HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Apprentissage profond en télédétection : une revue

Une approche par régression pour l'amélioration de la parole basée sur les réseaux de neurones profonds











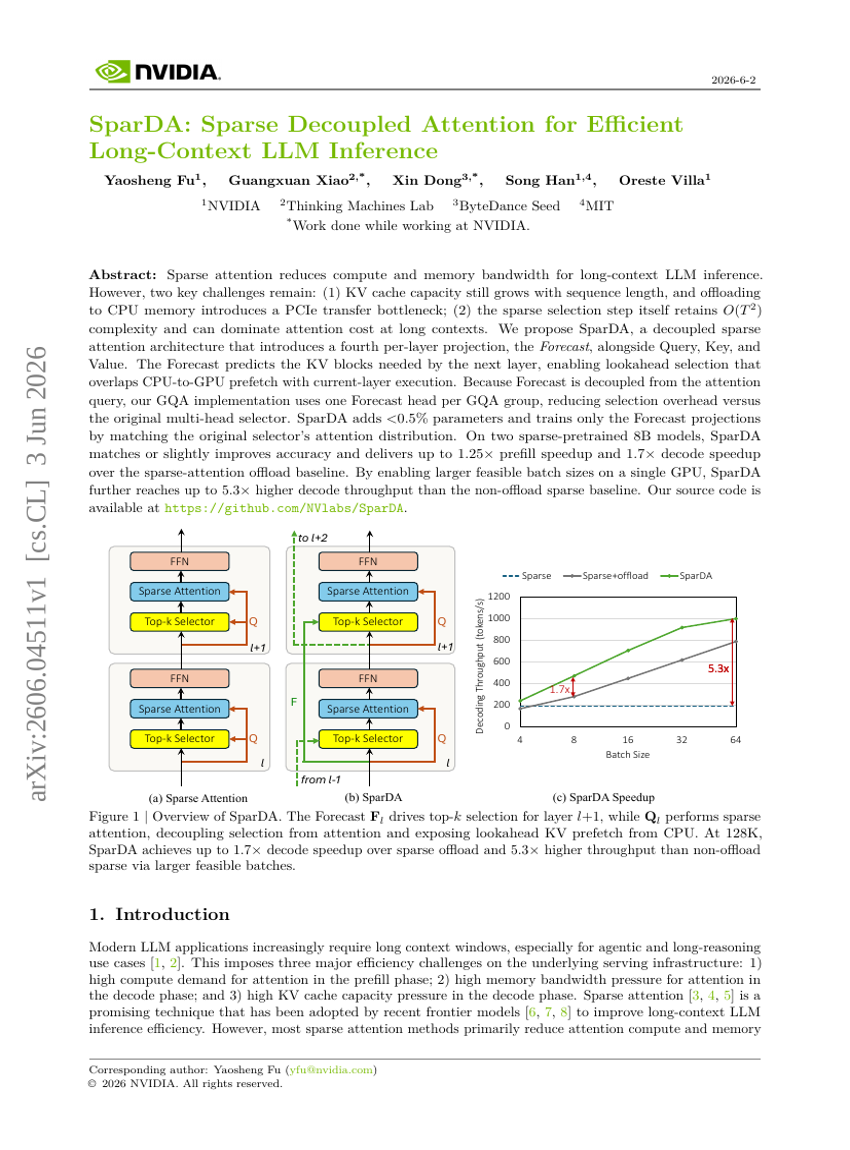














Apprentissage profond en télédétection : une revue
Une approche par régression pour l'amélioration de la parole basée sur les réseaux de neurones profonds
Réseaux de neurones profonds pour la modélisation acoustique en reconnaissance vocale
RoboTTT : Mise à l'échelle du contexte pour les politiques robotiques
SWE-agent : les interfaces agent-ordinateur permettent l’automatisation de l’ingénierie logicielle
Estimation efficace des représentations de mots dans l'espace vectoriel
Prédiction de carte de profondeur à partir d'une image unique à l'aide d'un réseau profond multi-échelle
TabNet : Apprentissage tabulaire interprétable par attention
AudioPaLM : un grand modèle de langage capable de parler et d’écouter
SQuAD : Plus de 100 000 questions pour la compréhension automatique de textes
DeepPose : Estimation de la pose humaine via des réseaux de neurones profonds
Auto-amélioration dans les systèmes agentiques modernes : une étude
Optimisation asynchrone à déploiement unique pour l’apprentissage par renforcement agentique
SparDA : attention découplée parcimonieuse pour une inférence efficace des LLM à long contexte
