Command Palette
Search for a command to run...
Gezielte Neuronenmodulation durch Suche nach kontrastiven Paaren
Gezielte Neuronenmodulation durch Suche nach kontrastiven Paaren
Sam Herring Jake Naviasky Karan Malhotra
Zusammenfassung
Sprachmodelle werden durch Instruction Tuning so angepasst, dass sie schädliche Anfragen ablehnen; die zugrunde liegenden Mechanismen dieses Verhaltens sind jedoch nur unzureichend verstanden. Beliebte Steuerungsmethoden (Steering Methods) wirken auf dem Residual Stream und verschlechtern die Kohärenz der Ausgabe bei hohen Interventionsstärken, was ihre praktische Anwendbarkeit einschränkt. Wir stellen die kontrastive Neuronenattributierung (Contrastive Neuron Attribution, CNA) vor, die jene 0,1 % der MLP-Neuronen identifiziert, deren Aktivierungen schädliche von harmlosen Prompts am deutlichsten unterscheiden. Dies erfordert lediglich Forward-Passes ohne Gradienten oder zusätzliches Training. Beim Abschalten (Ablation) der gefundenen Schaltung in Instruct-Modellen sinken die Ablehnungsraten auf einem gängigen Jailbreak-Benchmark um mehr als 50 %, während die Sprachflüssigkeit und Nicht-Entartung (Non-Degeneracy) über alle Steering-Stärken hinweg erhalten bleiben. Durch die Anwendung von CNA auf abgestimmte Base- und Instruct-Modelle der Architekturen Llama und Qwen (mit Größen von 1B bis 72B Parametern) stellen wir fest, dass Base-Modelle ähnliche Diskriminierungsstrukturen in den späteren Schichten aufweisen; eine Steuerung dieser Neuronen führt jedoch lediglich zu Verschiebungen im Inhalt und nicht zu einer Verhaltensänderung. Diese Ergebnisse zeigen, dass Interventionen auf Neuronenebene eine zuverlässige Verhaltenssteuerung ermöglichen, ohne die Qualitätskompromisse, die mit Residual-Stream-Methoden einhergehen. Darüber hinaus deuten unsere Befunde darauf hin, dass Alignment-Fine-Tuning die vorbestehende Diskriminierungsstruktur in einen sparsamen, gezielt ansteuerbaren Ablehnungsfilter (Refusal Gate) transformiert.
One-sentence Summary
The authors introduce Contrastive Neuron Attribution to identify the 0.1% of MLP neurons distinguishing harmful from benign prompts across Llama and Qwen architectures ranging from 1B to 72B parameters using only forward passes without gradients or auxiliary training, demonstrating that ablating this circuit in instruct models reduces refusal rates by over 50% on a standard jailbreak benchmark while preserving fluency and avoiding the coherence degradation of residual-stream methods, thereby suggesting that alignment fine-tuning transforms pre-existing discrimination structure into a sparse, targetable refusal gate.
Key Contributions
- The paper introduces contrastive neuron attribution (CNA), a technique that identifies the 0.1% of MLP neurons distinguishing harmful from benign prompts using only forward passes without gradients or auxiliary training. This method operates at the individual-neuron level rather than the residual stream to avoid the quality tradeoffs associated with residual-stream methods.
- Ablating the discovered circuit reduces refusal rates by over 50% on a standard jailbreak benchmark while preserving fluency and non-degeneracy across all steering strengths. These results demonstrate that neuron-level intervention enables reliable behavioral steering without the coherence degradation seen in residual-stream methods.
- Applying CNA across Llama and Qwen architectures reveals that base models contain similar late-layer discrimination structures that produce content shifts rather than behavioral changes when steered. These findings suggest that alignment fine-tuning transforms pre-existing discrimination structure into a sparse, targetable refusal gate.
