Command Palette
Search for a command to run...
OpenComputer: Überprüfbare Softwarewelten für Computer-Nutzungs-Agents
OpenComputer: Überprüfbare Softwarewelten für Computer-Nutzungs-Agents
Jinbiao Wei Qianran Ma Yilun Zhao Xiao Zhou Kangqi Ni Guo Gan Arman Cohan
Zusammenfassung
Titel: [Kein Titel angegeben]Zusammenfassung: Wir präsentieren OpenComputer, einen verifikationsbegründeten Rahmen zur Konstruktion überprüfbarer Softwarewelten für Computer-Use-Agents. OpenComputer integriert vier Komponenten: (1) anwendungsspezifische Zustandsverifikatoren, die strukturierte Inspektionsendpunkte über reale Anwendungen bereitstellen, (2) eine sich selbst entwickelnde Verifikationsschicht, die die Zuverlässigkeit der Verifikatoren durch ausführungsbegründetes Feedback verbessert, (3) eine Aufgaben-Generierungspipeline, die realistische und maschinenprüfbare Desktop-Aufgaben synthetisiert, und (4) eine Evaluierungs-Harness, die vollständige Trajektorien aufzeichnet und überprüfbare Teilpunktzahl-Belohnungen berechnet. In seiner aktuellen Form deckt OpenComputer 33 Desktop-Anwendungen und 1.000 abgeschlossene Aufgaben ab, die Browser, Büroanwendungen, Kreativsoftware, Entwicklungsumgebungen, Dateimanager und Kommunikationsanwendungen umfassen. Experimente zeigen, dass die fest codierten Verifikatoren von OpenComputer der menschlichen Urteilsfindung näher kommen als die LLM-as-Judge-Evaluierung, insbesondere wenn der Erfolg von einem feingranularen Anwendungsstatus abhängt. State-of-the-Art-Agents kämpfen trotz teilweiser Fortschritte mit der vollständigen Abschlussbearbeitung, und Open-Source-Modelle weisen starke Einbrüche gegenüber ihren OSWorld-Verified-Werten auf, was eine anhaltende Lücke in der robusten Computerautomatisierung aufzeigt.
One-sentence Summary
OpenComputer is a verifier-grounded framework that constructs verifiable software worlds for computer-use agents by integrating app-specific state verifiers, a self-evolving verification layer, a task-generation pipeline, and an evaluation harness across 33 desktop applications, demonstrating that its hard-coded verifiers align more closely with human adjudication than LLM-as-judge methods while exposing persistent end-to-end completion failures and OSWorld-Verified score drops in frontier and open-source models.
Key Contributions
- OpenComputer is a verifier-grounded framework that automatically synthesizes executable desktop tasks, environments, and machine-checkable success criteria without manual construction. By enforcing inspectable application state as a core design constraint, the system generates realistic software workflows for computer-use agents.
- Hard-coded verifiers align more closely with human adjudication than LLM-as-judge evaluations, particularly when success depends on fine-grained application state. A self-evolving verification layer further improves reliability by using execution-grounded feedback to automatically identify and repair verifier failures.
- The framework establishes a large-scale benchmark covering 33 desktop applications and 1,000 finalized tasks to evaluate frontier and open-source computer-use agents. Empirical results demonstrate that current models struggle with reliable end-to-end completion, exposing a persistent gap in robust desktop automation despite frequent partial progress.
Introduction
Computer-use agents represent a critical step toward general-purpose AI systems capable of interacting with everyday desktop software, yet scaling their training and evaluation is hindered by the manual effort required to build realistic environments. Existing methods rely on tedious, application-specific task construction and depend heavily on LLM-as-a-judge evaluation, which introduces prompt sensitivity, auditability issues, and a tendency to overlook critical errors in underlying application state. To address these bottlenecks, the authors leverage a verifier-grounded framework called OpenComputer that automates the creation of executable desktop tasks paired with machine-checkable success criteria. The system employs a self-evolving verification pipeline that continuously refines programmatic state checkers, enabling reproducible benchmarking across thirty-three applications and demonstrating that grounded state inspection aligns significantly better with human judgment than traditional screenshot or LLM-based evaluation.
