Command Palette
Search for a command to run...
Interaktive Bewertung erfordert eine Designwissenschaft
Interaktive Bewertung erfordert eine Designwissenschaft
Zusammenfassung
Die Evaluation künstlicher Intelligenz befindet sich im Wandel ihrer Struktur. Large Language Models (LLMs) werden zunehmend als Systeme eingesetzt, die über Zeit hinweg durch den Einsatz von Tools, Umgebungen, Nutzern und anderen Agents agieren. Dennoch übernehmen viele Evaluierungspraktiken noch immer Annahmen, die von antwortzentrierten Benchmarks stammen: feste Eingaben, isolierte Ausgaben und Bewertungen, die auf einer einzelnen Antwort basieren. Obwohl sich interaktive Benchmarks herausgebildet haben, bleibt die Landschaft fragmentiert: Die Benchmarks unterscheiden sich darin, welche Interaktionsartefakte sie berücksichtigen, wie Trajektorien bewertet werden und welche Schlussfolgerungen ihre Ergebnisse stützen. In diesem Positionspaper wird argumentiert, dass die interaktive Evaluation als ein prinzipiengeleiteter Evaluierungsansatz behandelt werden sollte und nicht merely als eine neue Familie von Agent-Benchmarks. Eine bloße Übernahme früherer Evaluierungsparadigmen reicht nicht aus. Wir definieren Evaluation als eine autonome Abbildung von Evidenz zu Urteilen und zeigen, dass die interaktive Evaluation beide Seiten dieser Abbildung verändert: Die Evidenz besteht aus interaktionsgenerierten Trajektorien, während das Bewertungsverfahren Prozesshaftigkeit, Wiederherstellbarkeit, Koordination, Robustheit und Systemleistungsmerkmale auf gesamtsystemischer Ebene beurteilen muss. Auf der Grundlage dieser Definition schlagen wir eine Taxonomie entlang zweier Achsen vor, leiten daraus Gestaltungsprinzipien und Berichtsstandards ab, untersuchen repräsentative Szenarien und analysieren, wie langjährige Herausforderungen der Evaluation auf der Trajektorienebene erneut auftreten.
One-sentence Summary
This position paper argues that interactive evaluation requires a design science rather than merely fragmented benchmarks relying on isolated outputs, defining evaluation as an autonomous mapping from evidence to judgments where interaction-generated trajectories replace fixed inputs and procedures assess process, recoverability, coordination, robustness, and system-level performance through a proposed two-axis taxonomy, design principles, and reporting standards.
Key Contributions
- The paper establishes a formal definition of evaluation as an autonomous mapping from evidence to judgments, where evidence shifts from isolated outputs to interaction-generated trajectories. This framework requires assessment procedures to evaluate process, recoverability, coordination, and system-level performance rather than single responses.
- A two-axis taxonomy is introduced to organize interactive evaluation, deriving specific design principles and reporting standards for benchmark construction. These standards address needs such as replayable trajectory logs, environment versioning, and transparent scoring mechanisms.
- Representative scenarios including coding agents are examined to analyze how longstanding evaluation challenges reappear at the trajectory level. This analysis highlights the need for trajectory-level measures over final resolution labels to distinguish genuine debugging competence from benchmark exploitation.
Introduction
Large language models are increasingly deployed as systems that act through tools and environments over time rather than as standalone generators. Current evaluation practices often inherit response-centered assumptions that treat isolated outputs as sufficient evidence, which fails to capture process quality or system-level robustness in interactive settings. Furthermore, the landscape of interactive benchmarks remains fragmented with varying artifacts and scoring procedures that obscure which claims results support. The authors argue that interactive evaluation should be treated as a principled design science to address this fragmentation. They define evaluation as an autonomous mapping from interaction-generated trajectories to judgments and propose a two-axis taxonomy along with design principles to make benchmark claims interpretable and comparable.
Dataset

- Dataset Composition and Sources: The authors constructed a benchmark corpus to analyze temporal trends in interactive evaluation. They combined a manually curated representative list with two semi-automated retrieval channels including citation-based snowball sampling and Semantic Scholar searches spanning 2020 to 2026.
- Key Details and Filtering: The team deduplicated entries using arXiv IDs or normalized titles. A paper was retained for the final set if it appeared in a top venue, achieved a citation velocity of at least 1.5, or accumulated 50 or more GitHub stars.
- Classification and Subsets: An LLM-based classifier sorted the corpus into three roadmap categories based on titles and abstracts. Papers classified as Not Relevant were excluded from the trend analysis. Validation on a manual anchor set confirmed over 90% agreement with human labels before full application.
