Command Palette
Search for a command to run...
Multi-LCB: Erweiterung von LiveCodeBench auf mehrere Programmiersprachen
Multi-LCB: Erweiterung von LiveCodeBench auf mehrere Programmiersprachen
Maria Ivanova Pavel Zadorozhny Rodion Levichev Ivan Petrov Adamenko Pavel Ivan Lopatin Alexey Kutalev Dmitrii Babaev
Zusammenfassung
LiveCodeBench (LCB) hat sich in jüngster Zeit zu einem weit verbreiteten Benchmark für die Evaluierung von Large Language Models (LLMs) bei Code-Generierungsaufgaben entwickelt. Durch die kuratierte Zusammenstellung von Wettbewerbsprogrammieraufgaben, das kontinuierliche Hinzufügen neuer Aufgaben zum Datensatz sowie deren Filterung nach Veröffentlichungsdaten ermöglicht LCB eine kontaminationsbewusste Evaluierung und bietet einen ganzheitlichen Überblick über die Programmierkompetenz. Allerdings beschränkt sich LCB nach wie vor auf Python, wodurch die Frage offen bleibt, ob LLMs ihre Fähigkeiten auf die in der praktischen Softwareentwicklung erforderlichen vielfältigen Programmiersprachen verallgemeinern können. Wir präsentieren Multi-LCB, einen Benchmark zur Evaluierung von LLMs über zwölf Programmiersprachen hinweg, einschließlich Python. Multi-LCB transformiert Python-Aufgaben aus dem LCB-Datensatz in äquivalente Aufgaben in anderen Sprachen, wobei die Kontaminationskontrollen und das Evaluierungsprotokoll von LCB beibehalten werden. Da es vollständig mit dem ursprünglichen LCB-Format kompatibel ist, wird Multi-LCB zukünftige LCB-Updates automatisch nachverfolgen, was eine systematische Bewertung der sprachenübergreifenden Code-Generierungskompetenz ermöglicht und Modelle dazu verpflichtet, die Leistung weit über Python hinaus aufrechtzuerhalten. Wir haben 24 LLMs hinsichtlich Instruktion und logischem Schlussfolgern auf Multi-LCB evaluiert und dabei Hinweise auf ein Overfitting auf Python, languagespezifische Kontaminationen sowie erhebliche Unterschiede in der multilingualen Leistung aufgedeckt. Unsere Ergebnisse etablieren Multi-LCB als einen rigorosen neuen Benchmark für die Code-Evaluierung in mehreren Programmiersprachen, der die Hauptbeschränkung von LCB direkt adressiert und kritische Lücken in den aktuellen Fähigkeiten von LLMs aufzeigt.
One-sentence Summary
Multi-LCB extends the Python-only LiveCodeBench benchmark to twelve programming languages by transforming its tasks into equivalent versions in other languages while preserving contamination controls, and an evaluation of twenty-four large language models reveals substantial cross-language performance disparities, language-specific contamination, and evidence of Python overfitting.
Key Contributions
- Multi-LCB extends the LiveCodeBench benchmark to twelve programming languages by converting Python tasks into equivalent implementations while preserving the original release-date filtering and live evaluation protocol.
- The framework automatically tracks future LiveCodeBench updates to enable continuous multilingual assessment and supports the evaluation of twenty-four instruction and reasoning-oriented large language models.
- Empirical evaluation reveals Python overfitting, language-specific data contamination, and substantial performance disparities, demonstrating that Python proficiency does not reliably predict capability across other programming environments.
Introduction
Large language models have become central to AI-assisted programming and automated software development, making rigorous evaluation benchmarks essential for tracking model capabilities. While LiveCodeBench established a contamination-aware standard for measuring code generation, it evaluates only Python. This narrow scope obscures whether models truly generalize programming competence or merely overfit to a single language, leaving a critical gap in assessing real-world software engineering workflows. The authors address this limitation by introducing Multi-LCB, an extension that scales LiveCodeBench’s contamination-controlled protocol across twelve programming languages. By systematically translating tasks while preserving continuous updates and standardized execution, the authors enable direct cross-language comparison and uncover significant performance disparities, language-specific data leakage, and widespread Python overfitting in modern models.
