Command Palette
Search for a command to run...
SAM 3D:将图像中的任意内容3D化
SAM 3D:将图像中的任意内容3D化
摘要
我们提出 SAM 3D,一种用于视觉引导的三维物体重建的生成模型,能够仅从单张图像中预测物体的几何结构、纹理信息及场景布局。SAM 3D 在自然图像场景中表现尤为出色,这类场景中遮挡和场景杂乱现象普遍,上下文提供的视觉识别线索起着更为关键的作用。我们通过构建“人机协同—模型协同”的标注流程,对物体形状、纹理与姿态进行高效标注,从而获得了前所未有的大规模视觉引导三维重建数据集。基于该数据,我们采用一种现代化的多阶段训练框架,融合合成数据预训练与真实世界对齐策略,成功突破了三维重建领域的“数据瓶颈”。在真实物体与场景的评估中,我们的方法在人类偏好测试中展现出至少5:1的胜率,显著优于现有最新方法。我们将开源代码与模型权重,提供在线演示,并发布一个面向真实复杂场景的三维物体重建新基准数据集,以推动该领域的进一步发展。
Summarization
Meta Superintelligence Labs提出了一种基于单张图像的视觉引导三维物体重建生成模型SAM 3D,通过人机协同标注构建大规模视觉对齐的三维数据集,并采用合成预训练与真实场景对齐相结合的多阶段训练框架,有效突破了三维重建的“数据瓶颈”,在真实复杂场景下实现了显著优于现有方法的重建性能,相关代码、模型权重及在线演示将公开发布。
Introduction
作者利用单张自然图像实现高保真3D形状、纹理与布局的生成式重建,旨在突破传统计算机视觉依赖多视角几何的局限,推动真实世界中复杂场景下的3D感知。现有方法受限于真实世界3D标注数据稀缺,且多在简化合成数据上训练,难以应对遮挡、杂乱场景和未知物体。为此,作者提出SAM 3D,构建了一套融合合成预训练、半合成中段训练与真实数据后训练的多阶段训练框架,并设计了“模型在环”(MITL)数据引擎,通过人类从模型生成的候选方案中筛选或由专业3D艺术家介入,形成高质量标注闭环,显著提升数据与模型的协同进化能力。研究亮点在于:
- 创新数据引擎:首次实现大规模真实世界3D标注的可扩展生成,通过“模型生成+人类筛选”机制,突破人工标注瓶颈;
- 多阶段训练范式:借鉴大语言模型训练流程,融合合成预训练、半合成中段训练与偏好对齐后训练,有效弥合合成与真实数据之间的巨大鸿沟;
- 端到端真实世界泛化能力:在全新构建的SA-3DAO基准上实现显著性能提升,支持从日常物品到大型结构的复杂对象重建,具备强泛化性与可扩展性。
Dataset
- 作者利用了多阶段、多来源的数据构建策略,涵盖合成数据、半合成数据与真实世界数据,形成从预训练到后训练的完整数据闭环。