- Usage and Metadata: The collection serves as descriptive evidence for broad temporal trends instead of model training data. No training splits or mixture ratios apply. Metadata such as citation counts and GitHub stars were recorded as approximate indicators of influence while noting limitations regarding repository age.
Method
The authors propose a methodological framework for Interactive Evaluation, which redefines the standard evaluation mapping E:X→Y. This approach shifts the focus from static answer verification to the assessment of dynamic interaction processes.
The evolution of this framework is illustrated in the timeline below, which categorizes benchmarks into four distinct stages.
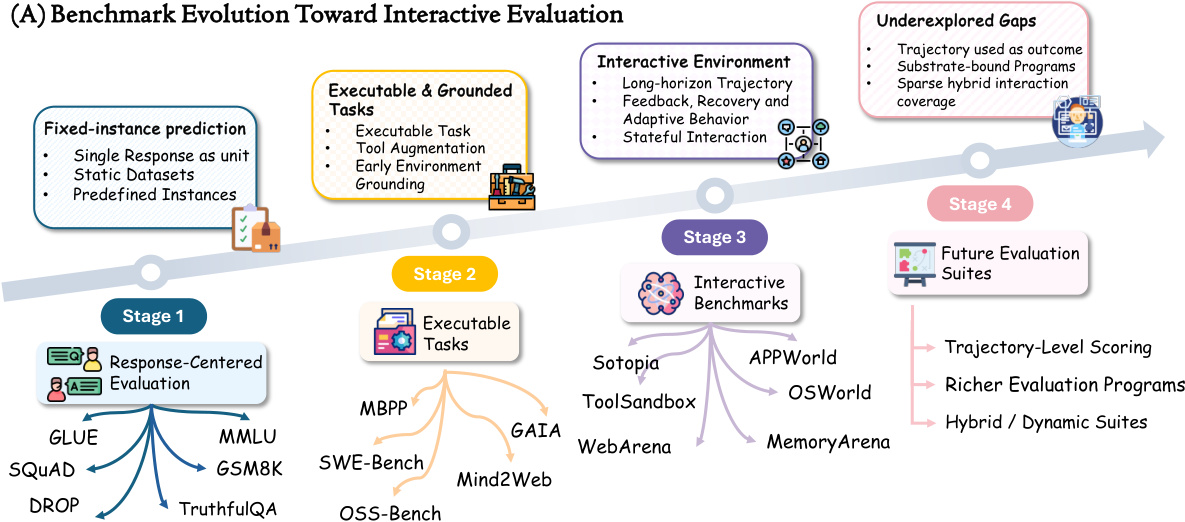
Stage 1 represents traditional Response-Centered Evaluation, relying on fixed-instance predictions and static datasets like GLUE or MMLU. Stage 2 introduces Executable & Grounded Tasks, incorporating tool augmentation and early environment grounding. Stage 3 marks the transition to Interactive Benchmarks, characterized by long-horizon trajectories, feedback loops, and stateful interaction. Finally, Stage 4 outlines Future Evaluation Suites, aiming for trajectory-level scoring and hybrid dynamic suites that address underexplored gaps such as substrate-bound programs and sparse interaction coverage.
The core distinction between traditional and interactive evaluation is defined by the components of the evaluation mapping. Refer to the comparison diagram below for a detailed breakdown of these components.
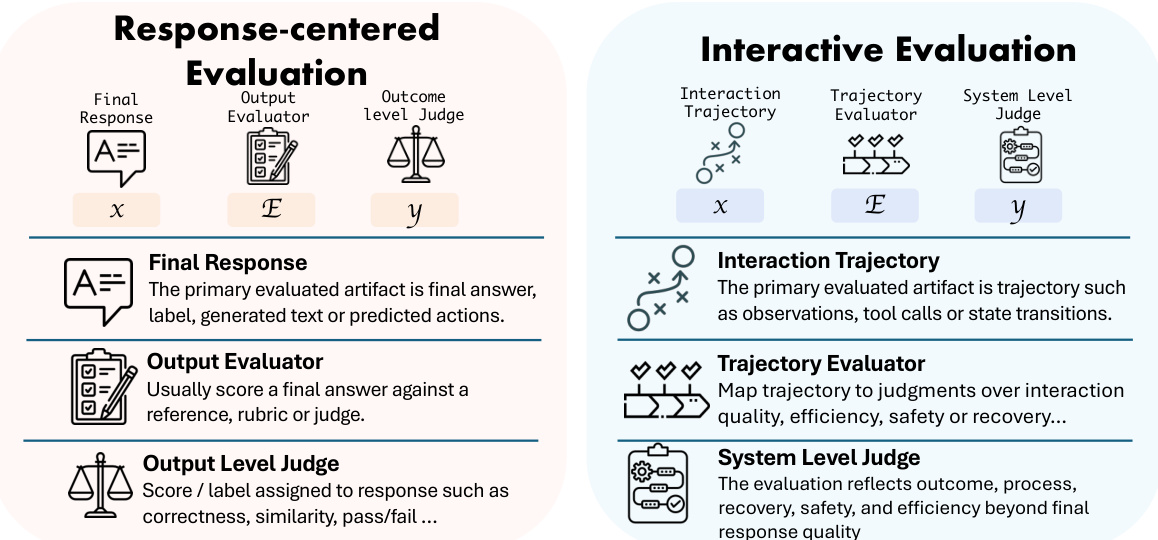
In the Response-Centered Evaluation paradigm, the primary artifact is the final response x. The evaluator E acts as an output evaluator, typically scoring the final answer against a reference or rubric. The resulting judgment y is an outcome-level assessment, such as correctness or pass/fail status.