Dataset
-
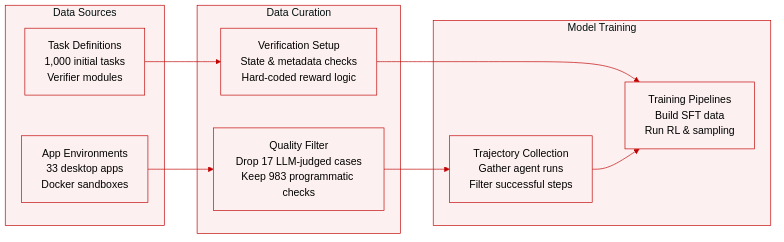
Dataset Composition and Sources: The authors release OpenComputer as an extensible benchmark infrastructure comprising 33 desktop applications and 1,000 finalized tasks. Each environment is synthetically generated and bundled with application-specific verifier modules, detailed task specifications, environment initialization scripts, and a standardized execution harness.
-
Subset Details and Filtering: The main benchmark contains exactly 1,000 tasks distributed across the 33 applications. During the synthesis phase, the authors identified 17 tasks that relied on LLM-based visual judgments rather than hard-coded programmatic checks. These cases were explicitly filtered out of the official benchmark to maintain auditability and reproducibility, though they are preserved in a separate diagnostic subset for future hybrid verification research.
-
Training and Evaluation Usage: Rather than enforcing fixed training splits or mixture ratios, the dataset is structured as a flexible pipeline for both evaluation and model training. The authors demonstrate how researchers can collect agent trajectories, filter for successful or partially successful runs, and assemble supervised fine-tuning datasets. The machine-verifiable rewards are also designed to support reinforcement learning and rejection sampling workflows.
-
Processing and Verification Strategy: Every finalized task is paired with executable verification criteria that inspect application state, file metadata, and persistent side effects instead of relying on visual proxies or LLM judgments. Environments are pre-seeded with specific initial files and paths, and tasks are executed within Docker-based sandboxes or cloud deployments. By strictly enforcing programmatic checkers and excluding visually grounded criteria, the authors ensure that success metrics remain fully reproducible across different agent implementations.
Method
The OpenComputer framework is structured around a four-phase pipeline designed to synthesize verifiable computer-use tasks in real desktop environments, ensuring both environment realism and reliable success verification. The overall architecture integrates app-specific verifiers, a self-evolving verification layer, a task generation pipeline, and an evaluation harness that computes auditable rewards. Each phase is tightly coupled to ensure that tasks are executable, checkable, and grounded in the actual state of the software.
Phase 1, Verifier Generation, begins with the construction of app-specific verifiers for each supported application. These verifiers are implemented as Python modules that expose CLI subcommands with JSON outputs, providing structured inspection and checking endpoints over the application state. The agents identify the most reliable inspection channels available for each application, such as browser debugging protocols (CDP), D-Bus, LibreOffice UNO, SQLite-backed profile databases, or accessibility APIs. The verifier development follows a fixed pipeline: first, inspectable state surfaces are enumerated and mapped to concrete verification channels; then, query and check endpoints are implemented and documented in an application-specific README. Each verifier undergoes a rigorous testing protocol that includes unit and integration tests, with a focus on realistic fixtures, JSON validity, and failure mode handling. Failed endpoints are debugged and retested until reliability is achieved. 
