Command Palette
Search for a command to run...
DeCo:面向端到端图像生成的频率解耦像素扩散
DeCo:面向端到端图像生成的频率解耦像素扩散
Zehong Ma Longhui Wei Shuai Wang Shiliang Zhang Qi Tian
摘要
像素扩散(Pixel diffusion)旨在以端到端的方式直接在像素空间生成图像。这种方法规避了由变分自编码器(VAE)带来的两阶段潜在扩散(latent diffusion)模型的局限性,从而提供了更高的模型容量。然而,现有的像素扩散模型通常需要在单个扩散Transformer(DiT)架构中同时对高频信号和低频语义进行建模,因此面临训练和推理速度缓慢的问题。为了探索更高效的像素扩散范式,我们提出了“频率解耦”像素扩散框架(frequency-DeCoupled pixel diffusion framework,简称DeCo)。基于将高频和低频分量生成过程解耦的设计思路,我们利用一个轻量级的像素解码器,在来自DiT的语义引导下生成高频细节。这一设计使得DiT能够专注于低频语义的建模。此外,我们还引入了一种频率感知的流匹配(flow-matching)损失函数,强调视觉上显著的频率,同时抑制无关紧要的频率。大量实验表明,DeCo在像素扩散模型中取得了优异的性能,在ImageNet数据集上分别达到了1.62(256x256分辨率)和2.22(512x512分辨率)的FID分数,缩小了与潜在扩散方法之间的差距。此外,我们的预训练文本生成图像(text-to-image)模型在GenEval基准测试的系统级比较中,取得了0.86的领先综合得分。代码已公开发布于:https://github.com/Zehong-Ma/DeCo
