Command Palette
Search for a command to run...
ACE-Ego-0 : Unification des données egocentriques humaines et robotiques pour le pré-entraînement VLA
ACE-Ego-0 : Unification des données egocentriques humaines et robotiques pour le pré-entraînement VLA
Résumé
Les modèles Vision-Language-Action (VLA) tirent parti de données incarnées à grande échelle et diversifiées, toutefois, l'extension de la collecte de trajectoires robotiques s'avère coûteuse et laborieuse. Des avancées récentes indiquent que les vidéos humaines égocentriques à grande échelle offrent une supervision complémentaire en environnement réel pour le pré-entraînement. Toutefois, l'entraînement conjoint sur des données humaines et robotiques demeure difficile en raison des divergences observées dans les espaces d'action, les structures d'incarnation, les dynamiques temporelles et la qualité de la supervision. Nous présentons ACE-EGO-0, un cadre unifié de pré-entraînement pour VLA exploitant conjointement des sources de données hétérogènes. Afin d'extraire une supervision de pré-entraînement à grande échelle à partir de vidéos humaines égocentriques, nous concevons un pipeline évolutif de conversion vidéo en action qui transforme les vidéos humaines brutes en trajectoires d'action pseudo au format robotique. Pour rendre ces étiquettes comparables aux démonstrations robotiques, ACE-EGO-0 s'appuie sur une représentation d'action unifiée fondée sur des actions dans l'espace caméra, un conditionnement morphologique et un découpage d'actions aligné temporellement. Pour exploiter de manière robuste la supervision d'action pseudo bruitée issue de vidéos humaines égocentriques, nous formulons un objectif d'entraînement tenant compte de la fiabilité, intégrant une perte auxiliaire humaine qui concentre la supervision sur les signaux fiables. Nous instancions ACE-EGO-0 sur 4.53K heures de données robotiques et de simulation, conjointement avec 1.48K heures de données humaines égocentriques étiquetées par des actions pseudo. Les expériences démontrent que l'intégration d'une supervision humaine à grande échelle, pondérée de manière à tenir compte de la fiabilité, améliore de façon constante tant le pré-entraînement conjoint unifié que l'affinement supervisé. ACE-EGO-0 atteint des performances de pointe sur les benchmarks RoboCasa GR1 TableTop et RoboTwin 2.0, tout en démontrant une capacité de transfert élevée vers la manipulation bimanuelle en environnement réel.
One-sentence Summary
ACE-EGO-0 is a unified vision-language-action pretraining framework that integrates robot and simulation data with egocentric human videos by converting raw videos into robot-format pseudo-actions via a camera-space unified action representation and a reliability-aware objective that concentrates supervision on reliable signals, achieving state-of-the-art performance on RoboCasa GR1 TableTop and RoboTwin 2.0 while demonstrating strong real-world bimanual transfer.
Key Contributions
- ACE-EGO-0 is a unified vision-language-action pretraining framework that aligns heterogeneous data sources through a shared camera-space action representation, cross-embodiment morphology conditioning, and time-aligned action chunking. This architecture systematically resolves coordinate frame, physical duration, and kinematic structure mismatches prior to joint training.
- A scalable egocentric video-to-action pipeline converts raw human footage into robot-format pseudo-action trajectories to enable large-scale supervision. The framework incorporates a reliability-aware training objective that dynamically weights auxiliary losses using step-level and dataset-level quality estimates to mitigate tracking noise and estimation bias.
- Trained on 4.53K hours of robot and simulation data alongside 1.48K hours of pseudo-action-labeled human videos, the model consistently improves both joint pretraining and supervised fine-tuning. ACE-EGO-0 achieves state-of-the-art performance on the RoboCasa GR1 TableTop and RoboTwin 2.0 benchmarks while demonstrating strong transfer to real-world bimanual manipulation.
Introduction
Vision-Language-Action models require massive, diverse embodied datasets to learn generalizable manipulation skills, but scaling robot data collection remains prohibitively expensive. Egocentric human videos present a highly scalable alternative, yet integrating them with robot demonstrations introduces significant technical hurdles. Prior methods struggle to align divergent coordinate frames, kinematic structures, and control frequencies, while naively training on noisy pseudo-action labels from human videos degrades policy performance. The authors leverage a unified pretraining framework that converts large-scale egocentric footage into robot-compatible action trajectories through a shared camera-space representation, morphology conditioning, and time-aligned action chunking. They further introduce a reliability-aware training objective that dynamically weights supervision quality, allowing the model to safely combine high-fidelity robot demonstrations with complementary human video data for state-of-the-art manipulation performance.
