Command Palette
Search for a command to run...
DreamX-World 1.0: Ein universell einsetzbares interaktives Weltmodell
DreamX-World 1.0: Ein universell einsetzbares interaktives Weltmodell
Zusammenfassung
DreamX-World 1.0 ist ein universelles, interaktives Text-/Bild-zu-Video-Weltmodell für die kontrollierbare Generierung über lange Zeithorizonte. Es unterstützt die Kameranavigation, das erneute Ansteuern zuvor beobachteter Regionen sowie promptbare Ereignisse in fotorealistischen, spielstilisierten und stilisierten Domänen. Unsere Data-Engine kombiniert Unreal-Engine-Rendering mit kameraexakter Geometrie, actionreiche Gameplay-Aufzeichnungen sowie Realweltvideos mit rekonstruierter Kamerageometrie. Für die Kamerasteuerung führen wir E-PRoPE ein, eine leichtgewichtige Variante der projektiven Positionsencodierung, die die projektive Kamerageometrie von PRoPE beibehält, während sie eine kameraabhängige Aufmerksamkeit auf räumlich reduzierte tokens anwendet. Wir wandeln einen bidirektionalen Video-Generator unter Verwendung von Causal Forcing, DMD-ähnlicher Distillation und Long-Rollout-Training in ein autoregressives Weltmodell mit wenigen Schritten um. Das Training auf selbstgenerierten Kontexten über lange Zeithorizonte setzt das Modell seiner eigenen generierten Historie aus und reduziert den Stil- und Farbdrift, der sich über autoregressive Chunks ansammelt. Memory-Conditioned Scene Persistence ruft frühere Ansichten durch eine Abfrage basierend auf der Kamerageometrie ab, während Residual Recycling den Bedingungspfad weniger empfindlich gegenüber unvollkommenen Memory-Latents macht. Event Instruction Tuning ermöglicht eine zusammensetzbare Ereignissteuerung, und Reinforcement-Learning-Alignment stellt nach der Distillation die Kamerasteuerung sowie die visuelle Qualität wieder her. Durch die Ausführung von DiT mit gemischter Präzision, die Wiederverwendung von Residuals, die VAE-Decodierung mit 75 % Pruning sowie asynchrone Pipeline-Parallelität erreicht DreamX-World 1.0 auf acht RTX 5090 GPUs bis zu 16 FPS. In unserer Basis-Evaluation über 5 Sekunden erzielt DreamX-World 1.0 einen Kamerasteuerungs-Score von 73,75 und einen Gesamtscore von 84,76 und übertrifft damit HY-WorldPlay 1.5 und LingBot-World im Gesamtscore, die jeweils 80,79 bzw. 80,45 erreichen.
One-sentence Summary
DreamX-World 1.0 is a general-purpose interactive world model for controllable long-horizon video generation that, through lightweight E-ProPE camera encoding, causal autoregressive distillation, memory-conditioned scene persistence, and event instruction tuning, achieves a camera-control score of 73.75 and an overall score of 84.76, outperforming HY-WorldPlay 1.5 (80.79) and LingBot-World (80.45), while running at up to 16 FPS on eight RTX 5090 GPUs.
Key Contributions
- A data engine integrates camera-accurate Unreal Engine rendering, action-rich gameplay recordings, and real-world videos with recovered camera geometry, while E-ProPE, a lightweight projective positional encoding, applies camera-aware attention to spatially reduced tokens for precise camera control.
- A bidirectional video generator is converted into a few-step autoregressive world model using causal forcing, DMD-style distillation, and long-rollout training on self-generated contexts to reduce style and color drift, and memory-conditioned scene persistence employs camera-geometry-based retrieval with residual recycling to maintain consistency across long horizons.
- Event Instruction Tuning adds composable event control, reinforcement learning alignment restores camera control and visual quality after distillation, and inference optimizations including mixed-precision DiT execution, residual reuse, 75%-pruned VAE decoding, and asynchronous pipeline parallelism achieve 16 FPS on eight RTX 5090 GPUs, yielding a camera-control score of 73.75 and an overall score of 84.76 that surpasses HY-WorldPlay 1.5 and LingBot-World.
