Command Palette
Search for a command to run...
AutoResearchClaw: Selbstverstärkende autonome Forschung mit Mensch-KI-Zusammenarbeit
AutoResearchClaw: Selbstverstärkende autonome Forschung mit Mensch-KI-Zusammenarbeit
Zusammenfassung
Titel:Abstract: Die Automatisierung wissenschaftlicher Entdeckungen erfordert mehr als die Generierung von Forschungsartikeln aus Ideen. Echte Forschung ist iterativ: Hypothesen werden aus verschiedenen Perspektiven hinterfragt, Experimente scheitern und liefern Erkenntnisse für den nächsten Versuch, und Erkenntnisse akkumulieren sich über die Zyklen hinweg. Bestehende autonome Forschungssysteme modellieren diesen Prozess häufig als lineare Pipeline: Sie stützen sich auf die reasoning (Schlussfolgerung) einzelner agenten, stoppen bei Ausführungsfehlern und übertragen keine Erfahrungen über verschiedene Durchläufe hinweg. Wir präsentieren AutoResearchClaw, eine multi-agent autonome Forschungs-Pipeline, die auf fünf Mechanismen basiert: strukturierte multi-agent Debatten zur Hypothesengenerierung und Ergebnisanalyse, einen selbstheilenden Executor mit einer Pivot/Refine-Entscheidungsschleife, die Fehler in Informationen umwandelt, überprüfbare Ergebnisberichte, die erfundene Zahlen und halluzinierte Zitationen verhindern, human-in-the-loop-Kollaboration mit sieben Interventionsmodi, die von vollständiger Autonomie bis hin zur schrittweisen Aufsicht reichen, und cross-run Evolution, die vergangene Fehler in zukünftige Schutzmaßnahmen umwandelt. Auf ARC-Bench, einem Benchmark für Experimentstadien mit 25 Themen, schlägt AutoResearchClaw AI Scientist v2 um 54,7 %. Eine human-in-the-loop-Ablation über sieben Interventionsmodi zeigt, dass präzise, gezielte Kollaboration an entscheidenden Hebelstellen konsistent besser abschneidet als sowohl vollständige Autonomie als auch exhaustive schrittweise Aufsicht. Wir positionieren AutoResearchClaw als Forschungsverstärker, der die menschliche wissenschaftliche Urteilsfähigkeit ergänzt, anstatt sie zu ersetzen. Der Code ist verfügbar unter https://github.com/aiming-lab/AutoResearchClaw.
One-sentence Summary
The authors propose AUTOResearchCLAW, a multi-agent autonomous research pipeline that iteratively advances scientific inquiry through structured multi-agent debate, a self-healing PIVOT/Refine executor that transforms execution failures into information, and cross-run evolution that converts past mistakes into future safeguards, ultimately outperforming AI Scientist v2 by 54.7% on the 25-topic ARC-Bench benchmark while demonstrating that targeted human-in-the-loop collaboration across seven intervention modes consistently surpasses both fully autonomous and exhaustive oversight modes.
Key Contributions
- The paper introduces AUTOResearchCLAW, a multi-agent autonomous research pipeline that replaces linear single-agent workflows with structured debate, a self-healing executor utilizing a PIVOT/Refine decision loop, and a cross-run evolution store. This architecture converts execution failures into persistent safeguards while preventing fabricated results through verifiable reporting mechanisms.
- Comprehensive evaluation on ARC-Bench, a 25-topic experiment-stage benchmark, demonstrates that the framework outperforms AI Scientist v2 by 54.7%. The performance gain validates the combined effectiveness of multi-agent collaboration and verifiable result reporting in end-to-end scientific discovery.
- A systematic ablation across seven human-in-the-loop intervention modes reveals that targeted human collaboration at high-leverage decision points consistently outperforms both full autonomy and exhaustive step-by-step oversight. This empirical insight positions the system as a research amplifier that optimally balances automated execution with strategic human judgment.
Introduction
Automating scientific discovery requires computational systems that can navigate the iterative nature of real research, where hypotheses are stress-tested, experiments frequently fail, and insights must accumulate across cycles. Prior autonomous research frameworks fall short because they model discovery as a linear pipeline. These systems typically rely on single-agent reasoning that struggles to identify flawed assumptions, halt execution entirely when code breaks, and reset to zero after each run without retaining learned strategies. The authors address these gaps by introducing AUTOResearchCLAW, a multi-agent pipeline that deploys structured role-based debate to strengthen hypothesis generation, a self-healing executor that transforms execution failures into strategic pivots, and a cross-run evolution module that injects historical lessons into future attempts. By anchoring outputs with strict verification protocols and enabling flexible human-in-the-loop oversight, the framework demonstrates that targeted human intervention at high-leverage decision points consistently outperforms both fully autonomous and exhaustively supervised workflows.
