Command Palette
Search for a command to run...
Guava : Un harnais efficace et universel pour la manipulation incarnée
Guava : Un harnais efficace et universel pour la manipulation incarnée
Haowen Liu Xirui Li Shaoxiong Yao Peng Shi Tianyi Zhou Jia-Bin Huang Furong Huang Jiayuan Mao
Résumé
Les modèles de langage entraînés sur des données vision-langue à grande échelle ont démontré un fort potentiel pour les agents incarnés. Le pilotage des modèles par l'utilisation d'outils incarnés offre une alternative prometteuse aux systèmes vision-langue-action de bout en bout, en combinant un raisonnement de haut niveau avec des modules externes pour la perception, la planification et le contrôle. Cependant, il reste à déterminer ce qui constitue un harnais efficace pour la manipulation incarnée, et dans quelle mesure un tel harnais peut débloquer des capacités incarnées dans une large gamme de modèles de raisonnement. Dans ce travail, nous présentons Guava, un cadre de harnais pour l'utilisation d'outils incarnés développé grâce à une exploration systématique de l'espace de conception des workflows d'agents, des espaces d'action et des espaces d'observation. Notre étude identifie trois ingrédients clés pour des agents incarnés efficaces : des boucles perception-raisonnement-action itératives, des abstractions sémantiques d'action et des observations multimodales. Afin de comprendre si ces principes de conception sont universels, même pour les petits modèles, nous développons un pipeline d'entraînement de bout en bout qui distille les capacités de manipulation incarnée dans un modèle open-source de 4B, en utilisant moins de 2K trajectoires collectées entièrement en simulation. Les résultats expérimentaux, tant en simulation que dans des environnements réels, montrent des performances comparables à celles des modèles propriétaires de pointe, tout en présentant une forte capacité de généralisation à des objets non vus, des instructions nouvelles et des tâches à long horizon. Ces résultats suggèrent qu'un harnais bien conçu peut servir d'interface évolutive et indépendante du modèle pour la manipulation incarnée, permettant le développement de fortes capacités incarnées émergentes dans des modèles open-source compacts nécessitant un minimum de données d'entraînement.
One-sentence Summary
Guava is a harness framework for embodied manipulation that leverages iterative perception-reasoning-action loops, semantic action abstractions, and multimodal observations to distill capabilities into a 4B open-source model using fewer than 2K simulation trajectories, achieving performance comparable to frontier proprietary models with strong generalization to unseen objects, novel instructions, and long-horizon tasks across both simulation and real-world environments.
Key Contributions
- This work introduces Guava, a modular harness framework for embodied tool use that systematically explores agent workflows, action spaces, and observation spaces to bridge high-level reasoning with external perception and control modules.
- The study identifies three core design principles for effective manipulation: iterative perception-reasoning-action loops, semantic action abstractions, and multimodal observations, which enable explicit plan inspection and continuous failure recovery.
- A data-efficient training pipeline distills these capabilities into a 4B open-source model using fewer than 2,000 simulation trajectories, achieving performance comparable to frontier proprietary models while generalizing to unseen objects, novel instructions, and long-horizon tasks in both simulation and real-world environments.
Introduction
Large vision-language models offer a promising foundation for embodied manipulation, yet end-to-end vision-language-action policies face significant hurdles regarding data efficiency and scalability across diverse environments. Existing harness-based methods often depend on one-shot program generation or specialized pipelines, which restricts robust long-horizon planning and failure recovery while requiring costly frontier models. The authors leverage these observations to develop Guava, a universal harness framework that optimizes embodied tool use through iterative perception-reasoning-action loops, semantic action abstractions, and multimodal observations. By integrating this architecture with a data-efficient training pipeline, they show that compact open-source models can match frontier performance, demonstrating strong generalization and real-world transfer using fewer than 2,000 simulation trajectories.
