Command Palette
Search for a command to run...
Mehrfach-Reflektives Masking ermöglicht das Schlussfolgern in Mask-Diffusionsmodellen
Mehrfach-Reflektives Masking ermöglicht das Schlussfolgern in Mask-Diffusionsmodellen
Yanming Zhang Yihan Bian Jingyuan Qi Yuguang Yao Lifu Huang Tianyi Zhou
Zusammenfassung
Während das Reasoning auf autoregressiven (AR) Modellen häufig durch Chain-of-Thought-Reasoning und Reflexion erfolgt, basiert die Verfeinerung vorheriger Ausgaben weiterhin auf einer vollständig sequenziellen Generierung, selbst wenn lediglich lokale Anpassungen erforderlich sind. Im Gegensatz dazu unterstützt der Maskierungsmechanismus in Mask Diffusion Models (MDMs) auf natürliche Weise explizite lokale Änderungen an vorherigen Ausgaben und ermöglicht so eine selektive Verfeinerung, ohne vorherige Antworten verwerfen und eine neue von Grund auf generieren zu müssen. Während diese Eigenschaft besser mit der Art und Weise übereinstimmt, wie Menschen Fehler durch iterative lokale Verfeinerung korrigieren, unterstützen bestehende MDMs kein mehrgängiges Masking und Rauschentfernung. Wir schlagen Reflective Masking (RM) vor, das eine solche inhärente Reasoning-Fähigkeit in MDMs durch leichtgewichtiges Post-Training hervorbringt. RM bietet ein natives Test-Time-Scaling, bei dem ein MDM seine vorherigen Ausgaben iterativ erneut betrachtet und basierend auf einem sich wandelnden Kontext überarbeitet. Um Erkenntnisse aus vorherigen Durchgängen, wie sie beim AR-Reasoning auftreten, zu nutzen, führen wir zudem History Reference ein, einen parameterfreien Mechanismus, der während der Überarbeitung auf intermediate Rauschentfernungszustände zurückgreift. Unser Ansatz erfordert keine architektonischen Änderungen und lässt sich problemlos auf bestehende MDMs anwenden. Über verschiedene Aufgaben und Modalitäten hinweg, darunter Textgenerierung, Sudoku und Bildbearbeitung, schlägt Reflective Masking konsistent standardmäßige, maskierungsbasierte Baselines und demonstriert eine hohe Allgemeingültigkeit, wodurch RM als grundlegendes Primitiv für das Reasoning auf MDMs positioniert wird.
One-sentence Summary
The authors propose Reflective Masking, a lightweight post-training method that elicits iterative reasoning in Mask Diffusion Models by enabling multi-turn masking for selective local refinement without relying on autoregressive sequential generation, and when combined with a parameter-free History Reference mechanism, it delivers native test-time scaling for iterative self-correction across existing architectures without structural modifications.
Key Contributions
- Reflective Masking is introduced as a lightweight post-training technique that formulates token masking as an uncertainty-driven decision process to enable iterative self-correction in Mask Diffusion Models. This method permits selective refinement of prior outputs without architectural modifications, establishing a native test-time scaling mechanism distinct from sequential autoregressive generation.
- A scalable training paradigm coupled with a specialized data generation strategy activates this capability by aligning optimization signals with the model's native output distribution. Evaluations across image editing, Sudoku reasoning, and text generation tasks demonstrate consistent performance improvements, confirming the approach's cross-modal applicability.
- History Reference is proposed as a parameter-free mechanism that preserves intermediate denoising states to maintain a temporal view of the decoding trajectory. This component explicitly incorporates past predictions into iterative updates, enhancing revision consistency and preventing repeated errors during multi-turn refinement.
Introduction
Large language models dominate reasoning tasks but frequently propagate errors in multi-turn settings, a structural weakness that forces full sequence regeneration and wastes computation. Mask diffusion models offer a compelling alternative by supporting localized token updates, which could maintain cleaner intermediate contexts and enable efficient self-correction. However, standard decoding follows a passive process that locks in early predictions, leaving models unable to actively revisit or fix previously committed errors. To unlock this latent capability, the authors introduce Reflective Masking, a post-training framework that treats token masking as an uncertainty-driven decision process for selective revision. They combine this with a lightweight training pipeline and History Reference, a parameter-free mechanism that preserves intermediate decoding states to guide iterative refinement. Together, these innovations shift mask diffusion generation from linear forward expansion to a self-correcting reasoning loop that consistently improves performance across text, structured, and image tasks.
