Command Palette
Search for a command to run...
Kairos: Une pile de modèles du monde native pour l'IA physique
Kairos: Une pile de modèles du monde native pour l'IA physique
Résumé
Les modèles de monde évoluent de générateurs visuels passifs vers une infrastructure opérationnelle fondamentale pour le Physical AI : ils doivent acquérir nativement des connaissances du monde à partir d'expériences hétérogènes, maintenir des états persistants sur de longs horizons et s'exécuter de manière efficace dans le respect des contraintes réelles de déploiement. Nous présentons Kairos, une pile de modèles de monde native conçue autour de ces exigences. (1) Kairos apprend le monde en inaugurant un Paradigme de pré-entraînement natif régi par un Curriculum de données multi-incarnations, qui organise des vidéos de monde ouvert, des données comportementales humaines et des interactions robotiques selon un parcours de développement progressif. (2) Kairos maintient le monde par une compréhension, une génération et une prédiction unifiées du monde au sein d'une Architecture unifiée native dotée d'une Attention temporelle linéaire hybride, où l'attention à fenêtre glissante capture la dynamique locale, les fenêtres glissantes dilatées capturent les dépendances à moyenne portée, et l'attention linéaire à portes maintient une mémoire globale persistante. Nous établissons des bornes théoriques formelles démontrant que cette factorisation temporelle limite strictement l'accumulation des erreurs, garantissant mathématiquement la propagation de l'état sur des horizons étendus. (3) Kairos fait fonctionner le monde en intégrant une Co-conception système consciente du déploiement afin de supporter la génération de rollout à faible latence sur du matériel serveur et grand public pour des boucles d'observation-action-retour en conditions réelles. Les expériences menées sur des benchmarks de modèles de monde incarnés, de long horizon et de politiques d'action montrent que Kairos atteint des performances de premier ordre tout en offrant un compromis robuste entre efficacité et capacité. Ensemble, ces résultats positionnent Kairos comme un socle opérationnel cohérent pour l'intelligence physique auto-évolutive de demain.
One-sentence Summary
Kairos is a native world model stack for Physical AI that combines a cross-embodiment data curriculum with a unified architecture employing hybrid linear temporal attention to theoretically bound error accumulation, integrates a deployment-aware system co-design for low-latency rollout on server and consumer-grade hardware, and achieves top-level performance across embodied, long-horizon, and action-policy benchmarks.
Key Contributions
- Kairos introduces a Native Pre-training Paradigm governed by a Cross-Embodiment Data Curriculum that structures open-world videos, human behavioral data, and robot interactions into a progressive developmental pathway for acquiring foundational physical knowledge. This curriculum enables the model to natively learn cross-embodiment representations.
- Kairos employs a Native Unified Architecture that integrates world understanding, generation, and prediction via a Hybrid Linear Temporal Attention mechanism combining sliding windows, dilated windows, and gated linear attention. Formal theoretical bounds demonstrate that this temporal factorization strictly limits error accumulation and guarantees stable state propagation across extended horizons.
- A Deployment-Aware System Co-Design optimizes rollout generation for low-latency inference on server and consumer-grade hardware to support real-world observation-action-feedback loops. Evaluations on LIBERO-plus and RoboTwin 2.0 demonstrate top-level performance across embodied and long-horizon benchmarks while maintaining a strong efficiency-capability trade-off.
Introduction
World models are transitioning from passive video generators to foundational substrates for physical AI, where they must support embodied interaction, temporal prediction, and continual adaptation in real-world robotics applications. Prior systems face critical bottlenecks, including fragmented knowledge acquisition from heterogeneous data sources, the inability to maintain global state consistency over long horizons due to error accumulation and quadratic attention costs, and a persistent gap between world understanding and actionable control, all while struggling to meet the strict latency and memory constraints required for closed-loop deployment. The authors introduce Kairos, a native world model stack that integrates a Cross-Embodiment Data Curriculum to synthesize physical laws and behavioral semantics from scratch, employs a hybrid linear temporal memory mechanism to guarantee persistent state propagation with linear complexity, and implements a deployment-aware co-design to enable real-time, low-latency inference on edge hardware for future self-evolving agents.
Dataset

-
Dataset Composition and Sources: The authors construct a hybrid dataset for the Kairos world model by combining open-source public resources with extensive in-house proprietary data. Public sources include general video datasets such as Koala-36M, Openhumanvid, and VidGen, along with specialized robotics corpora like AgiBotWorld-Beta and Droid. In-house data is gathered through a hierarchical taxonomy spanning tens of millions of leaf nodes across four domains: human, robot, general scenes, and physical phenomena. This proprietary collection also features first-person ego-centric recordings of human manipulation to fill gaps in fine-grained interaction scenarios. The pipeline accumulates hundreds of millions of standardized clips from several million hours of raw footage.
