Command Palette
Search for a command to run...
基于深度研究的通用 Agent 记忆
基于深度研究的通用 Agent 记忆
B. Y. Yan Chaofan Li Hongjin Qian Shuqi Lu Zheng Liu
摘要
对于人工智能(AI)智能体而言,记忆至关重要。然而,目前广泛采用的“静态记忆”(static memory)机制旨在提前生成立即可用的记忆,这种方式不可避免地面临着严重的信息丢失问题。为解决这一局限,我们提出了一种名为“通用智能体记忆”(General Agentic Memory, GAM)的全新框架。GAM 遵循“即时编译”(Just-In-Time, JIT)的原则:在离线阶段仅保留虽简单但具实用价值的记忆,而在运行时专注于为其客户端构建经过优化的上下文。为此,GAM 采用了包含以下组件的双模块设计:记忆器(Memorizer):利用轻量级记忆机制提炼关键的历史信息,同时将完整的历史记录保存在通用的“页面存储库”(page-store)中。研究器(Researcher):在预构建记忆的引导下,针对在线请求从页面存储库中检索并整合有效信息。这一设计使得 GAM 能够充分发挥前沿大语言模型(LLM)的智能体能力与测试时的可扩展性(test-time scalability),同时支持通过强化学习实现端到端的性能优化。实验研究表明,相较于现有的记忆系统,GAM 在各类基于记忆的任务完成场景中均取得了显著的性能提升。
总结
来自北京智源人工智能研究院、北京大学和香港理工大学的研究人员推出了通用智能体记忆 (GAM),这是一个克服静态记忆限制的框架,它应用即时编译原则,通过双重“记忆者-研究者”架构,从通用页面存储中动态构建优化上下文,以增强基于记忆的任务完成能力。