Dataset
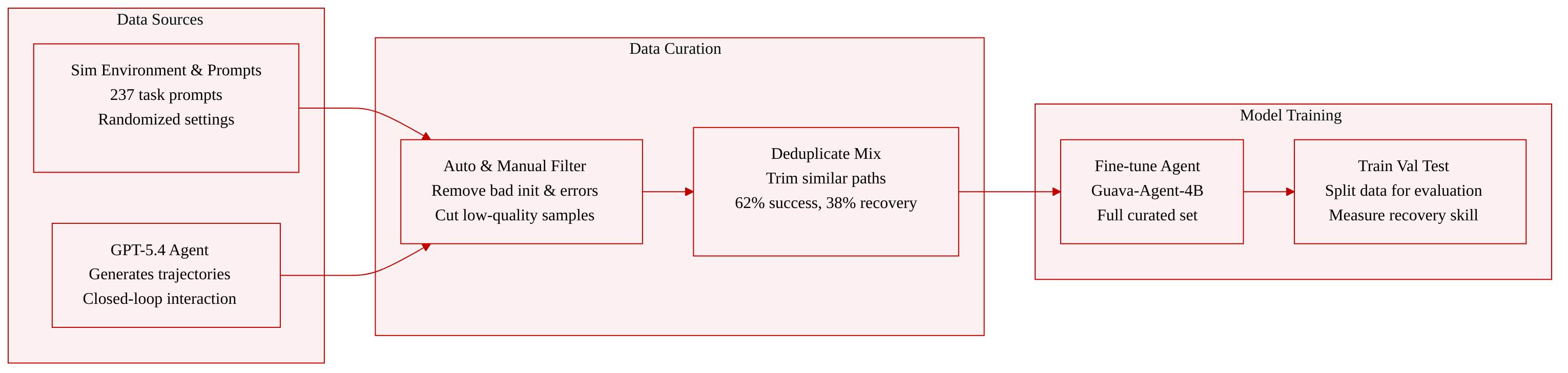
-
Dataset Composition and Sources: The authors construct the dataset by deploying the Guava harness framework with GPT-5.4 in the RoboSuite simulation environment. A standardized API enables closed loop interaction by exposing scene observations, action execution, and episode level feedback to the model.
-
Subset Details:
- Success Trajectories: Account for 1,191 episodes (62 percent of the dataset) generated from 237 unique task prompts. The authors randomize environmental parameters like pose, lighting, and camera views during generation to boost diversity.
- Recovery Trajectories: Comprise the remaining 743 episodes (38 percent). These are created by injecting predefined simulation errors such as missed grasps, dropped objects, or misalignments into successful rollouts, or by sampling random intermediate states to force the model to recover.
-
Data Usage and Mixture Ratios: The authors fine-tune Guava-Agent-4B using the complete curated set. They structure the training mixture with a 62 percent success to 38 percent recovery ratio to balance baseline performance with error recovery capabilities.
-
Processing and Quality Control: The authors apply a multi-stage curation pipeline to ensure quality and reduce bias. Initial filtering automatically removes episodes with invalid tool parameters or poor simulation initialization. A manual review step eliminates low-quality samples containing unrelated dialogue or excessive self-reflection. Finally, the authors deduplicate highly similar trajectories to prevent overfitting to specific prompts or execution patterns and apply the same filtering rules to the recovery data.
Method
The authors introduce Guava, a harness framework that transforms embodied manipulation from an open-loop prediction problem into a grounded, closed-loop interaction process. This framework enables robust performance by integrating iterative reasoning, semantic action abstractions, and multimodal observations. The system operates through perception-reasoning-action loops where the model continuously updates its plan based on new observations, allowing it to recover from grasp failures and state deviations.

A critical component of the design is the semantic action space, which delegates low-level geometric and physical reasoning to lower-level controllers. Rather than outputting raw joint coordinates, the VLM issues task-oriented commands using a set of defined tools. These tools include high-level actions such as grasp(object) and release(), as well as positioning primitives like align(object, position, clearance). The align function accepts a position parameter from the set {top,left,right,front,back} and a clearance parameter from {small,medium,large}, allowing the agent to reason about object relationships without managing precise 3D coordinates directly. This abstraction significantly improves performance compared to low-level interfaces that require explicit geometric planning.
To transfer these embodied capabilities to a compact open-source model, the authors develop a data-efficient training pipeline that distills behaviors from frontier VLMs. This process begins with a data generation engine that collects interaction trajectories in a simulation environment. The engine leverages scene randomization and targeted error perturbations to generate diverse examples, including not only successful completions but also recovery trajectories where the model learns to correct execution failures.