-
Key Subset Details: Open-source subsets provide the foundational backbone with large-scale diverse visual samples. The in-house internet subset offers fine-grained coverage through hundreds of secondary and thousands of tertiary categories within the taxonomy. The in-house ego-centric subset delivers high-precision manipulation data absent from public repositories. Initial cleaning removes corrupted files, duplicates, and clips shorter than 5 seconds. The dataset is curated using a progressive filtering strategy to supply high-quality, low-noise samples for distinct training phases.
-
Usage and Processing: The data forms the core training pool for the model, with the authors applying a multi-dimensional quality assessment to enhance data purity. Text metadata is enhanced to improve model capabilities; physics-tagged captions explicitly describe underlying laws like gravity, friction, and collision dynamics. Long-horizon task data for human and robot interactions includes decomposed causal chains and executable sub-steps to support sequence consistency. During early training phases, videos with excessive text are excluded based on an OCR score derived from text region proportion to aid convergence.
-
Cropping, Metadata, and Engineering: Raw videos are segmented using PySceneDetect with multiple detectors to achieve high precision and recall. Segments are constrained to 5 to 40 seconds, with longer shots split into 20-second clips and shorter ones discarded to balance spatiotemporal integrity and training efficiency. Metadata construction involves scoring filters for aesthetic quality via a CLIP-based predictor, motion intensity using RAFT optical flow, AIGC detection with a ViT-Large discriminator, NSFW filtering