Command Palette
Search for a command to run...
S-Agent: Räumliche Werkzeugnutzung fördert das Schlussfolgern für räumliche Intelligenz
S-Agent: Räumliche Werkzeugnutzung fördert das Schlussfolgern für räumliche Intelligenz
Zusammenfassung
Räumliche Intelligenz in der realen Welt erfordert das Schließen über eine kontinuierliche und sich entwickelnde 3D-Welt, doch bestehende VLMs und tool-augmentierte agents bleiben weitgehend an eine statische, zustandslose Inferenz aus isolierten visuellen Beobachtungen gebunden. Wir stellen \textsc{S-Agent} vor, ein agentices Paradigma für den räumlichen Werkzeuggebrauch zum Verständnis und Schließen über kontinuierliche Mehransichtsbilder und -videos. Durch die Formulierung räumlichen Schließens als räumlich-zeitliche Evidenzakkumulation anstelle isolierter Vorhersagen auf Frame-Ebene formiert S-Agent die räumliche Wahrnehmung in ein szenenzentriertes Verständnis um, das über die rein framezentrierte Erkennung hinausgeht. Insbesondere fungiert das VLM innerhalb von S-Agent als semantischer Planer, der entscheidet, welche Evidenz benötigt wird, während eine Hierarchie räumlicher Werkzeuge und Experten Objekte in 2D verankert, sie in 3D-geometrische Evidenz überführt und diese zu hochrangigem räumlichem Wissen aggregiert (z. B. Zählen, Messen, Orientierung und relative Position). Darüber hinaus ermöglicht ein zeitlicher Gedächtnismechanismus, der das Scene Memory zur Aufrechterhaltung des sich wandelnden Szenenzustands sowie das Agent Memory zur Akkumulation des Schließungskontexts umfasst, die Integration von Evidenz über Frames und Schließungsschritte hinweg. Umfassende Experimente auf Benchmarks für räumliches Schließen mit Mehransichten und Videos zeigen, dass S-Agent sowohl Open-Source- als auch Closed-Source-VLMs konsistent und ohne Trainingsaufwand verbessert. Über die Augmentierung während der Inferenzzeit hinaus führt das supervised fine-tuning (SFT) auf den von S-Agent generierten räumlichen Trajektorien S-300K zu S-Agent-8B, einem kompakten räumlichen agent, der ähnliche Baselines (z. B. Qwen3-VL-8B) deutlich übertrifft und sich in der Leistung mit fortschrittlichen Closed-Source-Modellen (z. B. GPT-5.4 und Gemini 3) messen kann.
One-sentence Summary
S-AGENT introduces a spatial tool-use paradigm that advances vision-language models beyond static frame-level inference by treating spatial reasoning as spatio-temporal evidence accumulation, employing a semantic planner, hierarchical geometric tools, and dual memory mechanisms to dynamically aggregate cross-frame data and achieve training-free performance gains on multi-view and video spatial reasoning benchmarks.
Key Contributions
- S-AGENT reformulates spatial perception as spatio-temporal evidence accumulation rather than isolated frame-level prediction by employing a vision-language model as a semantic planner. This framework orchestrates a hierarchy of spatial tools to ground 2D objects, extract 3D geometric cues, and synthesize high-level spatial knowledge.
- A dual memory architecture comprising Scene Memory and Agent Memory maintains evolving scene states and accumulates intermediate reasoning traces across frames and tool iterations. This stateful design explicitly links fragmented multi-view observations into a temporally grounded three-dimensional representation for continuous reasoning.
- Comprehensive evaluations on MMSI-Bench, ViewSpatial-Bench, ReVSI, and VSI-SUPER demonstrate that the training-free framework consistently improves both open-source and closed-source vision-language models. Fine-tuning the architecture on a curated spatial-instruction dataset yields a 10.5% accuracy gain on MMSI-Bench and matches the performance of advanced proprietary models across multiple benchmarks.