Introduction
The authors introduce DreamX-World 1.0, a general-purpose interactive world model designed to generate and simulate dynamic 3D environments from multimodal control signals such as captions, camera movements, and events. Interactive world models are critical for embodied AI, game simulation, and content creation, but prior approaches suffer from limited long-horizon visual and geometric consistency, conflicts among control modalities, and a lack of reliable automatic evaluation. DreamX-World 1.0 tackles these challenges through a full-stack design that jointly addresses data curation, training, evaluation, and inference acceleration, achieving improved interaction, controllability, and efficiency while laying the groundwork for future character-centric and native audio-visual extensions.
Dataset
The dataset combines synthetic, real-world, and game videos to train interactive world models with reliable camera and action annotations. The authors unify these sources through a shared annotation, geometric processing, and quality-control pipeline.
Dataset composition and sources
- UE-generated data: A large portion of the training data is synthesized in Unreal Engine 5, providing controllable camera and agent motion with ground-truth annotations. It includes three observation modes: first-person (free camera exploration), third-person (camera follows a moving character), and event clips (object interactions and visible state changes).
- Real-world data: Videos are collected from SpatialVID, RealEstate10K, Sekai, and DL3DV. Camera poses are sparsely estimated on key frames with MegaSaM and then densified.
- Game data: Clips are sourced from Sekai-Game and OmniWorld-Game. Engine-exported poses are converted to the same camera coordinate system used for UE and real-world data.
Key details for each subset
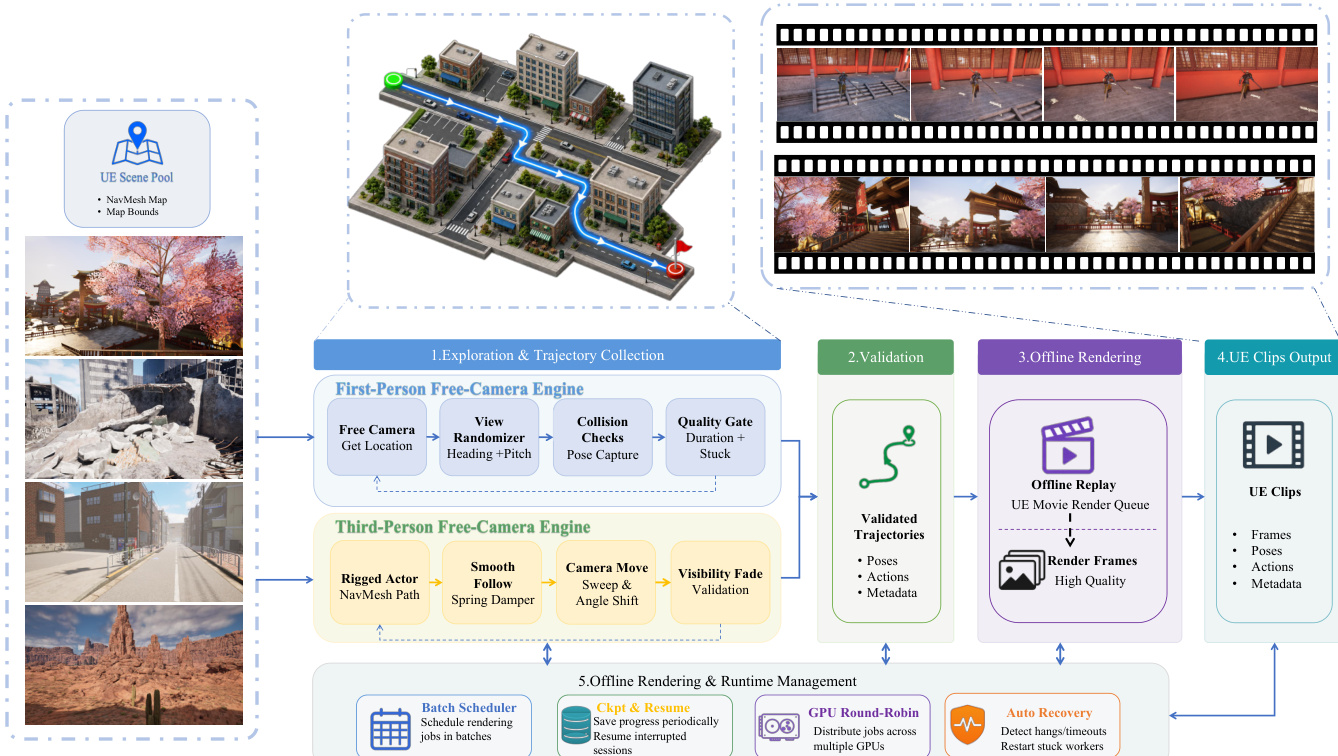
- UE first-person: Generated by a free camera navigating via NavMesh toward sampled goals with randomized heading and pitch. Trajectories are validated with collision checks, minimum duration and path-length constraints, and stuck detection; accepted trajectories are rendered offline.
