higher efficiency than the 4-bit version. Block efficiency improves as the draft length increases for both drafter variants. The 8-bit quantized drafter outperforms the 4-bit drafter in efficiency metrics. Both drafters maintain strong efficiency at the lowest tested draft length.

The the the table presents block efficiency metrics for auxiliary drafters across sequence length ranges. The data shows that for smaller models (Qwen2.5-7B and Llama3.1-8B), efficiency decreases as sequence length increases, indicating reduced effectiveness. In contrast, the larger model (Qwen2.5-14B) demonstrates increasing efficiency with longer sequences, although overall values remain lower than those of self-drafters. Smaller models exhibit declining block efficiency as sequence length grows. The larger model shows improved block efficiency with longer sequences. The metric values align with the described limited effectiveness of auxiliary drafters.

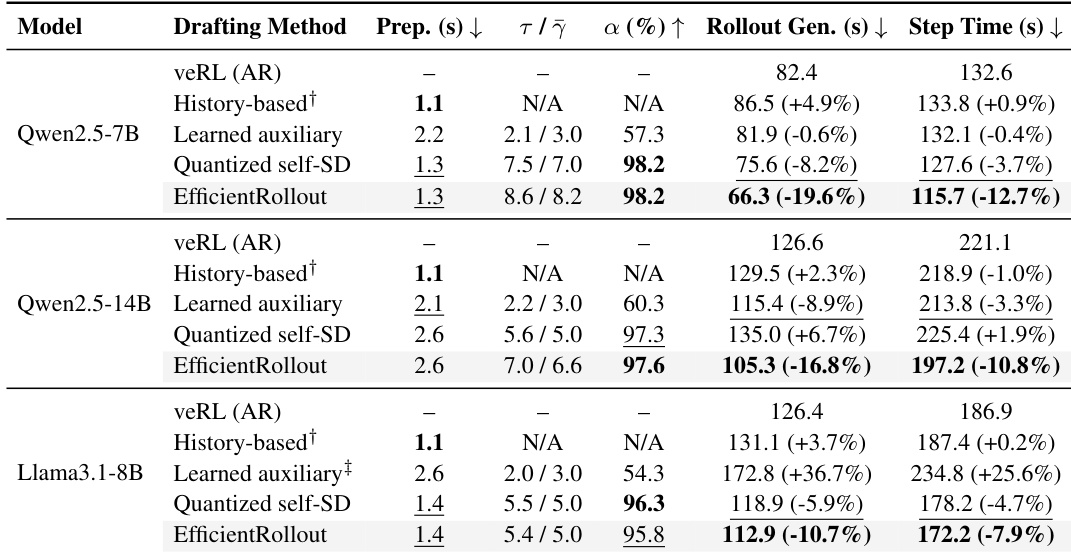
The experiment demonstrates that EfficientRollout provides the most significant end-to-end training acceleration across all evaluated models compared to standard autoregressive inference and various speculative decoding baselines. It achieves this by substantially reducing rollout generation latency while maintaining high token acceptance rates and preserving the target distribution. EfficientRollout consistently yields the lowest end-to-end step time across all model scales, outperforming history-based, learned auxiliary, and quantized self-drafting methods. The method sustains high acceptance rates and block efficiency, unlike learned auxiliary drafting which shows lower alignment and inconsistent performance. History-based drafting fails to reduce rollout generation latency despite low preparation overhead, indicating that simple prefix reuse is insufficient for speedup in this context.
The evaluation spans multiple model scales, draft lengths, and sequence ranges to validate the toggle policy, latency distribution, drafting efficiency, and end-to-end training acceleration. The roofline-based toggle policy accurately distinguishes beneficial from harmful speculative decoding configurations, with increased draft lengths expanding performance gains while circumventing high-batch overhead. Latency and efficiency breakdowns demonstrate that verification time consistently exceeds prediction time, quantization costs remain negligible regardless of model size, and self-drafters maintain superior efficiency over auxiliary methods across varying conditions. Collectively, these findings confirm that EfficientRollout achieves significant end-to-end training acceleration by reducing rollout latency and preserving target distribution alignment, consistently outperforming standard and speculative decoding baselines.