Introduction
Real-world spatial intelligence requires models to navigate dynamic 3D environments, a capability essential for embodied robotics, autonomous driving, and extended reality applications. Current vision-language models, however, are trained on passive 2D corpora and struggle to bridge the semantic-to-geometric gap, often relying on lossy representations that fail to capture precise spatial relationships. Even recent tool-augmented agents remain constrained by static, stateless inference on isolated frames, which prevents them from maintaining persistent object states or integrating visual evidence across multiple viewpoints and time. To overcome these limitations, the authors introduce S-AGENT, a spatial tool-use paradigm that reframes reasoning as continuous spatio-temporal evidence accumulation. The authors leverage a vision-language model as a semantic planner that orchestrates a hierarchy of spatial tools to ground objects in 2D, reconstruct 3D geometry, and extract high-level spatial relationships. Supported by a dual-memory system that tracks evolving scene states and reasoning history, this architecture enables persistent, stateful understanding of video and multi-view data. The framework consistently enhances zero-shot performance across existing models and yields a compact fine-tuned variant that matches the capabilities of leading closed-source systems.
Dataset

- Dataset Composition and Sources: The authors construct the S-300K dataset by sourcing initial prompts from SenseNova-SI-800K and selecting queries that challenge a weaker student model while naturally requiring tool use.
- Key Subset Details and Filtering Rules: The final corpus contains 300K trajectories. The authors estimate sample difficulty through multiple rollouts of Qwen3-VL-8B and prioritize uncertain or unstable cases. During export, they retain only trajectories with valid executions and correct final answers, applying answer-type-specific criteria such as exact option matching for multiple choice, mean relative accuracy for numeric questions, and normalized matching for text responses. Tool invocation is deliberately excluded as a hard filtering rule.
- Data Processing and Decomposition: Instead of treating rollouts as single examples, the authors decompose each retained trajectory into three distinct supervision formats. They generate end to end final answer sequences for spatial reasoning, turn level sequences to teach iterative tool use decisions under partial context, and expert level sequences to refine tool use policy. All raw agent traces are preserved independently for analysis.