简介
AI 智能体正越来越多地部署在软件工程和科学研究等复杂领域,这使得管理迅速扩展的上下文变得迫在眉睫。随着这些智能体将内部推理与外部反馈相结合,有效的记忆系统对于在不超出模型上下文窗口的情况下保持连续性和准确性至关重要。
先前的方法通常依赖于“提前”编译,即数据在离线状态下被压缩成静态记忆。这种方法在压缩过程中难免会有信息丢失,由于结构僵化而难以应对临时请求,并且严重依赖阻碍跨域泛化的人工启发式规则。
作者提出了通用智能体记忆 (GAM),这是一个基于“即时”编译的框架,它在保存完整历史数据的同时按需生成定制的上下文。通过将记忆检索视为动态搜索过程而非静态查找,GAM 通过双智能体系统确保了针对特定查询的无损信息访问。
关键创新包括:
- 双智能体架构: 该系统采用“记忆者 (Memorizer)”来索引历史会话,并采用“研究者 (Researcher)”进行迭代式深度研究和反思,以满足复杂的客户需求。
- 高保真适应性: 通过在数据库中维护完整历史记录并在运行时仅检索必要内容,该框架避免了压缩损失,并能动态适应特定任务。
- 自优化泛化: 该方法消除了对特定领域规则的需求,允许系统在各种场景中运行,并通过强化学习持续改进。
方法
作者为其通用智能体记忆 (GAM) 系统利用了一种双模块架构,旨在高效管理长智能体轨迹的同时保持任务性能。该框架在两个不同的阶段运行:离线记忆阶段和在线研究阶段。如下图所示,整个系统由一个记忆者和一个研究者组成,两者都是基于大型语言模型 (LLM) 的智能体。记忆者在离线阶段处理智能体的历史轨迹,生成紧凑的记忆表示,并将完整轨迹保存在页面存储中。相比之下,研究者在线运行以处理客户请求,通过从页面存储中检索和整合相关信息,最终为下游任务完成生成优化的上下文。