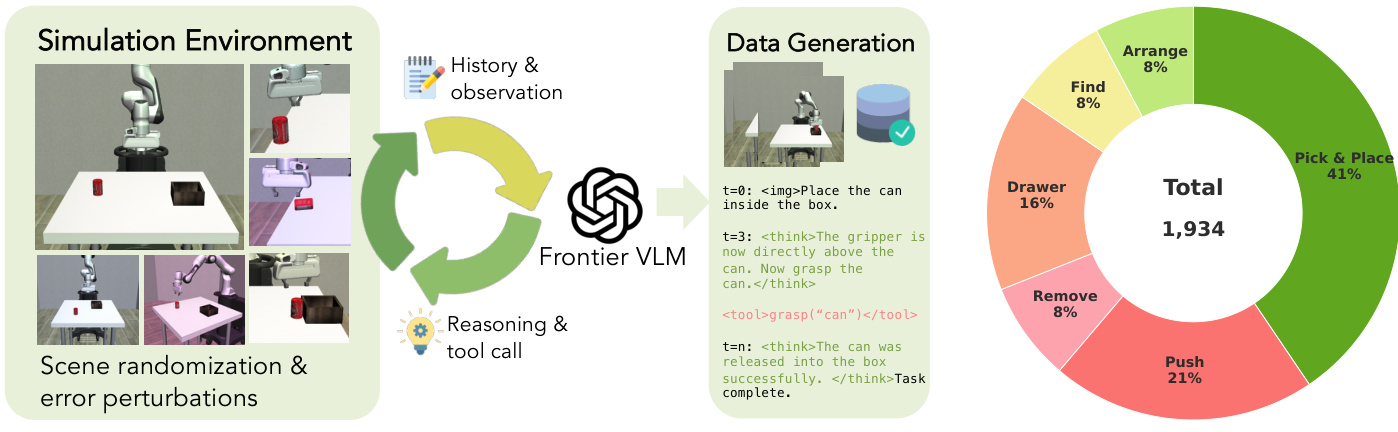
The training pipeline employs a two-stage approach to optimize the policy. First, supervised fine-tuning is performed on the collected dataset, which combines successful demonstrations with recovery scenarios to teach both manipulation skills and error correction. Following this, Group Relative Policy Optimization (GRPO) is applied using a sparse task-success reward. This reinforcement learning stage is strategically focused on the most challenging long-horizon tasks to improve sequential planning and adaptation without incurring excessive computational costs across simpler tasks.
Experiment
The evaluation setup tests a distilled 4B-parameter VLM across diverse in-distribution and out-of-distribution long-horizon manipulation tasks in both Robosuite simulation and a physical Franka robot arm. The experimental program validates that this compact model matches frontier proprietary systems in real-world deployment, demonstrating that embodied tool-use behaviors can be effectively transferred from minimal simulation data. Further ablations confirm that reinforcement learning post-training and continuous closed-loop execution are critical for robust long-horizon reasoning, error recovery, and emergent state awareness, while also exposing persistent limitations in precise spatial understanding. Overall, the results conclude that agentic planning successfully bridges simulation and reality by decoupling high-level semantic reasoning from low-level control.
The chart compares the token consumption per episode between GPT-5.4 and Guava-Agent-4B across a variety of manipulation tasks. Guava-Agent-4B generally requires fewer tokens to complete tasks than the GPT-5.4 baseline, with the difference being most significant in the overall average. This indicates that the compact model achieves comparable behaviors with substantially reduced computational overhead. Guava-Agent-4B utilizes fewer tokens per episode than GPT-5.4 in the majority of individual tasks. The overall token efficiency of Guava-Agent-4B is substantially higher than that of the GPT-5.4 model. The efficiency gap persists across diverse task complexities, despite minor variations in specific long-horizon scenarios.