- 预训练阶段使用 Iso-3DO 数据集,基于 Objaverse-XL 及授权数据集中的 270 万条 3D 网格,从 24 个视角渲染生成高分辨率单物体图像,共构建 2.5 万亿训练 token 的合成数据;为保证几何质量,采用规则过滤策略剔除过于简单或存在结构异常的低质网格。
- 中训练阶段构建 RP-3DO 数据集,通过“渲染-贴合”方式将纹理网格合成至自然图像中,包含 6100 万样本与 280 万唯一网格,涵盖遮挡-被遮挡对与真实物体替换场景,用于训练模型的掩码跟随、遮挡鲁棒性与布局估计能力。
- 为增强遮挡泛化能力,作者进一步构建 Flying Occlusions (FO) 数据集,随机将合成 3D 物体嵌入自然图像,强制遮挡比例在 10%–90% 之间,并通过可见区域占比 ≥0.2% 进行过滤,共生成 5510 万样本,用于提升模型对复杂遮挡场景的建模能力。
- 为实现纹理与外观的一致性,作者构建 Object Swap – Annotated (OS-A) 子集,基于 MITL-3DO 中人工标注的高质量匹配网格,进行像素对齐的渲染贴合,生成 40 万样本,用于纹理与精修模型的训练。
- 所有合成与半合成数据在渲染时均采用随机光照(方向与强度),并使用环境光渲染目标潜变量,以促使模型学习“去光照”纹理,避免强方向性阴影或高光固化,提升真实感与泛化性。
- 后训练阶段引入 数据引擎(Data Engine),通过迭代方式收集真实世界数据:首先利用当前模型生成候选 3D 形状与纹理(来自多模型集成),再由人工标注者从 8 个候选中选择最优项(Best-of-8 搜索),并按质量评分筛选,最终获得约 314 万条可训练形状、123 万条布局数据与约 10 万条纹理数据。
- 针对模型难以生成的“硬样本”,作者将少量极端案例转交专业 3D 艺术家处理,形成 Art-3DO 数据集,通过失败类型分类与聚类去重,确保高价值数据的高效覆盖。
- 3D 布局标注通过点云引导完成:在 2.5D 点云基础上,标注者通过交互式工具调整物体的旋转、平移与尺度,实现与场景结构的精准对齐。
- 整个数据引擎流程支持端到端的偏好学习,不仅产出正样本(D+),还保留劣质候选(D−)用于偏好对齐训练,形成闭环优化机制。
- 为评估模型在真实场景下的表现,作者构建新基准 SA-3DAO,包含 1000 个由专业艺术家从真实图像中重建的高保真 3D 模型,覆盖从日常物品到文化特有对象的广泛类别,成为评估 3D 重建质量的权威标准。
Method
作者利用了基于两阶段潜在流匹配架构的最新SOTA方法,构建了SAM 3D模型,该模型首先联合预测物体的位姿和粗略形状,随后通过整合视觉线索对形状进行细化。与以往仅重建孤立物体的方法不同,SAM 3D能够预测物体布局,从而生成连贯的多物体场景。在输入编码方面,作者采用DINOv2作为编码器,从两对图像中提取特征,得到4组条件token:一是对裁剪图像I及其对应的裁剪二值掩码进行编码,提供聚焦的高分辨率物体视图;二是对完整图像I及其完整图像二值掩码进行编码,提供全局场景上下文和识别线索。此外,模型还支持可选的粗略场景点图P作为条件,该点图可通过硬件传感器(如iPhone上的LiDAR)或单目深度估计获得,使SAM 3D能够与其他流水线集成。