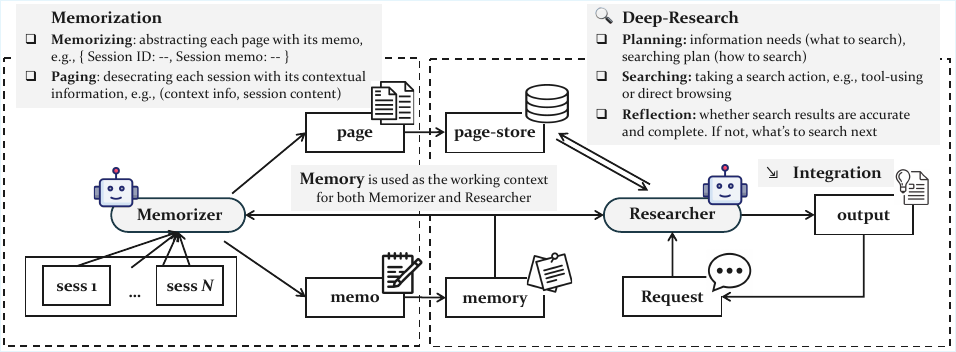
在离线阶段,记忆者对每个传入的会话 si 执行两个关键操作。首先,它执行记忆步骤,生成一个简洁且结构良好的备忘录 μi,捕捉新会话的关键信息。该备忘录是基于当前会话和现有记忆 mi 生成的,并且通过添加新备忘录来增量更新记忆以形成 mi+1。其次,记忆者执行分页操作,为会话创建一个完整的页面。该过程首先生成一个包含先前轨迹中基本上下文信息的页眉 hi。然后使用该页眉来修饰会话内容,形成一个附加到页面存储 p 的新页面。这两个步骤的过程确保系统既能维护轻量级、优化的记忆,又能维护智能体历史的全面且语义一致的记录。

在在线阶段,研究者的任务是处理客户的请求。它首先执行规划步骤,这涉及思维链推理,以分析请求 r 的信息需求。基于此分析,研究者使用提供的搜索工具包 T 生成具体的搜索计划,该工具包包括用于向量搜索的嵌入模型、用于基于关键字搜索的 BM25 检索器以及用于直接页面探索的基于 ID 的检索器。规划过程由特定的提示词引导,如下图所示,该提示词指示模型生成一个指定所需工具及其参数的 JSON 对象。

收到搜索计划后,研究者并行执行搜索动作,从页面存储中检索相关页面 pt。然后,它将检索到的页面中的信息与请求 r 的上一次整合结果 I 相结合,更新整合结果。此过程迭代重复。每次整合后,研究者执行反思步骤,以确定是否已完全收集回答请求所需的信息。这是使用二元指示器 y 完成的。