Command Palette
Search for a command to run...
GeoVista:面向地理定位的网络增强 Agent 视觉推理
GeoVista:面向地理定位的网络增强 Agent 视觉推理
Yikun Wang Zuyan Liu Ziyi Wang Pengfei Liu Han Hu Yongming Rao
摘要
当前关于代理视觉推理(Agentic Visual Reasoning)的研究虽然实现了深度的多模态理解,但主要集中于图像操作工具,导致其在迈向更通用的代理模型方面仍存在空白。在本研究中,我们重新审视了地理定位(Geolocalization)任务。该任务不仅需要精细的视觉定位能力,还需要在推理过程中利用网络搜索来确认或修正假设。鉴于现有的地理定位基准难以满足高分辨率图像的需求,也无法为深度代理推理提供足够的定位挑战,我们构建了 GeoBench。该基准包含来自世界各地的普通照片和全景图,以及涵盖不同城市的卫星图像子集,旨在严格评估代理模型的地理定位能力。同时,我们提出了 GeoVista,这是一种将工具调用无缝集成至推理回路中的代理模型。该模型集成了用于放大感兴趣区域的图像缩放工具,以及用于检索相关互联网信息的网络搜索工具。我们为其开发了一套完整的训练流程:首先通过冷启动监督微调(SFT)阶段,帮助模型学习推理模式及工具使用的先验知识;随后通过强化学习(RL)阶段,进一步增强其推理能力。我们还采用了分层奖励机制,以有效利用多层级的地理信息,从而提升整体的地理定位性能。实验结果表明,GeoVista 在地理定位任务上大幅超越了其他开源代理模型,并在大多数指标上取得了与 Gemini-2.5-flash 和 GPT-5 等闭源模型相媲美的性能。
Summarization
复旦大学、清华大学联合腾讯混元等提出了 GeoVista,这是一种集成了图像放大与网络搜索工具的视觉推理智能体,配合新构建的 GeoBench 基准及包含分层奖励的强化学习训练策略,在地理定位任务上展现了超越开源模型并媲美顶尖闭源模型的卓越性能。
Introduction
随着视觉语言模型(VLM)的快速演进,特别是OpenAI o3等模型的出现,多模态推理已从简单的单轮问答跨越到能够结合图像操作(如缩放、裁剪)的“图像思维”阶段。地理定位(Geolocalization)作为一种极具挑战的现实场景,天然要求模型既能从高分辨率图像中提取细粒度视觉线索,又能利用外部知识验证假设,因此成为检验这种代理式多模态推理能力的理想试金石。
然而,现有的开源复现工作往往局限于图像操作工具的使用,导致模型在解决问题时仅能依赖内部参数知识,缺乏利用网络搜索等外部工具进行信息检索的能力,这限制了其在复杂现实任务中的上限。
针对这一局限,作者提出了GeoVista模型及其配套的GeoBench基准。作者设计了一套包含冷启动监督微调(SFT)和强化学习(RL)的完整训练流程,使模型能够在动态推理循环中,像人类一样主动决策何时调用视觉工具或网络搜索工具,从而实现精准的地理定位。
该研究的主要技术亮点总结如下:
- 双重工具集成与动态推理:GeoVista无缝集成了“图像缩放”与“网络搜索”工具,能够在多轮交互中动态地提取视觉线索并利用外部检索信息来验证或修正假设,复现了类似闭源模型的复杂推理行为。
- 构建高难度基准GeoBench:作者推出了包含高分辨率照片和全景图的全球覆盖基准测试集,剔除了易识别地标和不可定位样本,支持分级与细粒度的评估,填补了高难度真实场景评测的空白。
- 基于层级化奖励的强化学习:在RL训练阶段,作者利用GRPO算法并结合地理信息的层级特性(如国家-城市-街道),设计了独特的层级化奖励机制,有效激励模型从图像中学习多层次的地理上下文信息。
Dataset
为了确保地理分布的多样性并提升模型的泛化能力,作者构建了 GeoBench 基准测试集以及 GeoVista 训练数据集。以下是关于该数据集构成、来源及处理策略的详细介绍:
-
多源数据采集与构成 作者从全球范围内的城市采集了三种不同类型的原始数据,以避免模型过拟合单一数据类型,所有图像均保证高分辨率(至少 1M 像素):
- 标准照片 (Normal Photos): 采集自互联网,涵盖图书馆、超市、郊区等多样化生活场景,分辨率不低于 1600×1200。
- 全景图 (Panoramas): 通过 Mapillary API 获取全球城市的 360∘ 街景数据,经本地拼接处理转换为平面全景图,分辨率固定为 4096×2048。
- 卫星图像 (Satellite Images): 检索自 Microsoft Planetary Computer 的 Sentinel-2 Level-2A 近期图像,对城市边界框内的低云层场景进行镶嵌处理,典型尺寸为 2000×2000。
-
GeoBench 基准测试集细节
- 样本量: 包含 512 张标准照片、512 张全景图和 108 张卫星图像。