- UE third-person: A rigged character follows navigation paths while a follow camera records with smooth tracking, collision avoidance, and occlusion handling. The character’s world position and heading are recorded alongside camera pose.
- UE event: Captures object interactions and visible state changes, sharing the unified output schema.
- Real-world and game videos: Processed through the same filtering and cleaning stages as UE data. Camera poses are interpolated (SLERP for rotation, linear interpolation for translation), normalized, and checked for inconsistent intrinsics, translation spikes, rapid rotations, vertical jitter, and invalid orientations.
Filtering and annotation pipeline
- Basic filtering: Removes clips with insufficient duration or frame rate, excessive overlaid text, black borders, or limited visual change (measured by CLIP embedding cosine similarity between first and last frames).
- Geometric camera-pose cleaning: Densifies sparse real-world poses, normalizes trajectories, and rejects those with geometric anomalies.
- Captioning and attribute tagging: Each clip gets a global caption describing scene, subjects, actions, and temporal changes. Retained clips are tagged with aesthetic quality, motion intensity, scene category, visual style, subject type, and a motion category (3D for static scenes with camera motion, 4D for scenes with both camera and object motion). These tags inform further filtering and training.
- Event instruction data: From the cleaned pool, clips with visible state changes are selected and annotated with structured event descriptions. A hierarchical captioning strategy pairs a holistic global description with dense, time-aligned entity-level event records (entity reference, event predicate, spatial anchor, temporal interval). The dataset mixes single-object and composable events to teach grounding of atomic and compositional instructions.
How the data is used
- The combined dataset serves as training material for interactive world models. The authors do not disclose exact mixture ratios, but the UE-generated portion forms a substantial share, supplemented by real-world and game videos.
- Per-frame ground-truth annotations in UE data (discrete action vectors as keyboard-style control signals: WASD for translation, IJKL for rotation, plus camera pose) enable supervised learning of action-conditioned dynamics. Third-person clips additionally provide character world position and heading for joint reasoning over camera and agent motion.
- The event instruction subset is used for Event Instruction Tuning, where the model learns to follow structured event descriptions that ground both atomic and compositional changes.
Processing details
- UE clips are generated in a two-stage pipeline: online trajectory discovery and validation, followed by offline rendering with Unreal Engine’s Movie Render Queue. Rendering is distributed across multiple GPUs with checkpoint resumption and automatic failure recovery, storing poses, actions, and metadata.
- Real-world and game videos are aligned to the same coordinate system and undergo the three-stage quality-control pipeline. No cropping strategy is explicitly mentioned; filtering focuses on removing low-quality or static clips, and metadata construction includes the hierarchical captions and attribute tags.
Method
The authors present DreamX-World 1.0, a general-purpose interactive world model initialized from Wan2.2. The system is designed to support camera-controlled generation, long-horizon scene persistence, and real-time streaming. The overall framework integrates a multi-source data system, a progressive training pipeline, and an optimized inference engine.