- Model Usage and Training Strategy: The authors use this multi granularity dataset exclusively for supervised fine tuning Qwen3-VL-8B. By feeding the decomposed trajectories into the training loop, they enable the compact student model to learn how to request evidence, interpret tool observations, and accumulate spatial knowledge across reasoning steps, ultimately producing the S-AGENT-8B model.
Method
The authors introduce S-AGENT, a spatial tool-use agentic framework designed to handle spatial reasoning over continuous multi-view images and videos. Rather than treating spatial reasoning as a single-shot prediction from isolated visual inputs, the system formulates it as a process of spatio-temporal evidence accumulation. The architecture leverages a large vision-language model (VLM) as a semantic planner, which actively acquires hierarchical spatial evidence through specialized tools while maintaining scene and agent memories for stateful reasoning. As illustrated in the framework overview, the system addresses the limitations of current spatial VLMs by explicitly modeling stateful spatial evidence from space and time, moving beyond single-shot predictions and limited tool use.
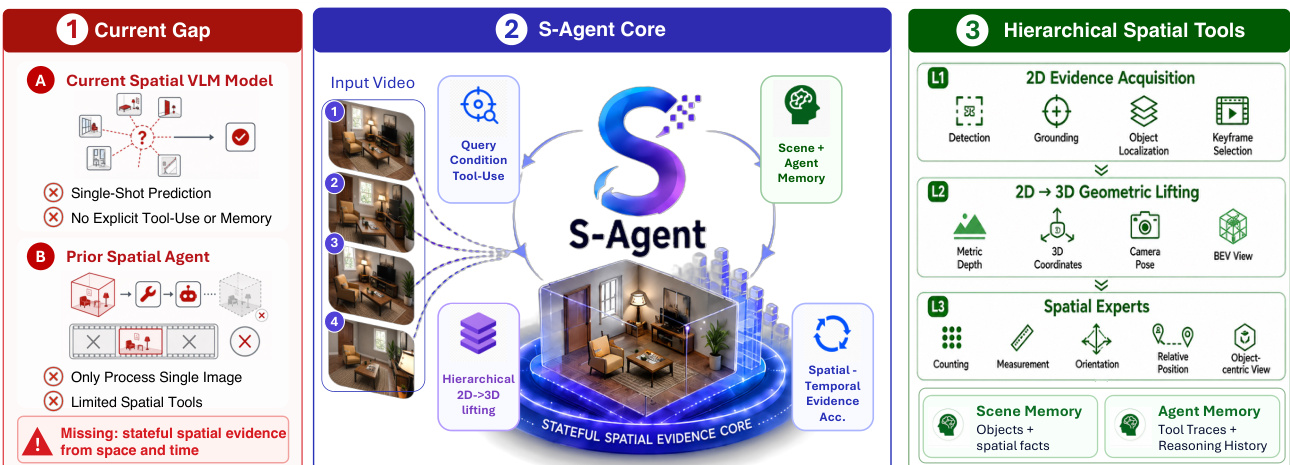
The core inference process is iterative. At each reasoning step t, the VLM planner receives a question q and a sequence of visual observations F. It maintains two memory states: a scene memory state St for grounded spatial evidence and an agent memory state Ht for reasoning history. The planner generates an evidence request rt conditioned on the question, observations, and current memory states:
rt=πθ(q,F,St,Ht)
A spatial tool or expert at level k executes this request, producing an observation ot:
ot=T(k)(rt,F,St)
This observation is decomposed into reusable scene evidence et and process context ct, which update the memories:
St+1=Merge(St,et),Ht+1=Append(Ht,ct)
The detailed pipeline of this interaction, including the planner, hierarchical evidence levels, and persistent memory structures, is shown below.
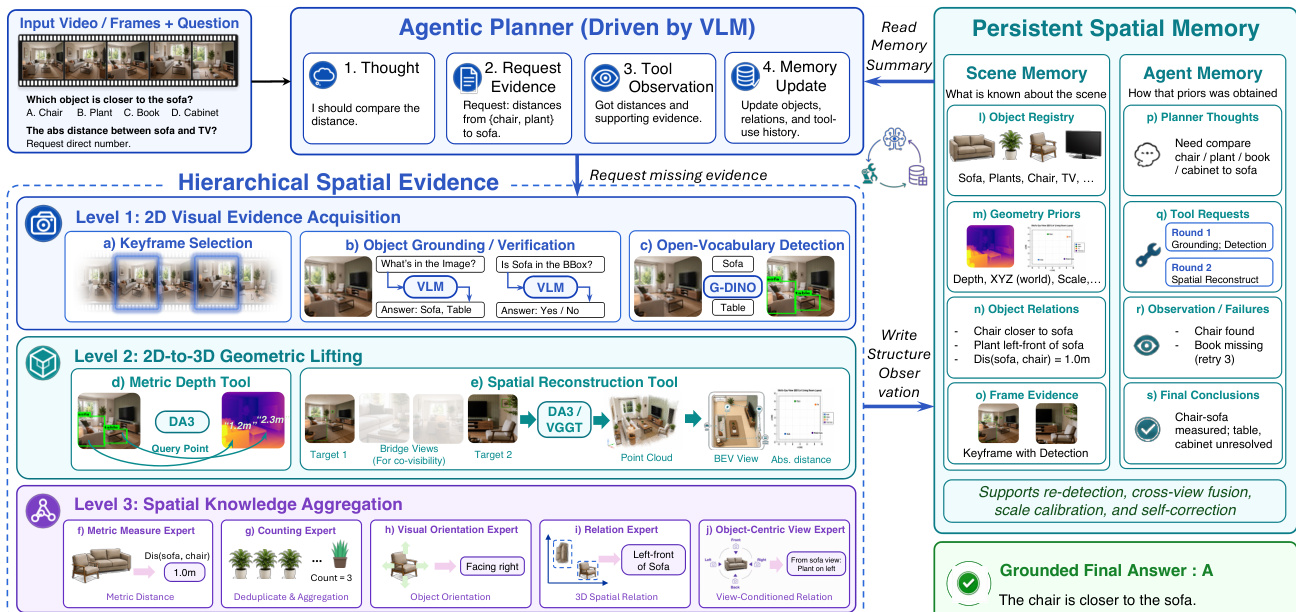
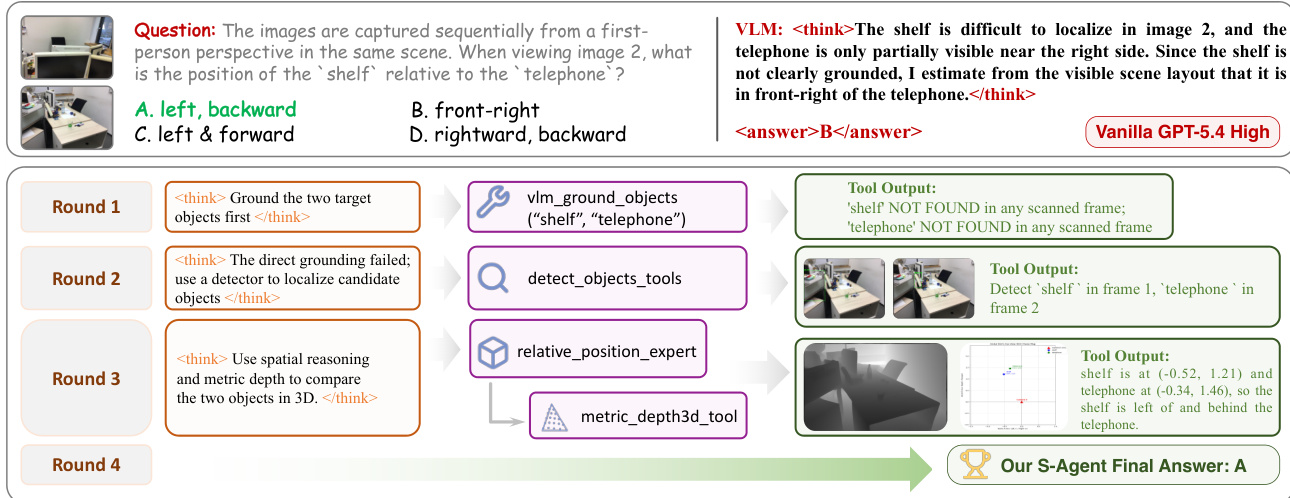