如果反思表明信息仍然缺失 (y=No),研究者会生成一个新的、更聚焦的请求 r′ 以驱动另一轮深度研究。如果认为信息已完整 (y=Yes),则研究过程结束,并将最终整合结果作为优化后的上下文返回。反思过程由提示词引导,指示模型识别缺失信息并生成有针对性的后续检索问题。

实验
- 使用 LoCoMo、HotpotQA、RULER 和 NarrativeQA 基准测试,将 GAM 与无记忆方法(Long-LLM、RAG)和基于记忆的基线(例如 Mem0、LightMem)进行了评估对比。
- GAM 在每个数据集上都始终优于所有基线,特别是在其他方法失败的 RULER 多跳追踪任务上达到了超过 90% 的准确率。
- 展示了对不同上下文长度的鲁棒性,在 HotpotQA 上针对 56K 到 448K token 的上下文仍保持高性能。
- 模型扩展分析表明,更大的骨干模型能改善结果,其中研究模块对模型大小的敏感度显著高于记忆模块。
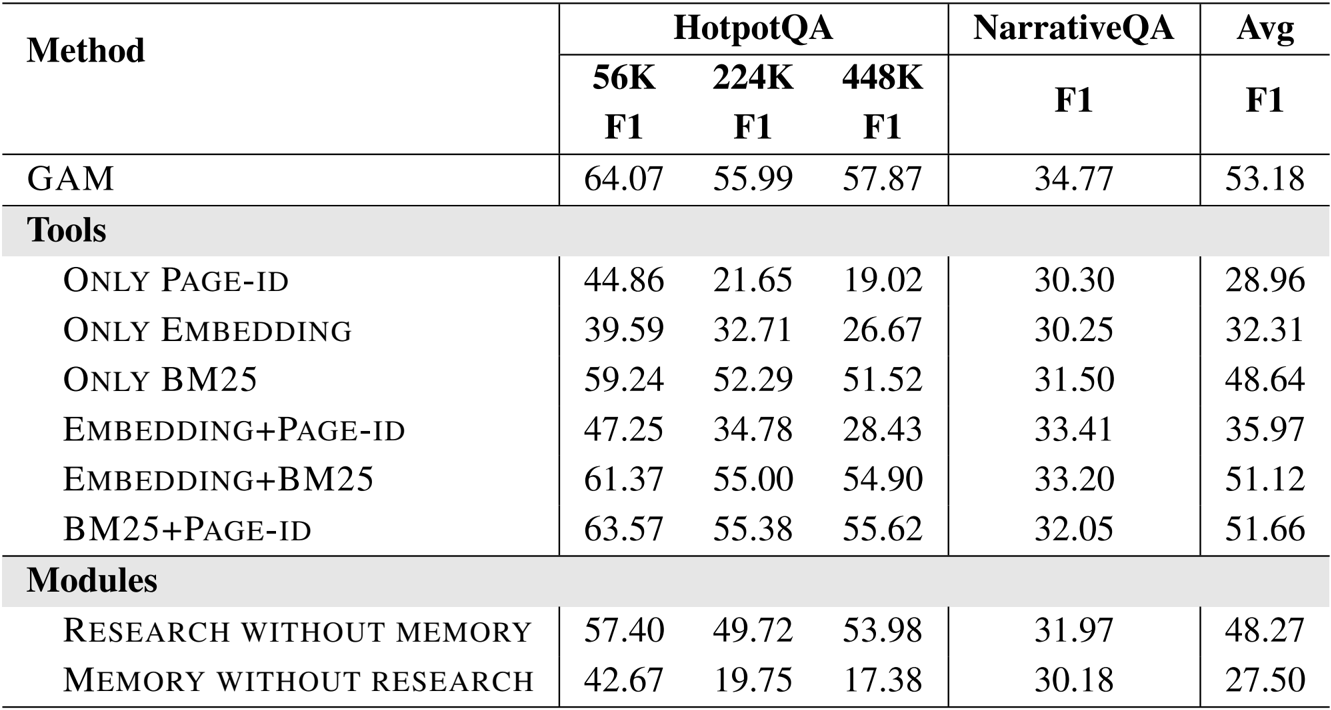
- 消融研究证实,结合搜索工具(Page-id、Embedding、BM25)能产生最佳结果,而移除记忆模块会导致性能大幅下降。
- 增加测试时计算量,特别是通过更高的反思深度和更多检索页面,带来了稳定的性能提升。
- 效率评估显示,GAM 的时间成本与 Mem0 和 MemoryOS 相当,同时提供了更优的成本效益。
作者利用 GAM 在所有基准测试中取得了最佳性能,在 LoCoMo、HotpotQA、RULER 和 NarrativeQA 上始终优于无记忆和基于记忆的基线。结果表明,GAM 显著改进了现有方法,特别是在需要多跳推理和长上下文理解的复杂任务中,同时保持了具有竞争力的效率。
