HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

LLaVA-UHD v4: Was macht das effiziente visuelle Encoding in MLLMs aus?

Entlarvung der On-Policy-Distillation: Wo sie hilft, wo sie schadet und warum

























LLaVA-UHD v4: Was macht das effiziente visuelle Encoding in MLLMs aus?
Entlarvung der On-Policy-Distillation: Wo sie hilft, wo sie schadet und warum
Ein einzelnes Neuron genügt, um die Sicherheitsausrichtung in großen Sprachmodellen zu umgehen
SlimQwen: Untersuchung der Pruning- und Distillationsmethoden in der Vorverarbeitung großer MoE-Modelle
ELF: Eingebettete Sprachflüsse
PaperFit: Optimierung der Satzstruktur wissenschaftlicher Dokumente durch visuelles Feedback
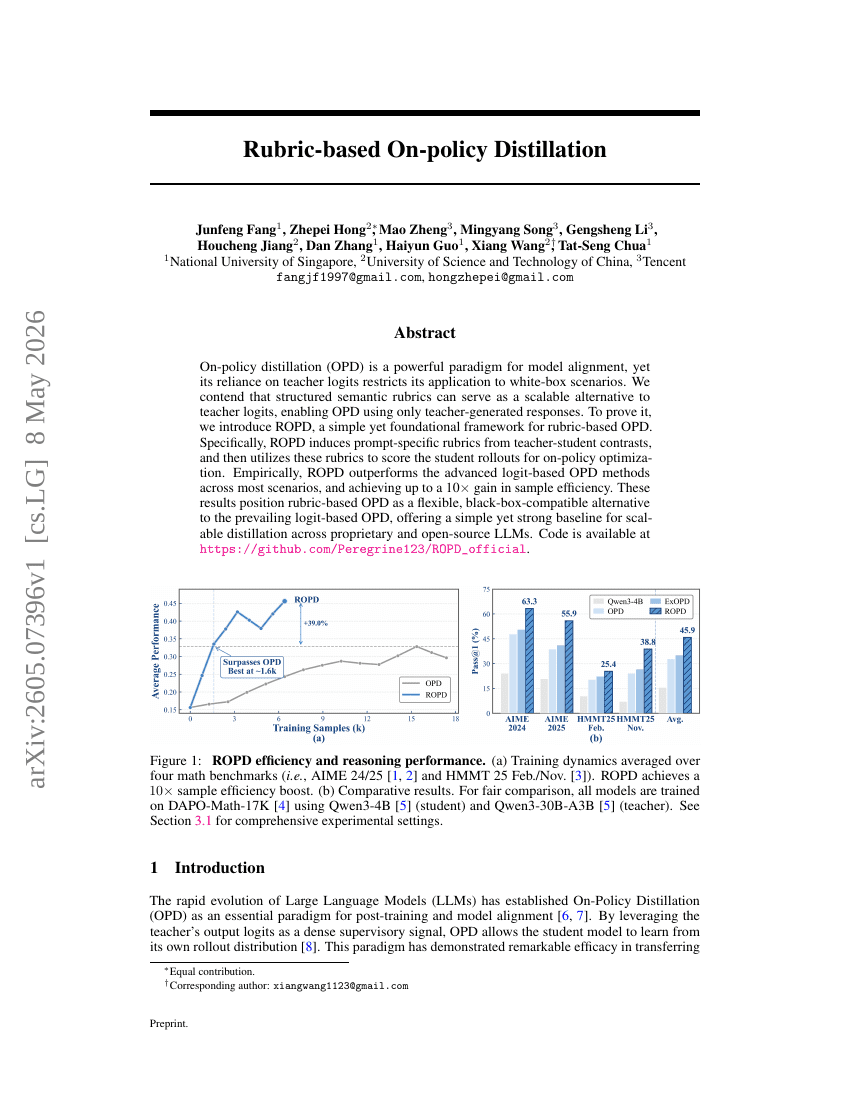
Rubrikbasierte On-Policy-Distillation
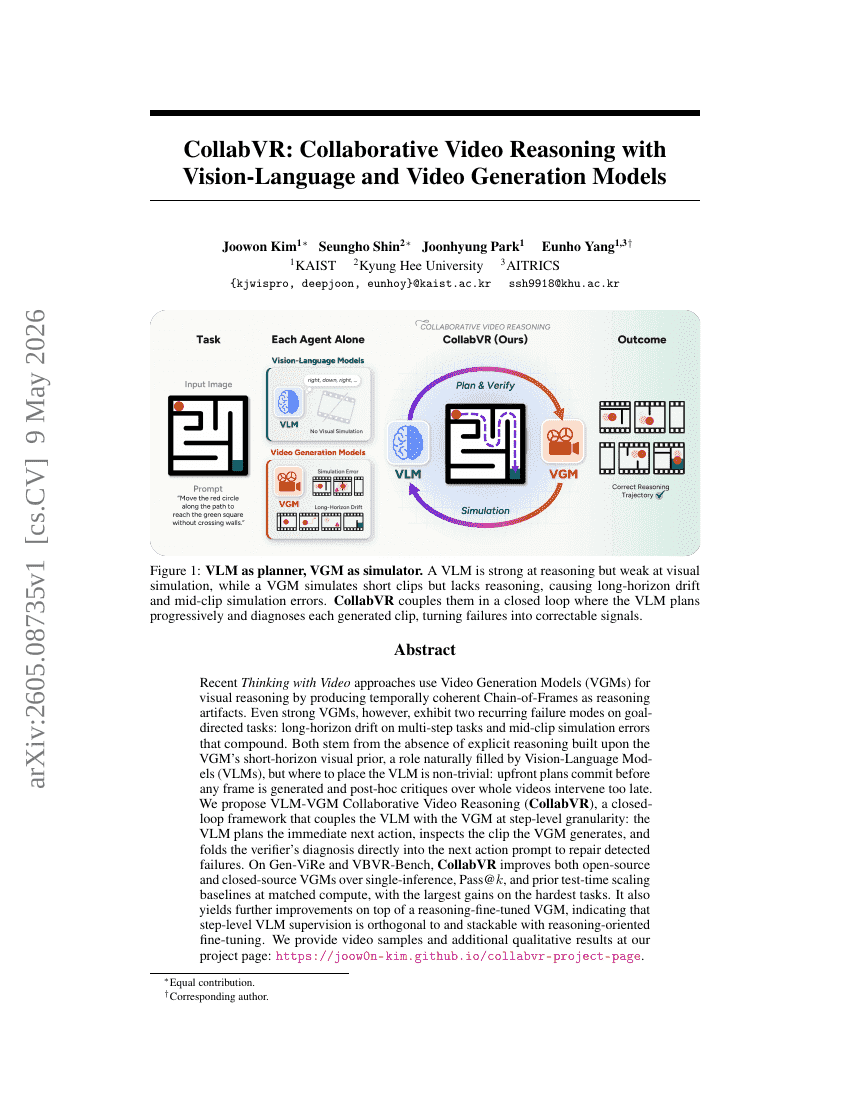
CollabVR: Kollaborative Videorationalität mit visuell-sprachlichen und videogenerativen Modellen
TMAS: Skalierung der Rechenleistung zur Testzeit durch Multi-Agent-Synergie
Soohak: Ein von Mathematikern kuratierter Benchmark zur Bewertung der mathematischen Fähigkeiten auf Forschungsstufe von LLMs
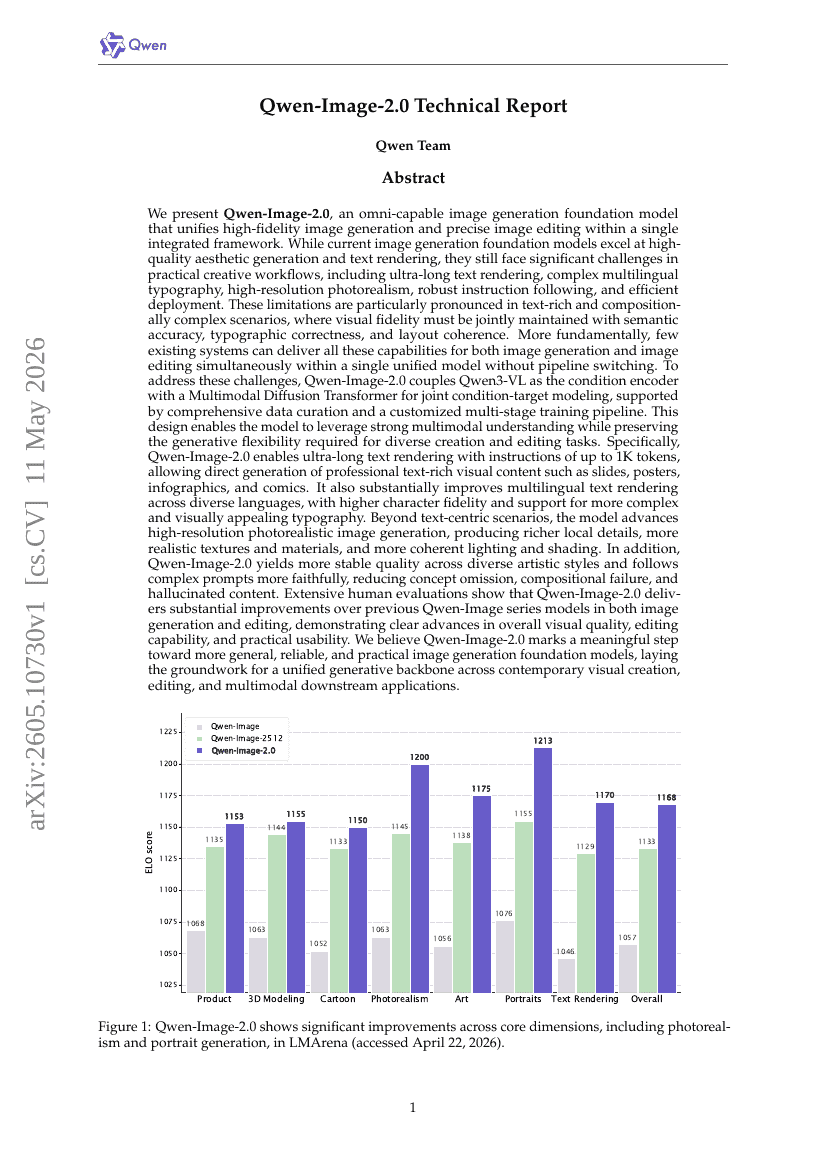