S-AGENT acquires evidence through a three-level hierarchy that transforms raw 2D observations into explicit spatial knowledge. Level 1 involves 2D visual evidence acquisition, where the system selects informative frames, grounds referred entities, and localizes candidate regions using open-vocabulary detectors. Level 2 performs 2D-to-3D geometric lifting, utilizing tools to recover scene-level 3D information such as depth structure, metric coordinates, and camera poses. This allows the agent to compare fragmented 2D observations in a shared spatial context. Level 3 aggregates spatial knowledge using specialized experts for counting, relative direction, and metric measurement. The iterative nature of this process is evident in the reasoning trace, where the planner adapts its strategy across rounds based on tool feedback, such as switching from direct grounding to detection when initial attempts fail.
The framework maintains two complementary memories to support stateful reasoning. Scene Memory consolidates reusable scene evidence by binding repeated observations to persistent scene entities and accumulating their visual and geometric attributes. This prevents duplicated evidence and stabilizes object identity across different views and frames. Agent Memory preserves the reasoning trajectory, recording intermediate thoughts, tool calls, and failure messages. This procedural context allows the planner to identify missing evidence and avoid redundant actions. The system's ability to execute complex spatial tasks is demonstrated through examples of absolute distance measurement and object size estimation, where the agent selects keyframes, estimates initial metrics, locates objects, and performs 3D measurements to derive the final answer.

Experiment
Evaluated across four spatial reasoning benchmarks covering multi-image, video, and perspective-aware tasks, the experiments validate S-AGENT’s capacity to systematically ground visual evidence and integrate cross-view information in both zero-shot and distilled training regimes. Zero-shot evaluations demonstrate that the framework consistently surpasses strong proprietary and specialized baselines by dynamically invoking specialized tools and memory modules to reconstruct metric spatial layouts. Ablation studies validate that structured evidence hierarchies and expert-mediated 3D interpretation are essential for filtering noisy geometric data, while qualitative analyses reveal that this tool-grounded approach successfully resolves occlusions and ambiguous cues that typically defeat standard vision-language models. Ultimately, trajectory distillation experiments confirm that these advanced reasoning capabilities can be effectively transferred to compact models, establishing a robust and scalable paradigm for spatial understanding.
