HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

TransitLM : un jeu de données et un benchmark à grande échelle pour la génération d'itinéraires de transport en commun sans carte

DelTA : Attribution discriminative de crédit de token pour l'apprentissage par renforcement à partir de récompenses vérifiables



























TransitLM : un jeu de données et un benchmark à grande échelle pour la génération d'itinéraires de transport en commun sans carte
DelTA : Attribution discriminative de crédit de token pour l'apprentissage par renforcement à partir de récompenses vérifiables
L'évaluation interactive nécessite une approche de science du design
ESI-BENCH : Vers une intelligence spatiale incarnée qui referme la boucle perception-action
Analyse comparative de la détection militaire à l'aide d'images de drones à travers plusieurs spectres visuels
Classification automatisée des diagnostics psychiatriques selon la CIM : des méthodes classiques de TALN aux grands modèles de langage
Gestion coordonnée et optimale de la qualité de l'alimentation dans les réseaux de distribution en utilisant la capacité résiduelle des IBR communautaires
EllipseLIO : Odométrie LiDAR inertielle adaptative avec une représentation ellipsoïdale
SMoA : Adaptateur de modulation de spectre pour le réglage fin efficace en paramètres
Détection des réseaux de neurones artificiels profonds piégés par analyse de régression spectrale
L'illusion de la pensée : comprendre les forces et les limites des modèles de raisonnement à travers le prisme de la complexité des problèmes