Technischer Bericht zu Qwen-Image-2.0
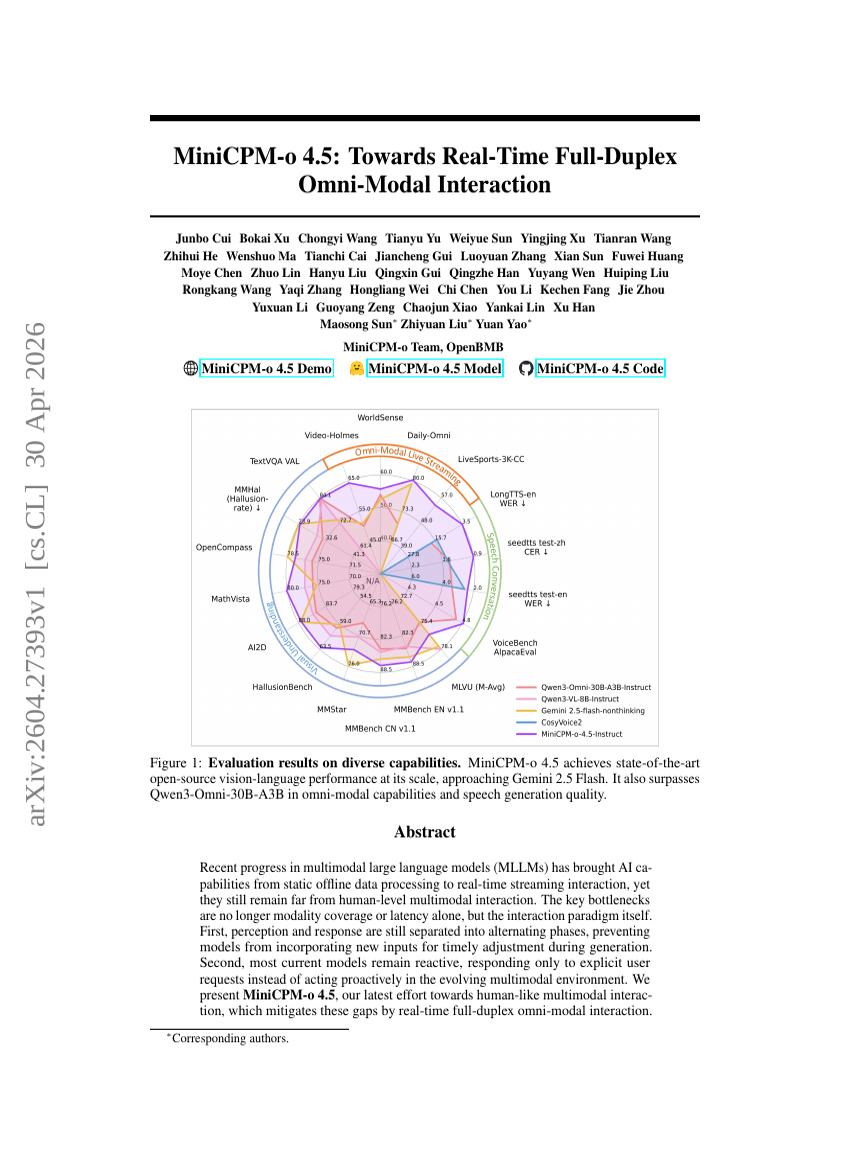
MiniCPM-o 4.5: Auf dem Weg zu einer Echtzeit-Voll-Duplex-Omni-Modal-Interaktion
Lernen während des Einsatzes: Fleet-Skalierbare Bestärkungslernen-Verfahren für allgemeine Roboterpolicies
Fast Byte Latent Transformer
KI-Mitmathematiker: Beschleunigung von Mathematikern durch agentic AI
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning für Parallele Multimodale Search Agents
Mean-Modus-Schreien: Mittelwert-Varianz-aufgeteilte Residuen für 1000-Schicht-Diffusions-Transformers
LLMs verbessern LLMs: Agentic Discovery für Test-Time Scaling
List-basierte Politikoptimierung: Gruppenbasierte RLVR als Zielprojektion auf das LLM-Antwort-Simplex
Flow-OPD: On-Policy-Distillation für Flow-Matching-Modelle
MACE-Dance: Bewegungs- und Erscheinungs-Kaskadierende Experten für musikgetriebene Tanzvideogenerierung
Erneutes Überdenken reasoning-intensiver Abrufmethoden: Bewertung und Verbesserung von Retrievers in agentic Search-Systemen
Wann ist der Phantasie zu vertrauen: Adaptive Handlungsexecution für World Action Models
