Command Palette
Search for a command to run...
AICC:精细化HTML解析,提升模型性能 —— 基于模型HTML解析器构建的7.3T面向AI语料库
AICC:精细化HTML解析,提升模型性能 —— 基于模型HTML解析器构建的7.3T面向AI语料库
摘要
尽管网络数据质量对大型语言模型(LLM)至关重要,但大多数数据治理工作主要集中在过滤和去重上,往往将HTML到文本的提取视为一个固定的预处理步骤。现有的网络语料库依赖于像Trafilatura这样的基于启发式规则的提取器,这些工具难以有效保留文档结构,并且经常破坏公式、代码和表格等结构化元素。我们提出假设:提高提取质量对模型下游性能的提升效果,不亚于激进的过滤策略。为此,我们推出了MinerU-HTML,这是一种全新的提取处理流程(pipeline),它将内容提取转化为由一个0.6B(6亿)参数语言模型解决的序列标注问题。不同于基于文本密度的启发式方法,MinerU-HTML利用语义理解能力,并采用两阶段格式化流程,在转换为Markdown格式之前显式地对语义元素进行分类。关键在于,这种基于模型的方法具有内在的可扩展性,而启发式方法的提升空间非常有限。在包含7,887个标注网页的自研基准测试集MainWebBench上,MinerU-HTML实现了81.8%的ROUGE-N F1分数,而Trafilatura仅为63.6%;同时,MinerU-HTML在结构化元素保留方面表现卓越(代码块保留率为90.9%,公式为94.0%)。利用MinerU-HTML,我们基于两个Common Crawl快照构建了AICC(AI-ready Common Crawl),这是一个包含7.3万亿Token的多语言语料库。在受控预训练实验中,我们将AICC与经由Trafilatura提取的TfCC进行相同的过滤处理,结果显示,在AICC(62B Token)上训练的模型在13个基准测试中的平均准确率达到50.8%,超越TfCC 1.08个百分点(pp)。这直接证明了提取质量显著影响模型能力。此外,AICC在关键基准测试上的表现也优于RefinedWeb和FineWeb。目前,我们已公开发布MainWebBench、MinerU-HTML和AICC,旨在表明HTML提取是网络语料库构建中一个关键却往往被低估的环节。
摘要
上海人工智能实验室的研究人员提出了 MinerU-HTML,该方法通过一个 0.6B 参数的模型将 HTML 提取视为序列标注问题,以更好地保留结构,并利用它构建了 AICC,这是一个包含 7.3 万亿 token 的语料库,在大型语言模型预训练基准测试中优于现有的基于启发式的数据集。
引言
大型语言模型 (LLM) 严重依赖像 Common Crawl 这样的大规模网络数据集,其中数据治理的质量是性能的主要驱动力。虽然最近的工作优化了过滤和去重,但将原始 HTML 转换为结构化文本这一基础步骤通常被视为固定的预处理任务,尽管它是数据保真度的关键瓶颈。
当前的提取工具依赖于僵化的启发式方法和手工制定的规则,难以应对现代网页的视觉复杂性。这些方法经常无法区分主要内容与广告和导航菜单等样板元素。此外,它们经常破坏或剥离结构化数据,如数学公式、代码块和表格,导致技术训练所需的语义上下文大量丢失。
作者通过引入 AICC (AI-ready Common Crawl) 来解决这一疏忽,这是一个通过名为 MinerU-HTML 的新型提取流程生成的预训练语料库。该系统不再依赖静态规则,而是将内容提取重新表述为由紧凑语言模型解决的序列标注问题,从而确保保留原始网页内容的结构和叙事连贯性。
关键创新和优势包括:
- 基于模型的提取: 该系统利用一个 0.6B 参数的模型来理解语义上下文,使其能够准确地将主要内容与噪声分离,而不依赖于脆弱的文本密度启发式方法。
- 高保真结构保留: 该流程在保留复杂元素方面显著优于现有工具,在代码块和数学公式上实现了高编辑相似度得分,而这些通常在标准提取过程中丢失。
- 卓越的下游性能: 在 AICC 语料库上预训练的模型在各种基准测试中表现出比在 FineWeb 和 RefinedWeb 等领先数据集上训练的模型更高的准确性,证明了提取质量直接影响模型能力。
