Command Palette
Search for a command to run...
PerceptionDLM : Perception parallèle de régions avec des modèles de langage de diffusion multimodaux
PerceptionDLM : Perception parallèle de régions avec des modèles de langage de diffusion multimodaux
Résumé
Les grands modèles de langage multimodaux (MLLMs) ont réalisé des progrès remarquables dans les tâches de compréhension visuelle. Cependant, la plupart des MLLMs existants reposent sur une génération autorégressive, ce qui limite leur efficacité pour les tâches de perception nécessitant le légendage de plusieurs régions. Dans ce travail, nous proposons PerceptionDLM, un modèle de langage multimodal de diffusion optimisé pour une perception parallèle et efficace des régions. Construit sur la base de PerceptionDLM-Base, un modèle de référence fondamental robuste qui atteint des performances de pointe parmi les MLLMs de diffusion open-source, notre architecture exploite pleinement la nature du décodage parallèle des DLMs. Plus précisément, nous introduisons un prompting efficace et un masquage d'attention structuré afin de permettre la perception simultanée de plusieurs régions masquées, permettant au modèle de générer des descriptions de régions en parallèle aux niveaux séquence et token. Cette conception améliore considérablement l'efficacité de l'inférence par rapport aux approches existantes qui traitent les régions de manière séquentielle. Afin d'évaluer systématiquement la propriété de parallélisme de la capacité de perception visuelle des DLMs, nous construisons un nouveau benchmark de légendage localisé détaillé et parallèle (ParaDLC-Bench) en étendant le DLC-Bench pour inclure plusieurs masques de région par image, permettant une évaluation conjointe de la qualité du légendage et de l'efficacité de l'inférence. Les expériences démontrent que PerceptionDLM maintient des performances compétitives en légendage de régions tout en réalisant des améliorations substantielles de vitesse pour les tâches de perception multi-régions. Nos résultats mettent en évidence le potentiel des modèles de langage multimodaux de diffusion pour une perception visuelle parallèle et efficace. À notre connaissance, nous sommes les premiers à réaliser un légendage et une perception parallèles de régions en tirant parti des avantages des modèles de langage de diffusion. Le code, les modèles et les jeux de données sont mis à disposition.
One-sentence Summary
PerceptionDLM is a multimodal diffusion language model that employs efficient prompting and structured attention masking to simultaneously generate region descriptions at both the sequence and token levels, substantially accelerating multi-region visual captioning while maintaining competitive accuracy on the newly constructed ParaDLC-Bench benchmark.
Key Contributions
- The paper introduces PerceptionDLM, a multimodal diffusion language model that employs efficient prompting and structured attention masking to generate descriptions for multiple image regions simultaneously. This architecture enables joint sequence- and token-level parallel decoding, directly addressing the linear latency growth of autoregressive region perception.
- To evaluate parallel visual perception, the work constructs ParaDLC-Bench, an extension of DLC-Bench that scales localized captioning datasets to support concurrent multi-region masks per image. This benchmark enables direct joint evaluation of caption quality and inference efficiency across sequential and parallel decoding paradigms.
- Experiments demonstrate that PerceptionDLM maintains competitive region captioning accuracy while delivering up to a 3.5 times throughput speedup in dense perception scenarios compared to autoregressive baselines. The framework also establishes a strong open-source diffusion baseline by outperforming LLaDA-V on 15 of 16 evaluated multimodal benchmarks.
Introduction
Multimodal large language models have significantly advanced visual understanding, yet real-world applications increasingly demand fine-grained localization that requires describing multiple image regions simultaneously. Existing systems predominantly rely on autoregressive decoding, which processes regions sequentially and causes inference latency to scale linearly as query density increases. To overcome this efficiency bottleneck, the authors introduce PerceptionDLM, a multimodal diffusion language model optimized for parallel region perception. By combining a strong discrete diffusion baseline with efficient prompting and structured attention masking, the framework jointly generates multiple region captions within a single denoising pass, dramatically improving throughput without sacrificing accuracy. The authors also establish ParaDLC-Bench to systematically benchmark parallel visual perception and release their code and models to accelerate open research.