Method
The authors propose Reflective Masking (RM), a framework that transforms Mask Diffusion Models (MDMs) into iterative reasoning engines capable of local editing. Standard MDMs typically follow an absorbing Markov process, whereas RM introduces a per-position decision mechanism that allows the model to selectively refine its outputs over multiple denoising steps without discarding previous answers.
At each timestep t, the model evaluates the current state x~(t) and determines the next state x~(t+1) for each position i based on its output probability distribution pθ(⋅∣x~(t))i. The transition is governed by a deterministic rule that splits on whether the position is currently masked:
x~i(t+1)=⎩⎨⎧Mx~i(t)argmaxv∈Vpθ(v∣x~(t))iif x~i(t)=M and pθ(M∣x~(t))i>pθ(x~i(t)∣x~(t))iif x~i(t)=M and pθ(M∣x~(t))i≤pθ(x~i(t)∣x~(t))iif x~i(t)=MAs shown in the framework diagram:
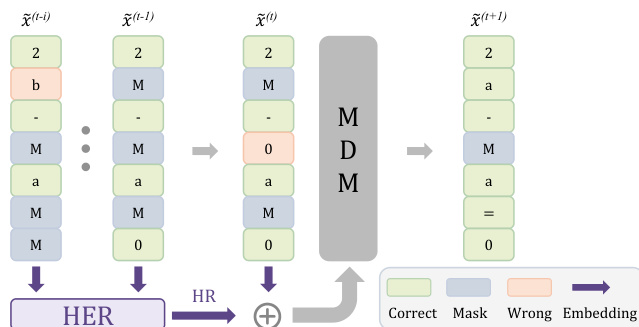
The diagram illustrates the iterative refinement process where a wrong token (orange) is re-masked (blue) and subsequently revealed as the correct token (green). To prevent the model from entering loops where identical states are repeatedly generated, the authors incorporate a History Reference (HER) module. This parameter-free mechanism aggregates intermediate denoising states into a history-aware embedding, providing the model with context about its revision trajectory and stabilizing the multi-turn refinement process.
To align the model with this inference behavior, the authors design a training paradigm that supervises the model with per-position oracle labels. The training data is constructed by simulating synthetic trajectories. Starting from a clean sequence, specific positions are corrupted either with mask tokens or wrong tokens sampled from a corruption distribution.
As illustrated in the figure below:
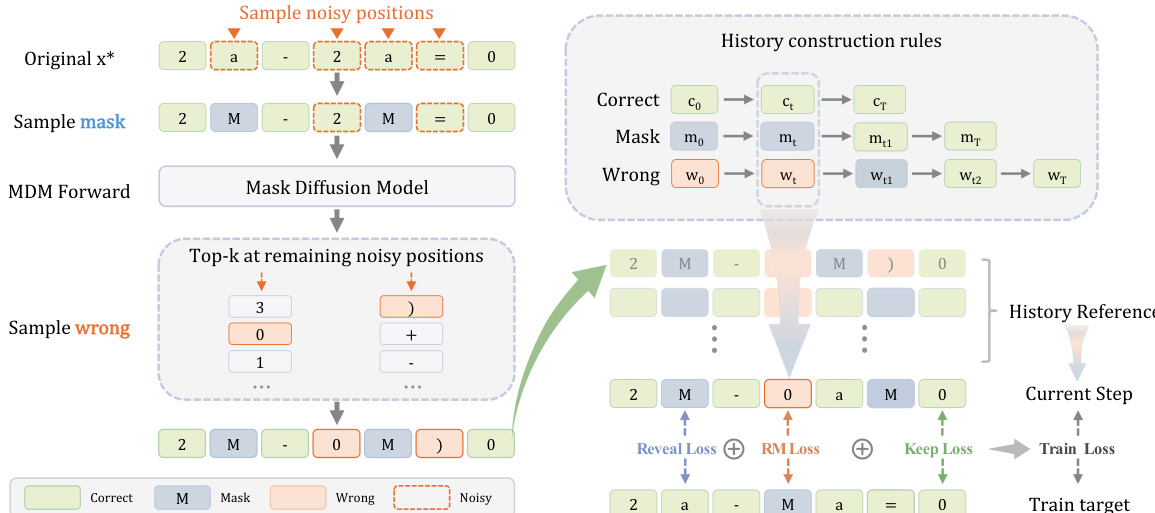
The figure details the history construction rules and the decomposition of the training loss. The transition rules dictate that wrong tokens should eventually transition to mask tokens and then to the correct target, while masked tokens transition directly to the target. The training objective minimizes the cross-entropy loss against these oracle actions, decomposing into three components: a reveal loss for masked positions, a mask loss for wrong positions, and a keep loss for correct tokens. This setup ensures the model learns to correctly identify when to revise a token versus when to preserve it, effectively enabling the reflective masking capability.