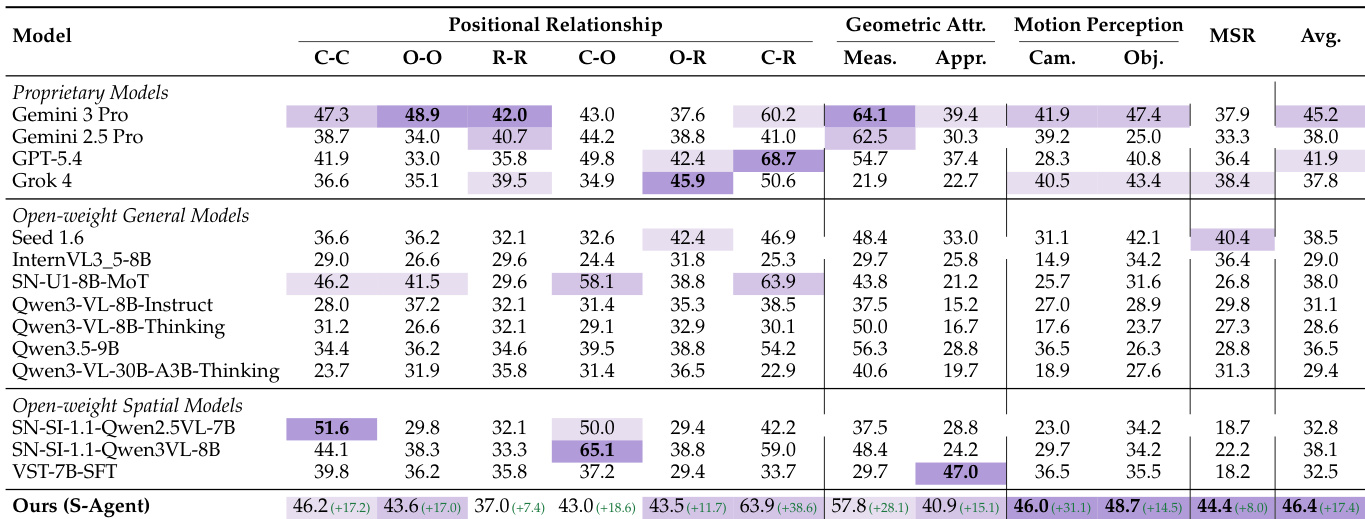
Results show that the S-AGENT model achieves the highest overall average score on the MMSI-Bench, outperforming leading proprietary models and open-weight baselines. The system demonstrates exceptional capability in dynamic spatial reasoning, securing top results in motion perception and multi-step reasoning. Additionally, it leads in specific camera-region positional relationships while maintaining robust performance in geometric attribute evaluation. S-AGENT achieves the highest overall average score, surpassing proprietary models like Gemini 3 Pro and GPT-5.4. The model leads in motion perception and multi-step reasoning categories. It secures top performance in camera-region positional relationships while remaining competitive in geometric measurement.
The authors evaluate S-AGENT on the ReVSI benchmark to assess spatial reasoning capabilities across numerical and multiple-choice tasks. S-AGENT achieves the highest average performance among open-source general and spatially specialized models. It demonstrates particular strength in multiple-choice tasks that require integrating evidence across frames, specifically excelling in relative direction and route planning. S-AGENT outperforms all open-source general and spatially specialized baselines on the benchmark. The model achieves the top results in relative direction and route planning categories. S-AGENT ranks second overall in average score, trailing only the strongest proprietary model.