Raisonnement Récursif Génératif
Pré-entraînement de sécurité : vers une nouvelle génération d'IA sécurisée
RubricEM : Apprentissage par renforcement méta-avec décomposition de politique guidée par une grille d'évaluation, au-delà des récompenses vérifiables
Lorsque la vision parle pour le son
AutoResearchClaw : Recherche autonome auto-renforçante avec collaboration humain-IA
Récompenses de processus avec fiabilité apprise
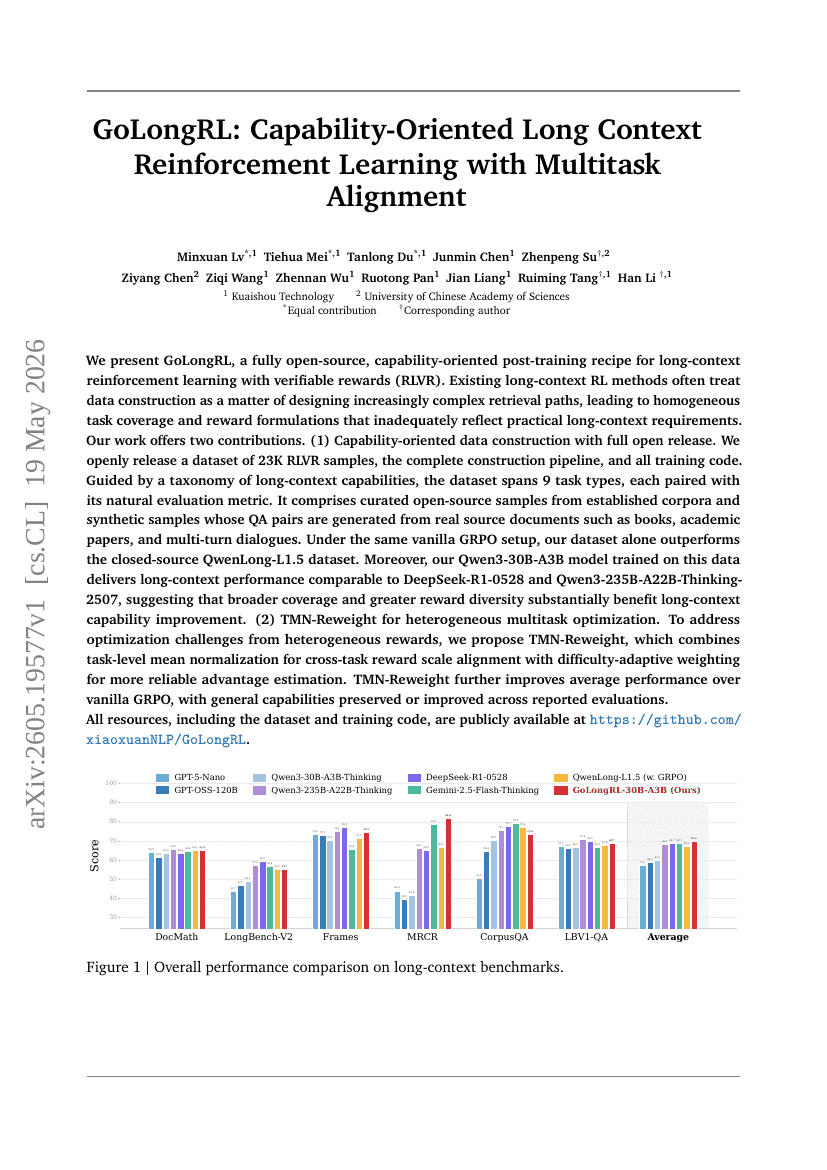
GoLongRL : Apprentissage par renforcement de contexte long orienté vers les capacités avec alignement multitâche
OpenComputer : des mondes logiciels vérifiables pour les agents d'utilisation d'ordinateur
Anti-Auto-Distillation pour le Renforcement par Apprentissage par Renforcement via l'Information Mutuelle Ponctuelle
Modulation ciblée des neurones par recherche de paires contrastives
Continuous Diffusion Scales Compétitivement avec Discrete Diffusion pour Langage
KVPO : GRPO natif pour les EDO pour l'alignement vidéo autoregressif via l'exploration sémantique KV
Code-as-Room : Génération de salles 3D à partir d'images de vue de dessus via la synthèse de code agentic
IA pour l'auto-recherche : feuille de route et guide utilisateur
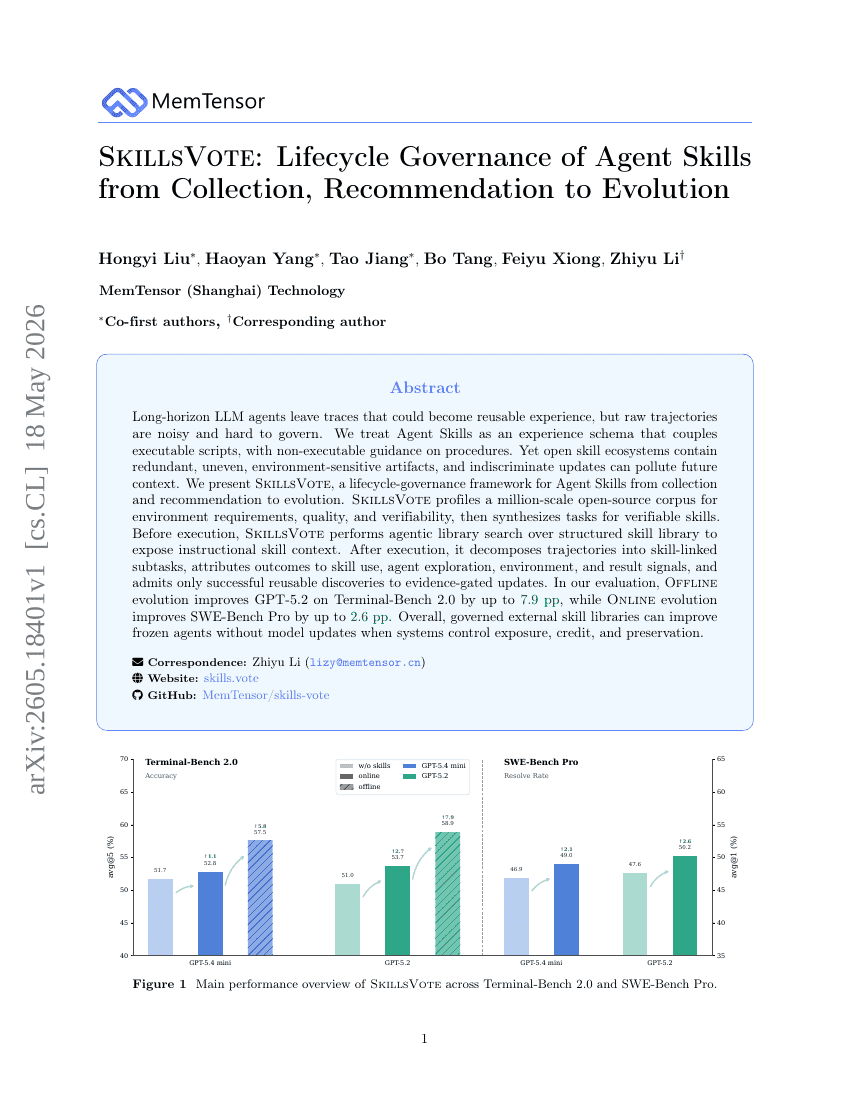
SkillsVote : Gouvernance du cycle de vie des compétences des agents, de la collecte et de la recommandation à l'évolution
Lance : Modélisation multimodale unifiée par synergie multi-tâches
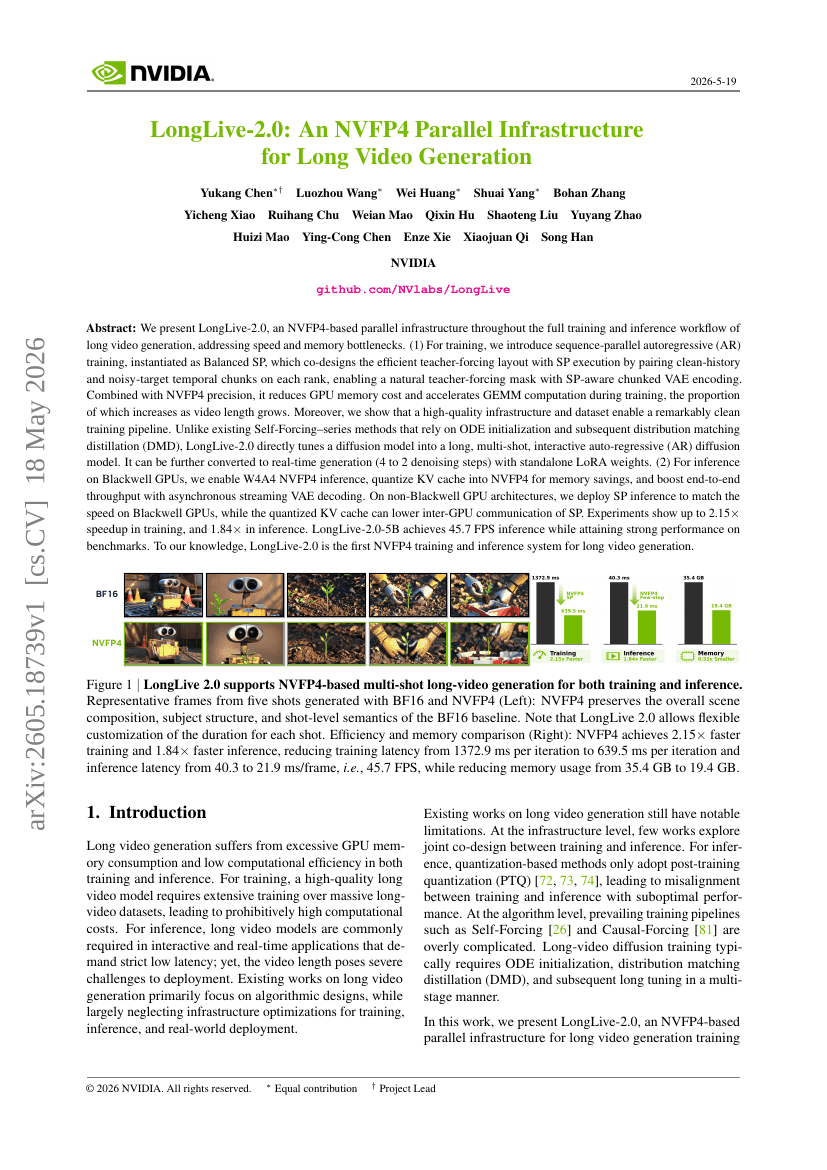
LongLive-2.0 : Une infrastructure parallèle NVFP4 pour la génération de vidéos longues
