Command Palette
Search for a command to run...
Docling:一种高效的开源AI驱动文档转换工具包
Docling:一种高效的开源AI驱动文档转换工具包
一键部署文档解析神器 Docling
摘要
我们推出了Docling,这是一个易于使用、自包含的MIT许可开源工具包,用于文档转换,能够将多种流行的文档格式解析为统一且结构丰富的表示形式。它由最先进的专用AI模型提供支持,包括用于布局分析的DocLayNet和用于表格结构识别的TableFormer,并在普通硬件上以较小的资源开销高效运行。Docling作为Python包发布,可用作Python API或命令行工具(CLI)。其模块化架构和高效的文档表示使得实现扩展、新功能、模型和自定义变得简便。Docling已集成到其他流行的开源框架中(例如LangChain、LlamaIndex、spaCy),使其成为文档处理和高阶应用开发的理想选择。开源社区已全面参与Docling的使用、推广和发展,在不到一个月的时间内GitHub星标数达到10万,并于2024年11月被评为全球GitHub排名第一的趋势仓库。
一句话总结
Docling 是一个开源 Python 工具包,通过分别利用 DocLayNet 和 TableFormer 模型进行版面分析与表格结构识别,将主流文档格式转换为统一且结构丰富的表示形式。其模块化架构能够在资源预算有限的商用硬件上高效运行,并支持与 LangChain、LlamaIndex 和 spaCy 直接集成。
核心贡献
- 推出 Docling,一款开源 Python 工具包,可将 PDF、Office、图像和 HTML 文档解析为统一的 DoclingDocument 表示形式。
- 将 DocLayNet(版面分析)和 TableFormer(表格结构识别)等专用 AI 模型集成至模块化架构中,完全在本地商用硬件上运行,并支持可选的 GPU 加速。
- 通过架构对比验证了转换效率与结构准确性,并通过与 LangChain 和 LlamaIndex 的原生集成以及获得超过 10,000 个 GitHub 星标,展示了其实用价值。
引言
大语言模型与检索增强生成(RAG)的普及,使得从高度多变的文档格式(如 PDF、Office 文件和扫描图像)中提取结构化数据成为必要。长期以来,标准化程度不足与面向打印优化的排版设计使该任务变得复杂,而现有的商业与云端解决方案依然成本高昂、缺乏透明度,且无法兼容本地或隐私敏感型部署。作者利用用于版面分析、光学字符识别(OCR)和表格结构识别的专用 AI 模型来驱动 Docling。这是一款开源 Python 库,完全在本地硬件上执行高保真文档转换。该工具包提供了一种透明、可扩展且面向框架集成的替代方案,弥合了专有系统与有限开源方案之间的质量差距。
数据集
- 构成与来源: 作者主要基于 DocLayNet 集合汇编了包含 89 个 PDF 文件的基准测试集,并整合了来自 CCpdf 的额外样本,以最大化风格与结构多样性。
- 子集详情: 合并后的数据集涵盖 4,008 页,包含 56,246 个文本项、1,842 个表格和 4,676 张图像。作者精心筛选了该特定规模的数据量,以在全面的功能覆盖与可控的基准测试耗时之间取得平衡。
- 数据用途与处理: 该数据集不用于支持模型训练,而是专作为评估基准。作者利用它来衡量不同 AI 模型与系统配置下的文档转换准确率及计算开销。
- 条件处理策略: 为优化效率,处理流水线仅在相关环节执行。OCR 模块仅针对包含位图的页面运行,而表格结构识别仅对具有表格排版的页面触发。这种定向方法确保了准确的单页耗时指标,同时避免了冗余计算。
方法
Docling 采用模块化架构,核心围绕三个组件构建:处理流水线(pipelines)、解析器后端(parser backends)以及 DoclingDocument 数据模型。该设计使系统能够将多样化的文档格式处理为统一的、结构丰富的表示形式,适用于下游应用。DoclingDocument 是一种基于 Pydantic 的数据模型,作为核心数据结构,封装了文本、表格、图表、列表及其他元素,及其层级关系、版面信息(边界框)和来源详情。它提供用于构建、检查以及导出至多种格式的 API,包括无损 JSON 与有损 Markdown 或 HTML。该模型还支持与分块抽象(chunking abstractions)集成,使用户能够生成结构化文档片段,以应用于检索增强生成(RAG)等场景。
