HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

FashionChameleon: Auf Echtzeit- und interaktive Mensch-Kleidungs-Videobearbeitung zusteuern

CiteVQA: Benchmarking der Evidenzzuschreibung für vertrauenswürdige Dokumentenintelligenz

























FashionChameleon: Auf Echtzeit- und interaktive Mensch-Kleidungs-Videobearbeitung zusteuern
CiteVQA: Benchmarking der Evidenzzuschreibung für vertrauenswürdige Dokumentenintelligenz
MMSkills: Auf dem Weg zu multimodalen Fähigkeiten für allgemeine visuelle Agenten
PhysBrain 1.0 Technischer Bericht
Zurück zu den Wertmodellen: Generative Kritiker für die Wertmodellierung in der Verstärkungslernmethode von LLMs
NEXUS: Ein Agentenframework für die Zeitreihenvorhersage
MemEye: Ein visuell-zentriertes Bewertungsframework für Multimodal-Agent-Gedächtnis
SANA-WM: Effizientes Weltmodellieren im Minutenbereich mit hybridem linearem Diffusions-Transformer
MemLens: Benchmarking multimodaler Langzeitgedächtnis in großen Vision-Sprache-Modellen
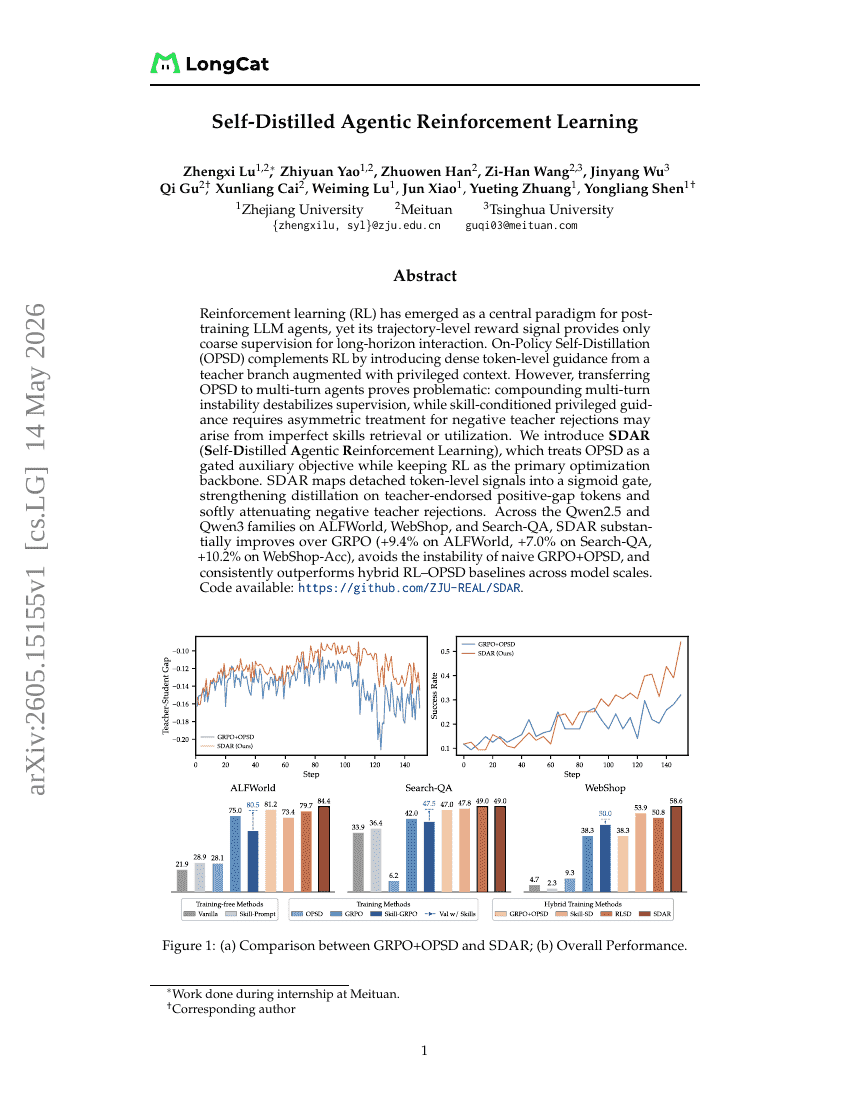
Selbstdistillierte agentic Verstärkungslernen
Kausales Erzwingen++: Skalierbare autoregressive Diffusionsdistillation mit wenigen Schritten für die Echtzeit-Interaktive Videoerstellung
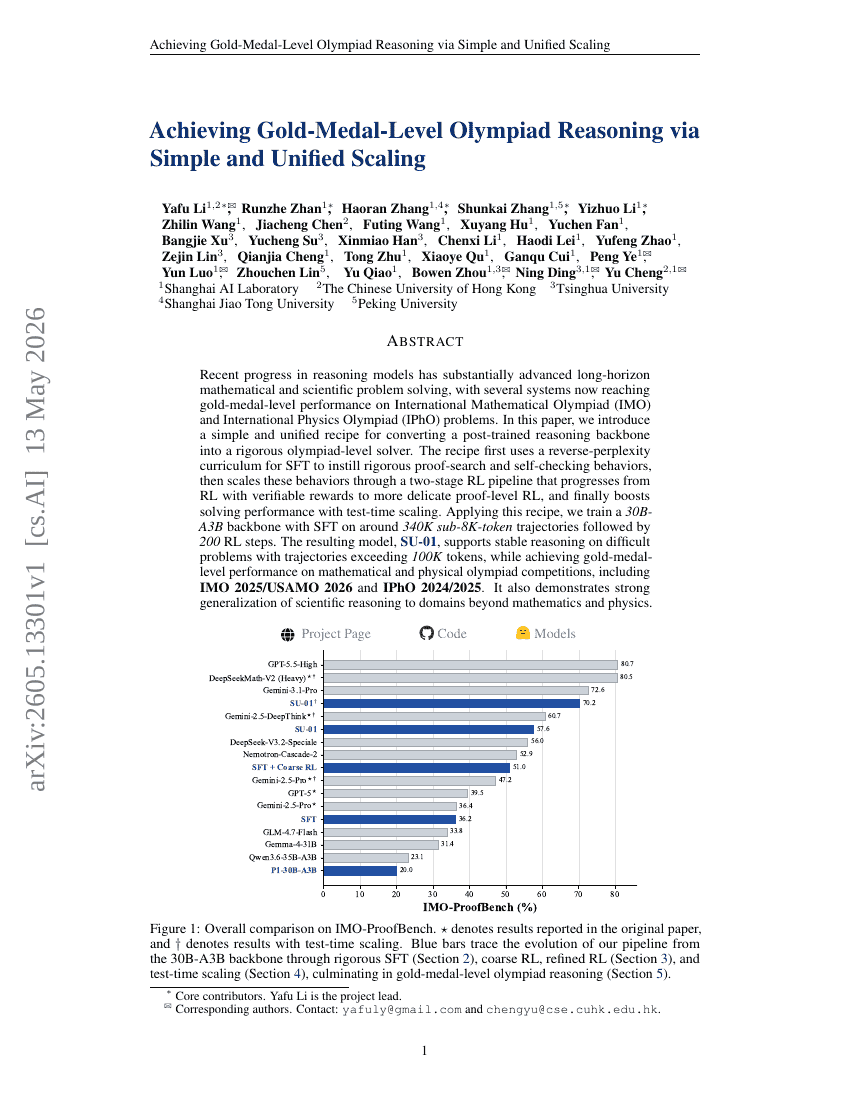
Erreichen von Goldmedaillen-Niveau bei Olympiaden-Reasoning durch einfaches und einheitliches Skalieren
RepoZero: Können LLMs ein Code-Repository von Grund auf erzeugen?