Dataset

Dataset Composition and Sources
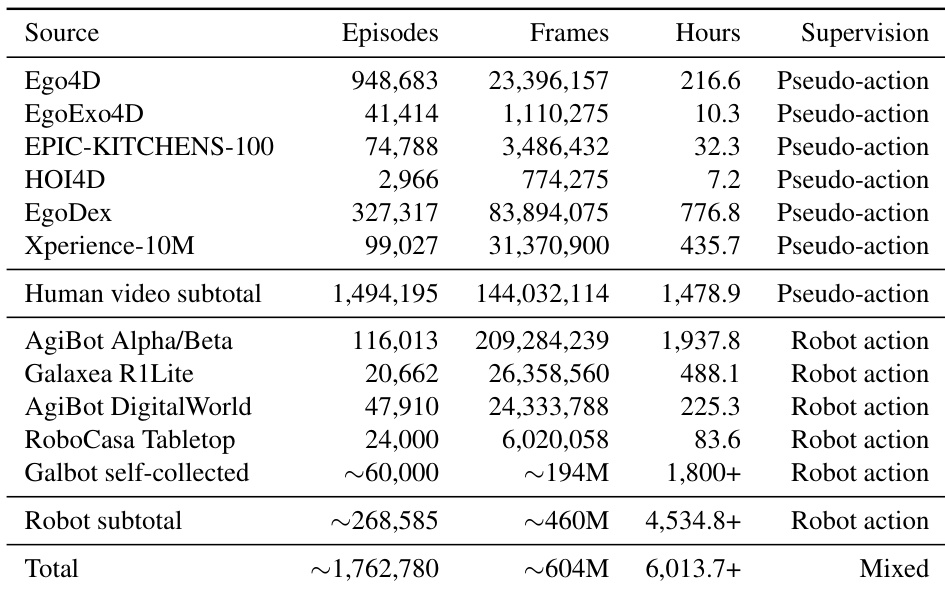
- The authors construct the ACE-Ego-0 pretraining pool containing over 6.0K hours of heterogeneous data drawn from robot demonstrations, simulation rollouts, and pseudo-action-labeled egocentric human videos.
- Robot and simulation sources include AgiBot Alpha and Beta demonstrations, Galaxea R1Lite data, AgiBot DigitalWorld simulation, RoboCasa Tabletop simulation with 24 tasks and 1,000 episodes each, and more than 1,800 hours of self-collected Galbot data.
- Human video sources comprise Ego4D, EgoExo4D, EPIC-KITCHENS-100, HOI4D, EgoDex, and Xperience-10M, covering diverse kitchens, homes, and workshops to capture long-tail manipulation behaviors.
Subset Details and Filtering Rules
- Robot and simulation data span humanoid, single-arm wheeled, and mobile bimanual embodiments with control frequencies ranging from 10 to 30 Hz, providing sensor-grounded end-effector action labels.
- Human video clips are filtered to a duration between 4 and 30 seconds to ensure the presence of complete manipulation primitives.
- The authors apply an ego-interaction filter that discards observer-centric clips based on face detection confidence thresholds and a captioning filter that retains only clips containing both manipulation verbs and object nouns.
- This processing pipeline yields 1,478 hours of pseudo-action-labeled clips from the human video sources.
Training Usage and Mixture Strategy
- The authors sample data at the dataset-group level using controlled weights to manage the contribution of each source independently.
- Robot sources are supervised with the main action objective, while human-video sources are routed through a reliability-aware human loss to accommodate the lower fidelity of vision-based pseudo-labels.
- This separation enables large human-video corpora to contribute broad visual and behavioral coverage without overwhelming the higher-fidelity robot demonstrations.
Processing and Standardization Details
- Robot end-effector poses are transformed into the head-camera frame using calibrated camera extrinsics.
- Human data undergoes a five-stage pipeline comprising curation, video selection, 3D hand reconstruction, action parameterization, and quality control.
- Reconstruction utilizes SAM3 tracking and HaMeR for MANO parameter estimation, followed by global trajectory optimization to reduce jitter and reprojection error, leveraging camera poses estimated by VIPE before converting actions to the head-camera frame.
- Actions are standardized into a unified 22-dimensional bimanual vector per arm consisting of position, continuous 6D rotation, gripper state, and an activity flag.