RaguTeam bei SemEval-2026 Aufgabe 8: Meno und Freunde in einem von einem Richter orchestrierten LLM-Ensemble für glaubwürdige Mehrfachantwort-Generierung
MiA-Signatur: Annäherung an globale Aktivität zum Verständnis langer Kontexte
Continuous Latent Diffusion Language Model
Fähigkeit 1: Unified Evolution von mit Fähigkeiten erweiterten Agents durch Reinforcement Learning
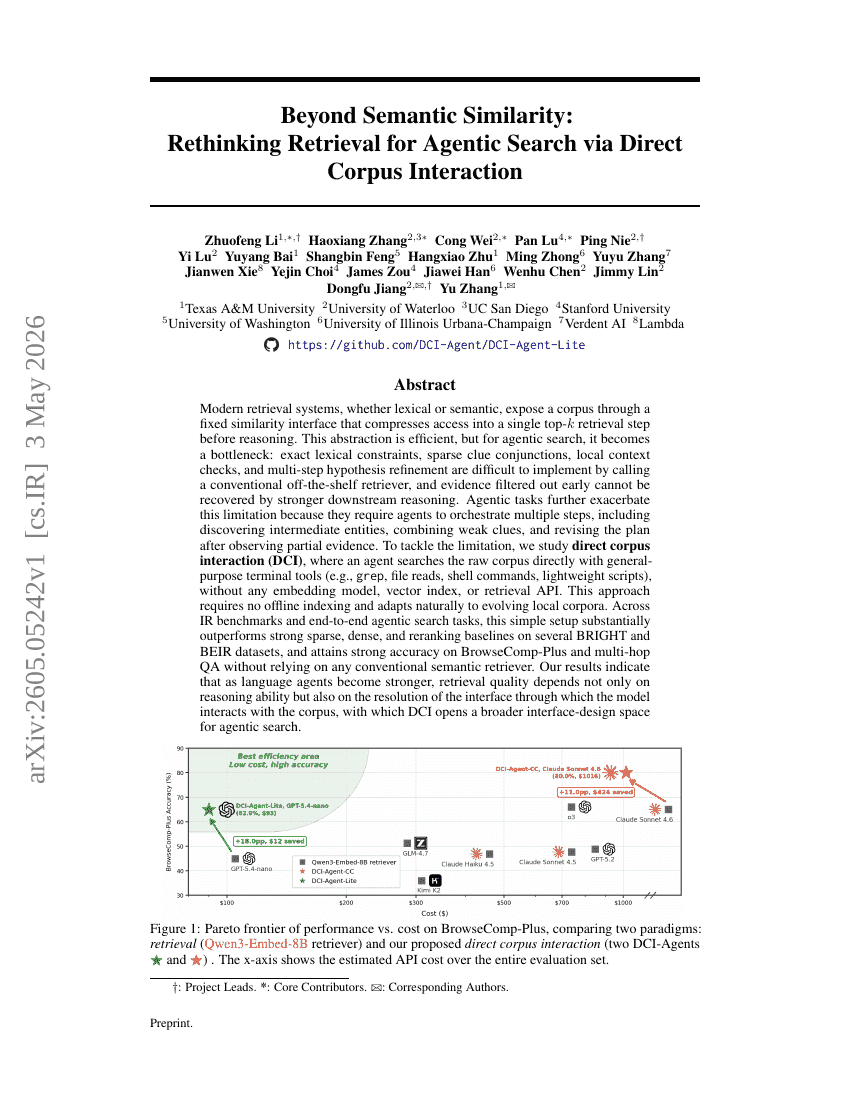
Über die semantische Ähnlichkeit hinaus: Eine Neubewertung der retrieval-basierten Suche für agentic Search durch direkte Interaktion mit dem Korpus
MathNet: Ein globaler Multimodal-Benchmark für mathematisches Reasoning und Retrieval
D-OPSD: On-Policy Selbst-Distillation zur kontinuierlichen Feinabstimmung von step-distilled Diffusion Modellen
ZAYA1-8B Technischer Bericht
PhysForge: Generierung physikalisch fundierter 3D-Assets für interaktive virtuelle Welten
Ein einzelnes Neuron genügt, um die Sicherheitsausrichtung in großen Sprachmodellen zu umgehen
SlimQwen: Untersuchung der Pruning- und Distillationsmethoden in der Vorverarbeitung großer MoE-Modelle
ELF: Eingebettete Sprachflüsse
PaperFit: Optimierung der Satzstruktur wissenschaftlicher Dokumente durch visuelles Feedback