Dataset

Dataset Composition and Sources
- The authors introduce Multi-LCB, a multilingual extension of the LiveCodeBench (LCB) code generation dataset designed to evaluate programming capabilities across twelve languages.
- The dataset aggregates problems from three major competitive programming platforms: LeetCode, AtCoder, and Codeforces.
- Supported languages include C++, C#, Python, Java, Rust, Go, TypeScript, JavaScript, Ruby, PHP, Kotlin, and Scala.
- Language selection prioritizes popularity, stable infrastructure support, and paradigmatic diversity across type systems, memory management models, and runtime environments.
Key Details for Each Subset
- Platform Formats: AtCoder and Codeforces tasks retain their native STDIN/STDOUT format, while LeetCode tasks originally use a functional format requiring specific function signatures and are converted to the unified STDIN/STDOUT structure.
- Filtering Rules: The dataset inherits LCB's contamination controls by filtering tasks based on contest release dates relative to model training windows.
- Quality Constraints: Tasks admitting multiple valid answers or requiring explicit data structure construction are excluded to ensure strict input/output grading.
- I/O Structures: Converted tasks are categorized by input and output dimensionality, including scalar values, one-dimensional arrays, and two-dimensional arrays.
- Scope Limitations: The benchmark covers 12 languages based on 2025 popularity rankings and excludes others such as Swift or Haskell due to runtime or ecosystem constraints.
Usage and Processing
- Evaluation Only: The authors use Multi-LCB strictly as an evaluation resource. No models are trained on the dataset, and there are no training splits or mixture ratios.
- Prompt Strategy: The benchmark employs a zero-shot prompting strategy. Prompts consist of a system message defining target language expertise, a user message containing the natural language description with explicit STDIN/STDOUT specifications and sample cases, and a code block placeholder.
- Conversion Pipeline: A dedicated pipeline converts LeetCode functional tasks to the unified STDIN/STDOUT format. This includes adapting problem prompts and transforming all test cases, including hidden tests, to enable a single evaluation harness across all languages.
- Evaluation Protocol: Generated code is compiled or executed in the target language and assessed using the Pass@1 metric.
Metadata and Processing Details
- Metadata Construction: Each task retains metadata from LCB, including contest release dates for contamination tracking, platform source, and difficulty levels.
- Formatting Rules: During conversion, lists are formatted as space-separated values. Two-dimensional arrays use a structure where the first line indicates the number of rows, followed by row-wise space-separated values.
- Language Agnosticism: The conversion process ensures tasks remain language-agnostic, requiring no language-specific rewriting of the core problem logic.
- Validation: Manual inspection of sample tasks confirmed the absence of inconsistencies caused by language-dependent features.
Method
The authors present Multi-LCB, a comprehensive evaluation framework designed to assess large language models across twelve distinct programming languages. This approach extends the original LiveCodeBench (LCB) to address the limitation of Python-only evaluation, enabling direct comparison of model capabilities on identical problems across different languages. The system relies on a modular pipeline that standardizes the problem-solving process from prompt construction to code execution.
Refer to the framework diagram below:
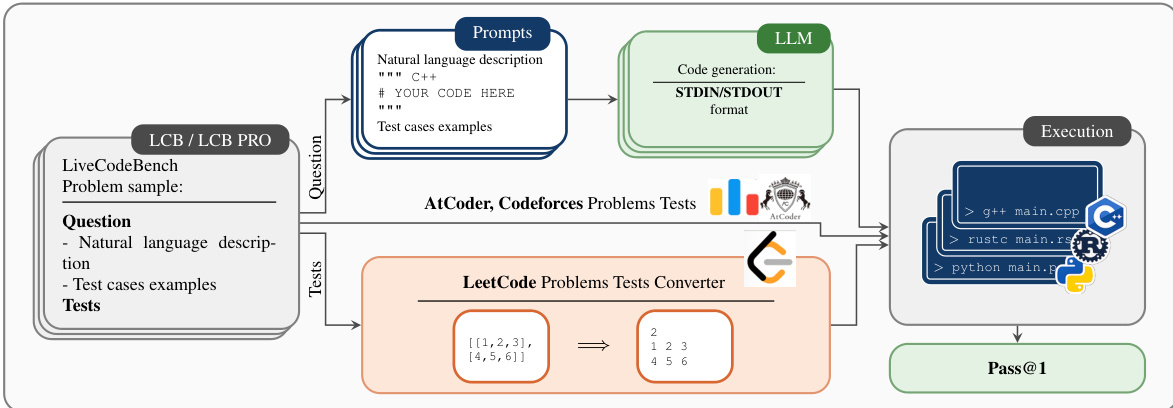
The pipeline begins with problem samples sourced from LCB or LCB PRO, which include natural language descriptions and test case examples. The authors leverage a standardized prompt template to format these inputs. For non-Python settings, the header of the code block is adjusted (e.g., """cpp or """java), while the rest of the prompt structure remains identical to the Python baseline. This ensures consistency in how the LLM receives instructions. The LLM is then tasked with generating code that adheres to a STDIN/STDOUT format, allowing for standardized input and output handling.