总结
来自北京大学、华为和南京大学的研究人员推出了 DeCo,这是一种频率解耦的像素扩散框架,通过采用用于高频细节的轻量级解码器和频率感知流匹配损失来实现高效的语义建模,从而缩小了与潜在扩散方法的性能差距。
简介
高保真图像生成目前由扩散模型主导,通常分为潜在扩散(通过 VAE 压缩图像)和像素扩散(直接对原始像素建模)。虽然像素扩散避免了与 VAE 相关的压缩伪影和训练不稳定性,但它面临着巨大的计算障碍:在巨大的像素空间内联合建模复杂的高频细节和低频语义效率低下,且容易受到噪声干扰。
当前的像素扩散方法通常依赖单个 Diffusion Transformer (DiT) 同时处理所有频率分量。作者指出,这种设置中的高频噪声会干扰模型,使其无法有效地学习低频语义结构,从而导致图像质量下降。
为了解决这个问题,作者推出了 DeCo,这是一个基于频率分量拆分生成过程的频率解耦框架。通过将语义建模分配给 DiT,将细节重建分配给专门的解码器,该系统独立优化了这两个方面。
关键创新包括:
- 解耦架构: 该模型利用 DiT 从下采样输入中捕获低频语义,而轻量级像素解码器利用这些语义线索从高分辨率输入中重建高频细节。
- 频率感知损失: 作者实现了一种受 JPEG 压缩启发的新型流匹配损失,该损失使用离散余弦变换 (DCT) 和自适应加权来优先考虑视觉上显著的频率,同时抑制难以察觉的高频噪声。
- 增强的像素保真度: 通过消除对 VAE 压缩的依赖并专门化模型组件,DeCo 在 ImageNet 上实现了卓越的 FID 分数,有效地缩小了像素空间和潜在空间扩散模型之间的性能差距。
方法