Phase 2, Self-Evolving Verification, refines the initial verifiers using execution-grounded feedback. For each application, a calibration set of approximately 15 easy-to-medium tasks is generated and executed in a persistent desktop sandbox. The resulting trajectories are frozen and used as fixed reference executions throughout the refinement process. An LLM evaluator inspects the full trajectory and final state to produce a reference verdict, while the programmatic verifier independently checks the same state. A comparator aligns the two verdicts criterion by criterion, identifying disagreements. Disagreements attributed to verifier-side errors—such as brittle schema assumptions or incomplete endpoint coverage—are used as feedback for refinement. The verifier evolution step is bounded to the verification stack: only checker code, endpoint implementations, or documentation may be modified, not the trajectory or task objective. The revised verifier is re-executed on the same cached state, and the process iterates until agreement is reached or a fixed budget is exhausted. This loop enables the system to detect and repair verifier issues that are not exposed by synthetic tests alone. 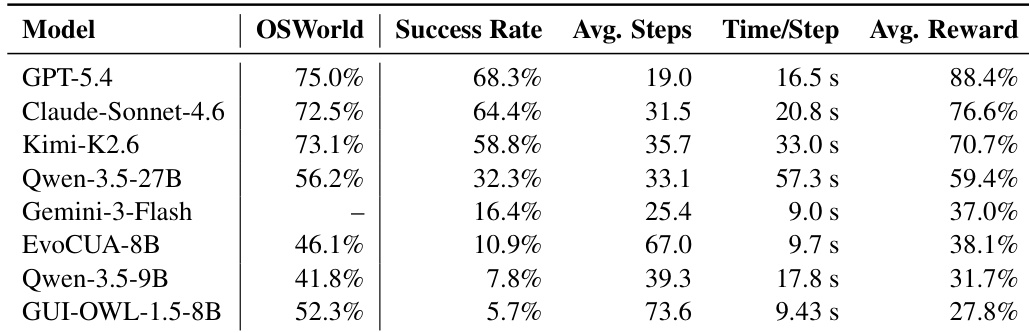
Phase 3, Task Generation Pipeline, synthesizes realistic and machine-checkable tasks by first proposing candidate goals from a user-centric perspective, avoiding direct conditioning on available endpoints to maintain benchmark diversity. These proposals are filtered for complexity and data generatability, prioritizing multi-step workflows and rejecting trivial or overly linear tasks. Accepted proposals are then grounded in the verification stack: if the outcome is already inspectable via existing endpoints, the task is retained; otherwise, the verifier is extended with new endpoints using the same generation procedure. The system then materializes each task by generating the required input artifacts—files, folders, configurations, or profiles—and packages them into a final task instance τ=(x,e,c), where x is the user-facing instruction, e is the environment initialization procedure, and c specifies the machine-checkable success criteria. A task-extension workflow periodically reviews application task sets to identify gaps and prioritize new candidate tasks. 
Phase 4, Evaluation Harness, executes the agent in a sandboxed environment initialized from the task's environment setup. The agent interacts with the system through screenshots and GUI actions, and the full trajectory is recorded. At the end of the run, the verifier checks the final application state using the structured endpoints, producing a machine verdict. The system computes a reward based on the alignment between the agent's outcome and the success criteria. This process ensures that rewards are grounded in the actual software state rather than heuristic or visual interpretation. The evaluation harness also supports the use of LLM-as-judge as a reference signal during verifier debugging, but final scoring relies exclusively on the hard-coded verifiers to ensure reproducibility, audibility, and sensitivity to fine-grained success conditions. 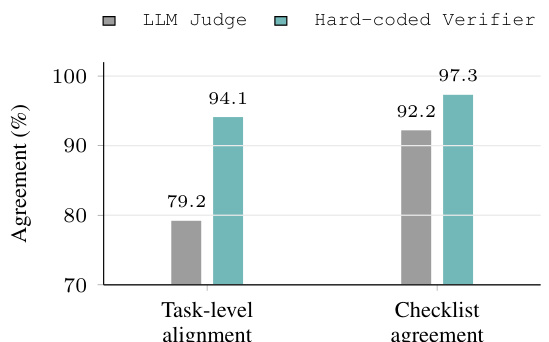
Experiment
The evaluation setup isolates agents in fresh sandboxes to interact with live desktop applications via a screenshot-action loop, employing hard-coded checkers to measure both exact completion and partial progress across a diverse task suite. Experiments validate that while current frontier models achieve substantial partial success, reliable end-to-end task completion remains challenging, with top performers excelling through action consolidation and streamlined reasoning. Comparative analyses demonstrate that programmatic verification significantly outperforms LLM-based judging in aligning with human judgments, particularly in dense or terminal-heavy environments where visual cues can be misleading. Finally, the study confirms that graphical interfaces yield higher task completion rates through superior visual grounding, whereas command-line approaches provide marked execution efficiency, and a self-evolving verification layer effectively enhances evaluator reliability by automatically correcting checker errors.