A critical module in this architecture is the "LeetCode Problems Tests Converter." Since many coding benchmarks, such as LeetCode, provide test cases as structured data (e.g., lists or arrays) rather than raw text, this converter transforms them into a format suitable for standard input streams. For instance, an input like [[1,2,3], [4,5,6]] is converted into a text representation where dimensions and elements are printed on separate lines. This module also facilitates compatibility with tests from other platforms like AtCoder and Codeforces.
Finally, the generated code and the converted test cases are passed to the execution environment. The framework supports a diverse range of execution models, categorized into compiled languages (C++, Rust, Go, Java, C#, Scala, Kotlin), interpreted languages (Python, Ruby, PHP), and transpiled languages (TypeScript to JavaScript). The system executes the code against the test cases and computes the Pass@1 metric to evaluate correctness. This end-to-end process allows for rigorous, contamination-aware evaluation of coding models across a wide spectrum of programming languages.
Experiment
The evaluation utilizes a fully automated, zero-shot pipeline to assess twenty-four large language models across twelve programming languages, validating cross-lingual generalization capabilities, benchmark fidelity, and contamination controls through secure execution against hidden test suites. Qualitative analysis reveals a persistent performance bias toward Python, demonstrating that single-language proficiency is an unreliable proxy for true multi-language coding competence. Temporal checks and error breakdowns confirm that release-date filtering effectively isolates genuine generalization from pretraining exposure, while also highlighting algorithmic correctness as the primary bottleneck and exposing predictable syntactic and runtime challenges inherent to compiled languages. Ultimately, the findings indicate that robust multi-language code generation remains a significant frontier, heavily constrained by training data distribution, language-specific execution overheads, and escalating problem complexity.
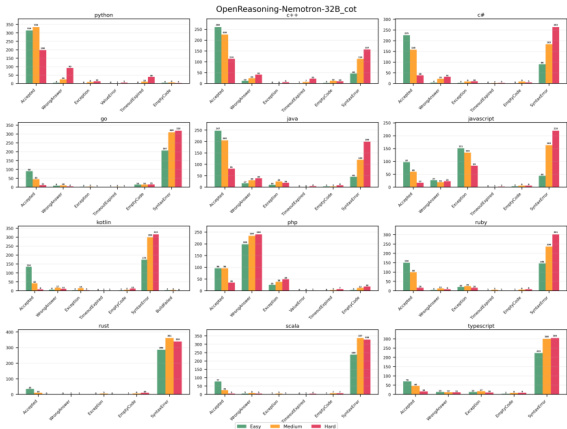
The experiment evaluates the OpenReasoning-Nemotron-32B model across 12 programming languages, analyzing performance by task difficulty and error type. Results show a consistent decline in success rates as problem complexity increases from Easy to Hard, with Hard tasks proving the most challenging. Error analysis reveals language-specific patterns, such as higher compilation errors in C++ and runtime errors in Java, while Python maintains the highest performance and lowest error rates. Model performance decreases significantly as task difficulty increases, with Hard problems showing the largest performance gaps. Wrong-answer errors dominate across most languages, but compiled languages like C++ and Rust also exhibit notable compilation error rates. Python demonstrates superior capability with the highest success rates and minimal runtime or syntax errors compared to other languages.