作者利用频率解耦框架 DeCo,通过分离低频语义建模与高频信号生成来改进像素扩散。如框架图所示,整体架构由两个主要部分组成:Diffusion Transformer (DiT) 和轻量级像素解码器。DiT 对下采样的小规模输入进行操作以建模低频语义,而像素解码器则以 DiT 的语义线索为条件生成高频细节。这种解耦使得 DiT 能够专注于语义建模,而不会受到高频噪声的干扰,从而实现更高效的训练和更高的视觉保真度。
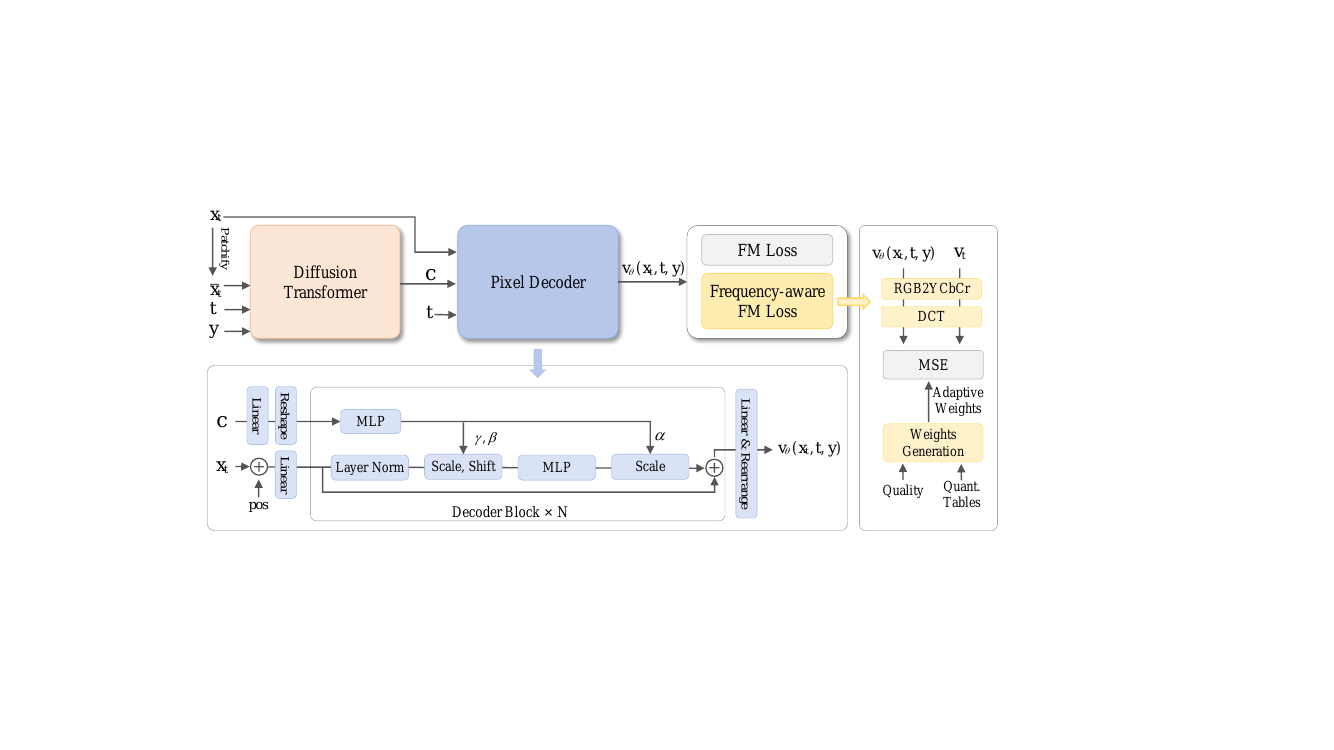
像素解码器是一个轻量级、无注意力机制的网络,由 N 个线性解码器块和若干线性投影层组成。它直接处理全分辨率加噪图像 xt 而无需下采样。所有操作均为局部和线性的,从而实现了高效的高频建模。密集查询的构建首先将加噪像素与其对应的位置嵌入 pos 拼接,并使用 Win 对其进行线性投影以形成密集查询向量 h0。对于每个解码器块,DiT 输出 c 被线性上采样并重塑以匹配 xt 的空间分辨率,产生 cup。多层感知机 (MLP) 生成用于自适应层归一化 (AdaLN) 的调制参数 α,β,γ,这些参数用于调制密集解码器查询。解码器的最终输出通过线性投影和重排操作映射到像素空间,以预测像素速度 vθ(xt,t,y)。

为了进一步强调视觉显著频率并抑制不重要的高频分量,作者引入了频率感知流匹配 (FM) 损失。该损失利用源自 JPEG 感知先验的自适应权重对不同频率分量进行重新加权。从空间域到频域的转换是通过将色彩空间转换为 YCbCr 并应用分块 8×8 离散余弦变换 (DCT) 来实现的。自适应权重由缩放量化表 Qcur 的归一化倒数生成,该表是根据人类视觉系统对不同频率的敏感度设计的。量化间隔较小的频率被认为在感知上更重要,因此被分配更高的权重。频率感知 FM 损失定义为预测的频域速度与真实频域速度之间加权平方差的期望值。总体训练目标结合了标准像素级流匹配损失、频率感知 FM 损失和 REPA 对齐损失。