via Falonsai, blurriness assessment through Laplacian operators, and human motion tracking with YOLOX and ByteTrack. Deduplication employs CLIP embeddings in a scalable pool to retain only the higher-resolution version when similarity exceeds a threshold. The authors optimize the data engineering infrastructure for over 30x throughput improvement using distributed scheduling, CPU-concurrent decoding, FP16 mixed precision, and pipeline architectures for shot detection, frame filtering, and captioning.
Method
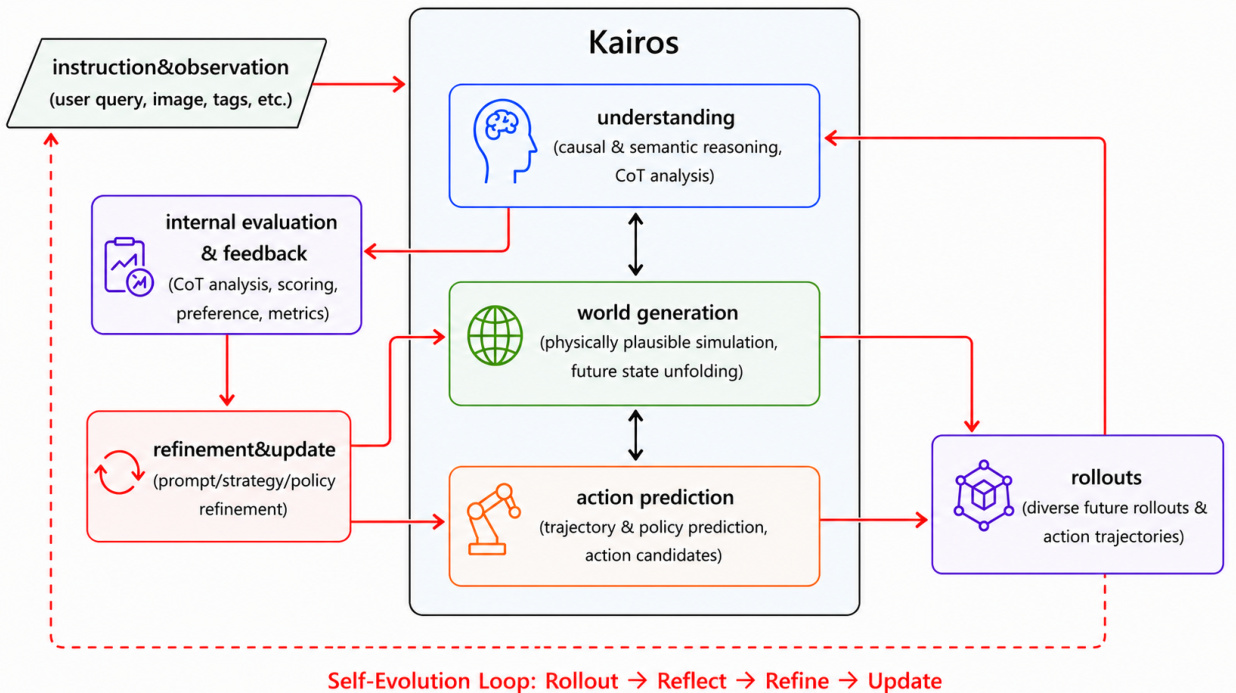
The authors introduce Kairos, a native world model stack designed to transition from passive visual generators to foundational infrastructure for Physical AI. As shown in the framework overview:
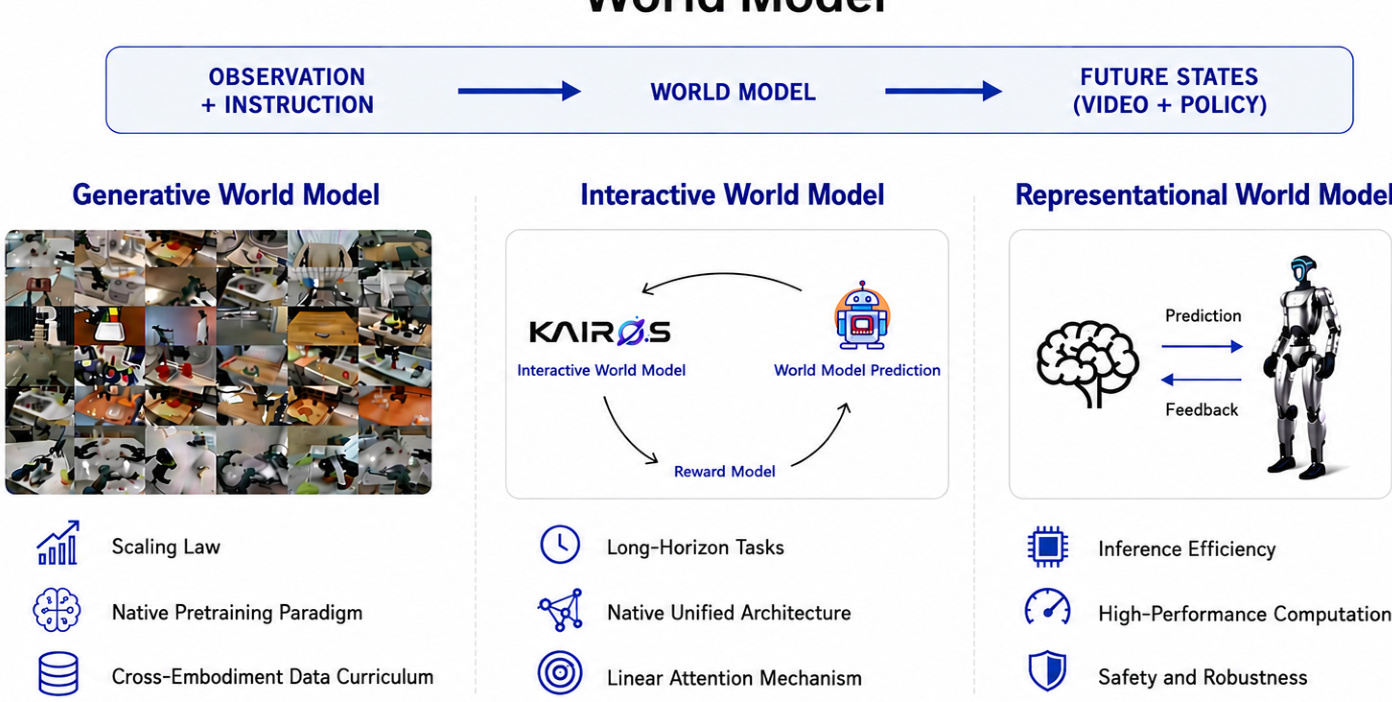 The architecture takes observation and instruction as input to predict future states, encompassing video generation and policy execution. The system is organized into three primary operational paradigms: Generative World Model, Interactive World Model, and Representational World Model. This design enables the system to scale efficiently, maintain native pretraining capabilities, and support cross-embodiment data curation while ensuring inference efficiency and safety.
The architecture takes observation and instruction as input to predict future states, encompassing video generation and policy execution. The system is organized into three primary operational paradigms: Generative World Model, Interactive World Model, and Representational World Model. This design enables the system to scale efficiently, maintain native pretraining capabilities, and support cross-embodiment data curation while ensuring inference efficiency and safety.