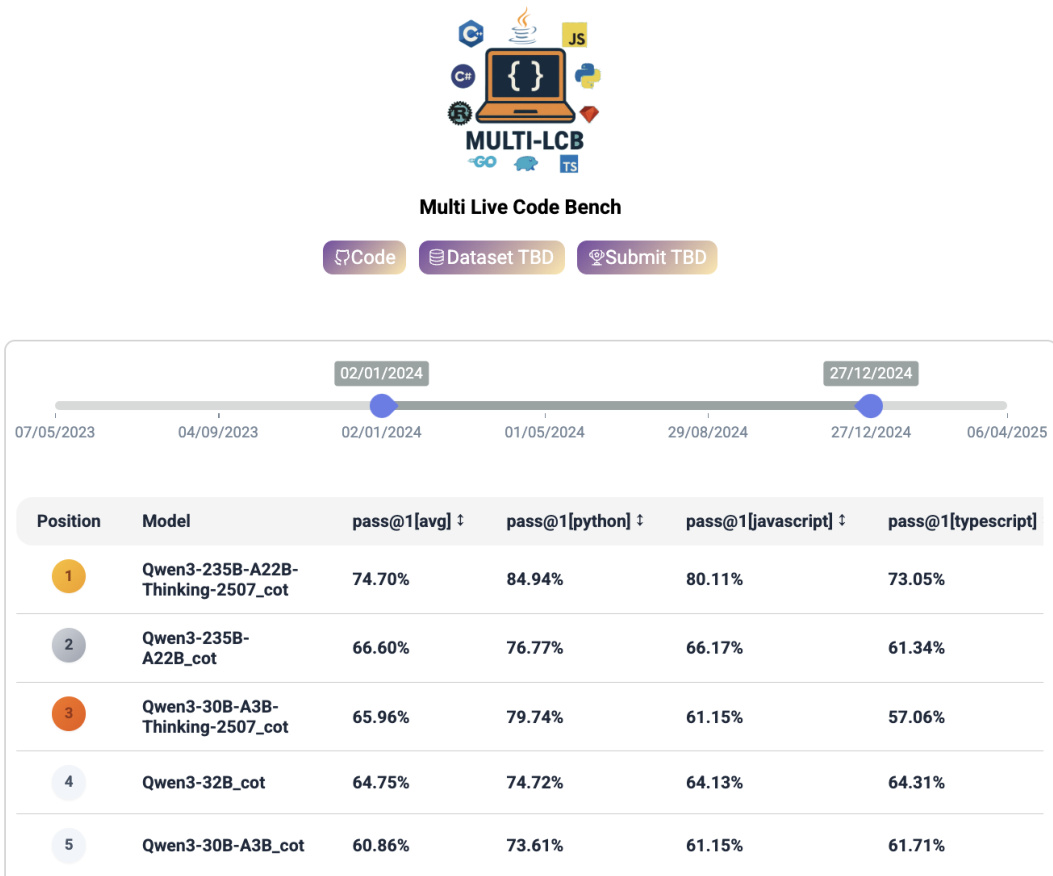
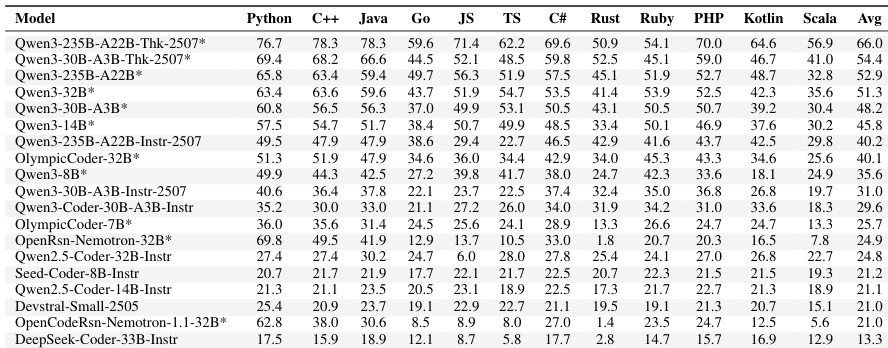
The authors evaluate a suite of large language models on the Multi-LCB benchmark to assess code generation capabilities across multiple programming languages. The results demonstrate that reasoning-augmented models, particularly the largest Qwen3 variant, achieve the highest overall performance. The evaluation reveals a persistent trend where models score significantly higher on Python tasks compared to JavaScript and TypeScript, highlighting a language-specific bias in current capabilities. Reasoning-enhanced models dominate the leaderboard, with the top-performing variant showing superior capabilities across all evaluated languages. There is a consistent performance gap between Python and other languages, as models achieve higher success rates on Python tasks. Efficient model architectures demonstrate strong competitiveness, securing high rankings despite having fewer parameters than the leading models.