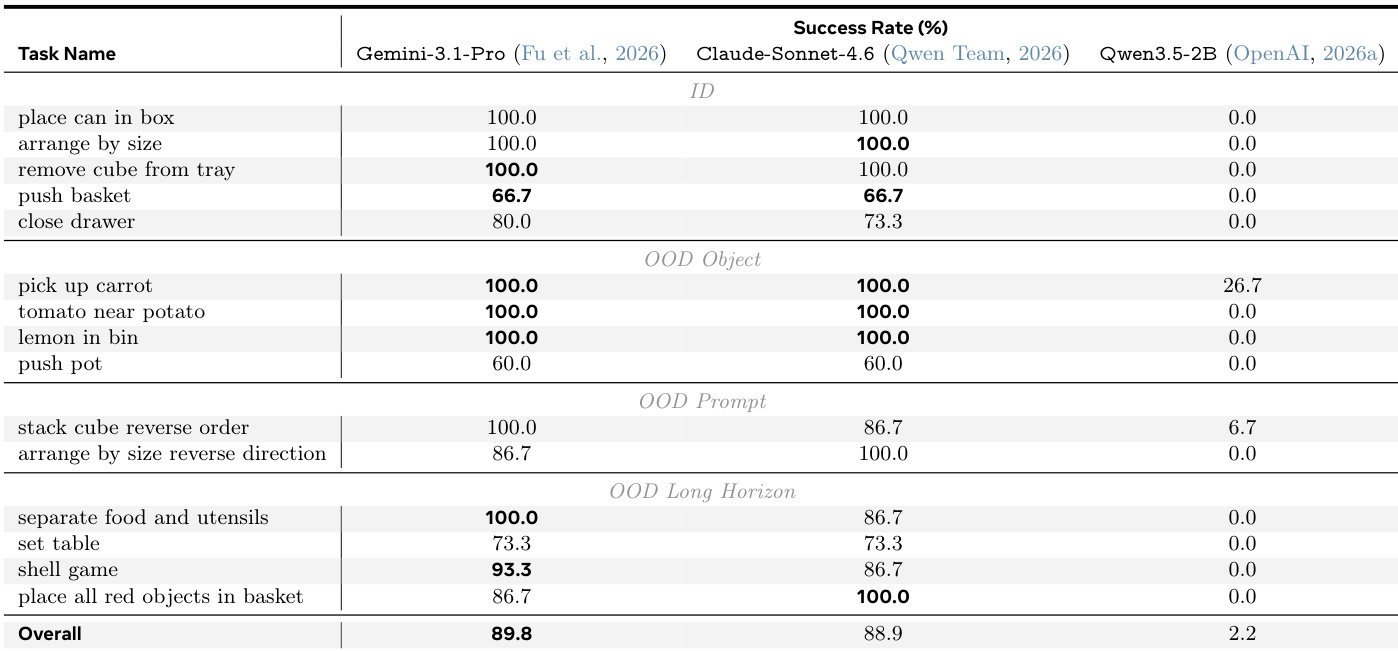
The experiment evaluates the Guava harness with different base models across various manipulation tasks. The results indicate that larger frontier models maintain high success rates across in-distribution and out-of-distribution scenarios, while the smaller model exhibits poor performance due to issues with instruction following and tool calling. Larger frontier models demonstrate robust capability in handling diverse task categories, including complex long-horizon sequences. The smaller model consistently fails across all task types, highlighting limitations in instruction following and tool selection. Gemini-3.1-Pro generally achieves the highest overall success rate compared to the other evaluated models.
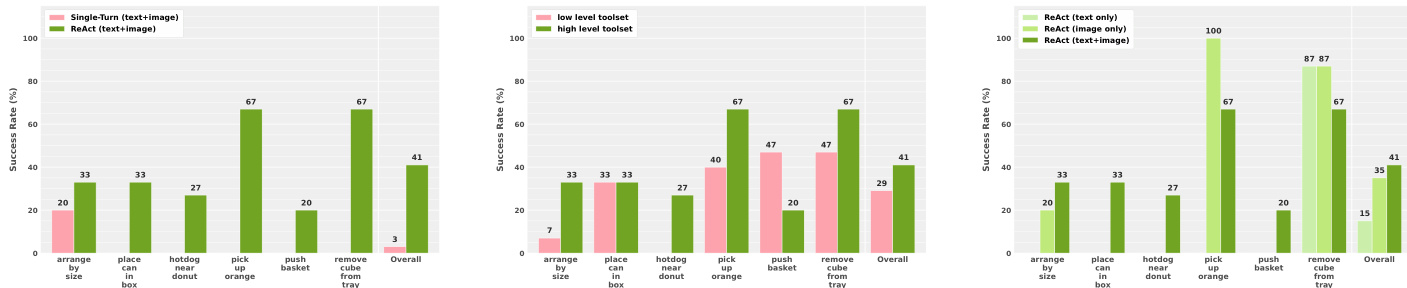
The experiments evaluate the Guava framework for embodied manipulation, demonstrating that closed-loop ReAct planning significantly outperforms single-turn approaches. High-level toolsets generally improve performance on complex tasks like picking up objects, while low-level tools are more effective for specific actions such as pushing. Furthermore, visual input is critical, with image-only inputs achieving superior results on certain spatial tasks compared to multimodal text-and-image inputs. Closed-loop ReAct execution significantly outperforms single-turn planning in overall success rates. High-level toolsets enhance performance on tasks like picking up oranges and removing cubes, while low-level tools are better for pushing. Image-only inputs achieve superior performance on specific spatial tasks compared to multimodal text-and-image inputs.