Rather than relying on modular platform-level integration, Kairos employs a single endogenous backbone that natively unifies world understanding, generation, and prediction. Refer to the detailed architectural flow:
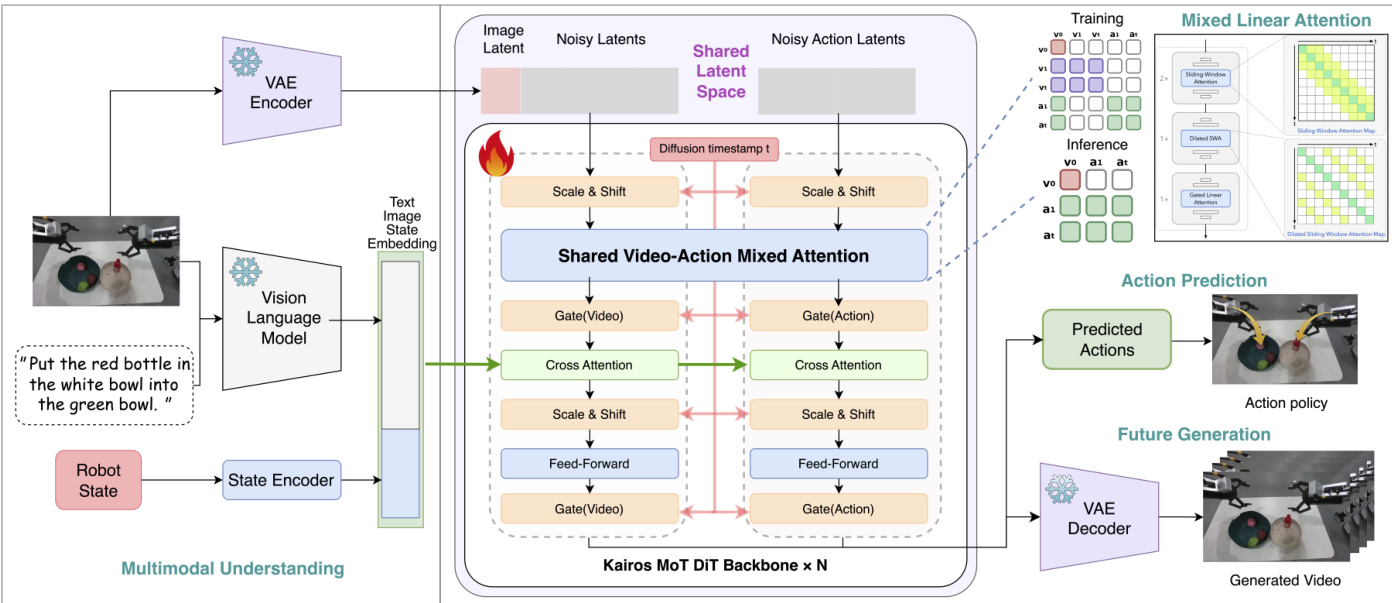 Multimodal inputs are processed through a Vision-Language Model and state encoders to form a unified embedding space. These embeddings condition a Mixture-of-Transformers Diffusion Transformer backbone, which jointly models video and action tokens within a shared latent space. This unified conditioning allows the diffusion model to leverage high-level semantic guidance while retaining the expressive capacity of the latent diffusion framework.
Multimodal inputs are processed through a Vision-Language Model and state encoders to form a unified embedding space. These embeddings condition a Mixture-of-Transformers Diffusion Transformer backbone, which jointly models video and action tokens within a shared latent space. This unified conditioning allows the diffusion model to leverage high-level semantic guidance while retaining the expressive capacity of the latent diffusion framework.
