HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
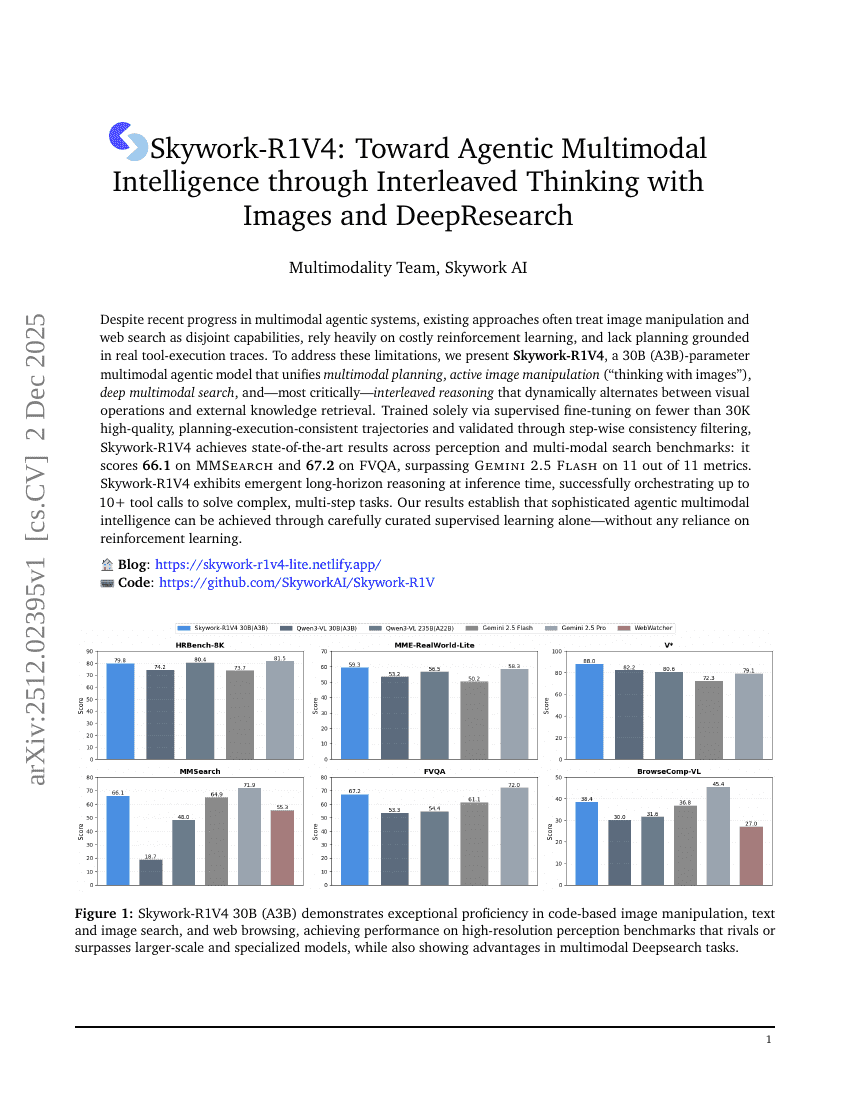
Skywork-R1V4:通过图像与DeepResearch的交织思维迈向智能多模态代理
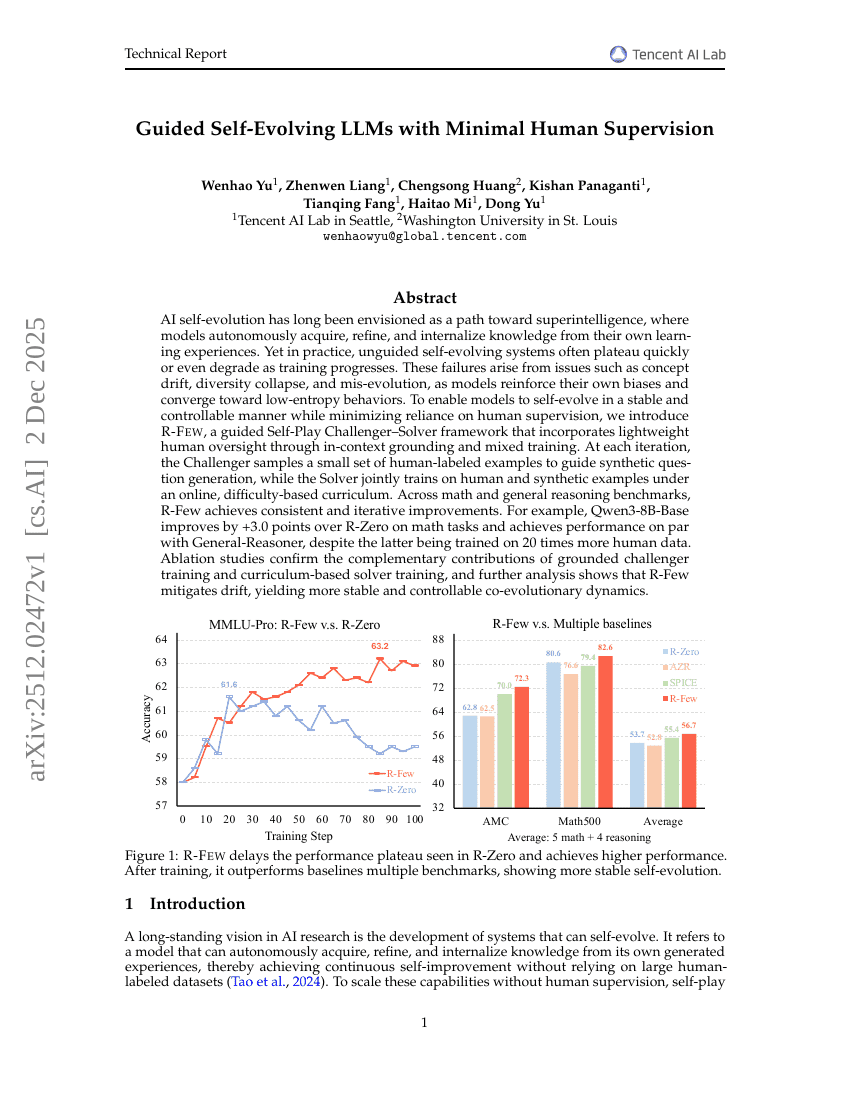
基于最小人类监督的引导式自进化LLM





























Skywork-R1V4:通过图像与DeepResearch的交织思维迈向智能多模态代理
基于最小人类监督的引导式自进化LLM
MultiShotMaster:一种可控制的多镜头视频生成框架
MG-Nav:通过稀疏空间记忆实现的双尺度视觉导航
一致性评论者:通过参考引导的注意力对齐修正生成图像中的不一致性
我们距离真正有用的深度研究Agent还有多远?
基于LLM的强化学习稳定性优化:方法与实践
Envision:面向因果世界过程洞察的统一理解与生成基准测试
LongVT:通过原生工具调用激励“以长视频进行思考”
从代码基础模型到Agent与应用:代码智能实用指南
基于物理驱动的时空建模用于AI生成视频检测
Mem-α:通过强化学习学习记忆构建
搜索自对弈:在无监督条件下推进Agent能力的边界
CudaForge:一种支持硬件反馈的CUDA内核优化Agent框架