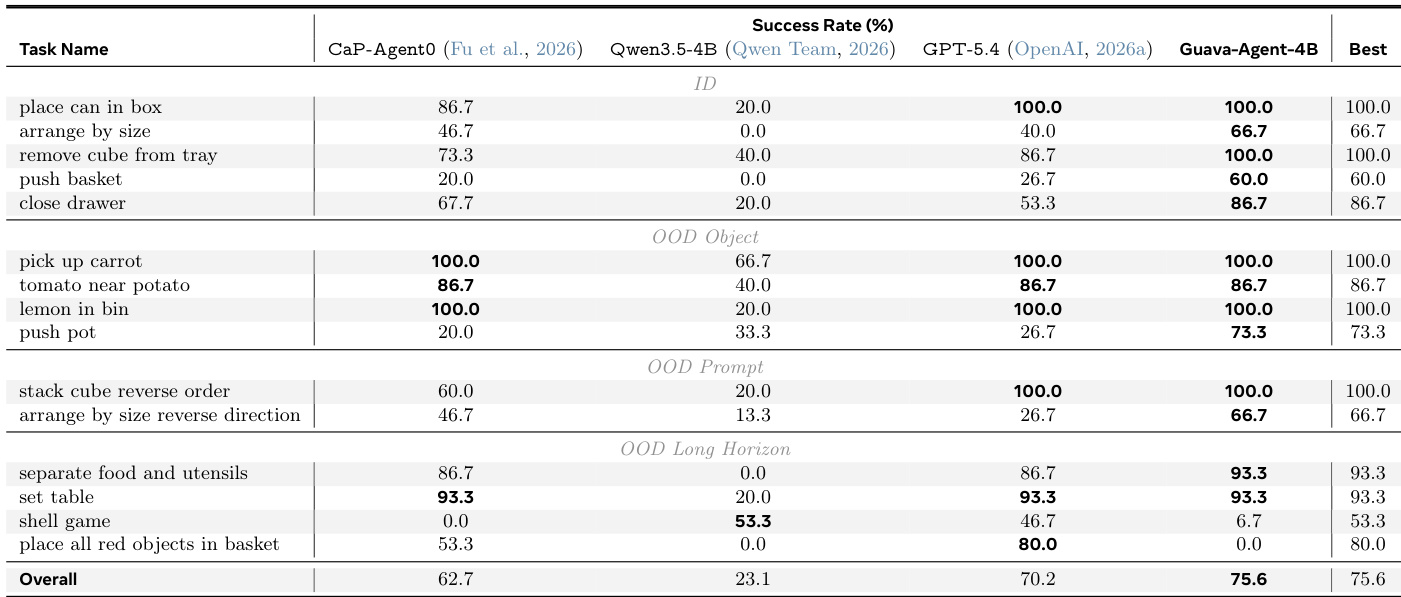
The experiment evaluates Guava-Agent-4B against several baselines across a suite of embodied manipulation tasks. Results indicate that Guava-Agent-4B achieves the highest overall success rate, generally outperforming the proprietary GPT-5.4 model and the concurrent CaP-Agent0. The base Qwen3.5-4B model shows significantly lower performance, underscoring the effectiveness of the proposed distillation harness. Guava-Agent-4B demonstrates superior overall performance compared to both proprietary and open-source baselines across various task categories. The model effectively generalizes to out-of-distribution scenarios, maintaining high success rates on tasks involving unseen objects and novel instructions. Significant performance gaps are observed between the trained Guava-Agent-4B and the untrained base Qwen3.5-4B model, highlighting the impact of the training process.
The experiments evaluate the Guava framework and its distilled agent across diverse embodied manipulation tasks, validating the effectiveness of the training harness, planning architecture, tool selection strategies, and computational efficiency. Qualitative assessments demonstrate that closed-loop ReAct planning consistently outperforms single-turn approaches, while specialized high- and low-level toolsets effectively optimize complex object manipulation and precise physical interactions. Additionally, the distilled model achieves robust generalization to unseen scenarios and substantially reduces computational overhead compared to larger proprietary baselines, with image-only inputs proving highly effective for spatial reasoning. Overall, the findings confirm that the proposed framework enables compact models to deliver superior task success and efficiency without relying on massive frontier architectures.