The backbone architecture is built upon a hybrid linear attention mechanism designed to satisfy efficiency, long-horizon modeling, and expandability requirements. As illustrated in the DiT block structure:
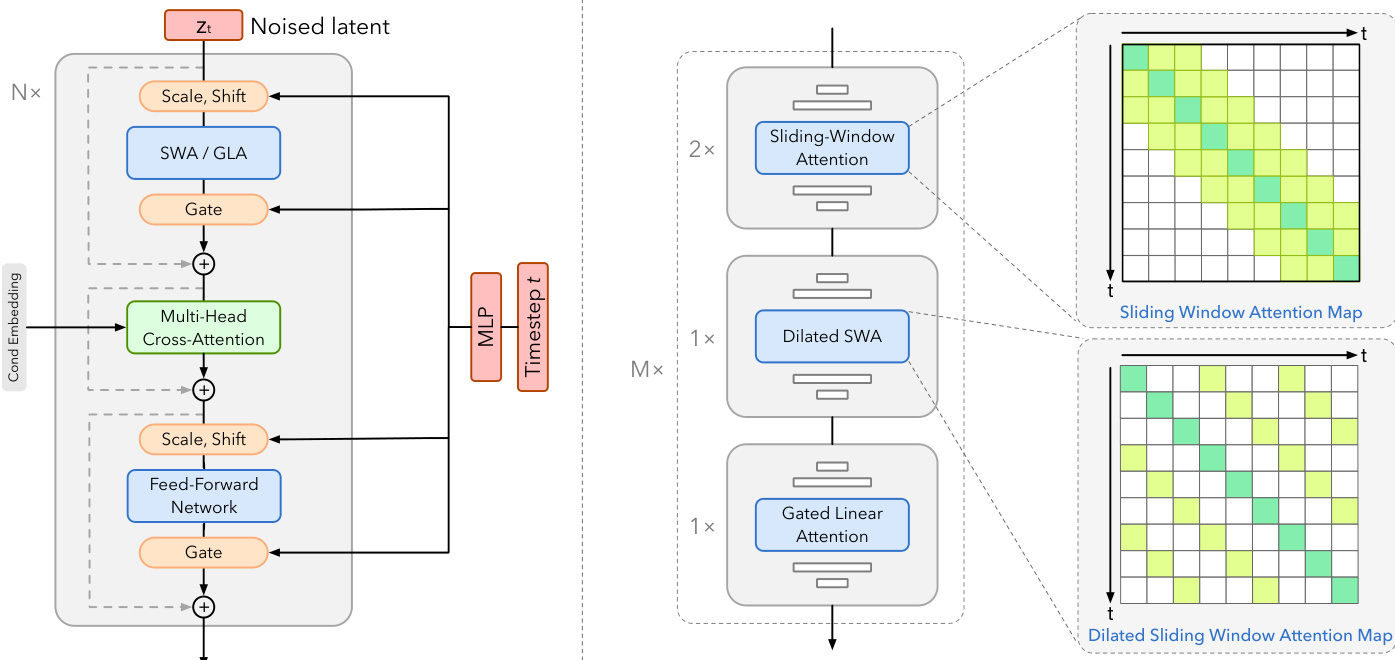 Each block integrates Scale and Shift operations, Multi-Head Cross-Attention, Feed-Forward Networks, and gating mechanisms. To manage temporal dependencies across varying scales, the model interleaves three distinct attention pathways. Sliding Window Attention captures local dynamics, Dilated Sliding Window Attention extends the receptive field for mid-range interactions, and Gated Linear Attention maintains global causal memory with linear complexity.
Each block integrates Scale and Shift operations, Multi-Head Cross-Attention, Feed-Forward Networks, and gating mechanisms. To manage temporal dependencies across varying scales, the model interleaves three distinct attention pathways. Sliding Window Attention captures local dynamics, Dilated Sliding Window Attention extends the receptive field for mid-range interactions, and Gated Linear Attention maintains global causal memory with linear complexity.
The internal mechanism of the attention module is depicted as follows:
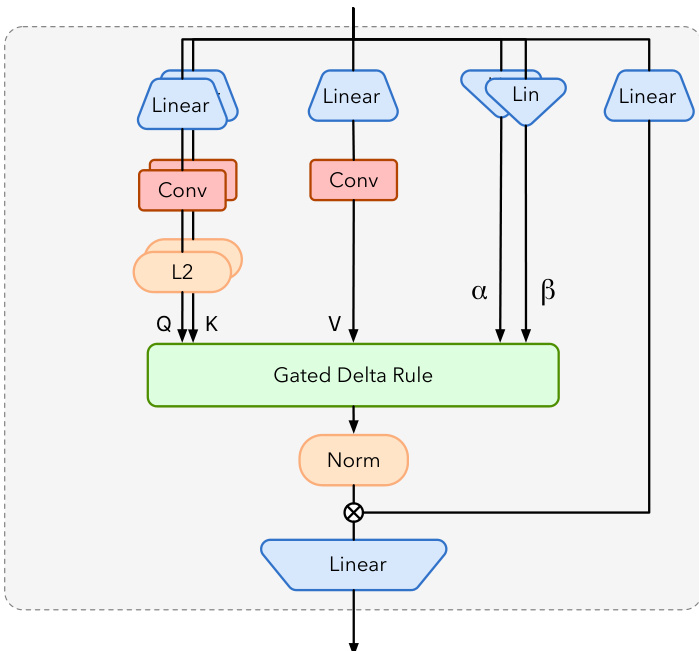 The Gated Linear Attention module serves as the primary mechanism for long-range information propagation, addressing the key collision problem found in vanilla linear transformers. The computation at each time step involves feature extraction where query, key, and value vectors are projected alongside a soft writing strength gate. Memory retrieval interpolates old and new values, followed by a delta state update that removes outdated associations and writes new information. This process is mathematically equivalent to a single step of stochastic gradient descent on an online regression loss. To further control global forgetting, a decay gate adaptively modulates the contribution of the previous state, ensuring precise associative correction and adaptive long-term memory management.