Découpage et Analyse Fine : Configuration de Mélanges Optimaux d'Experts
Découverte Agentique des Architectures Neurales : AIRA-Compose et AIRA-Design
Apprendre à prévoir : Révéler l'efficacité de déverrouillage de la distillation sur politique
DexJoCo : une plateforme d'évaluation et une boîte à outils pour la manipulation déxtere orientée tâche sur MuJoCo
L'évaluation interactive nécessite une approche de science du design
ESI-BENCH : Vers une intelligence spatiale incarnée qui referme la boucle perception-action
Analyse comparative de la détection militaire à l'aide d'images de drones à travers plusieurs spectres visuels
Classification automatisée des diagnostics psychiatriques selon la CIM : des méthodes classiques de TALN aux grands modèles de langage
Gestion coordonnée et optimale de la qualité de l'alimentation dans les réseaux de distribution en utilisant la capacité résiduelle des IBR communautaires
EllipseLIO : Odométrie LiDAR inertielle adaptative avec une représentation ellipsoïdale
SMoA : Adaptateur de modulation de spectre pour le réglage fin efficace en paramètres
Détection des réseaux de neurones artificiels profonds piégés par analyse de régression spectrale
L'illusion de la pensée : comprendre les forces et les limites des modèles de raisonnement à travers le prisme de la complexité des problèmes
Raisonnement Récursif Génératif
Pré-entraînement de sécurité : vers une nouvelle génération d'IA sécurisée
RubricEM : Apprentissage par renforcement méta-avec décomposition de politique guidée par une grille d'évaluation, au-delà des récompenses vérifiables
