HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA
Combien les modèles de langage mémorisent-ils ?

L'Atlas de l'obscurcissement : Cartographier là où l'honnêteté émerge dans le RLVR à l'aide de sondes de tromperie

























Combien les modèles de langage mémorisent-ils ?
L'Atlas de l'obscurcissement : Cartographier là où l'honnêteté émerge dans le RLVR à l'aide de sondes de tromperie
Position : La communauté de l’alignement construit involontairement une boîte à outils pour censeurs
Échantillonnage de haute précision pour les modèles de diffusion et les distributions log-concaves
AgenticDataBench : un banc d'essai complet pour les agents de données
FLUX DE CORRESPONDANCE MULTIRÉSOLUTION : ACCÉLÉRATION DE DIFFUSION SANS ENTRAÎNEMENT PAR ÉCHANTILLONNAGE ÉTAGÉ
Se transformer en modèles d'attention hybrides
EvoPolicyGym : Évaluation de l'évolution autonome des politiques dans des environnements interactifs
AgenticSTS : un banc d’essai à mémoire bornée pour agents LLM à long horizon
Program-as-Weights : un paradigme de programmation pour les fonctions floues
MatAnyone 2 : Passage à l'échelle du matage vidéo via un évaluateur de qualité appris
EdgeTAM : un modèle « Segment Anything » sur appareil
PixelRefer : Un cadre unifié pour la référence spatio-temporelle d'objets à granularité arbitraire
EdgeBench : Dévoiler les lois d'échelle de l'apprentissage à partir d'environnements réels
ASPIRE : Découverte agentique de compétences pour la robotique
AUTOMEM : Apprentissage automatisé de la mémoire en tant que compétence cognitive
La loi du travail de décodage : jointures spatiales exactes et prouvables, régies par la marge, sur géométrie compressée
Tarification neuronale de certificats pour les problèmes d'optimisation combinatoire
Utilisation optimale des ressources pour les orchestrateurs de laboratoires autonomes
TERA : Un cadre unifié d'analyse d'atteignabilité fondé sur les modèles de Taylor