As shown in the figure below:
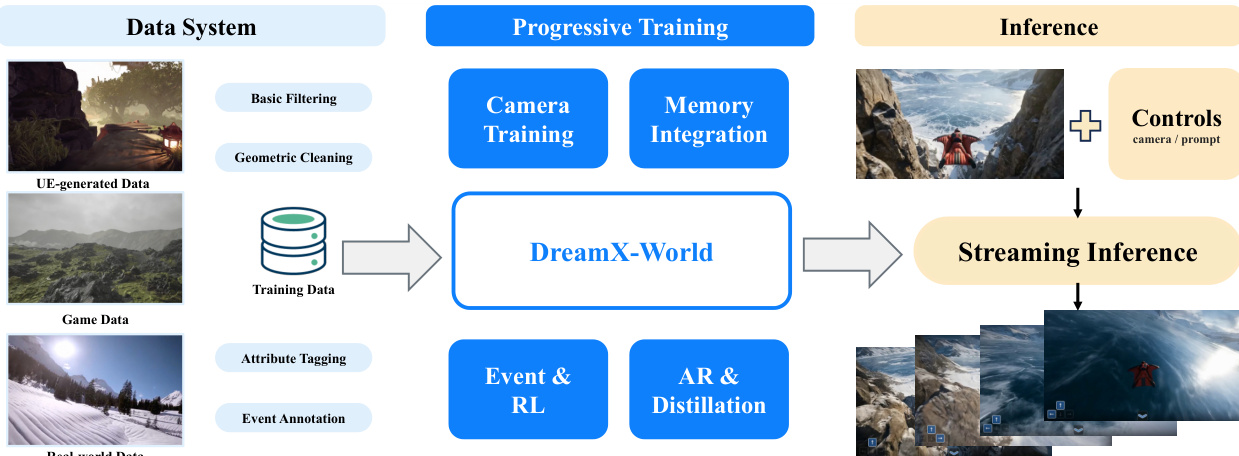
The training data is constructed from Unreal Engine trajectories with exact camera geometry, gameplay recordings with action-rich dynamics, and real-world videos with recovered camera poses. The data pipeline involves exploration and trajectory collection using first-person and third-person free-camera engines, followed by validation and offline rendering to produce high-quality clips with poses and metadata.
Refer to the framework diagram:
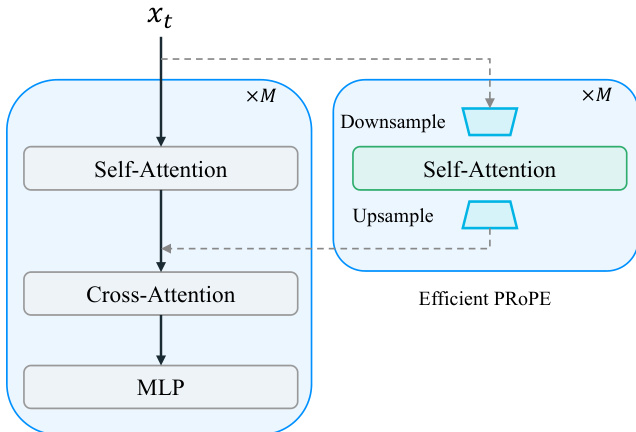
To enable efficient 6-DoF camera control, the authors introduce E-PRoPE (Efficient Projective Positional Encoding). Standard PROPE defines a per-token matrix composed of projective and rotary submatrices: DsPRoPE=[DsProj00DsRoPE]. Applying this to the full token set is computationally expensive. E-PRoPE downsamples the input tokens along the spatial dimension, computes self-attention in a lower-dimensional space using only the projective submatrix DsProj, and then upsamples the output to add to the original DiT attention output. This design retains trajectory-following performance while significantly reducing inference latency.
As shown in the figure below:
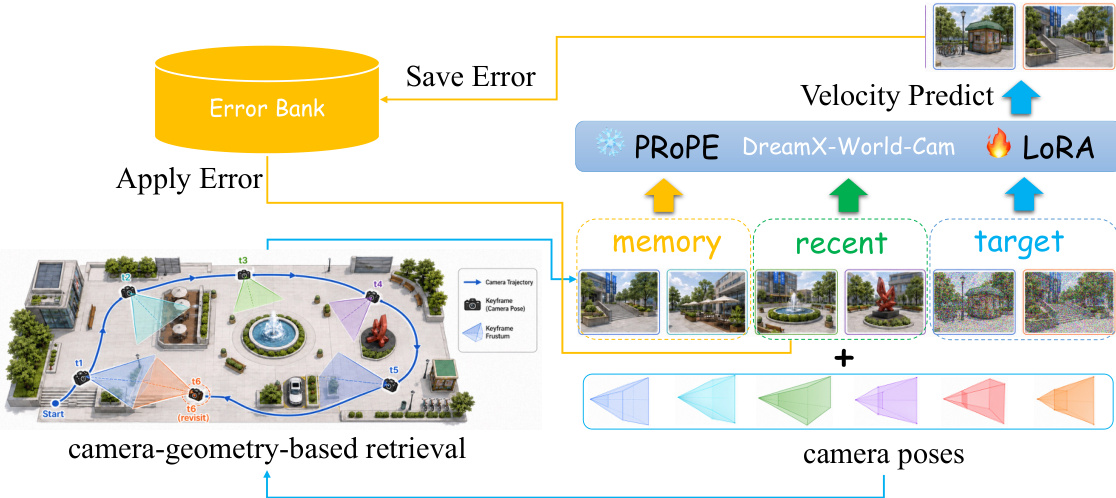
To address scene inconsistency when the camera revisits locations, a memory-conditioned stage is employed. The model uses geometry-based retrieval to select non-local memory frames that are highly relevant to the target view based on camera pose and view overlap. These memory frames are packed with recent history frames and target frames into the DiT self-attention stream. To mitigate the exposure bias arising from the gap between training and inference, the authors apply an error injection strategy where conditioning tokens are perturbed while keeping the target latent clean.