- Gripper distances are linearly normalized to a range of 0.04 to 0.10 meters, and trajectories with minimal variation are assigned a neutral gripper state.
- Quality control filters remove episodes containing NaN values, exhibiting insufficient motion energy, showing velocity spikes, or displaying implausible bimanual correlations.
- The authors validate trajectories by masking frames with non-positive depth or projections falling outside image boundaries.
Experiment
ACE-EGO-0 is evaluated across two simulation benchmarks for humanoid and bimanual manipulation, alongside a physical robot platform, to validate its cross-domain generalization and deployment simplicity. The results demonstrate that the camera-space action interface and embodiment-agnostic design enable robust execution of long-horizon sequences and contact-rich coordination without requiring source-specific coordinate transformations. Component and data ablations further validate that morphology conditioning, temporal alignment, and reliability-aware training are critical for stable learning, while human egocentric videos substantially improve adaptation by filling action coverage gaps in data-scarce fine-tuning regimes. Collectively, these findings confirm that unified pretraining paired with camera-space prediction and human video augmentation yields a highly transferable policy for complex real-world manipulation.
The authors specify the hyperparameters for the ACE-EGO-0 model, including auxiliary loss weights, human channel priors, step weights, dataset priors, and smoothing settings. The human channel prior assigns high importance to position channels while downweighting rotation and gripper channels. Step weights and dataset priors are calibrated using dataset-specific percentiles and ratios relative to robot references. The auxiliary loss utilizes a specific weight and Huber transition parameter. Human channel priors prioritize position data over rotation and gripper channels. Step weights and dataset priors are adapted using percentiles and ratios derived from the data.
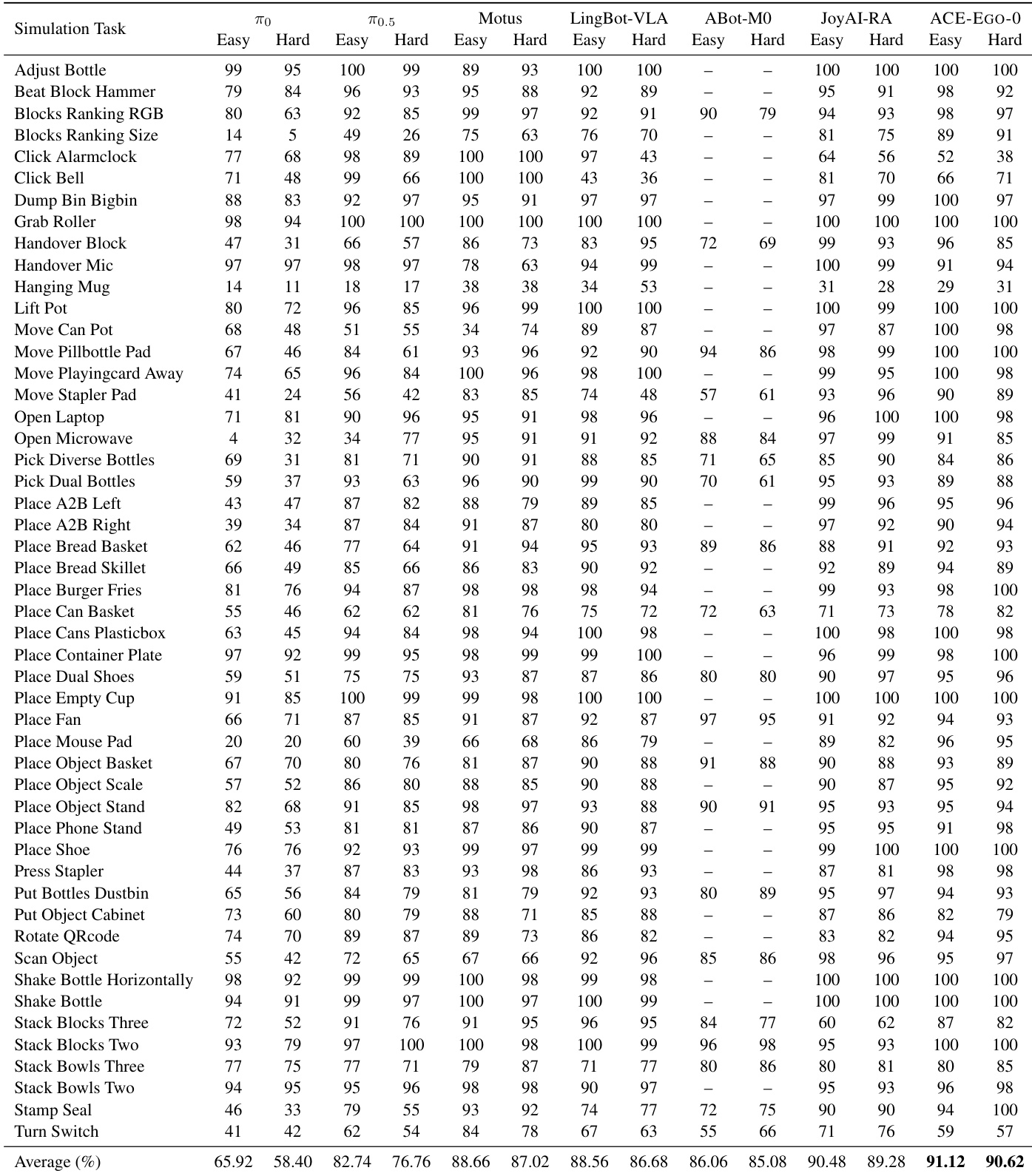
Results show that ACE-EGO-0 achieves the highest average success rates in both easy and hard settings on the RoboTwin 2.0 benchmark, outperforming all baselines. The model demonstrates robust generalization across diverse manipulation tasks, including bimanual coordination and tool use. ACE-EGO-0 achieves the highest average success rates in both easy and hard settings compared to baselines like JoyAI-RA and LingBot-VLA. The performance improvement is distributed across diverse manipulation primitives, including grasping, placement, and bimanual coordination. The model maintains a consistent lead over the next best baseline across both difficulty levels.