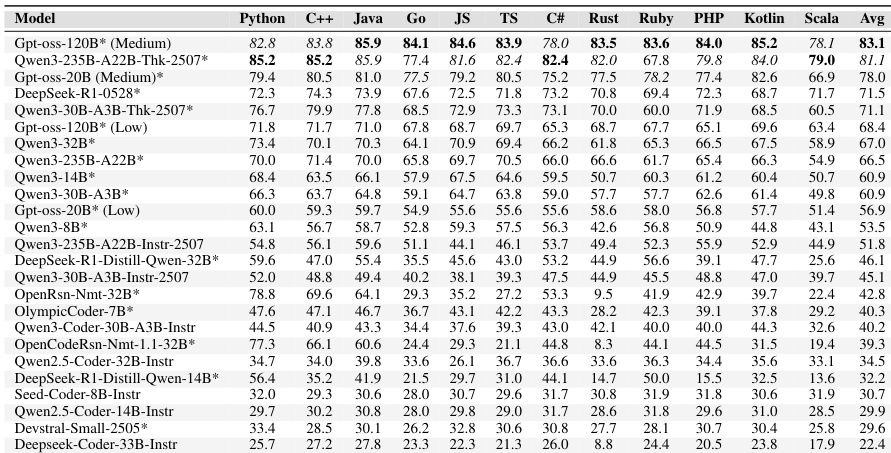
The authors evaluate a diverse set of large language models across multiple programming languages using a zero-shot prompting strategy. Results demonstrate that Python remains the most proficient language for current models, while compiled languages like Scala and Kotlin present significantly higher difficulty. Top-performing reasoning-augmented models establish a strong frontier, yet most evaluated systems struggle to achieve robust correctness across diverse language ecosystems. Python consistently yields the highest scores across nearly all models, whereas languages like Scala and Kotlin show the lowest performance. Reasoning-augmented models significantly outperform their non-reasoning counterparts, particularly in complex, compiled languages. Strong performance in Python does not reliably predict success in other programming languages, highlighting a gap in cross-lingual generalization.
The experiment evaluates a range of large language models across multiple programming languages to assess code generation capabilities. The results indicate that reasoning-augmented models, particularly the largest Qwen3 variant, achieve the highest overall performance. A consistent pattern emerges where Python scores are significantly higher than those of other languages, with Scala demonstrating the lowest success rates across most models. Reasoning-enhanced models consistently outperform instruction-tuned variants of comparable size. Python yields the highest pass rates across the majority of models, whereas Scala shows the lowest performance. The largest evaluated model establishes a clear performance advantage over smaller or less capable counterparts.
The evaluation demonstrates that reasoning-augmented models consistently achieve higher Pass@1 scores across diverse programming languages compared to standard instruction-tuned variants. Performance varies substantially by language, with interpreted languages like TypeScript and Go generally yielding higher success rates than compiled languages such as Rust and Scala. Additionally, platform-specific challenges are evident, as models often perform better on interview-style problems than on competitive programming tasks. Reasoning-enhanced models significantly outperform their standard counterparts across all evaluated languages. Interpreted languages like TypeScript and Go show higher overall success rates compared to compiled languages like Rust and Scala. Models generally achieve higher Pass@1 scores on LeetCode-style problems than on competitive programming platforms like AtCoder.