Qwen-Image-VAE-2.0 Technischer Bericht
Vorhersage von Entscheidungen von KI-Agents aus begrenzter Interaktion durch Text-Tabellarische Modellierung
Training von Lang-Kontext-Vision-Language-Modellen effektiv mit Verallgemeinerung über 128K Kontext hinaus
AnyFlow: Any-Step-Video-Diffusionsmodell mit On-Policy-Flow-Map-Distillation
MinT: Verwaltete Infrastruktur für das Training und den Betrieb von Millionen von LLMs
MulTaBench: Benchmarking multimodaler tabellarischer Lernverfahren mit Text und Bild
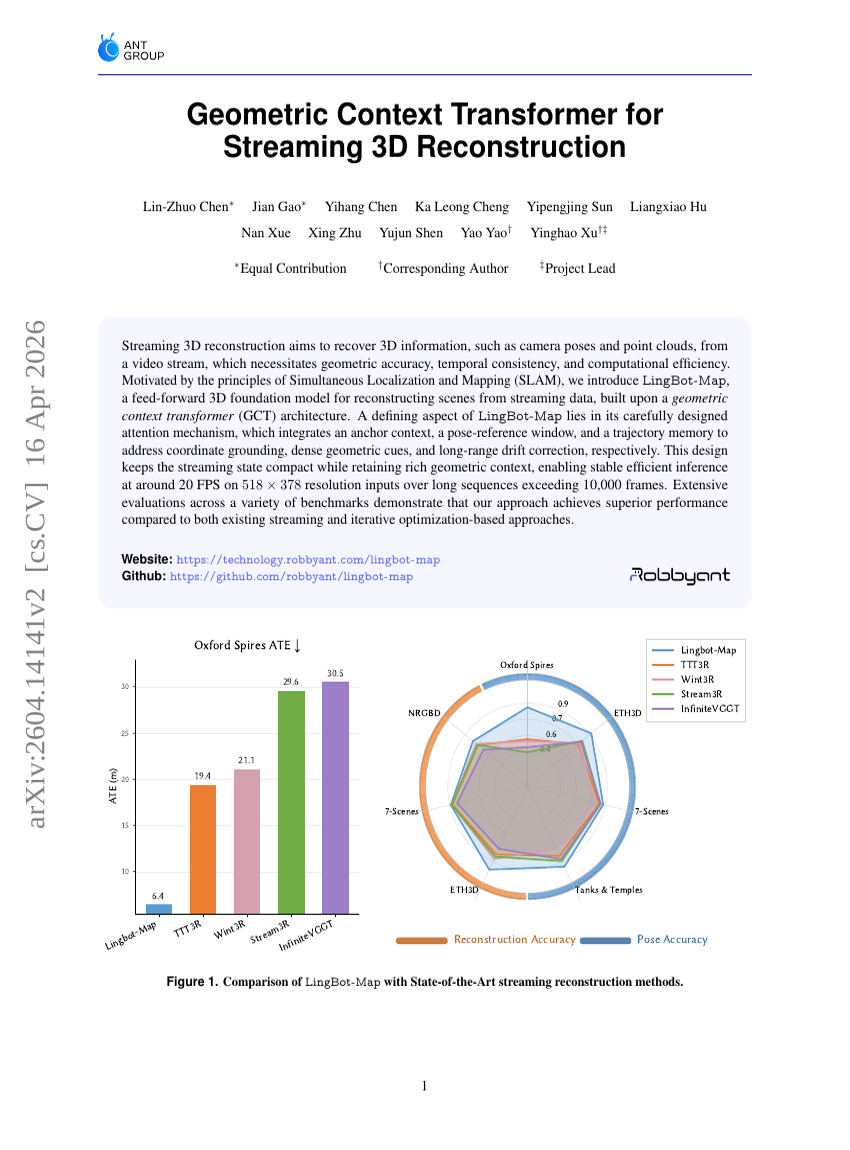
Geometrischer Kontext-Transformer für die Streaming-3D-Rekonstruktion
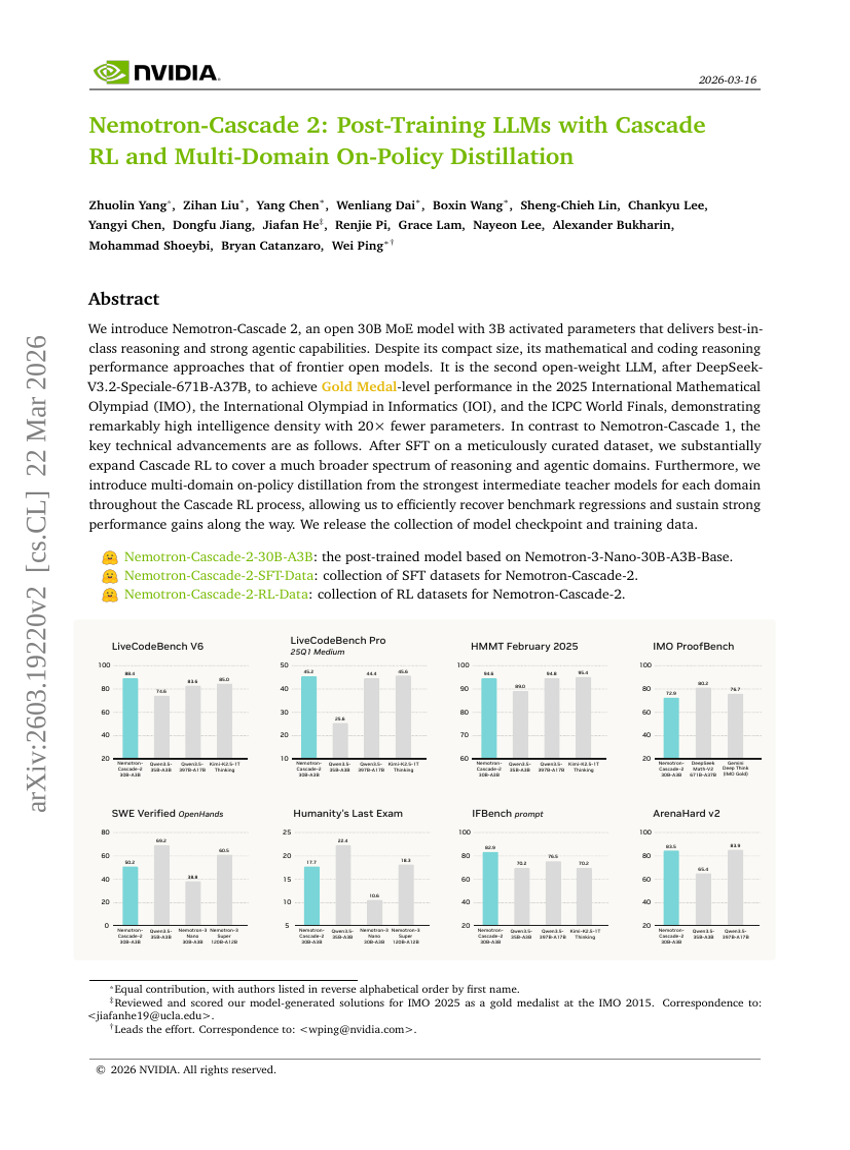
Nemotron-Cascade 2: Post-Training von LLMs mit Cascade RL und Multi-Domain On-Policy Distillation
Technischer Bericht zu MOSS-TTS
StreakMind: KI-basierte Erkennung und Analyse von Satellitenspuren in astronomischen Bildern mit automatisierter Datenbankintegration
VibeServe: Können KI-Agenten maßgeschneiderte LLM-Bereitstellungssysteme aufbauen?