Dataset

-
Dataset Composition and Sources: The authors construct ParaCaption-5.7M, a high-quality training corpus designed for parallel-region captioning in multimodal diffusion language models. The dataset aggregates region-level mask and caption pairs sourced from the SA-1B segmentation dataset and the COCONut dataset.
-
Subset Details and Filtering Rules:
- COCONut subset: Provides 334,000 images containing 3.4 million masks. The authors leverage its built-in mask and category annotations, generate initial descriptions with GAR-8B, and verify semantic alignment against ground-truth categories using Qwen3-8B.
- SA-1B subset: Provides 83,000 images containing 2.3 million masks. The pipeline first removes completely occluded or part-level masks. After GAR-8B generates initial descriptions, an LLM extracts core categories. SAM3 then re-predicts the masks, and the authors discard any samples where the re-predicted masks show low Intersection over Union (IoU) with the original ground-truth masks.
-
Model Usage and Training Strategy: The final 5.7 million mask-caption pairs are merged into a single training corpus to fine-tune diffusion language models for generating parallel descriptions across multiple masked regions. The authors treat the aggregated dataset as a unified training resource without specifying explicit train-validation splits or mixture ratios, focusing instead on improving inter-region feature independence and reducing cross-target hallucination during concurrent generation.
-
Processing and Metadata Construction: Both subsets undergo a unified post-processing stage that enforces strict length constraints and applies anti-repetition filtering to eliminate hallucinated content. The authors deploy an automated data construction pipeline that pairs segmentation masks with LLM-generated descriptive text, ensuring high semantic fidelity for multi-target scenarios.
Method
The authors propose a framework built around PerceptionDLM, a model designed to handle both parallel region perception and sequential per-region generation. Refer to the framework diagram:

The architecture begins with a Visual Encoder that processes input images through dynamic tiling and patch embedding. These visual tokens are then passed through an MLP Projector to generate pixel-unshuffled representations. To handle specific regions of interest, the model employs RoI-aligned feature replay via a RoI-Align module, which extracts region-aligned feature tokens. Additionally, region prompting is facilitated through Visual Prompt Embedding, which maps specific regions to their corresponding embeddings. The model also utilizes a Structured Attention Mask to manage interactions between image tokens, RoI features, and generated captions, ensuring that attention is appropriately restricted during the decoding process.
For generation, the authors leverage two distinct strategies. In parallel region perception, the model takes multiple masked regions and performs parallel decoding to generate captions for each mask simultaneously. In sequential per-region generation, the model adopts an autoregressive approach where regions are described one by one, allowing for detailed, region-specific descriptions. This sequential process is driven by an AR-based region-specific model, which refines captions step-by-step as more regions are masked and described.
The training and evaluation process involves generating captions for masked regions and assessing their accuracy through positive and negative questions. An LLM Judge evaluates the generated captions, assigning scores based on whether the description correctly mentions, mislocates, or hallucinates attributes of the masked regions. This structured evaluation ensures that the model learns to produce accurate and contextually appropriate descriptions for each region.
Experiment
These gains indicate that the proposed training pipeline and multimodal architecture significantly enhance diffusion-based models' capabilities for general-purpose understanding and perception.