Refer to the framework diagram:
For long-horizon streaming generation, the bidirectional model is distilled into a few-step autoregressive generator. The authors utilize Distribution Matching Distillation (DMD) and causal forcing. The E-PRoPE autoregressive student is distilled from the bidirectional E-PRoPE teacher over local temporal windows sampled from long videos. This process allows the model to stream from generated history while preserving visual quality and camera controllability.
As shown in the figure below:
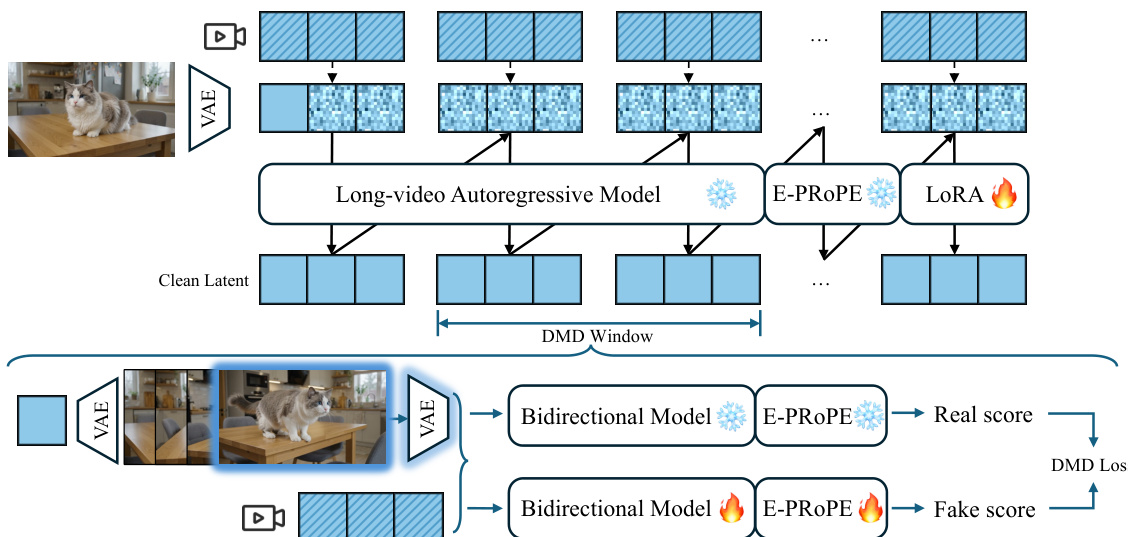
Finally, to recover visual quality and strengthen camera following after distillation, a reinforcement learning stage is applied. The model generates long-horizon rollouts, and short clips are sampled for evaluation by video-quality and camera-control reward models. A fused reward drives a conservative update, ensuring the model retains the efficiency of the few-step interface while improving output fidelity. Event Instruction Tuning is also integrated to support structured multi-entity event control through text conditioning. The inference pipeline further accelerates generation using mixed-precision DiT execution, residual reuse, pruned VAE decoding, and asynchronous pipeline parallelism to achieve real-time streaming speeds.