ScaleNet:通过增量参数扩展预训练神经网络
优化块注意力混合
分形取证:通过分形水印实现主动式深度伪造检测与定位
思维链劫持
InstanceAssemble:通过实例组装注意力实现布局感知的图像生成
3EED:在三维空间中处处实现万物具身化
DetectiumFire:一个全面的多模态数据集,连接视觉与语言以实现火灾理解
CHIP:工业场景中椅子6D位姿估计的多传感器数据集
几何约束Agent用于空间推理
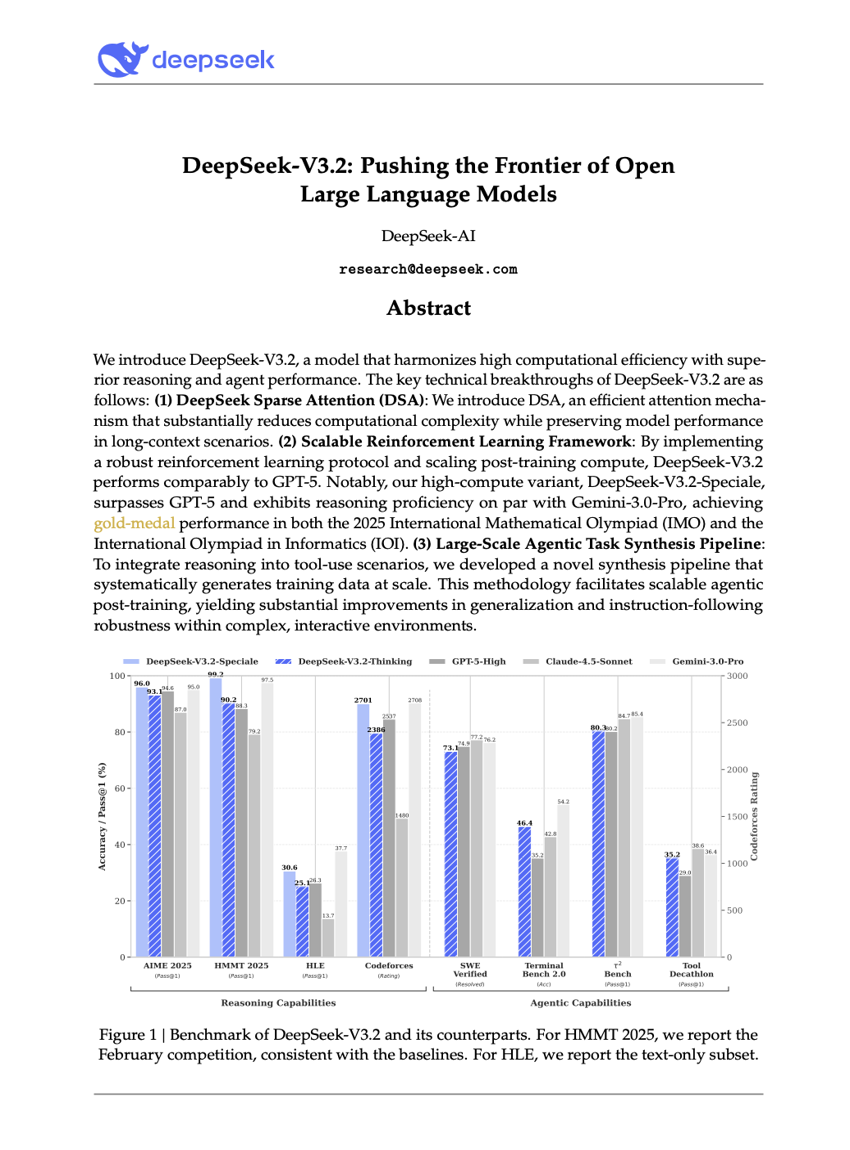
DeepSeek-V3.2:推动开源大型语言模型的前沿
DiP:在像素空间中驯服扩散模型
架构解耦并非构建统一多模态模型的全部所需
大规模视觉桥接Transformer
AnyTalker:通过交互式优化实现多人物对话视频生成的扩展
REASONEDIT:面向推理增强的图像编辑模型
OpenApps:通过模拟环境变化来衡量UI-Agent的可靠性
通义千问3-VL 技术报告
G2VLM:具有统一3D重建与空间推理能力的几何引导视觉语言模型
MultiShotMaster:一种可控制的多镜头视频生成框架
MG-Nav:通过稀疏空间记忆实现的双尺度视觉导航
一致性评论者:通过参考引导的注意力对齐修正生成图像中的不一致性
我们距离真正有用的深度研究Agent还有多远?
基于LLM的强化学习稳定性优化:方法与实践