Competitive performance with advanced autoregressive VLMs. PerceptionDLM-Base is also competitive with recent autoregressive VLMs of similar size. Across the 16 benchmarks, PerceptionDLM-Base achieves superior or comparable scores on a majority of the tasks. It excels particularly in fine-grained visual perception systematically outperforming both Qwen2.5-VL-7B [3] and InternVL3-8B [62] in these specific areas. This suggests that PerceptionDLM-Base possesses a distinct advantage in region-sensitive and detail-oriented visual understanding. While a performance gap remains in complex, reasoning-heavy scenarios (e.g., MMMU [55] and MathVista [27]), the paper observe that arbitrary-order parallel decoding fundamentally limits the reasoning potential of diffusion language models [32]. Thus, the paper adopt autoregressive-order decoding for PerceptionDLM-Base during these mathematical reasoning evaluations to better preserve reasoning traces. Inspired by recent advancements like DeepSeek-R1 [16], this bottleneck highlights a clear avenue for future work: leveraging Reinforcement Learning (RL) to further unlock the reasoning potential of diffusion-based VLMs.
- 4.3 Evaluation on Captionina Benchmarks with PerceptionDLM
To further assess fine-grained multimodal understanding, the paper evaluate PerceptionDLM on region captioning benchmarks, including the multi-region ParaDLC-Bench and the single-region DLC-Bench [23].
the table Comparison on the ParaDLC-Bench and DLC-Bench. The symbol 1∗ indicates that during the inference of these baseline diffusion VLMs, the paper set the number of denoising steps equal to the generation length, aiming to achieve their best possible generation quality.

Superior region captioning capability among diffusion VLMs. As shown in the table, PerceptionDLM exhibits leading advantages over existing diffusion-based VLMs. On ParaDLC-Bench, it achieves an average accuracy of 62.4%, nearly doubling the performance of SDAR-VL [9] (31.3%) and LLaDA-V [50] (35.2%). This substantial margin is consistent on DLC-Bench [23] (51.9% vs. 24.6% for baselines).
Competitive performance with unprecedented efficiency. To analyze efficiency, the paper adopt the Tokens Per Forward (TPF) metric [35], which quantifies the average number of generated tokens per forward pass Compared with AR-based region-specific models (e.g., DAM and GAR), PerceptionDLM demonstrates highly competitive accuracy while unlocking massive speed advantages. Although its average accuracy on ParaDLC-Bench is slightly lower than AR-based models, PerceptionDLM drastically reduces the total inference time across the benchmark to just 276 seconds, compared to 479 seconds for GAR and 718 seconds for PixelRefer [53].
This efficiency is driven by the parallel decoding paradigm. While AR models and standard DVLM baselines are restricted to a TPF of 1, PerceptionDLM achieves a TPF of 2.9, generating multiple region captions simultaneously. Note that on DLC-Bench, where instances contain only a single mask, the parallel-processing advantage cannot be fully exploited. Nevertheless, PerceptionDLM still sets a new benchmark for diffusion-based VLMs across both settings.
To systematically analyze the computational advantages of PerceptionDLM, the paper conduct a speed and efficiency profiling. As shown in the figure(b), PerceptionDLM achieves near-linear TPS growth while maintaining stable per-image latency (~2.9s). In contrast, GAR-8B is bottlenecked at a nearly constant TPS, and its latency degrades approximately linearly with the number of regions. As shown in the figure(c), under a constant heavy workload (4 masks per image), increasing the degree of parallelism (masks processed per pass) yields strong scaling for PerceptionDLM: throughput improves by 3.44 times, and single-image latency drops from 10.04s to 2.92s when fully parallelized.
The authors employ a four-stage training pipeline that starts with training the projector on a smaller dataset. Later stages expand the training to include the LLM backbone, utilizing progressively larger and more diverse datasets. The learning rate is reduced in the subsequent phases to facilitate stable fine-tuning of the entire model. The training process transitions from projector-only alignment to joint training of the vision tower and language model. Dataset size and diversity increase significantly across the stages, reaching over twenty million samples in later phases. The same vision tower and LLM backbone are utilized consistently throughout all training stages.

