HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

DR Tulu:面向深度研究的基于演化评分标准的强化学习

AICC:精细化HTML解析,提升模型性能 —— 基于模型HTML解析器构建的7.3T面向AI语料库




























DR Tulu:面向深度研究的基于演化评分标准的强化学习
AICC:精细化HTML解析,提升模型性能 —— 基于模型HTML解析器构建的7.3T面向AI语料库
UltraFlux:面向跨多种纵横比的高质量原生4K文本到图像生成的数据-模型协同设计
DeCo:面向端到端图像生成的频率解耦像素扩散
计算机操作 Agent 作为生成式用户界面的评判者
AutoEnv:衡量 Agent 跨环境学习的自动化环境
通过深度研究实现通用智能体记忆
VIRAL:面向人形机器人运动操作的规模化视觉仿真到现实迁移
MIST:基于监督训练的互信息
多智能体深度研究:使用 M-GRPO 训练多智能体系统
无数据流程图提炼
Docling:一种高效的开源AI驱动文档转换工具包
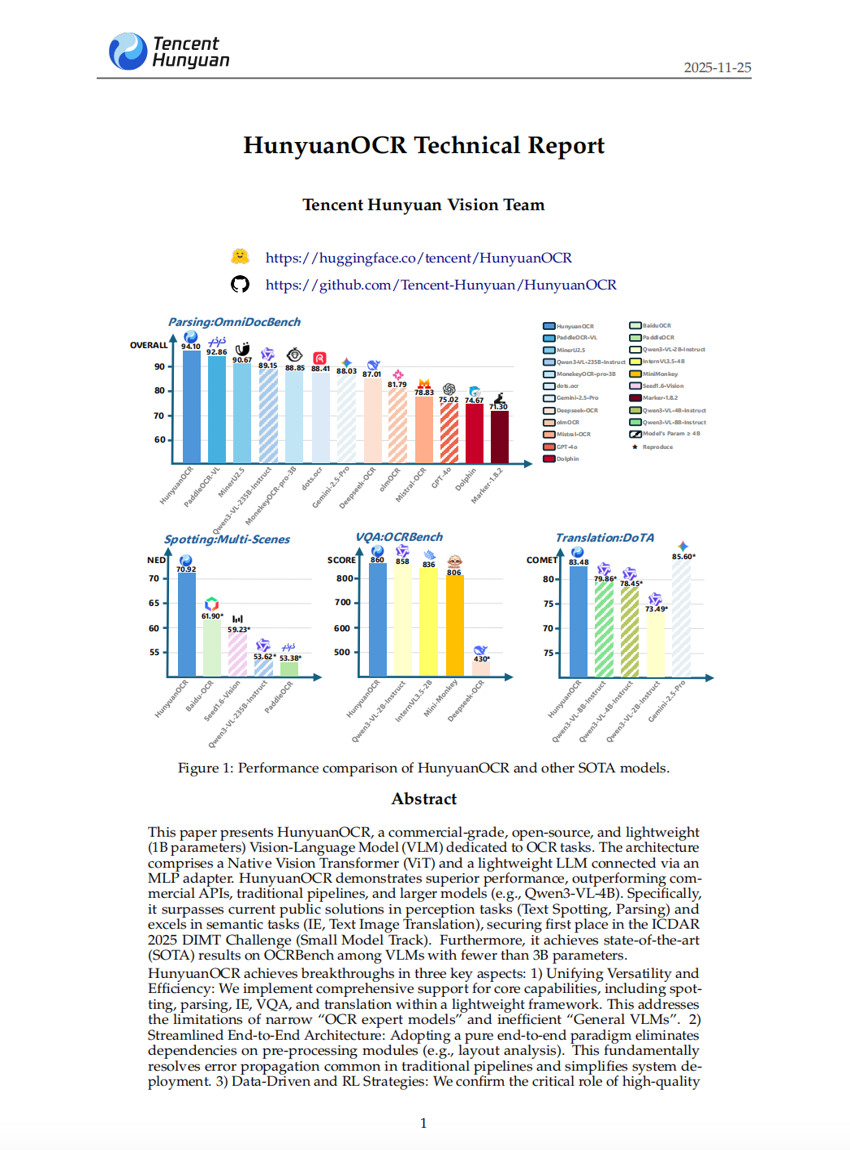
HunyuanOCR 技术报告
PhysToolBench:面向MLLMs的物理工具理解能力评估
赫胥黎-哥德尔机器:通过最优自改进机器的近似实现人类水平的编码Agent开发
无需空间超感知的空间超感知求解
Parrot:输出真实性的说服与认同鲁棒性评级——面向 LLMs 的阿谀鲁棒性基准
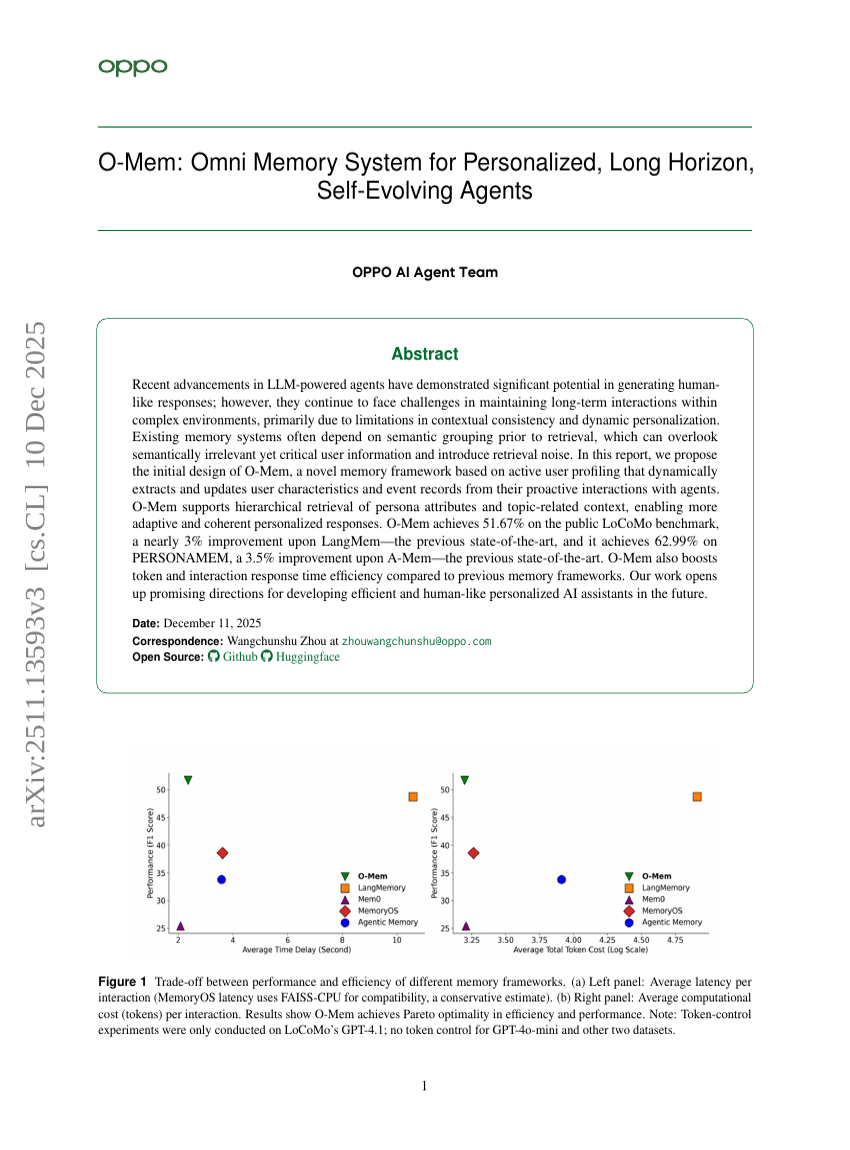
O-Mem:用于个性化、长视界自我演进智能体的全维记忆系统
揭示文本本征维度:从学术摘要到创意故事
SAM 3:基于概念的万物分割
GeoVista:面向地理定位的网络增强 Agent 视觉推理
OpenMMReasoner:以开放与通用的方案拓展多模态推理的前沿
HiPO:面向LLMs动态推理的混合策略优化
SERES:基于语义感知的稀疏视角神经重建
SDAR:一种用于可扩展序列生成的协同扩散-自回归范式