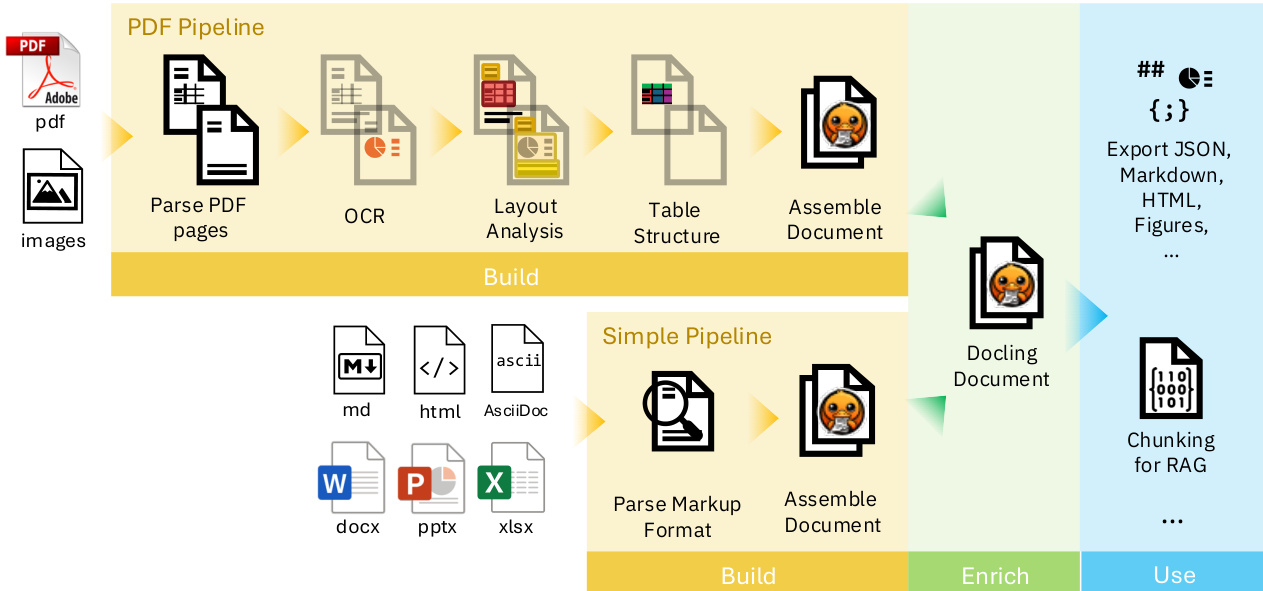
参见框架示意图,该图展示了整体架构。文档转换始于解析器后端,其选择取决于输入格式。对于 PDF 和扫描图像等底层格式,后端会提取带有几何坐标的文本 token,并渲染每页的视觉表示。对于 HTML、Markdown 和 Office 文档等基于标记的格式,后端通过解析语义结构直接构建 DoclingDocument 表示形式。提取的数据随后交由处理流水线进行后续处理。Standard-PdfPipeline 负责处理 PDF 和图像输入,对每页应用一系列 AI 模型以恢复版面与表格结构。SimplePipeline 处理基于标记的格式,并可利用额外模型对其进行增强。两条流水线最终将结果组装为完整的 DoclingDocument。

图中详细展示的 PDF 流水线是一个多阶段处理过程。在完成输入解析与页面渲染后,它会在每页独立应用 AI 模型。版面分析模型基于 RT-DETR 架构并在 DocLayNet 上训练,用于检测与分类页面元素,预测段落、图表和表格等项目的边界框。该模型的输出经过后处理,并与文本 token 进行交集运算,以形成连贯的内容单元。针对表格,采用基于视觉 Transformer 的 TableFormer 模型,通过预测行列边界并识别表头与主体单元格来识别逻辑结构。OCR 技术用于转录扫描图像中的文本,并集成了 EasyOCR 和 Tesseract 等库。最终阶段将所有预测结果组装为 DoclingDocument,并应用后处理以优化阅读顺序和图文匹配等特征。系统的可扩展性支持自定义流水线及新模型(如图表、公式或代码模型)的集成,其模块化设计便于 LangChain 和 LlamaIndex 等框架的采用。
实验
该评估在 x86 CPU、Apple M3 Max 和 Nvidia L4 GPU 配置下,将 Docling 与三款开源 PDF 转换工具进行基准测试,以在标准化资源约束下评估处理速度。独立实验验证了文档复杂度对转换时间的影响,并对各 AI 流水线组件进行性能剖析,以识别计算瓶颈。定性分析表明,处理耗时随内容密度而非页面数量呈比例增长,其中光学字符识别成为资源消耗最大的操作。尽管 GPU 加速显著降低了 AI 驱动任务的处理时间,但性能提升因模型而异。Docling 在 CPU 转换器中始终位列最快梯队,同时在 GPU 硬件上也保持高度竞争力。
作者在不同系统配置(包括纯 CPU、GPU 加速及 Apple Silicon 环境)下,对比了 Docling 与其他开源 PDF 转换工具的性能。结果表明,Docling 在 CPU 和 Apple Silicon 系统上实现了具有竞争力的转换速度,而 MinerU 在 GPU 加速下展现出更优的性能。下表概述了基准测试中各工具所使用的具体版本与配置选项。在 CPU 和 Apple Silicon 系统上,Docling 的转换速度快于其他工具;但在 GPU 加速环境下,MinerU 的表现优于其余工具。各工具的配置选项存在显著差异,体现在 OCR 引擎、版面分析模型以及表格检测方法的不同。GPU 加速为部分工具带来了显著的速度提升,但并非适用于所有工具,这表明各工具在 GPU 适配方面的优化程度存在差异。

该评估在纯 CPU、GPU 加速及 Apple Silicon 环境下,对多款开源 PDF 转换工具进行基准测试,以评估其跨平台效率。结果表明,Docling 在 CPU 和 Apple Silicon 系统上提供具有竞争力的转换速度,而 MinerU 在利用 GPU 加速时实现更优的性能。基准测试还凸显了底层配置的显著差异,这导致了硬件优化表现的不一致,并证明转换性能高度依赖于目标环境及具体工具的实现方式。