The authors compare two variations of the PerceptionDLM-Base model to determine the effectiveness of training the Vision Transformer versus keeping it frozen. The data indicates that freezing the visual encoder generally leads to better performance across most multimodal benchmarks. While the trained variant shows a slight advantage in complex reasoning tasks like MMMU, the frozen baseline is superior in general visual understanding and VQA tasks. Freezing the Vision Transformer results in better performance across the majority of evaluated benchmarks. The frozen baseline model outperforms the trained variant in tasks requiring general visual perception and VQA. Training the visual encoder offers a marginal benefit primarily in complex reasoning scenarios like MMMU.
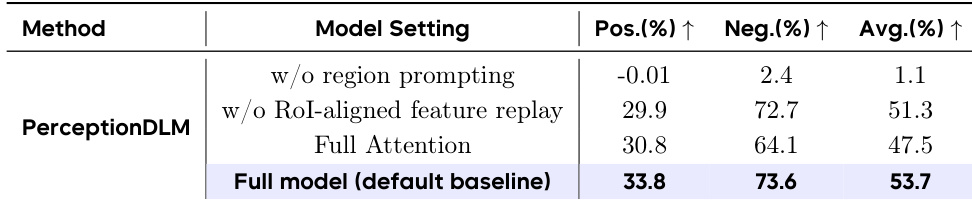
The authors conduct an ablation study on the PerceptionDLM model to evaluate the contribution of specific components like region prompting and RoI-aligned feature replay. The results demonstrate that the full model configuration achieves the highest performance across positive, negative, and average metrics compared to the ablated variants. The full model setting yields the best overall performance, outperforming configurations with removed components. Removing region prompting causes a drastic decline in performance, indicating it is essential for the model. The absence of RoI-aligned feature replay results in lower scores than the full model, validating its contribution.
The authors evaluate the PerceptionDLM model's performance across different sequence lengths to assess region perception capabilities. The results demonstrate that a sequence length of 32 yields superior accuracy compared to a length of 64 across all measured categories. This indicates that the model achieves better region understanding when constrained to shorter generation sequences. PerceptionDLM achieves higher performance with a sequence length of 32 than with a length of 64. The model shows consistent improvements in positive, negative, and average metrics at the shorter length.

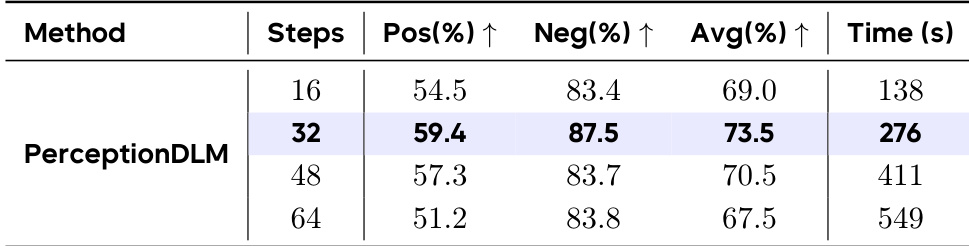
The authors analyze the impact of varying generation steps on the PerceptionDLM model's performance and efficiency. The results indicate that the highlighted configuration, corresponding to the default inference setting, achieves the highest average accuracy. Deviating from this setting by increasing or decreasing the steps results in lower performance scores. The model achieves peak performance at the default inference setting, which is highlighted in the the the table. Increasing the number of steps beyond the optimal point leads to diminishing returns and longer inference times. Reducing the number of steps results in faster inference but significantly lower accuracy compared to the default setting.
The evaluation utilizes a progressive four-stage training pipeline that transitions from projector alignment to joint fine-tuning on increasingly diverse datasets to validate the model's architectural and optimization strategies. Comparative experiments reveal that freezing the visual encoder generally enhances performance across standard visual understanding tasks, while training it only provides marginal gains in complex reasoning. Further ablation and sensitivity analyses confirm that region prompting and RoI-aligned feature replay are essential for robust multimodal capabilities, and that optimal accuracy is consistently achieved with shorter generation sequences and a calibrated inference step count.