Introduction
Modern language models rely on fine-tuning to refuse harmful requests, yet the mechanistic origin of this safety behavior remains unclear. Prior representation engineering methods steer behavior by modifying the entire residual stream, which is too coarse to isolate specific drivers, while sparse autoencoders require expensive training and struggle with noise. To address this, the authors introduce Contrastive Neuron Attribution, a technique that identifies a sparse subset of individual MLP neurons responsible for distinguishing harmful from benign prompts. Their experiments show that ablating just 0.1% of these neurons reduces refusal rates by over 50% across various model sizes without compromising output quality, demonstrating that safety circuits crystallize specifically during alignment fine-tuning.
Method
The authors leverage a method termed Contrastive Neuron Attribution (CNA) to identify specific behavioral circuits within language models. This approach focuses on isolating a sparse subset of neurons responsible for distinguishing between harmful and benign prompts without requiring gradient computations or auxiliary training. The overall framework operates through a process called contrastive discovery followed by a filtering stage to ensure robustness.
In the contrastive discovery phase, the method defines two distinct sets of prompts for a given task. One set consists of positive prompts that exhibit the target property, while the other comprises negative prompts that do not. The model processes all prompts through a forward pass, and the system records the MLP activations at the last token position. Specifically, the down projection of the MLP activations is captured for each task using forward pre-hooks. For a neuron j in layer ℓ, the activation on prompt x is denoted as ajℓ(x). The core calculation involves determining the mean contrastive difference between the positive and negative sets.
δjℓ=∣P+∣1x∈P+∑ajℓ(x) − ∣P−∣1x∈P−∑ajℓ(x)This metric quantifies how much a specific neuron activates differently depending on the prompt type. The authors then select the circuit Ck by taking the top k neurons with the highest absolute difference values across all layers. The value of k is set to 0.1% of the total MLP activations, a threshold found to reliably produce steering effects across various model sizes. This selection process interprets contrastive attribution at the neuron level rather than the residual stream level, relying solely on forward pass comparisons.
To refine the discovered circuit, the method incorporates a universal neuron filtering step. Some neurons tend to fire regardless of the specific prompt content, which could introduce noise into the steering mechanism. The system detects these by running diverse prompts and flagging any neuron that appears in the top 0.1% of MLP activations for at least 80% of the prompts. These universal neurons are excluded from all discovered neuron subsets to ensure the identified circuit specifically relates to the target behavior.
Experiment
This study evaluates neuron-level ablation across various Llama and Qwen architectures to verify causal links between specific activations and refusal behaviors. Experiments demonstrate that targeting a sparse subset of MLP activations effectively reduces refusal rates while maintaining generation coherence, whereas residual-stream steering methods degrade output quality at high intervention strengths. Additionally, comparisons between base and instruct models reveal that alignment fine-tuning transforms pre-existing late-layer discrimination structures into functional safety gates without changing the underlying network architecture.
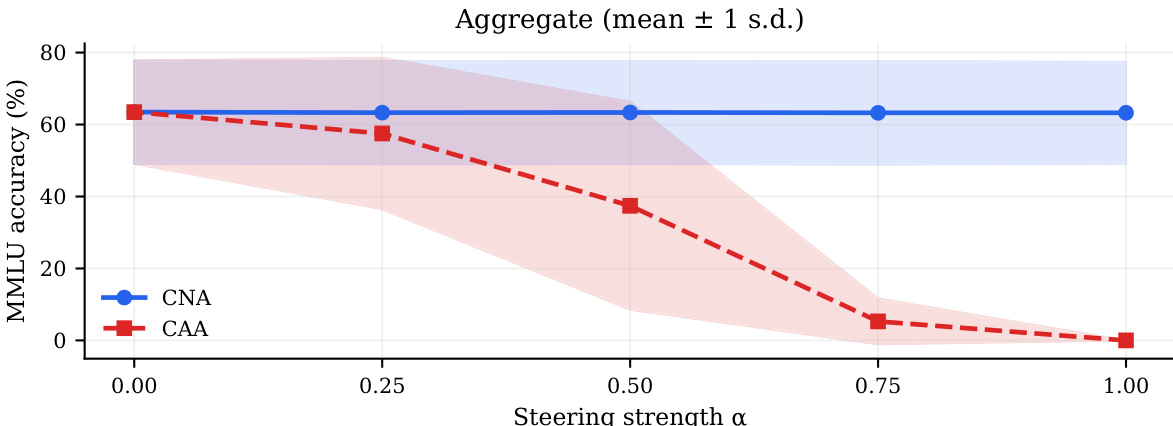
The authors compare neuron-level ablation against residual-stream steering methods to evaluate their impact on refusal behavior and output quality. The data demonstrates that the ablation method consistently lowers refusal rates while maintaining near-baseline generation quality across all model sizes. Conversely, the residual-stream method often causes significant quality degradation, leading to repetitive or incoherent responses at maximum intervention levels. Neuron-level ablation effectively reduces refusal rates while preserving high generation quality. Residual-stream steering methods often degrade output coherence and cause repetitive text at high strengths. The ablation technique remains stable across different model architectures and parameter scales.