数据集
作者构建了三种不同的数据资源来训练模型、生成大规模语料库并评估性能。
-
训练数据集
- 组成: 870,945 个标注样本,旨在涵盖各种网页布局和格式。
- 来源: 源自 Common Crawl,作者最初根据 DOM 树特征对页面进行聚类,以识别出 4000 万个布局独特的候选页面。
- 处理: 该池被过滤为一个涵盖多种语言的 100 万页面的平衡子集。最终的块级标注是使用简化算法结合大型语言模型 (LLM) 标注生成的。
-
AICC (以 AI 为中心的语料库)
- 组成: 一个包含 3720 亿 token 的大规模多语言网络语料库。
- 来源: 使用 MinerU-HTML 工具从两个 Common Crawl 快照 (CC-2023-06 和 CC-2023-14) 中提取。
- 过滤: 该流程应用精确去重 (SHA-256)、FastText 语言识别、基于 Gopher 的质量启发式方法、通过黑名单进行的安全过滤以及使用 MinHash 的模糊去重。
-
MainWebBench (评估基准)
- 组成: 7,887 个精心标注的网页,包含原始 HTML、真实 DOM 子树和 Markdown 表示。
- 来源: 采用混合策略,其中 90% 的页面从 Common Crawl 采样以覆盖长尾内容,10% 来自高流量网站 (Chinaz Alexa) 以代表专业设计的页面。
- WebMainBench-Structured 子集: 从主基准中选出的 545 个页面的重点集合。这些页面专门包含高密度的数学公式、代码块和表格,用于评估结构化元素的保留情况。
-
标注和元数据策略
- 标注原则: 人类标注员遵循基于“上下文完整性”(包括摘要等必要上下文)和“人类生成内容”(排除自动生成的元数据)的三阶段审查流程。
- 元数据构建: 该基准包含丰富的元数据,例如由 GPT-5 生成的语言和风格分类。
- 难度评分: 作者根据 DOM 结构复杂性、文本分布稀疏性、内容类型多样性和链接密度,计算了每个页面的定量“难度等级”。
方法
作者利用一个名为 MinerU-HTML 的两阶段流程,从原始 HTML 中提取高质量内容并将其转换为 AI-ready 格式。第一阶段侧重于提取原始文档的一个清洗后的子集,称为 Main-HTML,它仅包含承载内容的元素。第二阶段将此 Main-HTML 转换为结构化的、AI-ready 格式,如 Markdown,用于下游语言模型训练。
第一阶段的核心是 Main-HTML 提取的三阶段流程,旨在解决处理长 HTML 的计算负担,并确保忠实的内容提取而无幻觉。如下图所示,该流程从预处理开始,输入 HTML 被划分为语义块,生成两种同步表示:简化 HTML(剥离面向渲染的标记以创建语言模型的紧凑输入)和映射 HTML(保留原始块结构以实现忠实重建)。 
预处理阶段应用四种顺序变换,在保留语义信息的同时减少序列长度。这些包括非内容标签移除(例如 <style>、<script>)、属性简化(仅保留 class 和 id)、在渲染期间引起换行的元素处进行块级分块,以及对过长块的部分内容截断。此阶段的输出是一系列简化块,表示为 x=[x1,x2,…,xn],以及一个保持原始 DOM 结构的映射 HTML。
在分类阶段,该流程采用 MinerU-HTML-Classifier(一个紧凑的 0.6B 参数语言模型)来处理简化 HTML,并将每个块分类为主要内容或样板。此任务被公式化为序列标注问题,其中模型将输入序列 X=[x1,x2,…,xn] 映射到预测标签序列 Ypred=fθ(X)。为了确保有效的输出格式并消除幻觉,自定义 logits 处理器实现了受限解码。该处理器充当确定性有限状态机,强制执行严格的类 JSON 输出格式,并将模型的词汇表限制为仅两个 token:“main”和“other”,从而保证语法上有效的输出。
最后阶段是后处理,预测的标签被投影回映射 HTML。非内容块被修剪,剩余的承载内容的块被组装成最终的 Main-HTML,它构成了原始 DOM 的有效子树。