The Gated Linear Attention module serves as the primary mechanism for long-range information propagation, addressing the key collision problem found in vanilla linear transformers. The computation at each time step involves feature extraction where query, key, and value vectors are projected alongside a soft writing strength gate. Memory retrieval interpolates old and new values, followed by a delta state update that removes outdated associations and writes new information. This process is mathematically equivalent to a single step of stochastic gradient descent on an online regression loss. To further control global forgetting, a decay gate adaptively modulates the contribution of the previous state, ensuring precise associative correction and adaptive long-term memory management.
The multi-stage training pipeline is outlined in the curriculum diagram:
 To align the model with physical reality, the authors leverage a Cross-Embodiment Data Curriculum that systematically evolves the model from passive observation to active robotic control. The training process is structured into three progressive stages. The initial stage focuses on physical pretraining using massive web-scale video datasets to internalize general spatial-temporal dynamics and physical laws. The curriculum then transitions to human-centric behavior alignment, where the model learns task-structured semantics and causal consequences from human demonstrations. Finally, the joint world-action training stage anchors the learned priors into robot-specific interaction data, co-optimizing the video and action components to bridge perception and actuation.
To align the model with physical reality, the authors leverage a Cross-Embodiment Data Curriculum that systematically evolves the model from passive observation to active robotic control. The training process is structured into three progressive stages. The initial stage focuses on physical pretraining using massive web-scale video datasets to internalize general spatial-temporal dynamics and physical laws. The curriculum then transitions to human-centric behavior alignment, where the model learns task-structured semantics and causal consequences from human demonstrations. Finally, the joint world-action training stage anchors the learned priors into robot-specific interaction data, co-optimizing the video and action components to bridge perception and actuation.
During the optimization phase, the model utilizes Flow Matching as the primary objective, learning a continuous-time conditional velocity field that transports samples from Gaussian noise to the data distribution in latent space. The training loss is defined as the mean squared error between the predicted velocity and the ground-truth velocity:
LFM(θ)=Ez0,ϵ,σ,c[∥Vθ(zσ,σ,c)−uσ∥22].To handle varying video lengths and resolutions, a shape-aware exponential timestep shifting strategy is applied to the scheduler, dynamically reallocating steps toward trajectory regions sensitive to prediction error. The joint optimization encourages the model to learn a shared world-action representation, implicitly aligning environmental transitions with robot decision-making while enabling efficient action-only inference at deployment time. Qualitative generation results demonstrate the model's capability:
Experiment
The evaluation assesses Kairos-4B across hardware efficiency tests, embodied and general world modeling benchmarks, action planning tasks, and long-horizon generation to validate its computational scalability, physical reasoning, and policy planning capabilities. Hardware and latency analyses demonstrate that the model achieves linear performance scaling and real-time generation on diverse GPUs while significantly outperforming larger competitors in memory and computational efficiency. Comprehensive benchmarking combined with human evaluations confirms that Kairos-4B delivers state-of-the-art physical plausibility, instruction adherence, and task completion in both robotic and general video synthesis despite its compact parameter scale. Additionally, ablation studies and extended-duration experiments verify that human-centric pretraining, joint generation-prediction optimization, and stable temporal scaling collectively enable robust, physically consistent world modeling and reliable long-horizon planning.