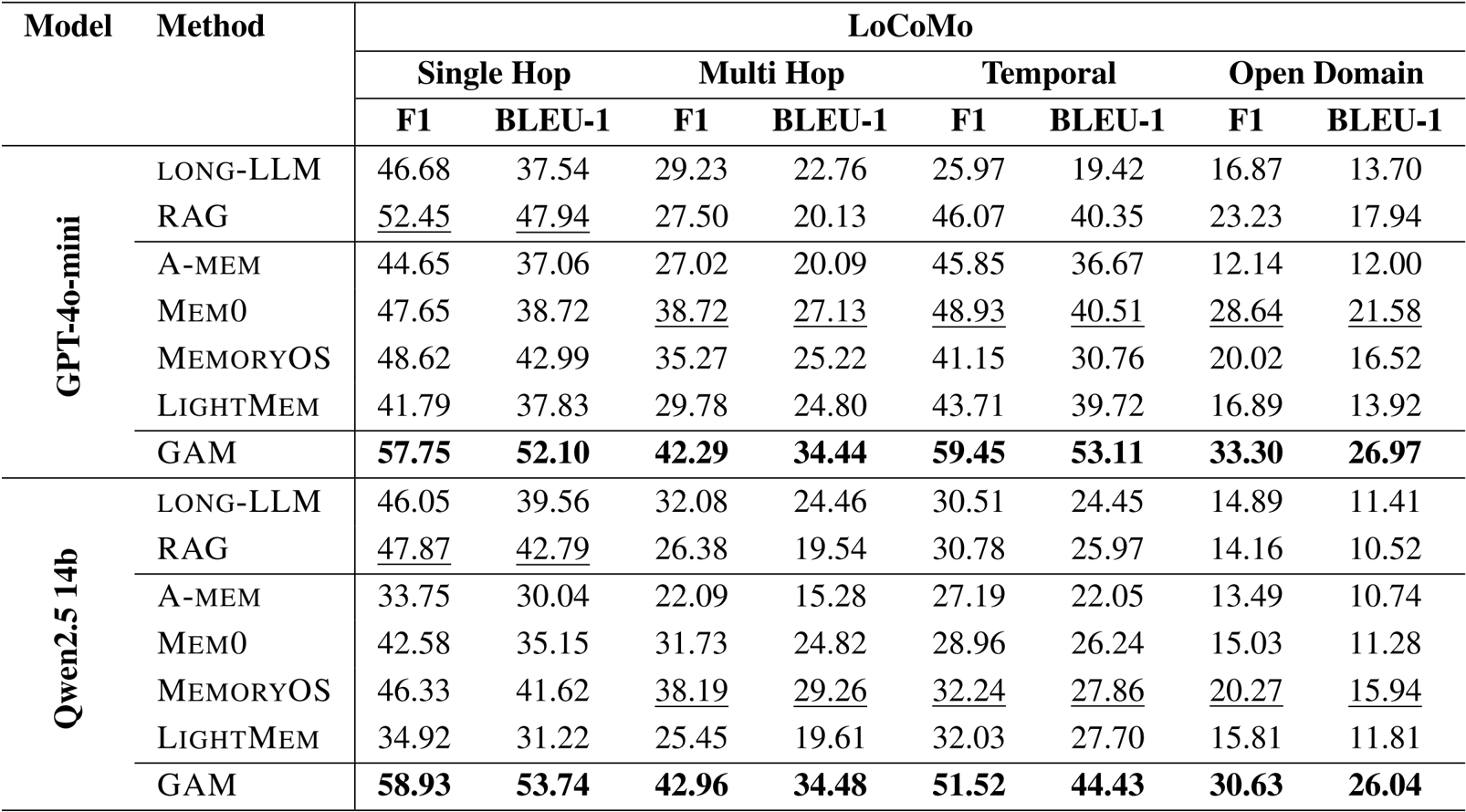
作者利用 GAM 在多个长上下文基准测试中取得了最先进的性能,始终优于无记忆和基于记忆的基线。结果表明,GAM 显著提高了需要多跳推理和检索的复杂任务的准确性,特别是在 HotpotQA 和 RULER 上,它在多跳追踪任务上达到了超过 90% 的准确率,同时在不同的上下文长度下保持了稳定的性能。
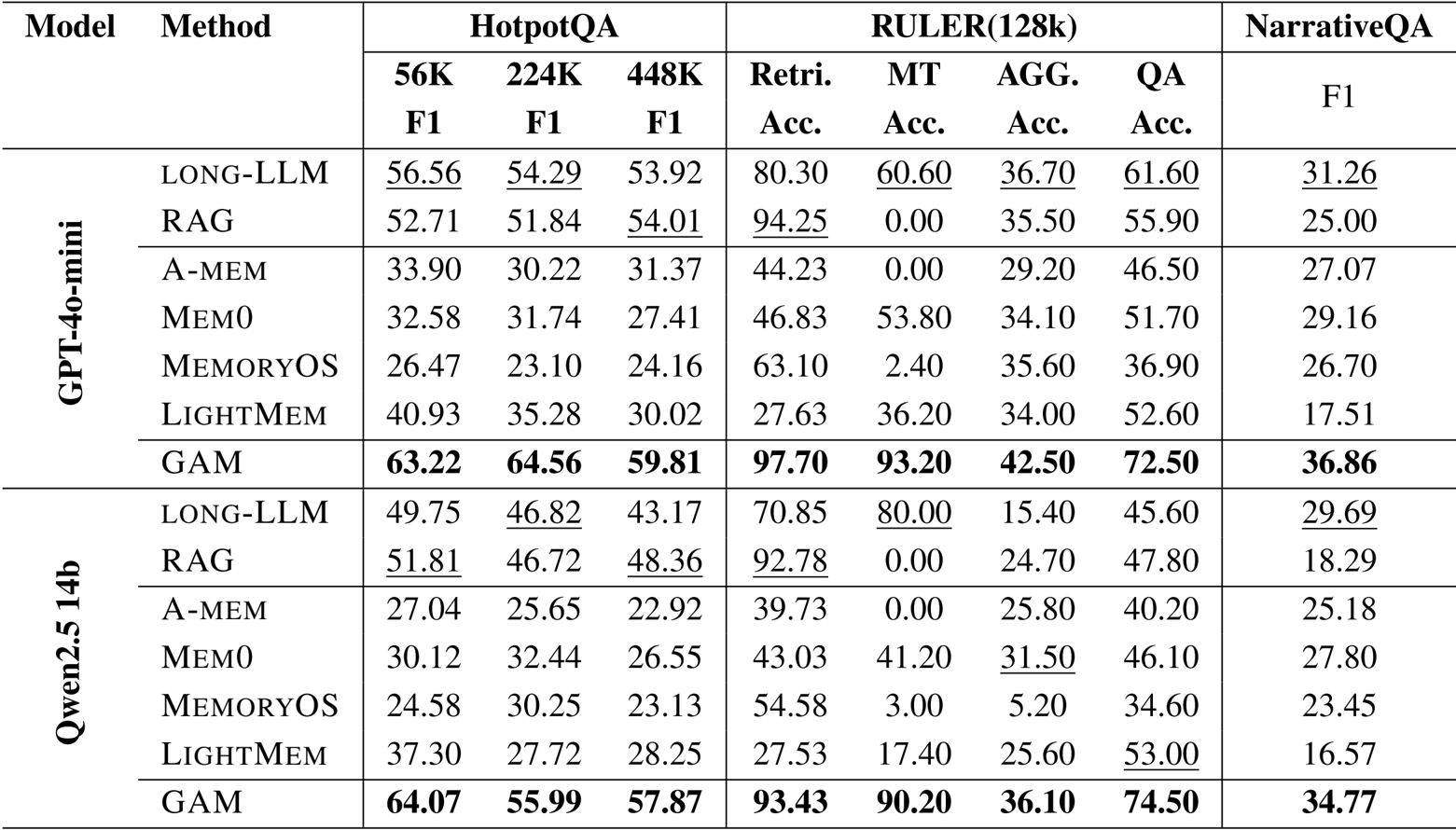
作者使用不同的 LLM 骨干网络运行 GAM,以评估其在 HotpotQA 和 NarrativeQA 上的性能,结果表明较大的模型通常能改善结果。GAM 使用 GPT-4o-mini 取得了最高的平均 F1 分数,优于所有 Qwen2.5 变体,并展示了随着模型尺寸增加而带来的一致增益,特别是在较长的上下文中。
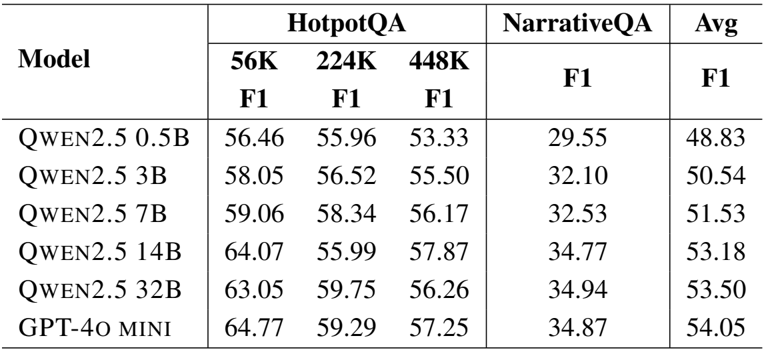
作者使用不同的 LLM 骨干网络运行 GAM,以评估模型大小对性能的影响。结果显示,较大的模型始终能提高性能,其中 GPT-4o-mini 取得了最高的平均 F1 分数 55.45,而最小的 Qwen2.5-0.5B 模型得分最低,为 9.08。
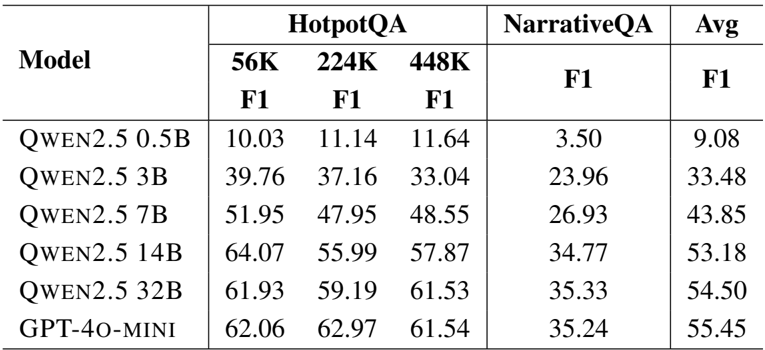
结果显示,GAM 在所有基准测试中均取得了最高性能,通过结合多种搜索工具以及记忆和研究模块,其有效性得到了增强。消融研究表明,使用包含所有工具和模块的完整系统能产生最佳结果,而移除任何组件都会显著降低性能。