Lorsque la vision parle pour le son
AutoResearchClaw : Recherche autonome auto-renforçante avec collaboration humain-IA
Récompenses de processus avec fiabilité apprise
GoLongRL : Apprentissage par renforcement de contexte long orienté vers les capacités avec alignement multitâche
OpenComputer : des mondes logiciels vérifiables pour les agents d'utilisation d'ordinateur
Anti-Auto-Distillation pour le Renforcement par Apprentissage par Renforcement via l'Information Mutuelle Ponctuelle
Modulation ciblée des neurones par recherche de paires contrastives
Continuous Diffusion Scales Compétitivement avec Discrete Diffusion pour Langage
KVPO : GRPO natif pour les EDO pour l'alignement vidéo autoregressif via l'exploration sémantique KV
Code-as-Room : Génération de salles 3D à partir d'images de vue de dessus via la synthèse de code agentic
IA pour l'auto-recherche : feuille de route et guide utilisateur
SkillsVote : Gouvernance du cycle de vie des compétences des agents, de la collecte et de la recommandation à l'évolution
Lance : Modélisation multimodale unifiée par synergie multi-tâches
LongLive-2.0 : Une infrastructure parallèle NVFP4 pour la génération de vidéos longues
Découpage et Analyse Fine : Configuration de Mélanges Optimaux d'Experts
Découverte Agentique des Architectures Neurales : AIRA-Compose et AIRA-Design
Apprendre à prévoir : Révéler l'efficacité de déverrouillage de la distillation sur politique
DexJoCo : une plateforme d'évaluation et une boîte à outils pour la manipulation déxtere orientée tâche sur MuJoCo