Envision:面向因果世界过程洞察的统一理解与生成基准测试
LongVT:通过原生工具调用激励“以长视频进行思考”
从代码基础模型到Agent与应用:代码智能实用指南
基于物理驱动的时空建模用于AI生成视频检测
Mem-α:通过强化学习学习记忆构建
搜索自对弈:在无监督条件下推进Agent能力的边界
CudaForge:一种支持硬件反馈的CUDA内核优化Agent框架
ScaleNet:通过增量参数扩展预训练神经网络
优化块注意力混合
分形取证:通过分形水印实现主动式深度伪造检测与定位
思维链劫持
InstanceAssemble:通过实例组装注意力实现布局感知的图像生成
3EED:在三维空间中处处实现万物具身化
DetectiumFire:一个全面的多模态数据集,连接视觉与语言以实现火灾理解
CHIP:工业场景中椅子6D位姿估计的多传感器数据集
几何约束Agent用于空间推理
DeepSeek-V3.2:推动开源大型语言模型的前沿
DiP:在像素空间中驯服扩散模型
架构解耦并非构建统一多模态模型的全部所需
大规模视觉桥接Transformer
AnyTalker:通过交互式优化实现多人物对话视频生成的扩展
REASONEDIT:面向推理增强的图像编辑模型
OpenApps:通过模拟环境变化来衡量UI-Agent的可靠性
通义千问3-VL 技术报告
G2VLM:具有统一3D重建与空间推理能力的几何引导视觉语言模型