The authors analyze the effectiveness of a self-evolving verification process that improves the reliability of task checkers by identifying and repairing errors in the verification logic. The process updates checker queries to better match the intended criteria, such as changing the database source for tag existence and improving the join condition for image-tag assignment. This results in higher agreement between human evaluations and automated checkers, indicating improved verification accuracy. The self-evolving verification process repairs checker-side errors by updating the logic used to validate tasks. Checker queries are modified to use more accurate data sources and join conditions, improving validation precision. The process increases agreement between human and automated evaluations, indicating improved verification reliability.
The authors evaluate multiple computer-use agents on a benchmark that tests their ability to complete tasks in diverse desktop applications, using a verifier-based reward system to measure both full success and partial progress. Results show that the strongest models achieve high average rewards but still fail to complete a significant fraction of tasks, with performance varying widely across models and efficiency differences observed in interaction steps and time per step. GPT-5.4 achieves the highest success rate and average reward among the evaluated models, but still fails to complete nearly one-third of the tasks. Performance varies significantly across models, with open-source models showing much lower success rates compared to frontier models. The most capable model is also the most efficient in terms of interaction steps, completing tasks in fewer steps than other models.
The authors evaluate the effectiveness of a self-evolving verification procedure by measuring its ability to identify and repair checker-side errors in a benchmark. Results show that the procedure successfully fixes the majority of errors within a limited number of iterations, significantly improving agreement between the verifier and human judgment. The process demonstrates high efficiency in resolving issues with minimal computational overhead. The self-evolving verification procedure repairs most checker-side errors within a single iteration. The method significantly improves alignment between automated verification and human judgment. The majority of errors are resolved quickly, with only a small fraction requiring the full repair budget.
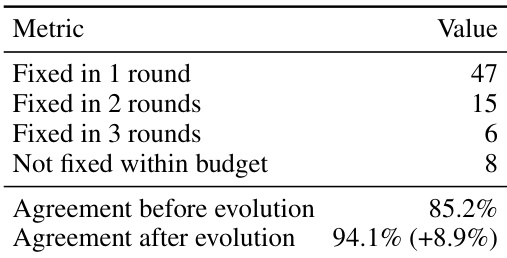
The authors evaluate a self-evolving verification process by measuring how often it can repair checker-side errors in task verification. The process is applied to a set of calibration tasks, and the results show that the majority of discrepancies between the programmatic checker and reference evaluation are resolved after one or two iterations. After evolution, the verifier achieves higher agreement with human judgments, indicating improved reliability. The self-evolving verification process repairs most checker-side errors within a few iterations. The programmatic verifier achieves higher alignment with human judgments after evolution. The majority of discrepancies between the programmatic checker and reference evaluation are resolved through self-evolution.

The authors compare the performance of GUI and CLI agents on a shared subset of tasks within the OpenComputer benchmark. Results show that GUI agents achieve higher success rates than the CLI agent, indicating that visual interaction provides useful grounding for desktop workflows. However, the CLI agent is significantly faster in terms of execution time, reflecting the efficiency advantage of command-line execution over screenshot-action loops. GUI agents achieve higher success rates than the CLI agent on a shared task subset. The CLI agent completes tasks much faster than the GUI agents, demonstrating efficiency advantages of command-line execution. Despite lower success rates, the CLI agent's performance suggests that task completion is possible through programmatic interfaces, even when visual grounding is absent.

The experiments evaluate computer-use agents on desktop task benchmarks to assess their task completion capabilities and efficiency, while also introducing a self-evolving verification process to validate and repair programmatic checker errors. The verification procedure successfully resolves most validation discrepancies within one or two iterations, substantially improving alignment between automated scoring and human judgment with minimal computational overhead. Agent evaluations reveal that while top-performing models achieve high success rates and efficiency, they still struggle to complete a significant portion of tasks, with frontier models consistently outperforming open-source alternatives. Finally, comparing interaction modalities demonstrates that GUI-based agents achieve higher completion rates through visual grounding, whereas CLI-based agents execute tasks significantly faster.