Dataset
-
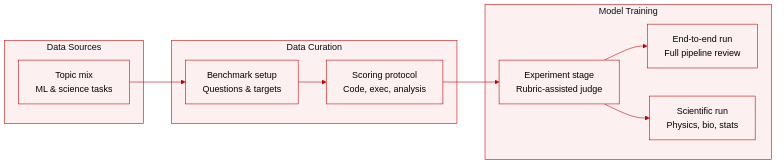
Dataset Composition and Sources: The authors introduce ARC-Bench, a structured benchmark comprising 25 machine learning topics and a 20-topic scientific extension. The ML subset covers areas such as tabular optimization, dimensionality reduction, NLP, AutoML, and causal discovery. The scientific extension includes 10 high-energy physics, 7 systems biology, and 3 statistics tasks. Each topic is paired with a research question, a target dataset or simulation reference, and explicit deliverable requirements including code, results, and analysis writeups.
-
Key Subset Details: The benchmark is divided into a primary 25-topic ML track and a 20-topic science track. Topics are sourced from established academic domains and are defined by their specific research questions and target data references. No manual filtering rules are applied, but the structured organization ensures comprehensive coverage across diverse algorithmic and scientific challenges.
-
Usage and Processing Pipeline: The authors use ARC-Bench as an evaluation framework rather than a training corpus. They deploy three distinct assessment modes. The experiment-stage mode tests system performance using a rubric-assisted judge. The end-to-end mode evaluates the complete research pipeline and final paper quality, which the authors apply to a 10-topic human-in-the-loop ablation study and a scientific domain coverage analysis. The scientific mode reuses the same rubric for the physics, biology, and statistics tasks. All competing systems are processed using an identical LLM backbone and sandboxed environment with uniform execution time budgets to isolate architectural contributions.
-
Judging and Evaluation Details: The authors implement a strict grading protocol that scores each system-topic pairing across three dimensions: Code Development, Code Execution, and Result Analysis, weighted at a 25:25:50 ratio. Two independent agent reviewers evaluate submissions in parallel. Score disagreements exceeding 0.20 trigger a re-adjudication step before final scores are averaged. The pipeline heavily weights Result Analysis to capture scientific reasoning quality, and the controlled execution environment ensures consistent processing and fair comparison across all baseline systems.
Method
The authors leverage a 23-stage pipeline organized into three primary phases—Discovery, Experimentation, and Writing—to structure the AUTOResearchClaw system, with five overarching mechanisms spanning all stages. The framework begins with Phase 1: Discovery, which includes research scoping and multi-agent hypothesis generation. This phase transitions into Phase 2: Experimentation, where code is generated and executed under a self-healing execution model, and decisions regarding proceeding, refining, or pivoting are made autonomously. Finally, Phase 3: Writing involves drafting, multi-agent review, revision, and citation verification. Each stage adheres to a formal input/output contract and supports checkpoint-based resumption, enabling robust recovery and continuity across runs.