The authors construct a pretraining dataset that integrates human egocentric videos and robot manipulation data. The human data is supervised via pseudo-actions, while the robot data provides direct action supervision. This combination of diverse sources enables the model to learn from a wide range of behavioral examples and control signals. The dataset merges human egocentric videos and robot demonstrations to cover a broad spectrum of manipulation tasks. Human data sources are supervised with pseudo-actions, whereas robot data relies on direct action logs. The dataset encompasses various sources, including household interaction videos and specialized robot platforms.
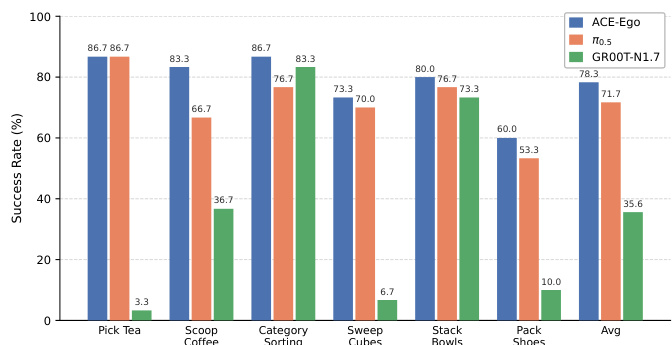
{ "summary": "The experiment evaluates the success rates of three models, ACE-Ego, π0.5, and GR00T-N1.7, on a real-robot platform across six manipulation tasks. ACE-Ego consistently achieves the highest success rates, leading in five of the six tasks and attaining the highest average performance. In contrast, GR00T-N1.7 shows significantly lower performance, particularly on tasks requiring complex coordination or long-horizon sequences.", "highlights": [ "ACE-Ego achieves the highest average success rate, outperforming both π0.5 and GR00T-N1.7.", "ACE-Ego leads in performance across five of the six individual tasks evaluated.", "GR00T-N1.7 exhibits notably lower success rates on tasks such as Pick Tea, Sweep Cubes, and Pack Shoes." ] }
The authors evaluate the ACE-EGO-0 model on the RoboCasa GR1 TableTop benchmark, which comprises 24 manipulation tasks involving pick-and-place and articulated objects. The results indicate that ACE-EGO-0 achieves the highest average success rate among all evaluated baselines, demonstrating superior performance across the entire task set. ACE-EGO-0 surpasses all baseline models, including GR00T-N1.6 and JoyAI-RA, in average success rate on the RoboCasa benchmark. The model maintains consistent performance improvements across both articulated-object interaction and pick-and-place rearrangement categories. The camera-space action interface allows for broad generalization, benefiting a wide range of manipulation tasks rather than a narrow subset.