为了将此方法扩展到网络规模的 Common Crawl,作者引入了模板感知优化策略。该策略利用网页的结构规律性,对从相似模板生成的页面进行聚类。对于每个聚类,选择一个代表性页面,并执行完整的三阶段流程。然后分析模型的分类决策以导出通用的 XPath 或 CSS 选择器,这些选择器使用高效的基于 CPU 的处理传播到聚类中的所有其他页面。这种方法大大减少了需要基于 GPU 的语言模型推理的页面数量,在实现网络规模处理的同时保留了核心提取流程的质量。
流程的第二阶段将提取的 Main-HTML 转换为 AI-ready 格式。这是通过两阶段转换策略实现的。首先,Main-HTML 被解析为结构化内容列表,这是一种基于 JSON 的表示,明确地按类型(例如标题、段落、代码块、表格、公式)对每个语义单元进行分类。这种中间表示支持灵活的过滤和特定格式的渲染。其次,内容列表被转换为目标格式,Markdown 是语言模型训练的主要输出。转换过程遍历内容列表元素,并应用特定于类型的渲染规则,将每个语义类型映射到其相应的 Markdown 语法。
实验
- 主要内容提取: 使用 ROUGE-N F1 在 MainWebBench 数据集上进行评估。MinerU-HTML 取得了 0.8182 的最先进得分,显著超过了最佳基线 Trafilatura (0.6358),在对话内容、表格和数学方程方面取得了显著收益。
- 结构化元素保留: 使用编辑相似度和 TEDS 指标评估代码、公式和表格的保真度。该方法表现出卓越的性能,代码块得分为 0.9093(Trafilatura 为 0.1305),数学公式为 0.9399,表格结构为 0.7388。
- 泛化能力: 在 Web Content Extraction Benchmark (WCEB) 上进行测试,以验证跨不同来源的鲁棒性。MinerU-HTML 获得了 0.8002 的总分,优于最强的基线 (0.7833)。
- 效率分析: 验证了预处理流程对计算可行性的影响。与原始 HTML 处理相比,该方法将输入 token 减少了约 87%(从 44,706 减少到 5,735),从而实现了高效推理。
- 质量评估: 使用 LLM-as-a-judge 协议对 10,000 个文档进行了成对评估。MinerU-HTML 的提取结果在 72.0% 的情况下优于 Trafilatura 的提取结果,表明其保留了更多有价值的主要内容。
- 下游预训练性能: 比较了在来自各种语料库的 62B token 上训练的 1.5B 参数模型。在 MinerU-HTML 数据 (AICC) 上训练的模型在 13 个基准测试中取得了 50.82% 的平均准确率,优于 FineWeb (49.61%)、RefinedWeb (49.13%) 和 TfCC (49.74%)。
作者使用 ROUGE-N F1 评估主要内容提取,结果显示 MinerU-HTML 取得了相对于基线方法的显著改进,总分为 0.8182,而 Resiliparse 为 0.6233,Trafilatura 为 0.6237。MinerU-HTML 在具有挑战性的内容类型(包括对话内容、表格和数学方程)上表现出特别强的性能,在这些方面它大幅超越了基线。

结果显示,MinerU-HTML 在保留结构化元素方面显著优于 Trafilatura 和 Resiliparse,代码块的编辑相似度得分为 0.9093,数学公式为 0.9399,同时表格结构保留的 TEDS 得分达到 0.7388。这些结果表明,MinerU-HTML 有效地维护了复杂内容结构的完整性,而这些结构通常在基于启发式的提取方法中丢失。
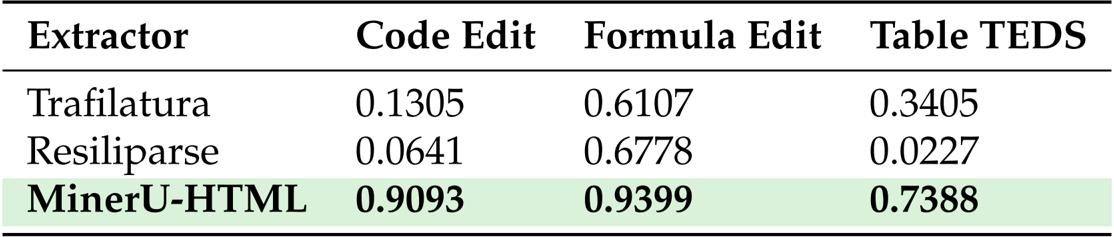
作者使用 ROUGE-N F1 评估主要内容提取,MinerU-HTML 取得了 0.8002 的总分,优于 Trafilatura (0.7833) 和 Resiliparse (0.7225)。结果显示,MinerU-HTML 在各个难度级别上都保持了强劲的性能,特别是在简单和中等难度的内容上表现出色,分别取得了 0.8293 和 0.8005 的得分。