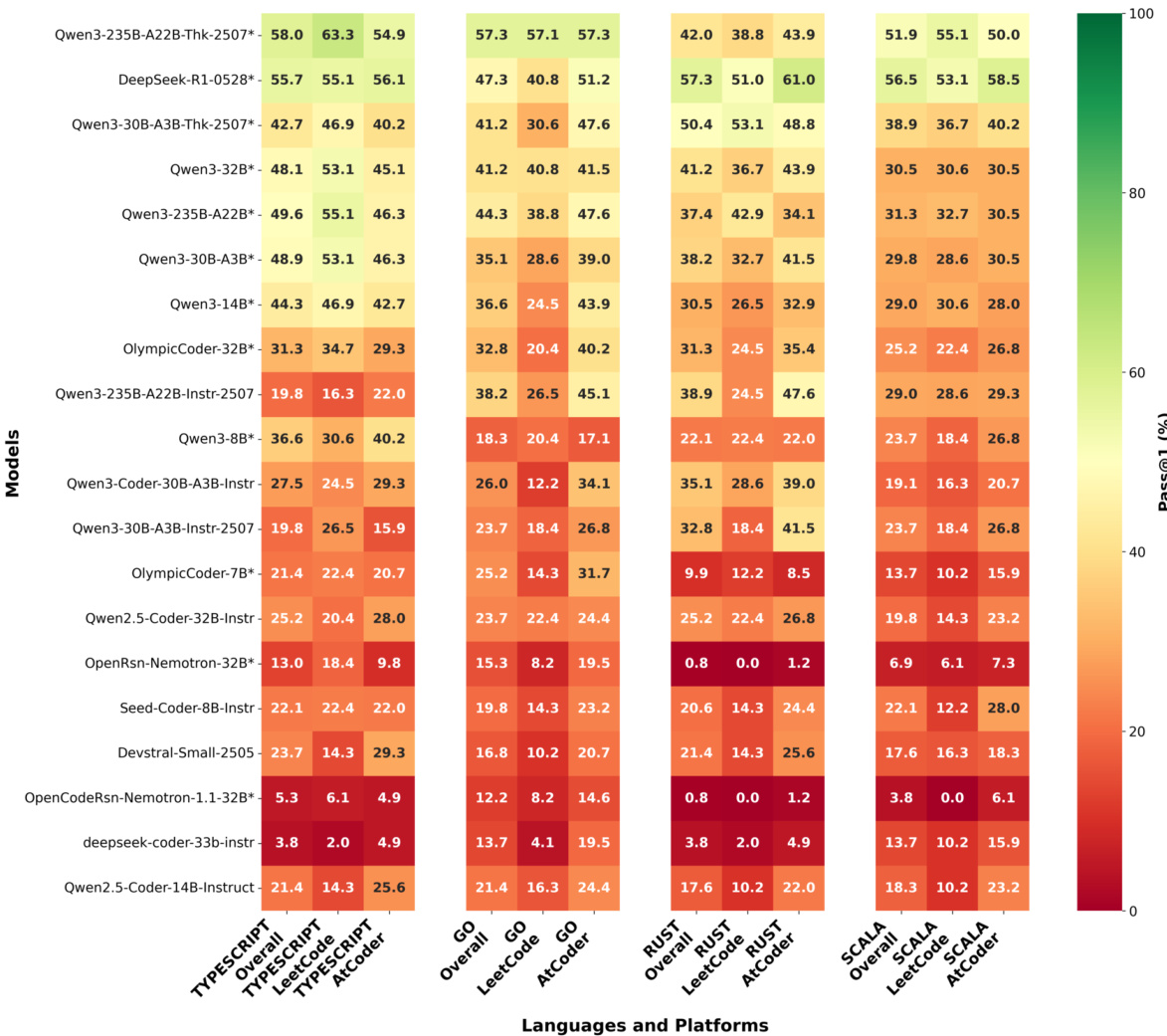
Multiple experiments evaluate a diverse range of large language models across numerous programming languages to assess code generation capabilities and validate the effects of reasoning augmentation, task complexity, and language paradigms. Qualitative analysis reveals that reasoning-enhanced architectures consistently outperform standard instruction-tuned variants, with larger models demonstrating superior robustness on increasingly difficult problems. Performance exhibits a pronounced language-specific bias, as interpreted languages like Python and TypeScript yield significantly higher success rates than compiled alternatives, and strong results in one language do not reliably predict cross-lingual generalization. Furthermore, error patterns highlight distinct challenges across ecosystems, with compiled languages struggling primarily with syntax and compilation issues while models consistently perform better on standard interview-style tasks than on rigorous competitive programming benchmarks.