Delta-Mem: Effizienter Online-Speicher für große Sprachmodelle
MCP-Cosmos: Weltmodell-verstärkte Agenten für die Ausführung komplexer Aufgaben in MCP-Umgebungen
Jenseits des Reasonings: Reinforcement Learning erschließt parametrisches Wissen in LLMs
Verzerrungsfreie modellbasierte Repräsentationen für stichprobeneffiziente kontinuierliche Steuerung
Multi-Stream-LLMs: Entblocken von Sprachmodellen mit parallelen Strömen von Gedanken, Eingaben und Ausgaben
Ihr Sprachmodell ist sein eigener Kritiker: Verstärkungslernen mit Werteschätzung aus den internen Zuständen des Akteurs
Relit-LiVE: Beleuchtung von Videos durch gemeinsames Lernen von Umgebungs-Videos
Positive Ausrichtung: Künstliche Intelligenz für das menschliche Gedeihen
MMSkills: Auf dem Weg zu multimodalen Fähigkeiten für allgemeine visuelle Agenten
PhysBrain 1.0 Technischer Bericht
Zurück zu den Wertmodellen: Generative Kritiker für die Wertmodellierung in der Verstärkungslernmethode von LLMs
NEXUS: Ein Agentenframework für die Zeitreihenvorhersage
MemEye: Ein visuell-zentriertes Bewertungsframework für Multimodal-Agent-Gedächtnis
SANA-WM: Effizientes Weltmodellieren im Minutenbereich mit hybridem linearem Diffusions-Transformer
MemLens: Benchmarking multimodaler Langzeitgedächtnis in großen Vision-Sprache-Modellen
Selbstdistillierte agentic Verstärkungslernen
Kausales Erzwingen++: Skalierbare autoregressive Diffusionsdistillation mit wenigen Schritten für die Echtzeit-Interaktive Videoerstellung
Erreichen von Goldmedaillen-Niveau bei Olympiaden-Reasoning durch einfaches und einheitliches Skalieren
RepoZero: Können LLMs ein Code-Repository von Grund auf erzeugen?
Qwen-Image-VAE-2.0 Technischer Bericht
Vorhersage von Entscheidungen von KI-Agents aus begrenzter Interaktion durch Text-Tabellarische Modellierung
Training von Lang-Kontext-Vision-Language-Modellen effektiv mit Verallgemeinerung über 128K Kontext hinaus
AnyFlow: Any-Step-Video-Diffusionsmodell mit On-Policy-Flow-Map-Distillation
MinT: Verwaltete Infrastruktur für das Training und den Betrieb von Millionen von LLMs
MulTaBench: Benchmarking multimodaler tabellarischer Lernverfahren mit Text und Bild
Geometrischer Kontext-Transformer für die Streaming-3D-Rekonstruktion
Nemotron-Cascade 2: Post-Training von LLMs mit Cascade RL und Multi-Domain On-Policy Distillation
Technischer Bericht zu MOSS-TTS
StreakMind: KI-basierte Erkennung und Analyse von Satellitenspuren in astronomischen Bildern mit automatisierter Datenbankintegration
VibeServe: Können KI-Agenten maßgeschneiderte LLM-Bereitstellungssysteme aufbauen?
Delta-Mem: Effizienter Online-Speicher für große Sprachmodelle
MCP-Cosmos: Weltmodell-verstärkte Agenten für die Ausführung komplexer Aufgaben in MCP-Umgebungen
Jenseits des Reasonings: Reinforcement Learning erschließt parametrisches Wissen in LLMs
Verzerrungsfreie modellbasierte Repräsentationen für stichprobeneffiziente kontinuierliche Steuerung
Multi-Stream-LLMs: Entblocken von Sprachmodellen mit parallelen Strömen von Gedanken, Eingaben und Ausgaben
Ihr Sprachmodell ist sein eigener Kritiker: Verstärkungslernen mit Werteschätzung aus den internen Zuständen des Akteurs
Relit-LiVE: Beleuchtung von Videos durch gemeinsames Lernen von Umgebungs-Videos
Positive Ausrichtung: Künstliche Intelligenz für das menschliche Gedeihen