实验
- DCT 能量谱分析: 验证了 DeCo 通过在像素解码器中保留高频分量,同时将其从专注于低频语义的 DiT 中移出,从而有效地解耦了频率。
- 消融研究: 确认了多尺度输入策略和基于 AdaLN 的交互的关键作用,确定了像素解码器隐藏层大小为 32、深度为 3 和 patch 大小为 1 的最佳设置。
- 类别到图像生成 (ImageNet 256x256): 该模型实现了领先的 1.62 FID 和 1.05s 的推理延迟,在效率上显著优于 RDM (38.4s) 和 PixelFlow (9.78s),同时与两阶段潜在扩散模型相媲美。
- 训练效率: DeCo 展示了 10 倍的训练效率提升,仅在 80 个 epoch 内就达到了 2.57 的 FID,超过了基线在 800 个 epoch 时的性能。
- 类别到图像生成 (ImageNet 512x512): 该方法获得了 2.22 的卓越 FID,性能可与 DiT-XL/2 和 SiT-XL/2 相媲美。
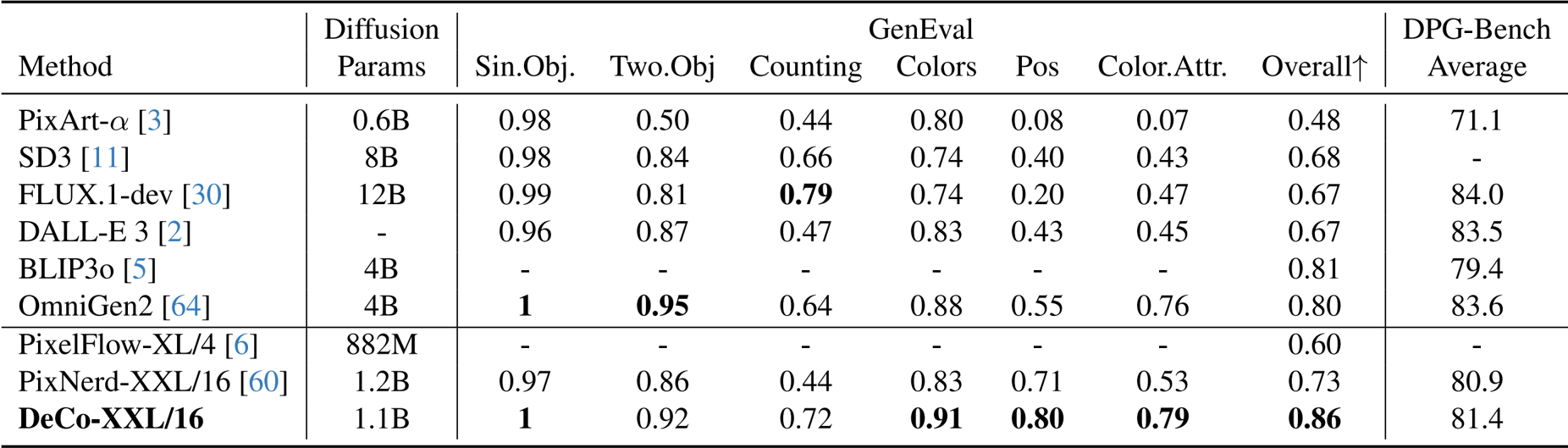
- 文本到图像生成: 在 GenEval 基准测试中,DeCo 获得了 0.86 的总分,优于 SD3、FLUX.1-dev 和 BLIP3o 等知名模型,以及 PixNerd 等像素扩散方法。