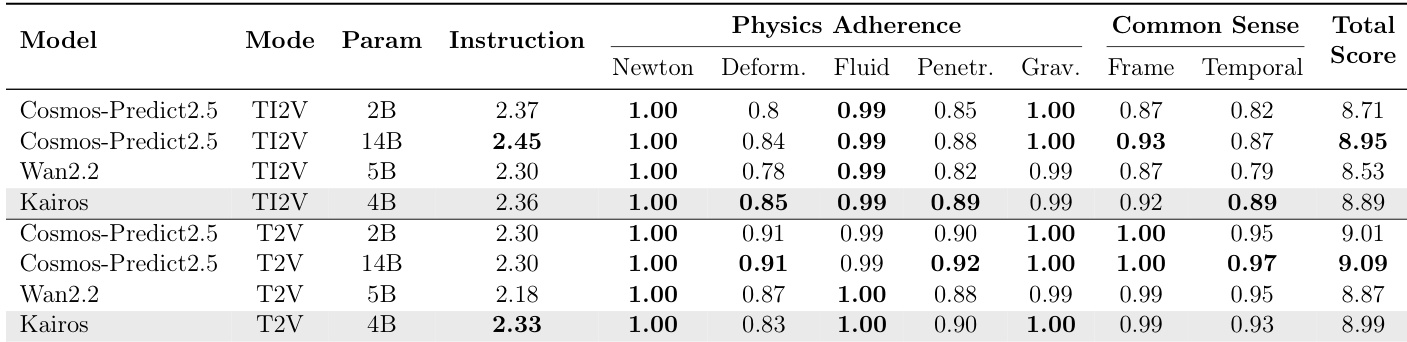
The authors evaluate the Kairos model on the WorldModelBench benchmark, comparing it against baseline models in both text-to-video and image-to-video modes. The results indicate that Kairos delivers competitive performance, often surpassing models with similar parameter counts while demonstrating strong instruction following and physics adherence. Additionally, the model exhibits robust common sense reasoning, particularly in temporal consistency. Kairos achieves competitive total scores in both image-to-video and text-to-video modes, outperforming models of similar scale. The model demonstrates strong instruction following and physics adherence, maintaining high scores across various physical categories. Kairos exhibits robust common sense reasoning, particularly in temporal consistency metrics compared to baseline competitors.
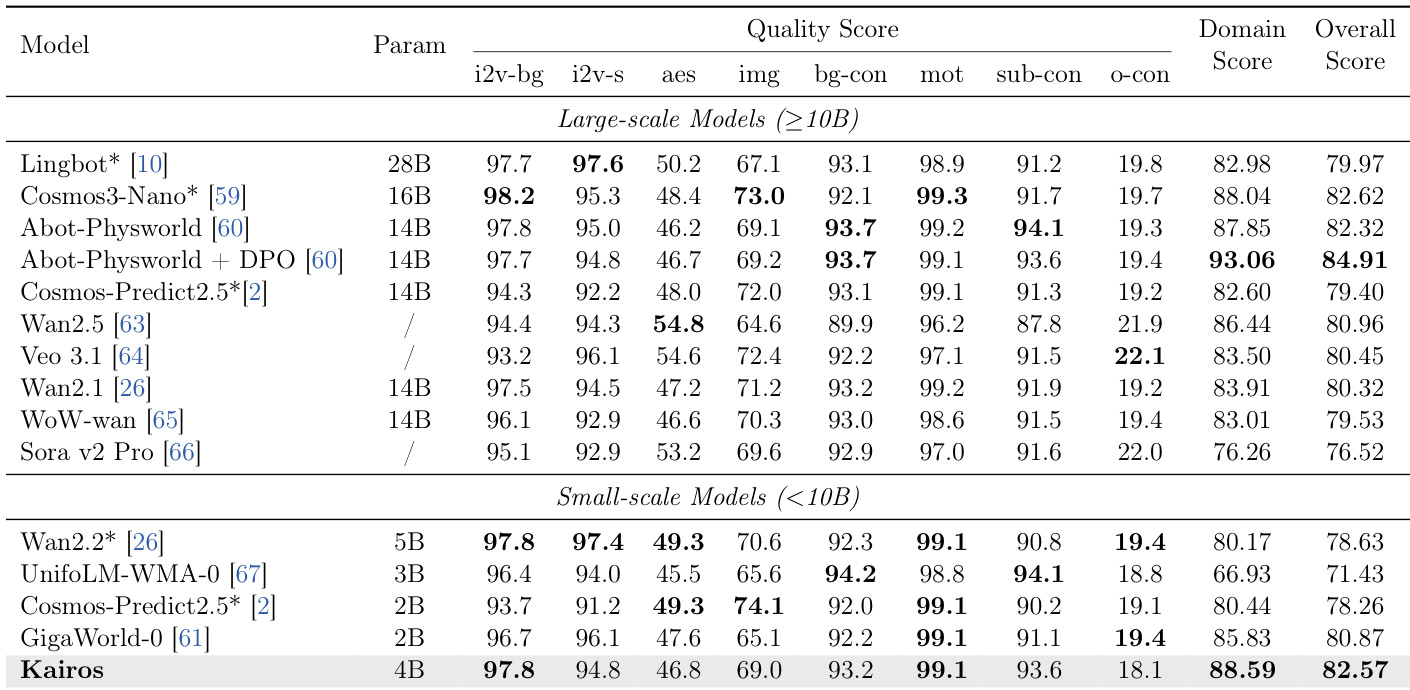
The authors evaluate the Kairos-4B model against various baselines, demonstrating that it achieves the best performance among small-scale models in both domain and overall quality scores. The results indicate that Kairos is highly competitive with larger models, particularly in maintaining visual consistency and generating high-quality videos across diverse domains. Kairos ranks first among small-scale models in Domain Score and Overall Score. The model achieves the highest subject and background consistency scores within its parameter range. Kairos demonstrates strong motion consistency, matching the top performance of other small-scale models.