MetaView : Synthèse de nouvelles vues monoculaire avec des a priori géométriques implicites sensibles à l'échelle
PolicyShiftGuard : Évaluation et amélioration des garde-fous d’images adaptatifs aux politiques
KnowAct-GUIClaw : Connaître en profondeur, agir parfaitement, assistant personnel GUI avec mémoire et compétences auto-évolutives
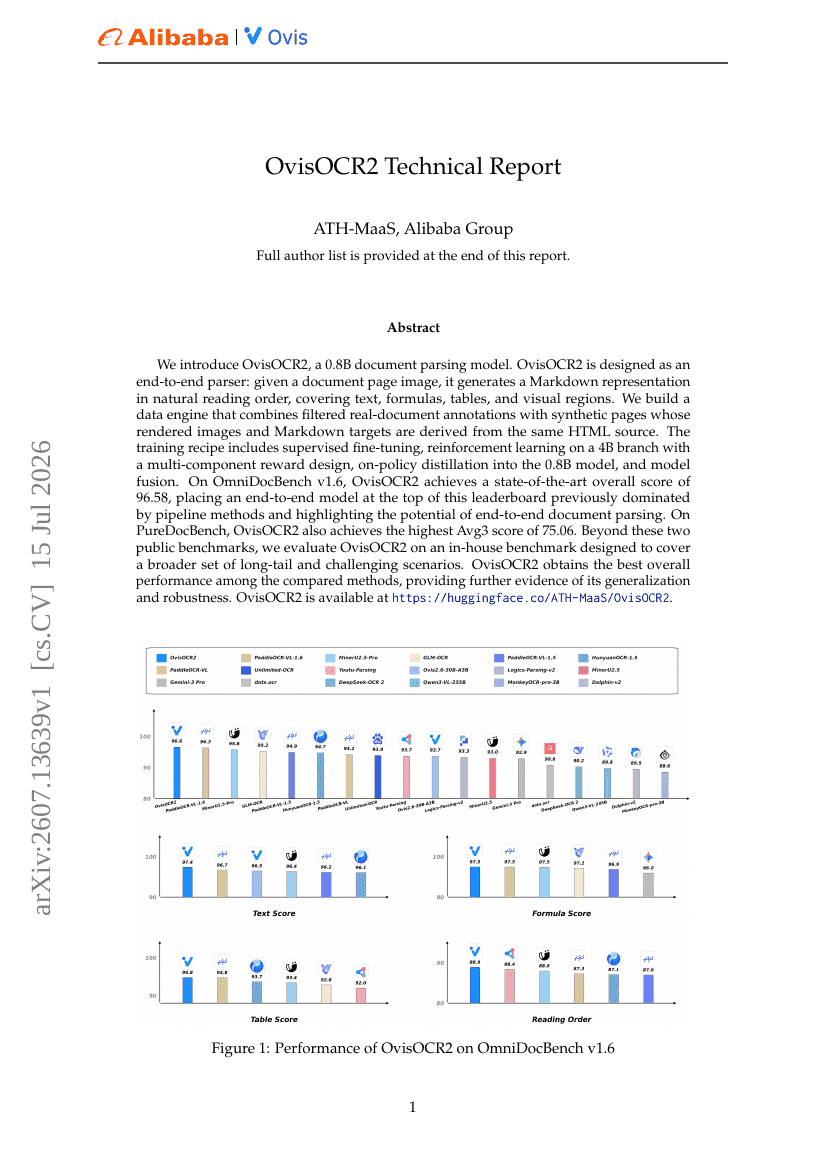
Rapport technique OvisOCR2
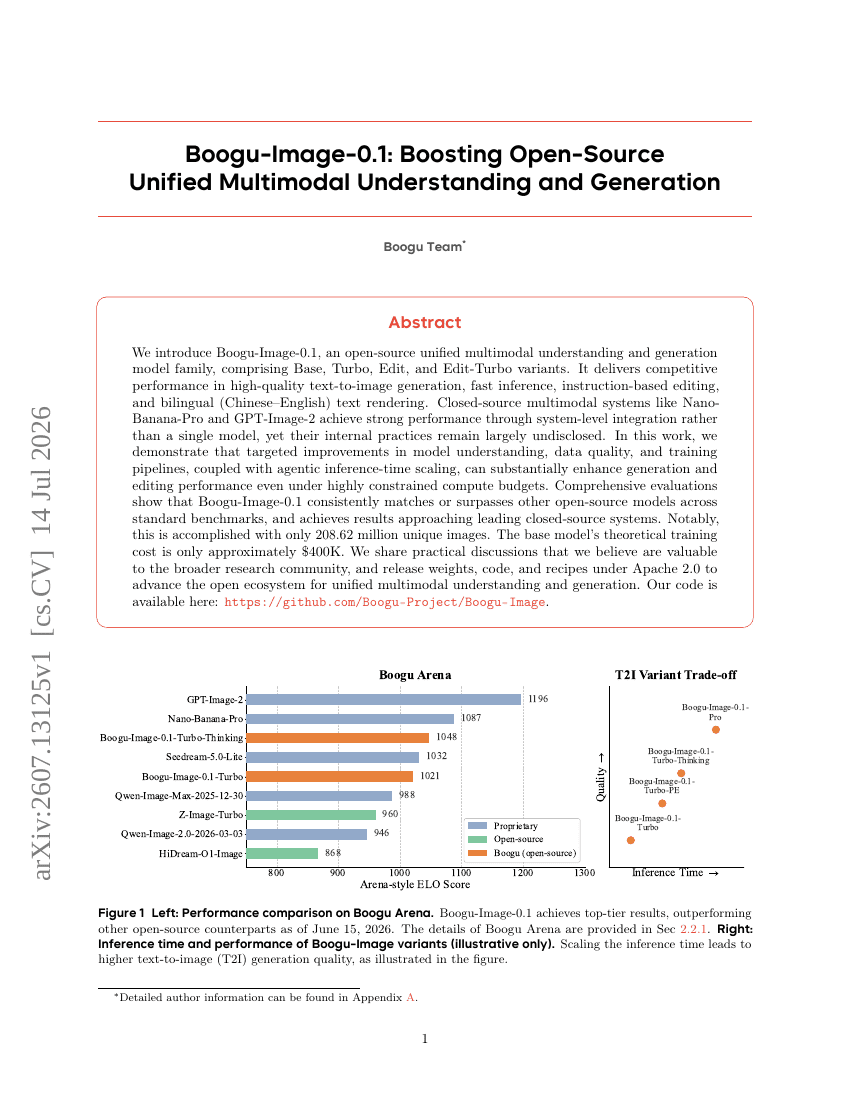
Boogu-Image-0.1 : Améliorer la compréhension et la génération multimodales unifiées en open source
Manuel du harnais : rendre les harnais d'agents évolutifs lisibles, navigables et modifiables
Rapport technique de Qwen-Music
Recâblage spectral pour l'exploration, la purification et la fusion de modèles
Repenser l'évaluation de l'évolution des harnais pour les agents
Ring-Zero : Mise à l'échelle du RL zéro à un billion de paramètres pour le raisonnement émergent
Combler le fossé entre le raisonnement latent et explicite avec les Transformers en boucle
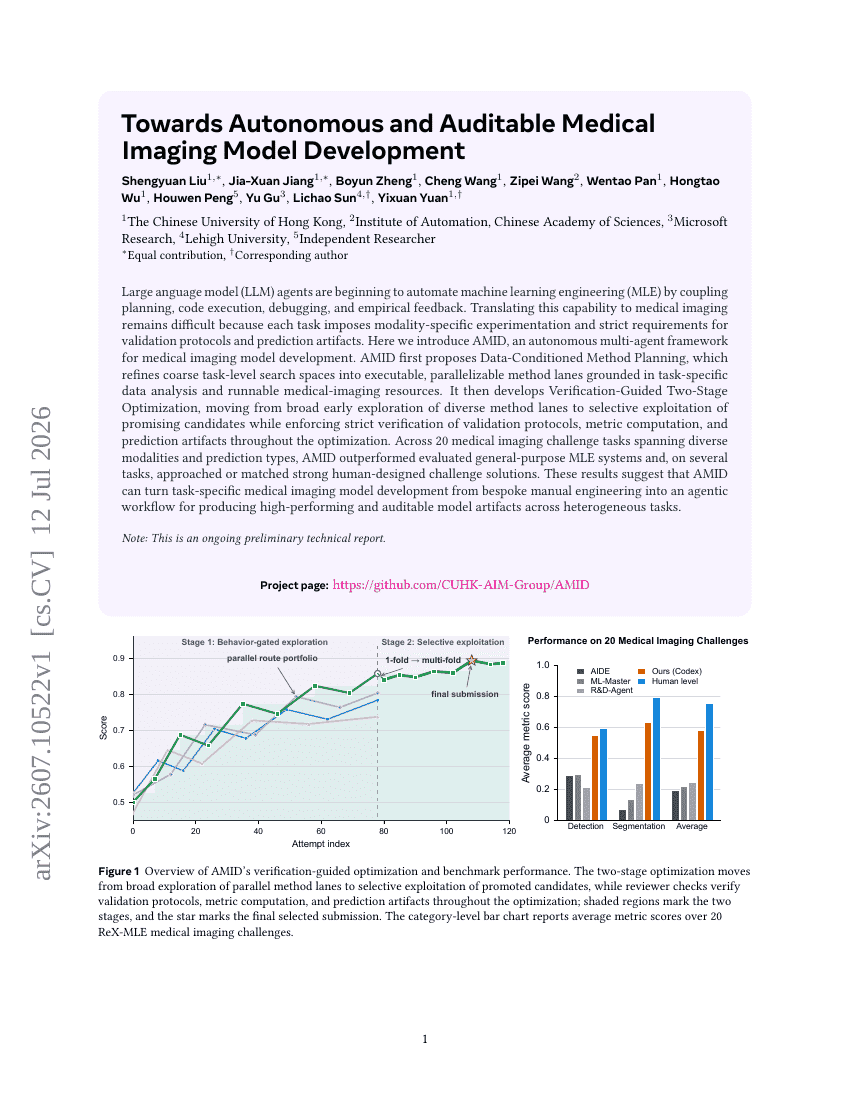
Vers un développement autonome et vérifiable de modèles d’imagerie médicale
MUSCRIPTOR : UN MODÈLE OUVERT POUR LA TRANSCRIPTION MUSICALE MULTI-INSTRUMENT
Analyse principielle des paradigmes d'évaluation et de conception en apprentissage par renforcement profond
Savoir avant de corriger : acquisition de connaissances sur le dépôt guidée par questions-réponses pour la résolution de tickets logiciels