作者使用基线 DiT 模型并将其与 DeCo 框架进行比较,后者用像素解码器替换了最后两个 DiT 块。结果表明,DeCo 实现了显著更好的生成质量,将 FID 从 61.10 降低到 31.35,将 IS 从 16.81 提高到 48.35,同时保持了相当的训练和推理成本。
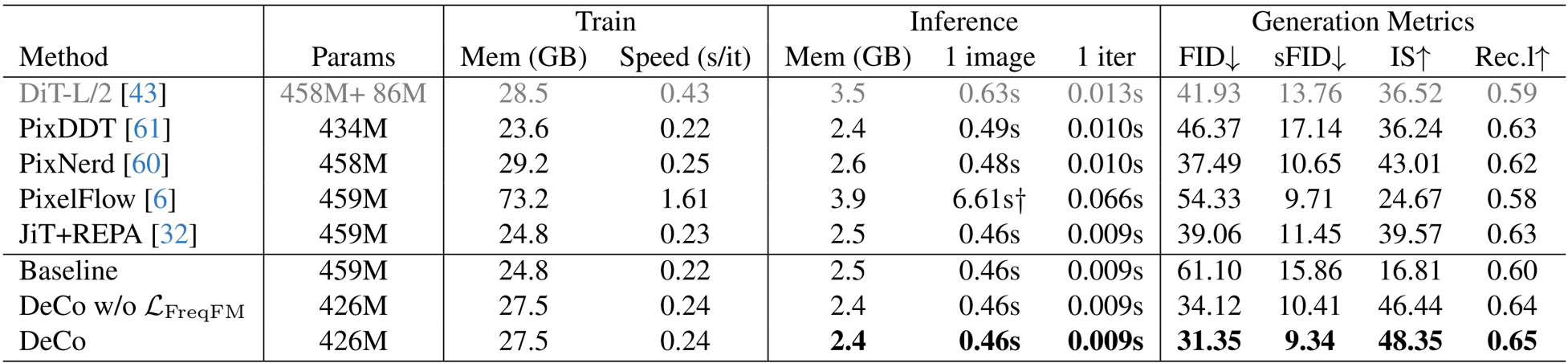
作者使用多尺度输入策略和基于 AdaLN 的交互,有效地将高频信号从 DiT 中解耦,允许像素解码器对精细细节进行建模,而 DiT 则专注于低频语义。结果表明,DeCo 在类别到图像和文本到图像生成任务上均取得了优异的性能,优于现有的像素扩散模型,并取得了与两阶段潜在扩散方法相当的结果。
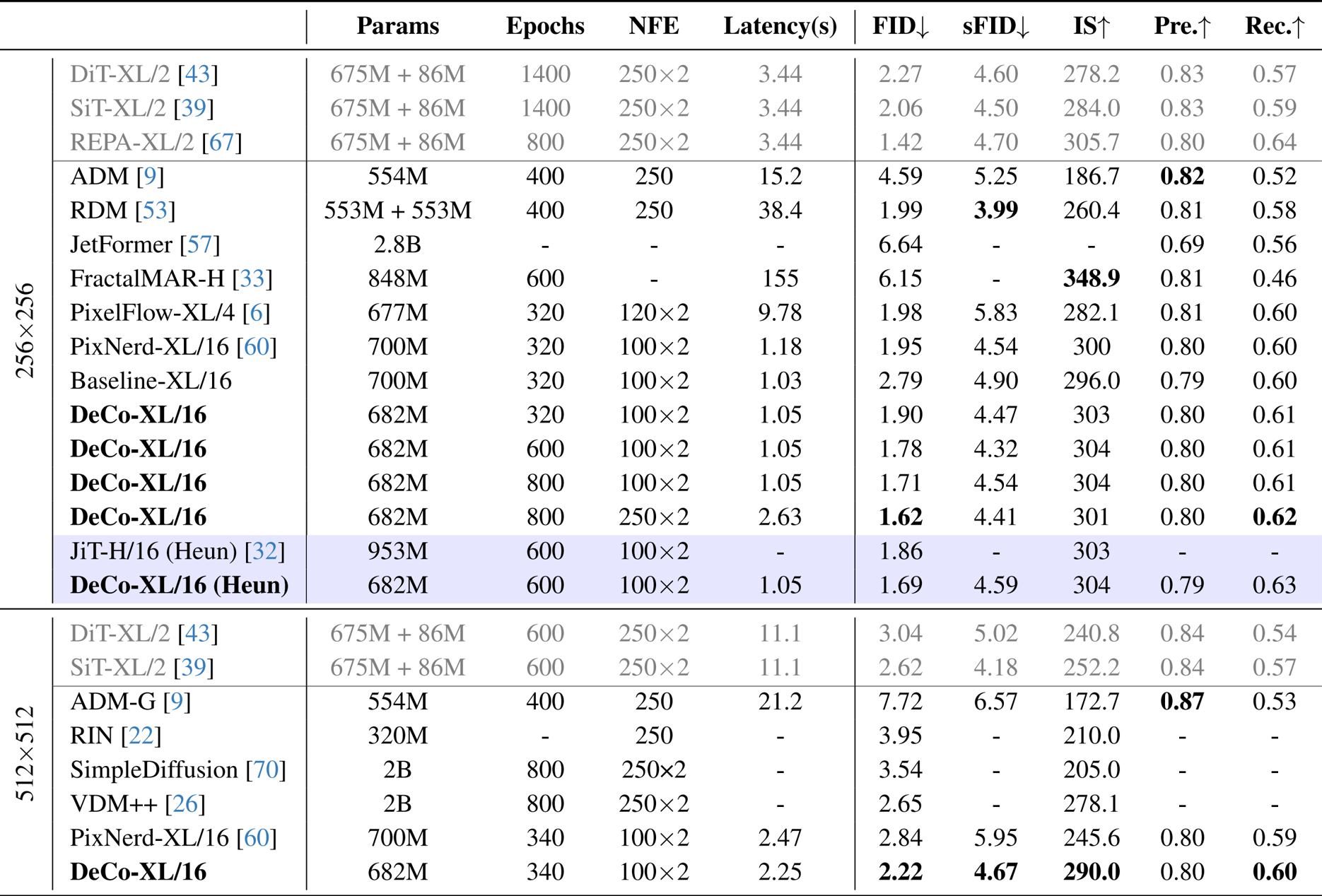
作者利用 DeCo 在文本到图像生成方面取得了最先进的性能,在 GenEval 基准测试中以 0.86 的总分优于 SD3 和 FLUX.1-dev 等模型,同时在 DPG-Bench 上也取得了具有竞争力的结果。DeCo 超越了 PixelFlow 和 PixNerd 等其他端到端像素扩散方法,证明了基于像素的扩散可以在质量上与两阶段模型相媲美,且计算成本更低。
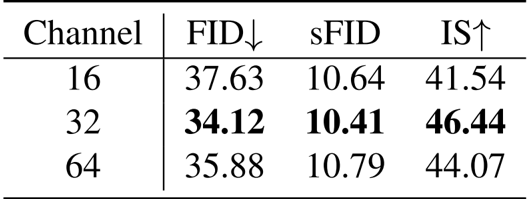
作者分析了像素解码器隐藏层大小对性能的影响,结果显示隐藏层大小为 32 时效果最佳,FID 为 34.12,sFID 为 10.41,IS 为 46.44。较小的大小(16)会导致性能降低,而增加到 64 则没有进一步的改善。
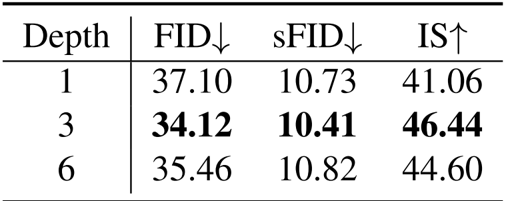
结果表明,像素解码器深度为 3 时性能最佳,FID 为 34.12,sFID 为 10.41,IS 为 46.44,优于更浅和更深的配置。