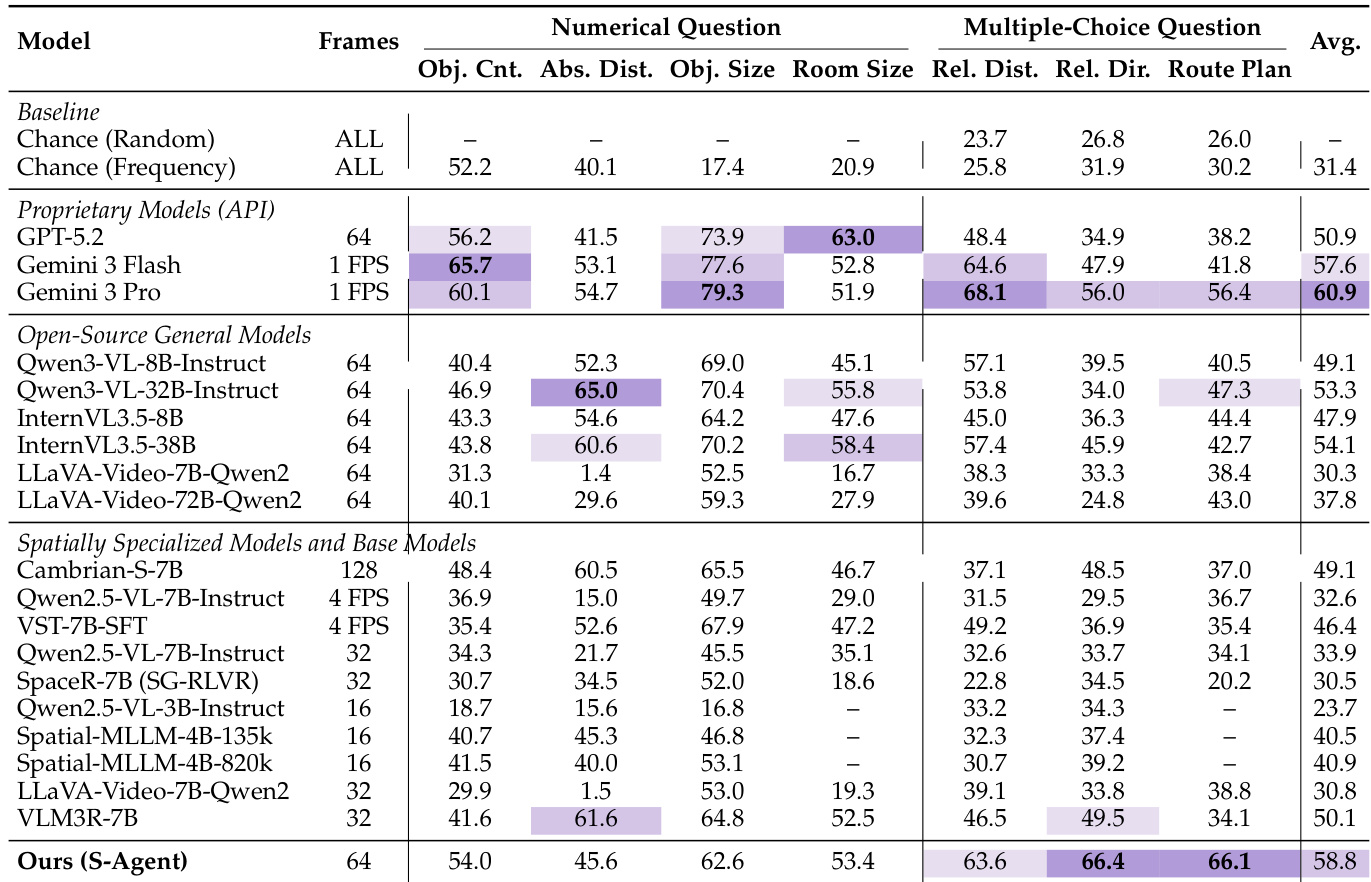
The authors evaluate S-AGENT on the ViewSpatial-Bench benchmark, comparing it against proprietary and open-weight models. Results show that S-AGENT achieves the highest average performance, significantly outperforming leading proprietary models like GPT-5.4. The model demonstrates superior capabilities in both camera-centered and person-centered spatial reasoning tasks. S-AGENT achieves the top average score on ViewSpatial-Bench, surpassing proprietary baselines. The model shows strong performance in camera-perspective object view orientation and person-perspective relative direction. S-AGENT yields significant improvements on the challenging person-perspective scene-simulation relative direction task.