Blind-Spots-Bench : Évaluation des angles morts dans les modèles multimodaux
Read It Back : Les MLLM préentraînés sont des modèles de récompense zero-shot pour la génération texte-image
Le rôle de la rigueur en intelligence artificielle
Réseaux de neurones profonds pour la modélisation acoustique en reconnaissance vocale
RoboTTT : Mise à l'échelle du contexte pour les politiques robotiques
SWE-agent : les interfaces agent-ordinateur permettent l’automatisation de l’ingénierie logicielle
Estimation efficace des représentations de mots dans l'espace vectoriel
Prédiction de carte de profondeur à partir d'une image unique à l'aide d'un réseau profond multi-échelle
TabNet : Apprentissage tabulaire interprétable par attention
AudioPaLM : un grand modèle de langage capable de parler et d’écouter
SQuAD : Plus de 100 000 questions pour la compréhension automatique de textes
DeepPose : Estimation de la pose humaine via des réseaux de neurones profonds
Auto-amélioration dans les systèmes agentiques modernes : une étude
Optimisation asynchrone à déploiement unique pour l’apprentissage par renforcement agentique
SparDA : attention découplée parcimonieuse pour une inférence efficace des LLM à long contexte
MetaView : Synthèse de nouvelles vues monoculaire avec des a priori géométriques implicites sensibles à l'échelle