Perceive-to-Reason : Découpler la perception et le raisonnement pour le raisonnement visuel fin
Plans d'expériences basés sur des tries pour une évaluation efficace des pipelines de recherche d'information
Sur la non-linéarité de la loi d'échelle du taux d'apprentissage pour l'entraînement des LLM
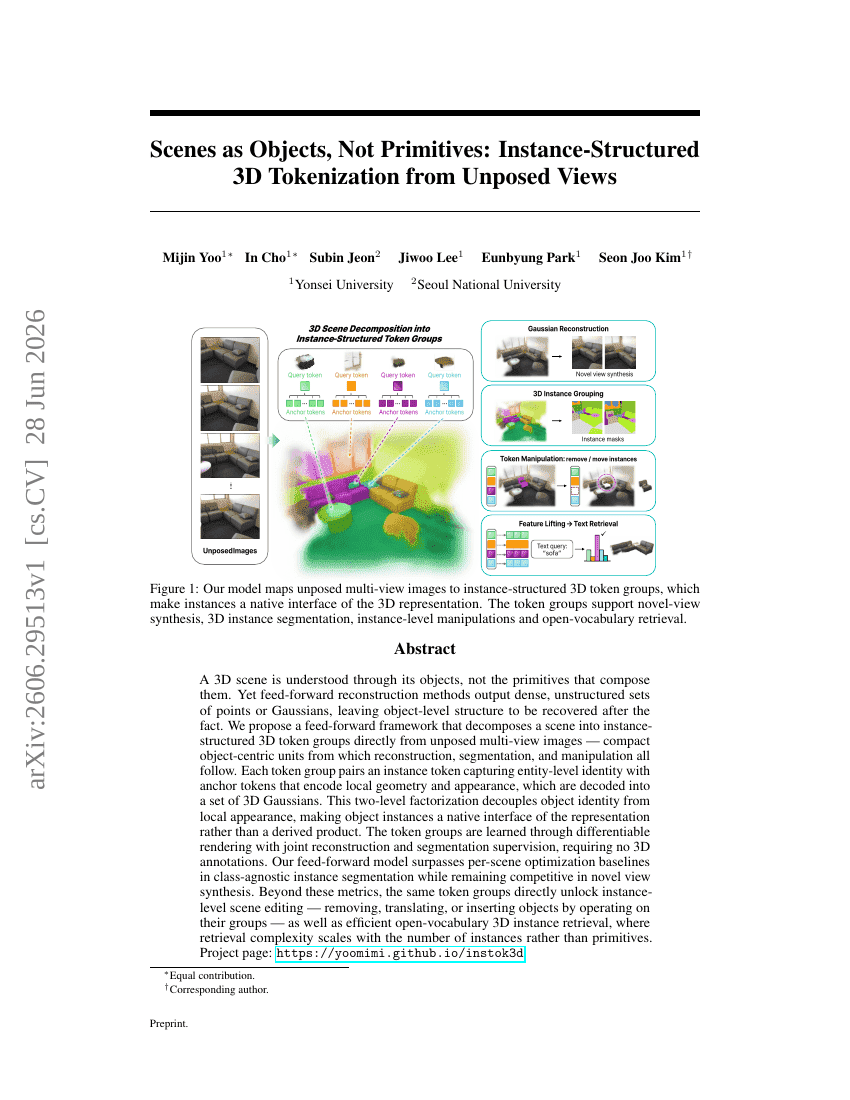
Les scènes comme objets, non comme primitives : tokenisation 3D structurée par instances à partir de vues non recalées
BlockPilot : apprentissage de politique adaptative par instance pour le décodage spéculatif basé sur la diffusion
DOPD : Distillation double en politique
Dockerless : Vérificateur de programmes sans environnement pour agents de codage
Orca : Le monde est dans votre esprit
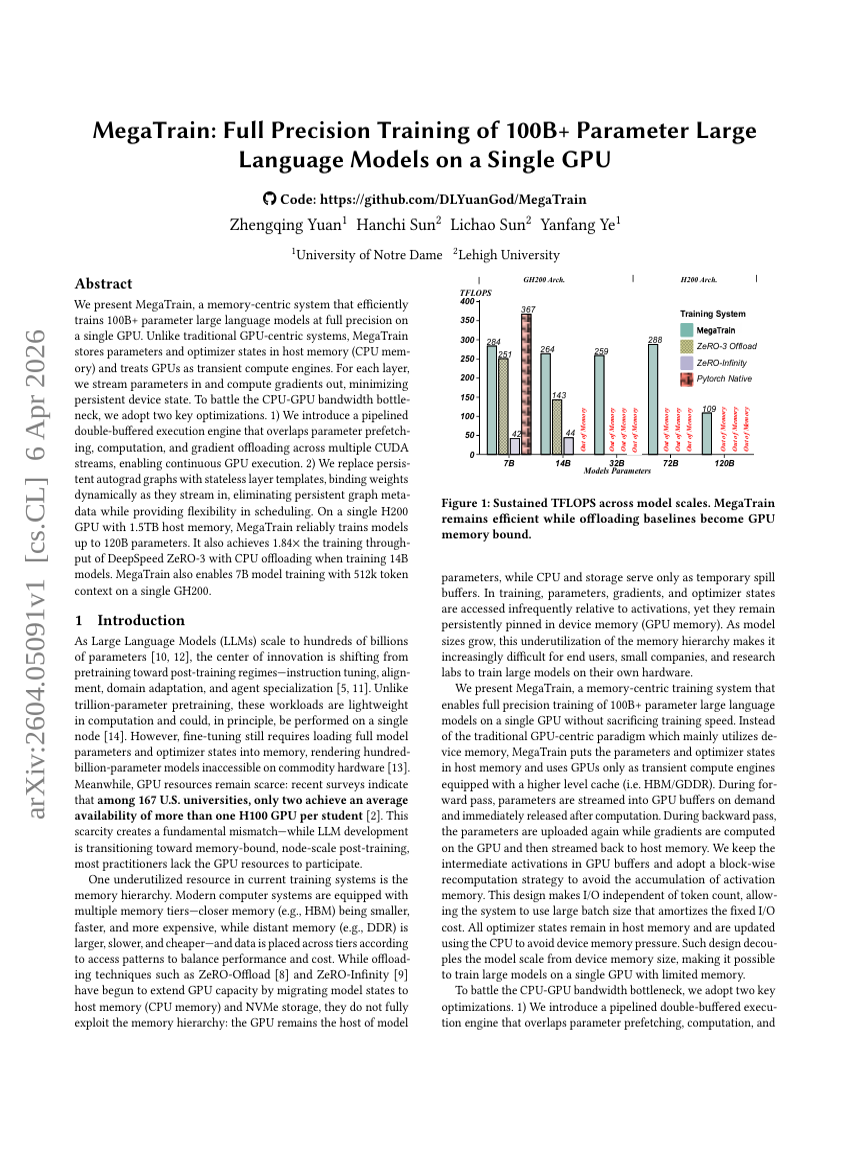
MegaTrain : Entraînement en pleine précision de grands modèles de langage de plus de 100 milliards de paramètres sur un seul GPU
Trouver le temps de réfléchir : apprentissage des budgets de planification en RL temps réel
À quoi ressemblent les courbes de taux d'apprentissage quasi optimales ?
Au-delà de l'IID : Dans quelle mesure les modèles tabulaires fondamentaux sont-ils vraiment généraux ?
Position : La communauté de l’alignement construit involontairement une boîte à outils pour censeurs
Échantillonnage de haute précision pour les modèles de diffusion et les distributions log-concaves
AgenticDataBench : un banc d'essai complet pour les agents de données
FLUX DE CORRESPONDANCE MULTIRÉSOLUTION : ACCÉLÉRATION DE DIFFUSION SANS ENTRAÎNEMENT PAR ÉCHANTILLONNAGE ÉTAGÉ
Se transformer en modèles d'attention hybrides
EvoPolicyGym : Évaluation de l'évolution autonome des politiques dans des environnements interactifs
AgenticSTS : un banc d’essai à mémoire bornée pour agents LLM à long horizon
Program-as-Weights : un paradigme de programmation pour les fonctions floues