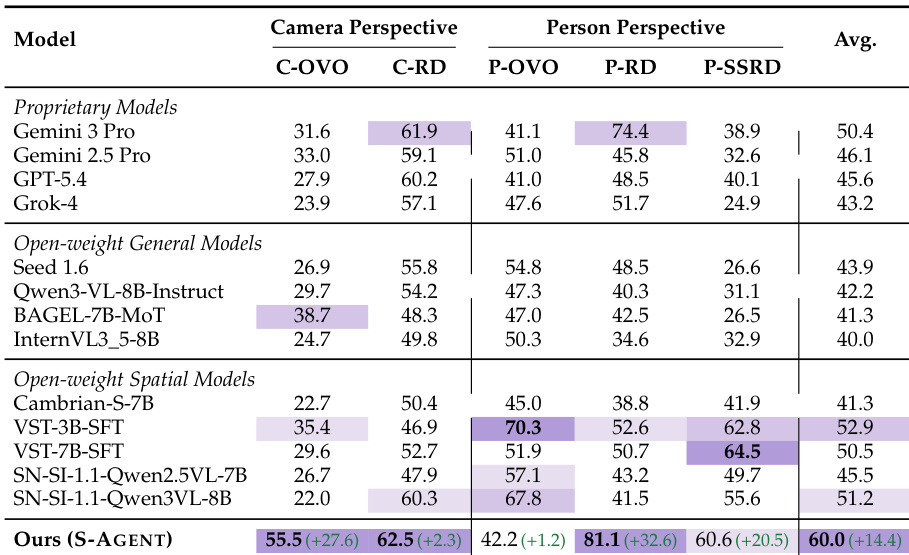
The authors perform ablation studies on the spatial evidence hierarchy and memory modules of S-AGENT. The results show that while basic 2D evidence provides a moderate improvement over a baseline, raw 3D evidence alone is less effective due to noise. In contrast, utilizing Level-3 3D experts significantly enhances performance, and integrating both scene and agent memory modules yields the best overall results. Utilizing Level-3 3D experts significantly enhances performance compared to raw 3D evidence, indicating the value of expert interpretation. Integrating both scene and agent memory modules yields the best overall results, outperforming the use of either module alone. Basic 2D evidence provides a moderate improvement over a baseline, whereas raw 3D data without expert filtering offers limited benefit.
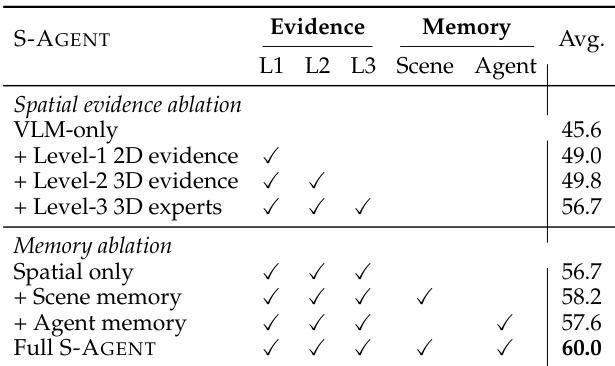
The authors evaluate the proposed S-Agent model on video spatial reasoning and change detection tasks across varying video durations, ranging from short clips to extended sequences. The results demonstrate that S-Agent maintains robust and high performance across all tested durations, significantly outperforming baselines like Cambrian-S-7B which fail on longer videos. Additionally, S-Agent is the only model capable of achieving non-zero performance on the change detection task for shorter durations, highlighting its superior capability in handling complex temporal changes. S-Agent sustains high accuracy on extended video sequences, whereas competing models show severe performance degradation or complete failure. The method significantly outperforms spatially specialized baselines like Cambrian-S-7B across all video lengths. S-Agent is the only model to achieve non-zero scores on video spatial change tasks for shorter durations, demonstrating unique temporal reasoning capabilities.
The S-AGENT model was evaluated across multiple spatial reasoning benchmarks, ablation studies on evidence hierarchies and memory modules, and video-based temporal reasoning tasks. Across these diverse evaluations, the system consistently outperformed proprietary and open-weight baselines, demonstrating exceptional proficiency in dynamic spatial inference, perspective-aware scene understanding, and cross-frame evidence integration. Ablation results indicate that expert-filtered 3D evidence and combined scene-agent memory modules are essential for peak performance, whereas raw 3D data introduces detrimental noise. Additionally, the model sustains robust accuracy across varying video durations and uniquely succeeds in short-duration temporal change detection, highlighting its superior capability in handling complex spatial and temporal dynamics.