The ablation study on embodied human-centric pretraining indicates that utilizing human-centric data significantly enhances the model's performance on the LIBERO-Plus benchmark. The results show a clear advantage when human-centric data is included in the training process, leading to a higher average score. This confirms the effectiveness of human-centric pretraining for embodied tasks. Incorporating human-centric pretraining data leads to a substantial improvement in the average benchmark score. The model trained with human-centric data outperforms the baseline model that lacks this data. The experimental results validate the effectiveness of human-centric data in boosting performance on embodied tasks.

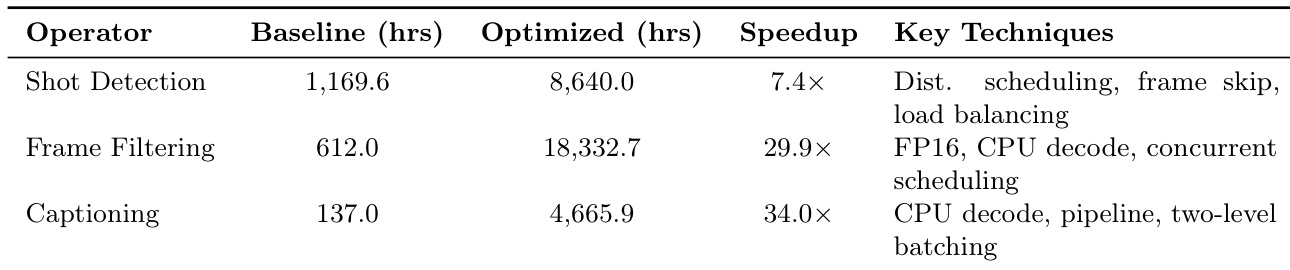
The authors evaluate the efficiency of an optimized video processing pipeline against a baseline across three core operators: shot detection, frame filtering, and captioning. Results demonstrate that the optimized approach yields substantial speedups for all tasks, leveraging advanced scheduling and decoding strategies to significantly improve processing performance. The optimized pipeline achieves notable speedups across shot detection, frame filtering, and captioning tasks. Key efficiency gains are driven by techniques such as distributed scheduling, frame skipping, and concurrent processing. Frame filtering and captioning exhibit the most pronounced performance improvements relative to the baseline.
The authors evaluate the physical reasoning capabilities of Kairos against several baseline models on the VideoPhy benchmark. The results indicate that Kairos achieves the highest average score, surpassing both smaller and significantly larger competitor models. This demonstrates the model's high parameter efficiency and ability to generate videos that adhere to real-world physical laws. Kairos achieves the highest average score on the VideoPhy benchmark among the evaluated models. The model outperforms the significantly larger Cosmos-Predict2.5-14B despite having fewer parameters. Kairos demonstrates superior physical reasoning and semantic adherence compared to Wan2.2-5B and Cosmos-Predict2.5-2B.

The evaluation assesses the Kairos model across text-to-video, image-to-video, and physical reasoning benchmarks, validating its superior instruction following, temporal consistency, and adherence to real-world physics compared to both similarly sized and larger baselines. An ablation study on embodied tasks confirms that human-centric pretraining substantially enhances model performance in this domain. Furthermore, an optimized video processing pipeline is tested against standard approaches, demonstrating significant computational speedups across shot detection, frame filtering, and captioning through advanced scheduling and concurrent execution. Collectively, these experiments establish Kairos as a highly parameter-efficient generative model while validating the effectiveness of targeted pretraining and pipeline optimization.