MatAnyone 2 : Passage à l'échelle du matage vidéo via un évaluateur de qualité appris
EdgeTAM : un modèle « Segment Anything » sur appareil
PixelRefer : Un cadre unifié pour la référence spatio-temporelle d'objets à granularité arbitraire
EdgeBench : Dévoiler les lois d'échelle de l'apprentissage à partir d'environnements réels
ASPIRE : Découverte agentique de compétences pour la robotique
AUTOMEM : Apprentissage automatisé de la mémoire en tant que compétence cognitive
La loi du travail de décodage : jointures spatiales exactes et prouvables, régies par la marge, sur géométrie compressée
Tarification neuronale de certificats pour les problèmes d'optimisation combinatoire
Utilisation optimale des ressources pour les orchestrateurs de laboratoires autonomes
TERA : Un cadre unifié d'analyse d'atteignabilité fondé sur les modèles de Taylor
Perceive-to-Reason : Découpler la perception et le raisonnement pour le raisonnement visuel fin
Plans d'expériences basés sur des tries pour une évaluation efficace des pipelines de recherche d'information
Sur la non-linéarité de la loi d'échelle du taux d'apprentissage pour l'entraînement des LLM
Les scènes comme objets, non comme primitives : tokenisation 3D structurée par instances à partir de vues non recalées
BlockPilot : apprentissage de politique adaptative par instance pour le décodage spéculatif basé sur la diffusion
DOPD : Distillation double en politique
Dockerless : Vérificateur de programmes sans environnement pour agents de codage
Orca : Le monde est dans votre esprit
MegaTrain : Entraînement en pleine précision de grands modèles de langage de plus de 100 milliards de paramètres sur un seul GPU
Trouver le temps de réfléchir : apprentissage des budgets de planification en RL temps réel
À quoi ressemblent les courbes de taux d'apprentissage quasi optimales ?
Au-delà de l'IID : Dans quelle mesure les modèles tabulaires fondamentaux sont-ils vraiment généraux ?