MultiPL-MoE:通过混合专家模型扩展大型语言模型的多编程语言能力
CapRL:通过强化学习激发密集图像描述能力
通过离散扩散发散指令实现超快速语言生成
DisCO:通过判别约束优化强化大型推理模型
QSVD:面向低精度视觉-语言模型中统一查询-键-值权重压缩的高效低秩近似
嵌套学习:深度学习架构的幻觉
SAM 3D:将图像中的任意内容3D化
UltraFlux:面向跨多种纵横比的高质量原生4K文本到图像生成的数据-模型协同设计
DeCo:面向端到端图像生成的频率解耦像素扩散
计算机操作 Agent 作为生成式用户界面的评判者
AutoEnv:衡量 Agent 跨环境学习的自动化环境
通过深度研究实现通用智能体记忆
VIRAL:面向人形机器人运动操作的规模化视觉仿真到现实迁移
MIST:基于监督训练的互信息
多智能体深度研究:使用 M-GRPO 训练多智能体系统
无数据流程图提炼
Docling:一种高效的开源AI驱动文档转换工具包
HunyuanOCR 技术报告
PhysToolBench:面向MLLMs的物理工具理解能力评估
赫胥黎-哥德尔机器:通过最优自改进机器的近似实现人类水平的编码Agent开发
无需空间超感知的空间超感知求解
Parrot:输出真实性的说服与认同鲁棒性评级——面向 LLMs 的阿谀鲁棒性基准
O-Mem:用于个性化、长视界自我演进智能体的全维记忆系统
揭示文本本征维度:从学术摘要到创意故事
SAM 3:基于概念的万物分割
GeoVista:面向地理定位的网络增强 Agent 视觉推理
OpenMMReasoner:以开放与通用的方案拓展多模态推理的前沿
HiPO:面向LLMs动态推理的混合策略优化
SERES:基于语义感知的稀疏视角神经重建
SDAR:一种用于可扩展序列生成的协同扩散-自回归范式
MultiPL-MoE:通过混合专家模型扩展大型语言模型的多编程语言能力
CapRL:通过强化学习激发密集图像描述能力
通过离散扩散发散指令实现超快速语言生成
DisCO:通过判别约束优化强化大型推理模型
QSVD:面向低精度视觉-语言模型中统一查询-键-值权重压缩的高效低秩近似
嵌套学习:深度学习架构的幻觉
SAM 3D:将图像中的任意内容3D化