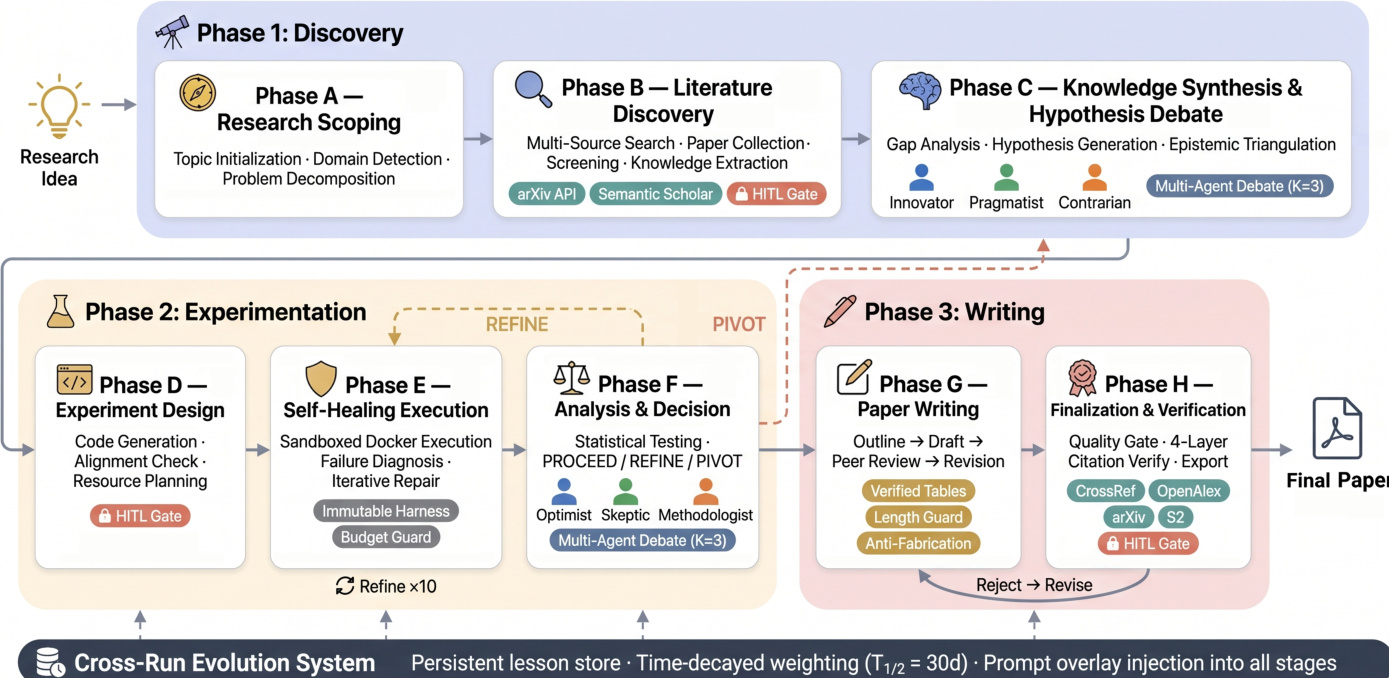
As shown in the figure below, the pipeline is divided into distinct phases, each with specialized modules. Phase A, Research Scoping, initiates the process with topic initialization, domain detection, and problem decomposition. Phase B, Literature Discovery, involves multi-source search, paper collection, and screening, supported by a Semantic Scholar API and an arXiv API. Phase C, Knowledge Synthesis & Hypothesis Debate, synthesizes findings into hypotheses through a multi-agent debate involving an Innovator, Pragmatist, and Contrarian, with a synthesizer integrating their outputs into falsifiable hypotheses.
Phase D, Experiment Design, generates code and performs alignment checks and resource planning, while Phase E, Self-Healing Execution, manages sandboxed Docker execution, failure diagnosis, and iterative repair. This phase includes a mutable harness and a budget guard, with a mechanism for refining experiments up to ten times. Phase F, Analysis & Decision, conducts statistical testing and makes decisions to proceed, refine, or pivot, guided by a second multi-agent debate involving an Optimist, Skeptic, and Methodologist. Phase G, Paper Writing, produces an outline, drafts, and revises the paper, supported by verified tables, length guards, and anti-fabrication checks. Phase H, Finalization & Verification, performs quality gates, citation verification via CrossRef, OpenAlex, arXiv, and Semantic Scholar, and exports the final paper.
The system incorporates a persistent lesson store, enabling cross-run evolution. At the end of each run, structured lessons are extracted from repair attempts, PIVOT/REFINE decisions, HITL feedback, and verification results. These lessons are stored with a severity score s(l)∈(0,1] and a recommended mitigation. When a new run begins, relevant lessons are retrieved by category and ranked using a time-decayed weight formula:
w(l)=s(l)⋅exp(−ln2⋅T1/2Δt),where Δt is the elapsed time since the lesson was recorded and T1/2 is the half-life hyperparameter, set to 30 days by default. Lessons are injected into prompts as natural-language overlays, requiring no model retraining and remaining applicable to any LLM backbone.