Experiment
The evaluation spans three task categories that progressively increase in reasoning complexity and decrease in external guidance: instruction-based image editing, structured Sudoku revision, and fully autonomous text reasoning and code generation. These experiments validate how Reflective Masking enables precise, localized revisions under explicit supervision, while History Reference facilitates autonomous error detection and iterative correction when guidance is minimal. Qualitatively, the model demonstrates targeted self-correction that preserves unmodified regions in images and systematically refines logic-critical tokens during multi-step reasoning. Overall, the findings confirm that integrating iterative revision with structured historical memory consistently enhances accuracy and logical consistency across diverse generation tasks.
The authors evaluate an image editing approach against Lumina and a fine-tuned baseline across three key dimensions: edit localization, background preservation, and overall editing quality. The results demonstrate that the proposed method consistently outperforms the baselines in accurately targeting specific regions while maintaining the integrity of the surrounding image. The proposed method achieves superior precision and coverage in identifying target regions for editing compared to baseline models. Background preservation is significantly improved, with the method maintaining higher similarity and lower error rates in unedited areas. The approach yields better overall editing quality, ranking highest in both automated scoring and user preference studies.

The authors evaluate Sudoku revision capabilities by testing variants of their method, including Reflective Masking and History Reference. Results indicate that incorporating History Reference significantly enhances exact accuracy and validity while reducing errors and conflicts. The complete model, which integrates all components including decay and HER, achieves the superior performance across all metrics. Integrating History Reference substantially improves exact accuracy and valid rates while minimizing replay mistakes and conflict cells compared to the baseline. The full method combining all components achieves the best overall performance, outperforming variants that lack specific mechanisms. Adding a decay factor to history reference alone offers limited benefits compared to using history reference without decay, but becomes advantageous when combined with HER.

The authors evaluate their approach on text reasoning tasks spanning mathematics, code generation, and multiple-choice questions. Results demonstrate that the proposed method consistently outperforms baseline models across all evaluated categories. Notably, the method achieves substantial improvements in code generation tasks compared to mathematical reasoning. The proposed method consistently outperforms both LLaDA and Vanilla SFT baselines across math, code, and multiple-choice benchmarks. Performance gains are particularly pronounced in code generation tasks, where the model benefits significantly from iterative revision capabilities. The approach effectively improves multi-step reasoning and structured output generation without compromising standard inference capabilities.

The authors evaluate their method on the Minerva MATH benchmark across various mathematical subjects. The results demonstrate that the proposed method consistently outperforms the Vanilla SFT baseline across all subject categories and the aggregate score. The method achieves higher accuracy than the baseline in every subject category, including Algebra, Geometry, and Number Theory. There is a consistent positive improvement in the aggregate performance metric. The approach effectively enhances performance in diverse mathematical reasoning tasks.

Evaluated against established baselines across image editing, Sudoku revision, text reasoning, and mathematical problem-solving, the experiments validate the method's precision, error reduction, and iterative reasoning capabilities. In image editing, the approach consistently achieves superior region targeting and background preservation while delivering higher overall quality. For structured tasks like Sudoku and code generation, incorporating history-based references and revision mechanisms significantly improves accuracy and minimizes conflicts without degrading standard inference. Across mathematical benchmarks, the method uniformly enhances performance in diverse reasoning categories, demonstrating robust cross-domain improvements.