见框架图
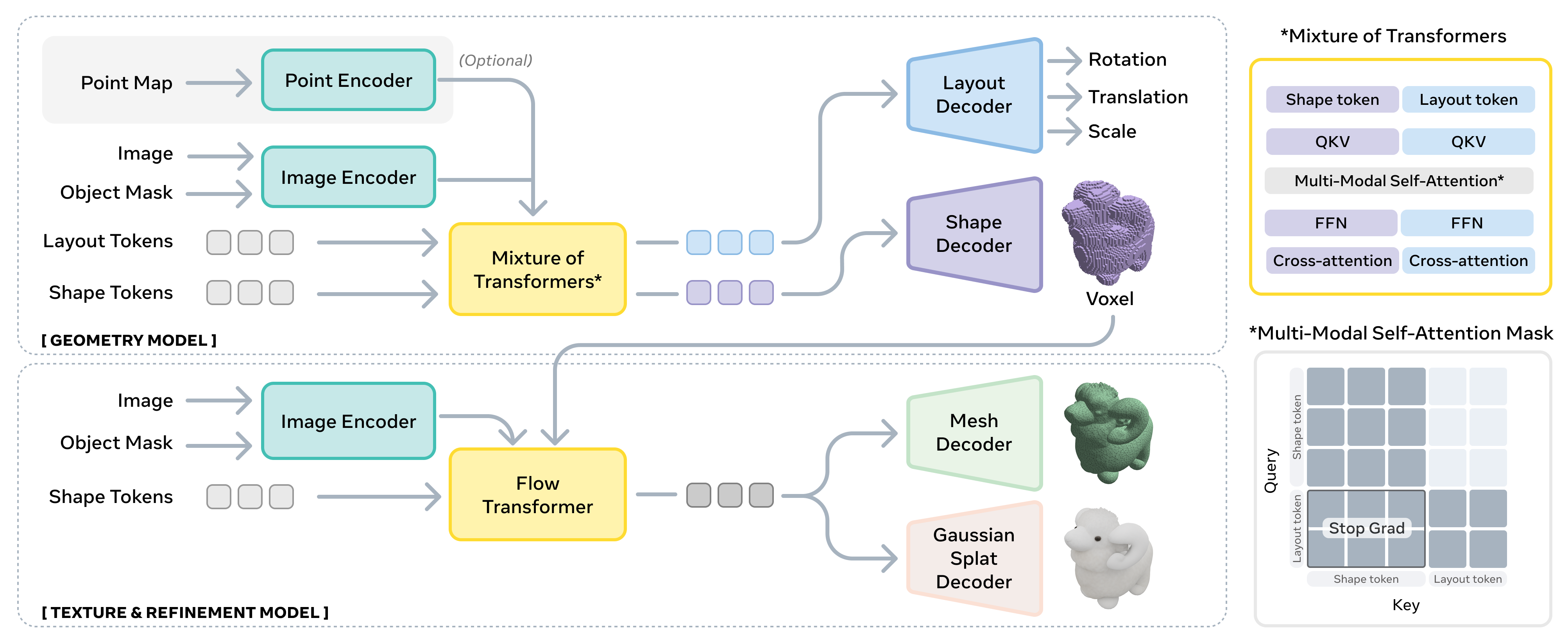
在几何模型部分,作者建模了条件分布p(O,R,t,s∣I,M),其中O∈R643为粗略形状,R∈R6为6D旋转,t∈R3为平移,s∈R3为缩放。在输入图像和掩码编码的条件下,作者采用了一个12亿参数的流变换器,其架构为混合变换器(MoT),利用注意力掩码对几何O和布局(R,t,s)进行建模。在纹理与细化模型部分,作者学习条件分布p(S,T∣I,M,O)。首先从几何模型预测的粗略形状O中提取活动体素,然后使用一个6亿参数的稀疏潜在流变换器对几何细节进行细化并合成物体纹理。
在3D解码器部分,纹理与细化模型的潜在表示可以通过一对变分自编码器(VAE)解码器Dm和Dg分别解码为网格或3D高斯喷溅。这些解码器是独立训练的,但共享相同的VAE编码器,因此共享相同的结构化潜在空间。作者还详细介绍了在\ref{sec:vae_improvements}中的一些改进。
见框架图
在几何模型的架构细节中,作者采用了一个潜在流匹配模型。对于形状,它在粗略的163×8表示的潜在空间中对643个体素进行去噪,遵循\citep{xiang2025structured}的方法。对于布局,我们直接在参数空间(R,t,s)中进行去噪,因为其维度较小。此外,作者引入了模态特定的输入和输出投影层,将形状和布局参数映射到一个维度为1024的共享特征空间,然后将其投影回各自的参数空间。这导致形状输入为4096个token,布局输入为1个token,分别输入到混合变换器(MoT)中。MoT架构由两个变换器组成:一个专门用于形状token,另一个的参数与布局参数(R,t,s)共享,如\ref{fig:method}所示。
见框架图
在几何模型的训练目标中,作者采用条件修正流匹配(Conditional Rectified Flow Matching)进行训练。给定输入图像I和掩码M,几何模型优化以下多模态流匹配目标:
LCFM=m∈M∑λmτ,x0mE[∥vm−vθm(xτm,c,τ)∥2]其中M={S,R,t,s}表示预测模态(形状、旋转、平移、缩放),c=(I,M)包含条件模态(图像、掩码),vθm是模态m在部分噪声状态xτm下的学习速度场。作者希望学习生成干净状态{x1m}m∈M∼p(M∣c),在训练期间这些是每个模态的地面真实3D注释。然后,时间τ∈[0,1]的目标概率路径是目标状态x1m和初始噪声状态x0m∼N(0,I)之间的线性插值xτm=τx1m+(1−τ)x0m。因此,目标速度场是此线性插值的梯度vm=x˙τm=(x1m−x0m)。λm是每个模态的加权系数。纹理与细化模型使用SLAT特征优化类似的流匹配目标。作者使用AdamW(无权重衰减)训练这两个模型,训练超参数如采样和学习率调度、EMA权重在\ref{sec:texture_hyperparameters}中。