Experiment
The evaluation assesses DreamX-World 1.0 across basic 5-second clips, extended 30-second rollouts, and a novel revisit-based memory protocol that probes scene persistence when the camera returns to earlier locations. Qualitatively, the model produces smooth, temporally coherent sequences with high visual fidelity across diverse photorealistic, game-style, and stylized domains. Compared to HY-WorldPlay 1.5 and LingBot-World, DreamX-World 1.0 achieves the best camera controllability and overall score on short clips, sustains superior imaging quality and artifact resistance over long horizons, and demonstrates stronger memory consistency at pixel, perceptual, semantic, and place-recognition levels, showing that its forcing-based architecture and memory-conditioned design effectively reduce drift and preserve scene content.
The authors evaluate memory consistency through revisit-based protocols on generated videos to assess how well models remember previously visited regions. DreamX-World-1.0-5B achieves the highest gains across pixel-level, perceptual, semantic, and place-recognition metrics, demonstrating stronger memory retention at various levels of abstraction. HY-WorldPlay 1.5 leads in geometric structure matching and temporal smoothness, while LingBot-World demonstrates lower gains across all revisit metrics. DreamX-World-1.0-5B outperforms competing models in pixel-level fidelity, perceptual consistency, semantic identity, and place recognition. HY-WorldPlay 1.5 achieves the best scores for geometric structure matching and temporal smoothness. LingBot-World shows the lowest performance gains across all evaluated memory consistency metrics.

The authors compare the standard PRoPE camera conditioning with their lightweight variant, E-PRoPE. Results show that E-PRoPE significantly reduces latency while maintaining camera control performance that is nearly identical to the original method. Furthermore, the lightweight variant improves visual quality metrics such as transition detection and motion smoothness, though the original method retains a slight advantage in dynamic degree. E-PRoPE achieves substantially lower latency than PRoPE, validating its design as a computationally efficient variant. Camera control scores are highly comparable between the two methods, indicating that the lightweight design preserves trajectory adherence. The E-PRoPE variant outperforms the baseline in visual quality metrics like transition detection, temporal stability, and motion smoothness.

The authors evaluate DreamX-World-1.0-5B against HY-WorldPlay 1.5 and LingBot-World on long-horizon generation rollouts. Results show that DreamX-World-1.0-5B achieves the highest overall score, demonstrating superior imaging quality and artifact detection despite having fewer parameters than the competing models. While other models perform better in specific areas like camera control and motion smoothness, the proposed model sustains higher visual fidelity over long horizons. DreamX-World-1.0-5B achieves the best overall performance and imaging quality among the compared models on long-horizon rollouts. The model demonstrates superior artifact detection capabilities, indicating robust visual fidelity over extended generation periods. Competing models with larger parameter counts lead in specific metrics such as camera control and motion smoothness, but fall short in overall long-horizon consistency.

The authors evaluate their model against representative open-source world models on basic metrics including camera controllability and visual quality. Results show that the proposed method achieves the highest camera control score and the best overall score while maintaining competitive performance across visual quality dimensions. The proposed model outperforms larger competing models in overall score and camera controllability. The method maintains competitive visual quality metrics, such as transition detection and flicker reduction, across different evaluation dimensions. The model achieves superior artifact detection and dynamic motion generation compared to the largest baseline model despite having fewer parameters.

The authors compare the event control and interaction capabilities of DreamX-World 1.0 against several existing world models. Results show that DreamX-World 1.0 is the only model to fully support all evaluated dimensions, including promptable events, object-level events, region-guided events, multi-entity composition, and inter-object interaction. In contrast, competing models offer only partial support for region-guided and multi-entity tasks, while lacking inter-object interaction entirely. DreamX-World 1.0 achieves full support across all five evaluated event and interaction categories. Competing models such as LingBot-World and HY-WorldPlay 1.5 demonstrate partial capabilities in region-guided events and multi-entity composition. Matrix-Game 3.0 and Yume-1.5 lack support for most advanced event control and interaction features.

The experiments assess DreamX-World models across memory consistency in revisit scenarios, camera conditioning efficiency, long-horizon generation, basic controllability and visual quality, and event interaction capabilities. DreamX-World-1.0-5B consistently achieves the highest overall performance, exhibiting strong memory retention, superior long-horizon visual fidelity, and robust artifact detection despite its smaller parameter count, while the lightweight E-PRoPE camera variant preserves trajectory adherence with substantially lower latency. DreamX-World 1.0 is the only model that fully supports all five evaluated event and interaction categories, including inter-object interaction, whereas competing models provide only partial functionality.