Rubrikbasierte On-Policy-Distillation
CollabVR: Kollaborative Videorationalität mit visuell-sprachlichen und videogenerativen Modellen
TMAS: Skalierung der Rechenleistung zur Testzeit durch Multi-Agent-Synergie
Soohak: Ein von Mathematikern kuratierter Benchmark zur Bewertung der mathematischen Fähigkeiten auf Forschungsstufe von LLMs
Technischer Bericht zu Qwen-Image-2.0
MiniCPM-o 4.5: Auf dem Weg zu einer Echtzeit-Voll-Duplex-Omni-Modal-Interaktion
Lernen während des Einsatzes: Fleet-Skalierbare Bestärkungslernen-Verfahren für allgemeine Roboterpolicies
Fast Byte Latent Transformer
KI-Mitmathematiker: Beschleunigung von Mathematikern durch agentic AI
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning für Parallele Multimodale Search Agents
Mean-Modus-Schreien: Mittelwert-Varianz-aufgeteilte Residuen für 1000-Schicht-Diffusions-Transformers
LLMs verbessern LLMs: Agentic Discovery für Test-Time Scaling
List-basierte Politikoptimierung: Gruppenbasierte RLVR als Zielprojektion auf das LLM-Antwort-Simplex
Flow-OPD: On-Policy-Distillation für Flow-Matching-Modelle