在偏好对齐目标中,作者遵循Diffusion-DPO~\citep{wallace2024diffusion}并适应流匹配,如下所示:给定相同的输入图像和掩码c,我们根据人类偏好采样一对3D输出(x0w,x0l),其中x0w是首选选项,x0l是不太喜欢的选项。我们的训练目标是:
LDPO=−EI(x0w,x0l)τxτwxτl∼ I,∼ XI2∼ U(0,T)∼ q(xτw∣x0w)∼ q(xτl∣x0l)[logσ(−βTw(τ)⋅Δ)] whereΔ=∥vw−vθ(xτw,c,τ)∥22−∥vw−vref(xτw,c,τ)∥22−(∥vl−vθ(xτl,c,τ)∥22−∥vl−vref(xτl,c,τ)∥22)其中vw和vl是xτw和xτl的目标流匹配速度,vθ和vref是学习和冻结的参考速度场。在实现细节中,作者在几何模型的形状预测和纹理与细化模型的预测上应用DPO。我们使用在阶段2收集的偏好数据,其中我们移除了非SAM 3D生成的负样本(例如基于检索的方法或多视图扩散纹理生成),因为它们超出了SAM 3D的分布。
在模型蒸馏目标中,作者采用流匹配蒸馏技术来减少推理步骤,同时最小化对质量的影响。具体来说,我们采用~\citet{frans2024one}的扩散快捷公式,该公式相对于之前的连续性蒸馏方法具有几个优势:(1)它很简单,避免了多阶段训练和不稳定性;(2)该模型支持两种模式,允许无缝切换回原始的流匹配推理,因此一个单一模型可以服务于两种目的。与原始公式不同,我们不是从头开始训练快捷模型。相反,我们从完全训练的检查点初始化,并进一步使用快捷目标进行微调。
LS(θ)=Ex0∼N(0,I),x1∼q(x),τ,d∼p(τ,d)[Flow-Matching∥v−vθ(xτ,c,τ,d=0)∥2+Self-Consistency∥vconsistency−vθ(xτ,c,τ,2d)∥2].其中:
- x0∼N(0,I):从标准正态分布中抽取的高斯噪声样本。
- x1∼p(x):从数据分布中抽取的真实数据样本。
- xτ:在时间步τ处介于x0和x1之间的插值样本。(通过论文中前面定义的扩散/流匹配路径定义。)
- τ:扩散时间(或噪声水平),模型在该时间步预测局部速度或更新步骤。
- d:指定快捷模型应预测的步长的步长。d=0对应于流匹配,d>0对应于一致性训练。
- c:条件token。
- p(τ,d):训练期间用于采样扩散时间和步长的联合采样分布。