PolicyShiftGuard : Évaluation et amélioration des garde-fous d’images adaptatifs aux politiques
KnowAct-GUIClaw : Connaître en profondeur, agir parfaitement, assistant personnel GUI avec mémoire et compétences auto-évolutives
Rapport technique OvisOCR2
Boogu-Image-0.1 : Améliorer la compréhension et la génération multimodales unifiées en open source
Manuel du harnais : rendre les harnais d'agents évolutifs lisibles, navigables et modifiables
Rapport technique de Qwen-Music
Recâblage spectral pour l'exploration, la purification et la fusion de modèles
Repenser l'évaluation de l'évolution des harnais pour les agents
Ring-Zero : Mise à l'échelle du RL zéro à un billion de paramètres pour le raisonnement émergent
Combler le fossé entre le raisonnement latent et explicite avec les Transformers en boucle
Vers un développement autonome et vérifiable de modèles d’imagerie médicale
MUSCRIPTOR : UN MODÈLE OUVERT POUR LA TRANSCRIPTION MUSICALE MULTI-INSTRUMENT
Analyse principielle des paradigmes d'évaluation et de conception en apprentissage par renforcement profond
Savoir avant de corriger : acquisition de connaissances sur le dépôt guidée par questions-réponses pour la résolution de tickets logiciels
Blind-Spots-Bench : Évaluation des angles morts dans les modèles multimodaux
Read It Back : Les MLLM préentraînés sont des modèles de récompense zero-shot pour la génération texte-image
Le rôle de la rigueur en intelligence artificielle