Experiment
The evaluation employs an experiment-stage benchmark, an end-to-end assessment across seven human-in-the-loop regimes, a component ablation study, and a detailed case study to validate the system's architectural mechanisms and collaboration strategies. The benchmark and ablation experiments demonstrate that multi-agent debate and result verification significantly enhance analytical rigor and scientific integrity, while self-healing execution ensures robust pipeline completion. The end-to-end and case studies reveal that targeted human intervention at high-leverage decision points consistently outperforms both full autonomy and exhaustive oversight, establishing precise human-AI collaboration as the optimal operating paradigm. Ultimately, the framework proves to be a reliable research amplifier that accelerates scientific exploration while maintaining verifiability and requiring expert judgment.
The authors evaluate AUTOResearchClaw against existing systems on ARC-Bench, showing that it outperforms baselines across all dimensions, particularly in result analysis and overall quality. The results highlight that the system's design, including multi-agent debate and self-healing execution, drives its superior performance, even without human intervention. Targeted human-in-the-loop guidance at key decision points further enhances paper quality and acceptance rates compared to both full automation and exhaustive supervision. AUTOResearchClaw achieves higher performance than all baselines across all evaluation dimensions, with the largest gains in result analysis. The system outperforms baselines even in full-auto mode, indicating that its improvements stem from internal mechanisms rather than human input. Targeted human intervention at high-leverage points significantly boosts paper quality and acceptance rates compared to both full automation and step-by-step oversight.

The authors conduct an end-to-end evaluation of AUTOResearchClaw across multiple intervention regimes, assessing paper quality and completion rates. Results show that targeted human intervention at key decision points significantly improves outcomes compared to both full automation and exhaustive step-by-step oversight, with the CoPilot mode achieving the highest acceptance rate and quality score. CoPilot achieves the highest acceptance rate and mean quality score among all evaluated modes. More intervention does not improve quality; targeted human guidance at high-leverage points outperforms both full automation and exhaustive oversight. Gate-Only mode provides a cost-effective balance, improving acceptance rates with minimal interventions.
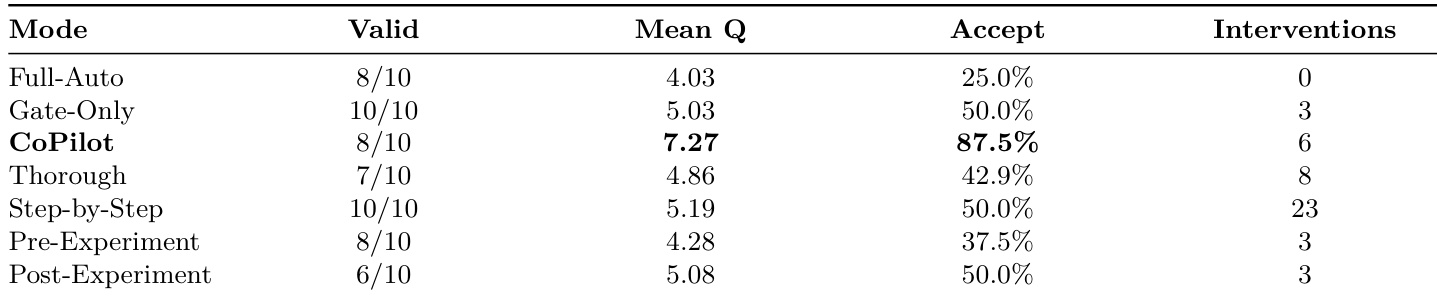
{"summary": "The authors evaluate AUTOResearchClaw through multiple studies, including an experiment-stage comparison, end-to-end human-in-the-loop ablation, and component ablation. Results show that AUTOResearchClaw outperforms existing systems across all dimensions, with the largest gains observed in result analysis, where multi-agent debate and verified reporting significantly improve conclusion quality. The framework achieves higher paper quality and acceptance rates with targeted human intervention compared to both full automation and exhaustive oversight.", "highlights": ["AUTOResearchClaw outperforms all baselines in experiment-stage evaluation, particularly in result analysis, due to multi-agent debate and verified result reporting.", "Targeted human intervention at high-leverage decision points achieves the highest paper quality and acceptance rates, surpassing both full automation and step-by-step oversight.", "Component ablation reveals that debate, self-healing, and verification are complementary mechanisms, with their combined removal leading to a super-additive drop in performance."]