- vθ(xτ,c,τ,d):由θ参数化的快捷模型,输入为当前样本xτ,条件c,时间τ,和期望步长d。
- v:用于流匹配目标的实证瞬时数据流速度(对应于d=0)。
- vconsistency:自一致性目标,通过组合两个大小为d的步骤来形成大小为2d的单跳的参考。\ref{alg:consistency}描述了如何构建vconsistency。
见框架图
在纹理与细化训练细节中,作者遵循与几何模型类似的多阶段训练范式。在预训练阶段,作者从Iso-3DO-500K开始训练模型,这是一个具有高美学的Iso-3DO数据的分区。在预训练数据中,我们从3D网格渲染条件图像。我们引入了随机光照增强,其中对于每个视图,我们在渲染引擎中应用随机光照设置。我们希望模型能够学习在生成纹理时去除光照效果。在中期训练中,我们在RP-3DO(FO和OS-A)上进行训练。正是从这个阶段开始,我们额外为模型提供了完整的图像条件,因为我们认为上下文线索可以帮助模型预测合理的纹理,尤其是在物体被严重遮挡的情况下。我们展示了在RP-3DO(FO)上训练的效果,以及进一步添加RP-3DO(OS-A)训练数据到此阶段的效果,在\ref{fig:ablations_texture}中。我们还为RP-3DO(FO)引入了图像数据增强:\textbf{掩码}增强和\textbf{模糊}增强。掩码增强随机侵蚀或扩张输入掩码。这是为了处理推理时掩码中的噪声(例如,来自模型的分割预测)。模糊增强对图像应用下采样操作,然后进行上采样操作。这对于处理运动模糊和图像中的小物体尤其重要。这些增强在\ref{sec:texture_eval}中进行了仔细研究。在监督微调(SFT)阶段,模型在MITL-3DO纹理注释上进行训练,其中包括在\ref{sec:data_eng_img_obj_selection}中描述的“美学”样本。我们展示了将MITL-3DO纹理注释缩放2倍的效果,在\ref{fig:ablations_texture}中,这将人类偏好率提高了14.2%。与几何模型类似,我们运行一个最终的DPO阶段,以对齐从纹理数据引擎收集的人类偏好。DPO对纹理性能的影响在\ref{table:stage}和\ref{fig:ablations_texture}中都有显示。我们遵循与方程~\eqref{eq:dpo}中描述的相同训练目标。
Experiment
- 通过合成数据预训练、中期训练和真实数据后训练的多阶段训练策略,SAM 3D实现了从合成到真实世界数据的平稳迁移,并通过人类偏好数据驱动的飞轮机制持续优化模型性能。
- 在SA-3DAO和Aria Digital Twin数据集上,SAM 3D在3D布局预测任务中显著优于现有Pipeline方法和联合生成模型(如MIDI),在3D IoU、ADD-S等指标上均取得领先,尤其在ADD-S @ 0.1指标上提升至77%,展现出强大的真实场景泛化能力。