In contrast, Interactive Evaluation fundamentally alters the input artifact x to be the Interaction Trajectory. This trajectory includes observations, tool calls, state transitions, and intermediate artifacts generated during consequential interaction. Consequently, the evaluator E becomes a Trajectory Evaluator. Instead of merely checking a final answer, this module maps the trajectory to judgments regarding interaction quality, efficiency, safety, and recovery. The final output y is a System Level Judge that reflects the outcome, process, and resilience of the system beyond just the final response.
The framework utilizes this two-axis view to categorize evaluations based on what interaction-generated artifacts enter X and how the program E maps those artifacts to judgments. This design allows for the assessment of complex properties like recoverability after error, cooperative behavior, and robustness under disruption, which are invisible in static response-based benchmarks.
Experiment
Fidelity, Control, and Simulator Artifacts. Interactive evaluation must decide how much of deployment to reproduce and how much to abstract away. High-fidelity environments can provide richer evidence about situated behavior, but they are expensive, noisy, and harder to control. Controlled simulators improve repeatability and comparison, but may reward strategies that exploit simulator artifacts rather than genuine interactive competence. There is no universal optimum between realism and control. Benchmarks should instead state which deployment conditions they model faithfully, which they deliberately abstract away, and which claims their level of fidelity can and cannot support.
Evaluator and Counterpart Dependence. As user simulators, model judges, human experts, and counterpart agents become standardized evaluation infrastructure, they begin to shape what counts as successful interaction. Scores may then reward adaptation to particular evaluators or counterpart policies rather than the intended
capability. This creates a construct-validity risk: systems may perform well under one judge, simulator, or expert group but fail under plausible alternatives. Future benchmarks should test whether conclusions remain stable across evaluator and counterpart variants.
- Alternative view 6: Interactive evaluation conflates model capability with system engineering.
A further objection is that interactive benchmarks often evaluate more than the base model. Tool wrappers, memory, retrieval systems, planners, sandboxes, interface affordances, orchestration policies, and prompting strategies may dominate performance. If so, interactive evaluation may make it difficult to know whether progress comes from better models or better systems engineering.
Response. the paper agree that interactive evaluation often evaluates systems rather than isolated models. This is not a defect of the paradigm; it is a property of the deployment settings that motivate it. When an AI system acts through tools, environments, users, memory, or other agents, the relevant object of evaluation is frequently the assembled system. A benchmark that ignores wrappers, permissions, state, orchestration, or tool interfaces may provide a cleaner model-level comparison, but it may not support claims about deployed interactive behavior.
The implication is that benchmark reports must distinguish model-level and system-level claims. If the goal is to compare base models, then the surrounding scaffold should be controlled and reported. If the goal is to compare complete agents or deployed assistants, then the scaffold is part of the evaluated object and should be documented as such. Interactive evaluation therefore raises the standard for reporting: model identity alone is insufficient. Evaluations should specify tools, memory, retrieval, prompts, orchestration, sandbox permissions, environment versions, and logging protocols so that readers can interpret what the score is actually evidence about.
- C.3 Industry-Academic Comparison.
Panel (c) of the figure compares evaluation-stage composition between recent frontier industry reports and academic benchmark papers from 2024-2026. The industry sample contains 43 distinct benchmark families extracted from the most recent public model cards or technical reports of OpenAI, Anthropic, Google DeepMind, and Alibaba/Qwen, with each benchmark family counted once per source document regardless of variants or subtasks. The academic sample is the 2024-2026 subset of the benchmark collection described above, containing 360 benchmark papers. Bars report percentage shares within each group, so each group sums to 100%. A Pearson χ2 test gives χ2(2)=7.09, p=0.029, indicating a statistically significant difference in
stage distribution. the paper interpret this comparison as descriptive evidence that the transition toward task-driven and interactive evaluation is uneven across the evaluation ecosystem, rather than as an exhaustive census of either community.