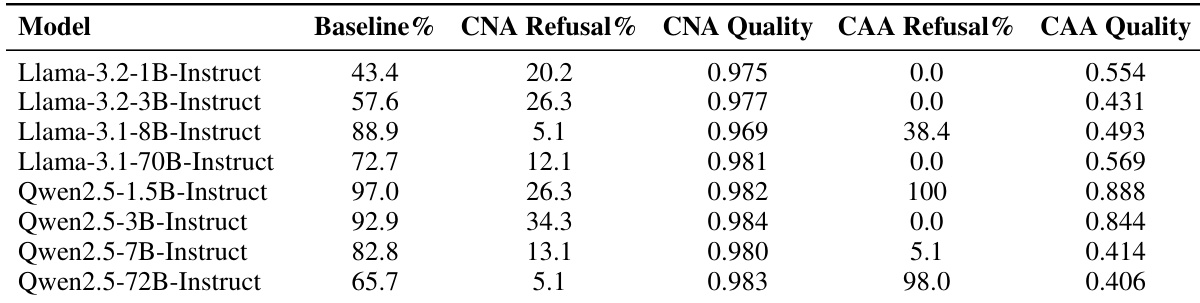
The the the table compares the performance of CNA and CAA intervention methods across various Llama and Qwen models, focusing on refusal rates and output quality. Results show that while both methods reduce baseline refusal rates, CNA generally maintains higher output quality compared to CAA. This trend suggests that CNA is more effective at steering model behavior without degrading generation coherence. CNA generally yields higher quality scores than CAA across the majority of tested models. Both intervention methods successfully lower refusal rates compared to baseline performance. The quality advantage of CNA is particularly evident in larger parameter models.
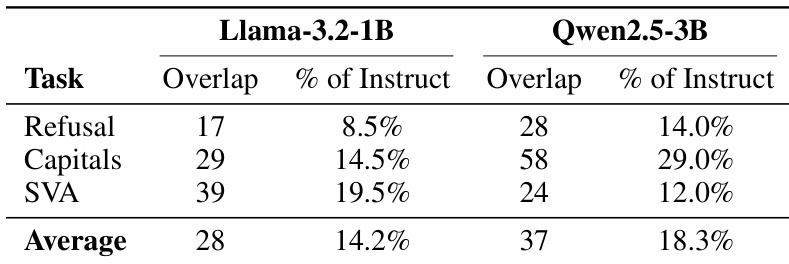
The the the table analyzes the overlap of top neurons between base and instruct model variants for tasks involving refusal, capitalization, and subject-verb agreement. Results indicate that instruction tuning replaces the majority of specific neurons identified in base models, with only a small portion of the circuitry remaining consistent. Overlap between base and instruct neuron circuits is consistently low across all tasks and model architectures. The Qwen model demonstrates a higher average overlap of neurons compared to the Llama model. Tasks related to capitalization show greater neuron retention from the base model than refusal tasks in both architectures.