- 人类偏好评估显示,SAM 3D在单物体生成、纹理渲染和3D场景重建方面均以5:1至6:1的胜率显著优于现有SOTA方法,尤其在遮挡、密集场景和长尾类别中表现突出。
- 通过引入基于视觉语言模型的Best-of-N搜索与奖励模型筛选,有效提升了对困难样本(如食物类)的标注成功率,使标注数据中困难类占比提升9倍,显著加速了对齐过程的收敛。
- 在测试时优化阶段,将SAM 3D的布局预测结果用于渲染-比较优化,进一步提升了Aria Digital Twin上的3D IoU和2D掩码IoU,验证了其作为高质量初始提案的潜力。
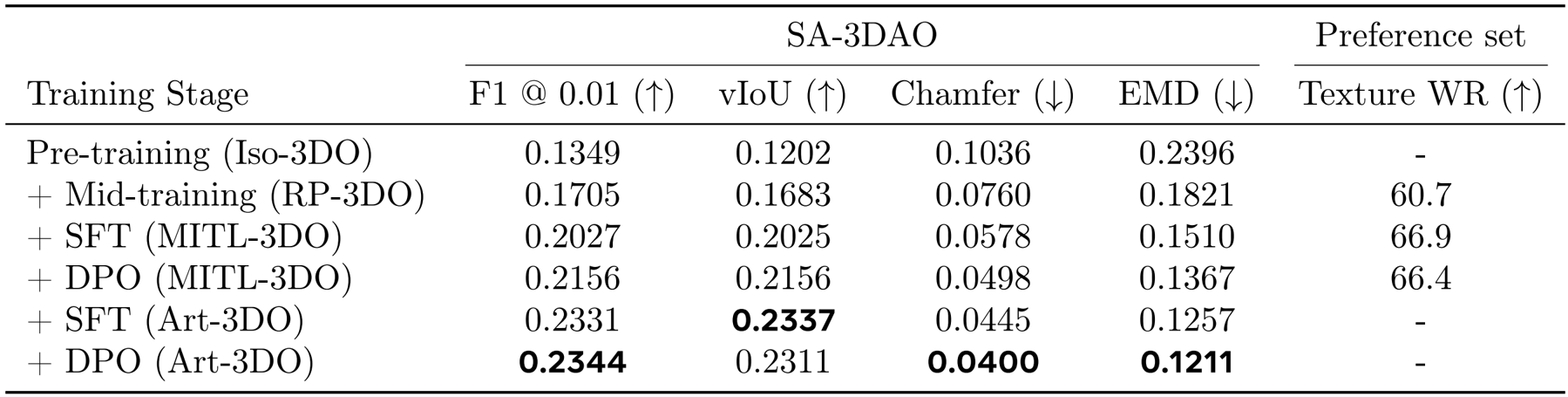
作者利用了多阶段训练策略,将SAM 3D的训练分为几何模型和纹理与精修模型两个阶段,每个阶段均包含预训练、中段训练、监督微调和对齐四个步骤。结果显示,该训练流程通过逐步引入真实世界数据和人类偏好反馈,实现了从合成数据到真实数据的平稳过渡,并在多个评估任务中显著提升了模型性能。
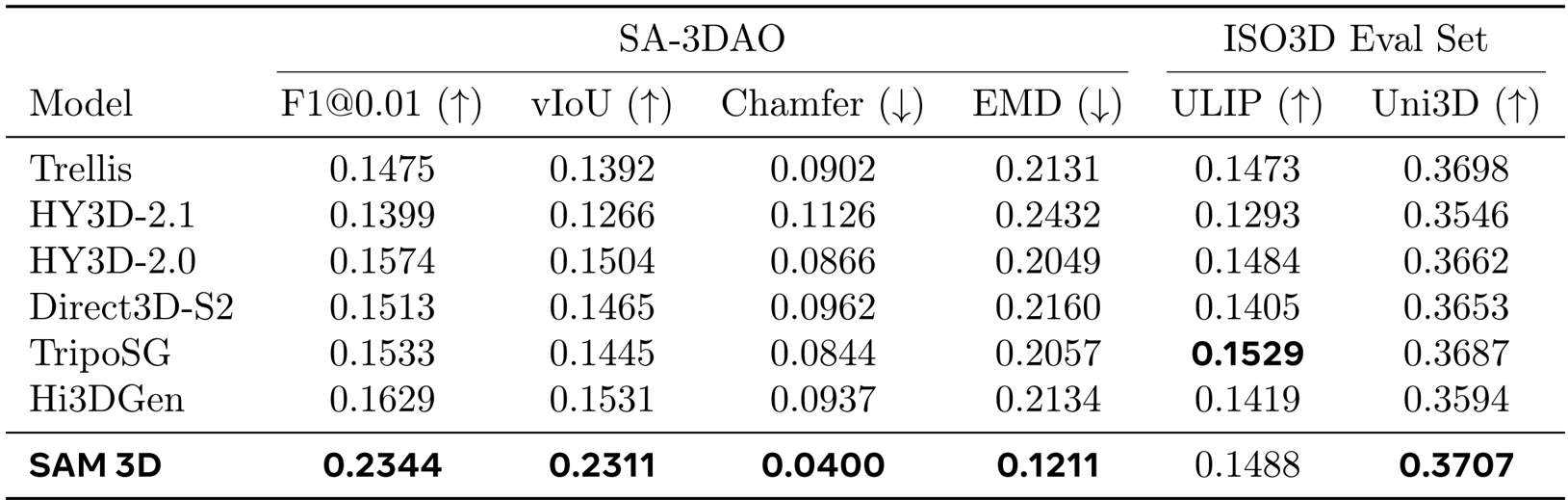
作者利用该表格对SAM 3D与多个现有方法在SA-3DAO和ISO3D数据集上的3D形状生成性能进行了定量比较,结果显示SAM 3D在所有评估指标上均显著优于其他方法,尤其在SA-3DAO数据集上的[email protected]、vIoU和Chamfer距离等关键指标上表现突出。在ISO3D评估集上,SAM 3D在ULIP和Uni3D两个感知相似性指标上也取得了最佳结果,表明其生成的3D形状在视觉质量和与输入图像的匹配度方面具有更强的鲁棒性。
作者利用SAM 3D在SA-3DAO和Aria Digital Twin数据集上与多种现有方法进行了对比,结果显示SAM 3D在联合生成模式下显著优于所有管道式方法和基线模型。在SA-3DAO数据集上,SAM 3D的3D IoU达到0.4254,ICP-Rot.降低至20.7667,ADD-S降至0.2661,ADD-S @ 0.1提升至0.7232;在Aria Digital Twin数据集上,其3D IoU为0.4970,ICP-Rot.为15.2515,ADD-S为0.0765,ADD-S @ 0.1为0.7673,各项指标均大幅领先。

作者利用多阶段训练策略逐步提升模型性能,结果显示随着训练阶段的增加,模型在SA-3DAO数据集上的各项几何质量指标持续提升,其中[email protected]、vIoU和Chamfer距离等指标在最终阶段达到最优。在偏好数据集上,通过SFT和DPO阶段的联合优化,模型在纹理偏好上的得分也显著提高,表明该训练流程有效增强了模型对真实世界数据和人类偏好的适应能力。