MACE-Dance: Bewegungs- und Erscheinungs-Kaskadierende Experten für musikgetriebene Tanzvideogenerierung
Erneutes Überdenken reasoning-intensiver Abrufmethoden: Bewertung und Verbesserung von Retrievers in agentic Search-Systemen
Wann ist der Phantasie zu vertrauen: Adaptive Handlungsexecution für World Action Models
RaguTeam bei SemEval-2026 Aufgabe 8: Meno und Freunde in einem von einem Richter orchestrierten LLM-Ensemble für glaubwürdige Mehrfachantwort-Generierung
MiA-Signatur: Annäherung an globale Aktivität zum Verständnis langer Kontexte
Continuous Latent Diffusion Language Model
Fähigkeit 1: Unified Evolution von mit Fähigkeiten erweiterten Agents durch Reinforcement Learning
Über die semantische Ähnlichkeit hinaus: Eine Neubewertung der retrieval-basierten Suche für agentic Search durch direkte Interaktion mit dem Korpus
MathNet: Ein globaler Multimodal-Benchmark für mathematisches Reasoning und Retrieval
D-OPSD: On-Policy Selbst-Distillation zur kontinuierlichen Feinabstimmung von step-distilled Diffusion Modellen
ZAYA1-8B Technischer Bericht
PhysForge: Generierung physikalisch fundierter 3D-Assets für interaktive virtuelle Welten