The authors evaluate AUTOResearchClaw against existing systems through multiple experiments, including an experiment-stage comparison, an end-to-end human-in-the-loop ablation, and a component ablation. Results show that AUTOResearchClaw outperforms all baselines across key dimensions, particularly in result analysis and overall paper quality, with the highest accept rate under targeted human intervention. The system's effectiveness is attributed to complementary mechanisms such as multi-agent debate, self-healing execution, and verification, which together enable higher-quality, more reliable research outputs. AUTOResearchClaw achieves the highest performance in result analysis and overall paper quality compared to all baselines, especially under targeted human intervention. The system's success is driven by a combination of mechanisms including multi-agent debate, self-healing execution, and verification, which are essential for both quality and completion. Targeted human intervention at high-leverage decision points significantly improves paper quality and accept rates, outperforming both full automation and exhaustive step-by-step oversight.
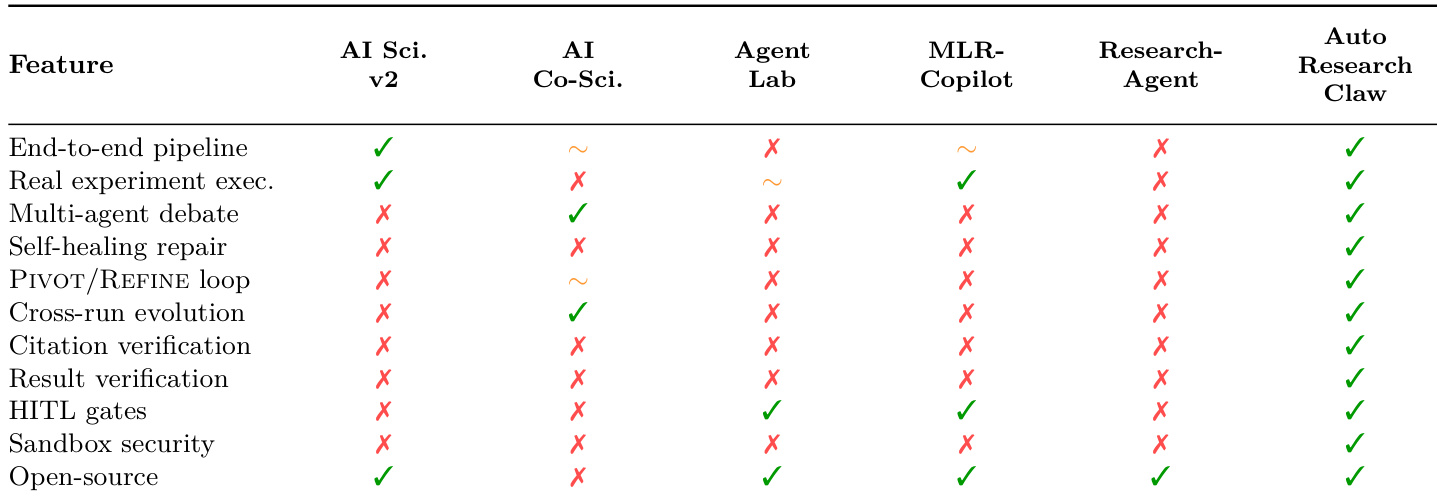
The authors conduct a component ablation study to isolate the contributions of different mechanisms in AUTOResearchClaw, evaluating their impact on completion, quality, acceptability, and fabrication. Results show that debate and self-healing are critical for high-quality and complete outputs, while verification prevents fabricated results but reduces acceptance when strict criteria are applied. The mechanisms interact in a super-additive manner, where removing multiple components leads to a significant drop in performance. Debate and self-healing are essential for achieving high completion and quality, with their removal causing substantial declines in both metrics. Verification prevents fabrication but reduces acceptance rates, indicating a trade-off between integrity and output validity. The combined removal of debate and self-healing leads to a complete failure in completion and quality, highlighting their complementary and super-additive effects.

The authors evaluate AUTOResearchClaw through a multi-stage experimental framework on ARC-Bench that assesses end-to-end performance, human-in-the-loop intervention strategies, and individual component contributions. The experiments validate that the system consistently surpasses existing baselines, particularly in result analysis and overall paper quality, due to the synergistic effects of multi-agent debate, self-healing execution, and verification. Qualitatively, the findings demonstrate that targeted human guidance at high-leverage decision points optimizes both paper quality and acceptance rates, outperforming both full automation and exhaustive oversight. Furthermore, the component analysis reveals that these internal mechanisms operate super-additively, with debate and self-healing driving completion and analytical depth while verification ensures integrity, though strict verification criteria can trade off against acceptance.