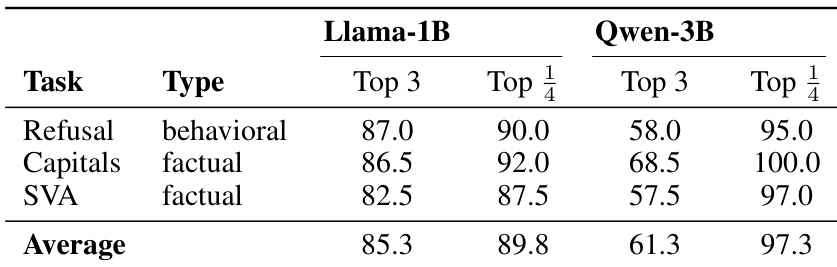
The experiment analyzes the spatial distribution of discrimination circuits within Llama-1B and Qwen-3B models across refusal, factual capitalization, and subject-verb agreement tasks. Data indicates that these functional circuits are heavily localized in the late layers of the network architecture. This concentration is particularly pronounced within the final quarter of the layers for both model families. Discrimination circuits for behavioral and factual tasks consistently localize in the late layers of the network. The final quarter of layers contains the vast majority of top discrimination neurons across all tested tasks and models. Llama models exhibit a higher density of these circuits in the final three layers compared to Qwen models.
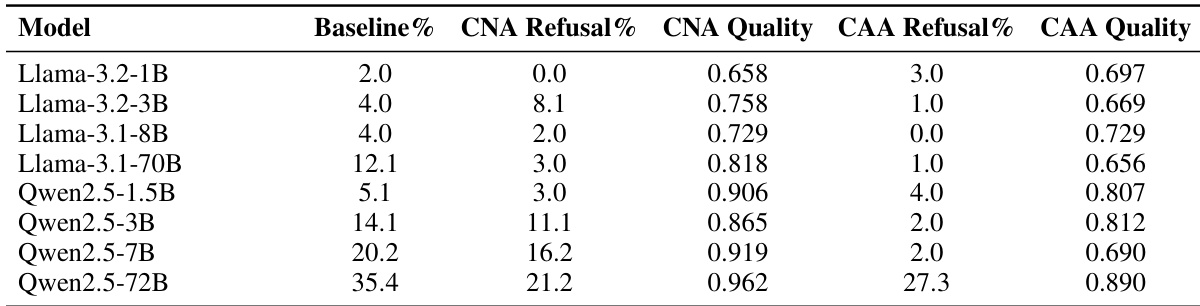
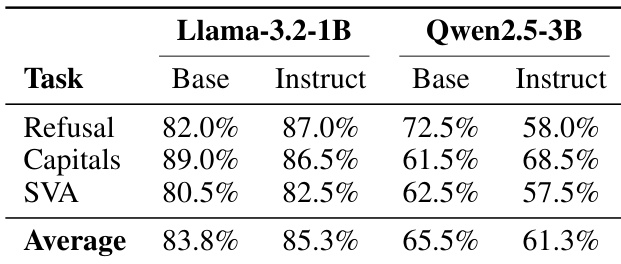
The the the table compares the performance of Base and Instruct variants of Llama-3.2-1B and Qwen2.5-3B models across Refusal, Capitals, and Subject-Verb Agreement (SVA) tasks. Results indicate that fine-tuning (Instruct) leads to higher refusal rates and average performance for Llama-3.2-1B, whereas Qwen2.5-3B shows lower refusal rates and average performance in the Instruct variant. Task-specific capabilities like Capitals and SVA exhibit mixed improvements or declines depending on the model architecture. Llama-3.2-1B Instruct model achieves higher refusal rates and average scores compared to its Base variant. Qwen2.5-3B Instruct model demonstrates lower refusal rates and average scores compared to its Base variant. Performance on general capabilities such as Capitals and SVA varies between Base and Instruct models across the two architectures.
The experiments compare neuron-level ablation against residual-stream steering, finding that ablation consistently lowers refusal rates while maintaining high generation quality across model sizes. Analysis reveals that discrimination circuits concentrate in the late network layers and instruction tuning largely replaces base model neurons, though retention varies by task. Additionally, comparisons between Base and Instruct variants demonstrate architecture-specific variations in refusal behavior and general task performance.