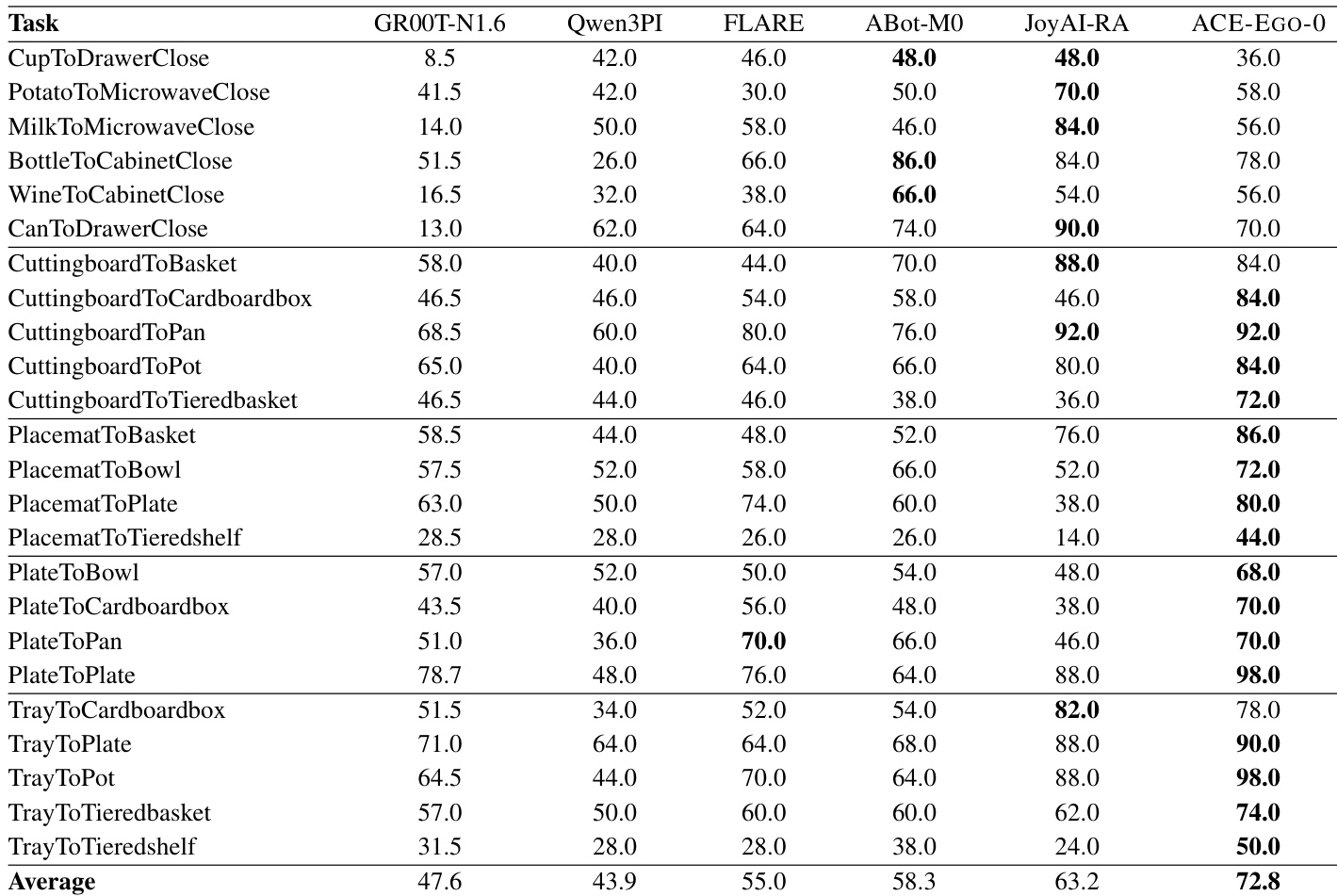
The evaluation setup tests the model across multiple simulation and real-robot benchmarks, including the RoboTwin 2.0, RoboCasa TableTop, and a six-task real-world platform, while comparing it against several established baselines. These experiments collectively validate the system's capacity to generalize across diverse manipulation scenarios, ranging from bimanual coordination and tool use to articulated object handling and long-horizon sequences. Qualitatively, the model consistently demonstrates robust performance and maintains a clear advantage over competing approaches across both easy and challenging difficulty levels. Ultimately, the results confirm that the combined human and robot pretraining strategy alongside the camera-space action interface enables reliable, broad-spectrum robotic manipulation without task-specific degradation.