- 地理覆盖: 数据横跨全球 6 大洲、66 个国家和 108 个城市(如西安、都柏林、华盛顿特区等),旨在评估模型在不同数据条件下的通用推理能力。
-
数据过滤策略 (Localizability Filtering) 为了保持合理的定位难度并测试真实的推理能力,作者实施了基于模型的过滤机制,剔除了两类图像:
- 不可定位图像: 缺乏可识别地理线索的通用物体或场景(如食物特写、室内房间、单一动物、普通自然景观)。
- 易定位地标: 包含强地理先验的标志性地标(防止模型仅依赖预训练记忆而无需推理即可作答)。
-
元数据构造与评估使用
- 多级标注: 每个样本均配备精确的经纬度元数据,以及包含国家、省/州、城市的多级行政区划标签。
- 混合验证机制: 结合基于规则的验证器与基于模型(OpenAI gpt-4o-mini)的验证器,用于检查模型在不同行政级别的回答正确性。
- 细粒度评估: 利用 Google Geocoding API 将模型预测的文本位置转换为大地坐标,通过计算预测点与真值坐标之间的 Haversine 距离 (km) 来进行自动化、细粒度的性能评估。
Method
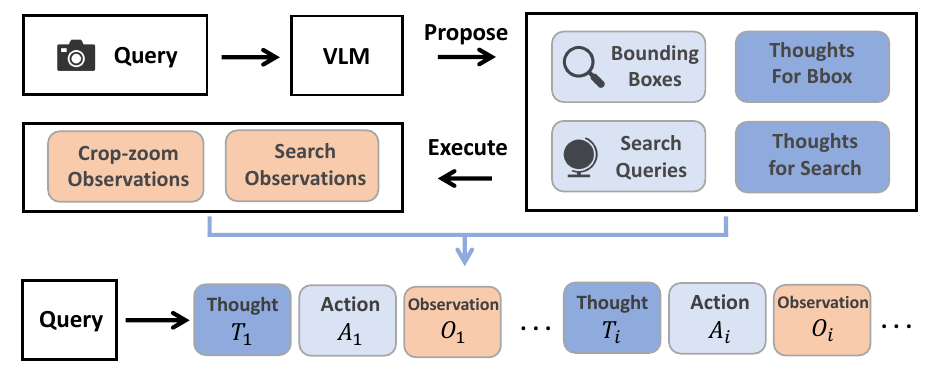
作者利用了一个基于代理的推理框架来实现地理定位任务,该框架的核心是一个策略模型,它能够根据用户查询和输入图像,迭代地生成思考(Thought)和动作(Action)。整个过程形成一个“思考-动作-观察”循环:策略模型输出的动作被解析并执行,从而与环境交互并获得新的观测结果;该观测结果被追加到交互历史中,并重新输入到策略模型中。这一循环持续进行,直到模型决定输出最终答案或达到最大交互轮次限制。见框架图

该框架中,策略模型可调用两种类型的工具:一是“裁剪-放大”工具,模型输出一个由bbox_2d参数化的边界框,用于裁剪并放大感兴趣的区域,观测结果即为放大后的子图;二是“网络搜索”工具,模型生成一个网络搜索查询,从互联网检索最多10个相关信息源,观测结果为包含网页URL的文本文档。见框架图

为了在模型训练初期提供有效的引导,作者设计了一种冷启动和思维轨迹规约的方法。作者最初尝试仅使用强化学习来训练模型(即Qwen-2.5-VL-Instruct),但发现模型倾向于生成过于简洁的响应,并且在调用工具时犹豫不决,导致性能不佳。这一观察促使作者引入显式的思维轨迹进行监督微调,以激励模型具备多轮次工具使用能力。作者借鉴了人类在地理定位时的思维过程——首先选择几个候选区域进行检查,然后参考外部知识源(如谷歌搜索)获取更多信息。受此启发,作者使用一个视觉语言模型(Seed-1.6-vision)来提出多个区域(边界框)以及中间推理过程。在感知到显著的地理线索后,该VLM被提示生成多个网络搜索查询及其伴随的推理,然后要求其生成最终判断的推理。最后,将推理步骤、边界框和网络搜索查询组装成一个包含工具调用的连贯思维轨迹。由于作者仅希望为模型提供一个推理模式先验,因此没有对推理轨迹应用基于答案的过滤。通过这种方式,作者为地理定位任务规约了2,000个冷启动推理轨迹示例。见图
在强化学习阶段,作者采用了一个简单的GRPO设置:每个问题q被传递给策略模型,该模型生成一组输出{oi}。奖励ri根据响应的正确性(例如,模型是否预测了照片拍摄的城市)来计算。在实现中,作者没有包含KL或熵正则化。形式上,优化目标为:
JGRPO(θ)G1i=1∑G;clip(πθold(oi∣q)πθ(oi∣q),,1−ϵ,,1+ϵ)Ai)]=Eq∼D,oii=1G∼πθold(⋅∣q)[min(πθold(oi∣q)πθ(oi∣q)Ai, Ai=std({r1,r2,…,rG})ri−mean({r1,r2,…,rG}).然而,由于数据具有多级标签,仅在模型预测正确城市时给予奖励的简单奖励机制无法充分利用这种分层信息。在这种简单的奖励下,模型在GeoBench上的表现不佳,并且工具调用次数较少。为了解决这个问题,作者采用了一种分层奖励来充分利用多级结构:
ri=⎩⎨⎧β2,β,1,0,if city-level correct,if provincial/state-level correct,if country-level correct,else.作者设置β>1,使得在更小行政划分上的正确答案获得更大的奖励。例如,对于一张在洛杉矶拍摄的照片,我们给“洛杉矶”这个答案的奖励高于“旧金山”,因为前者在城市级别上是正确的,尽管两者在州级别上都是正确的。为了防止β过大导致奖励差距过大,或过小导致奖励崩溃,作者在后续实验中经验性地选择了一个折中值β=2。由于强化学习成本较高,特别是由于搜索API的使用和响应组回放的计算开销,作者没有尝试其他β值。见图
Experiment
- 主要实验内容:在GeoBench基准上进行了多层级(国家、省、市)及多数据类型(全景图、照片、卫星图)的地理定位评估,对比了包括Gemini-2.5-pro、GPT-5在内的闭源模型以及Mini-o3-7B、Qwen2.5-VL等开源模型;同时通过消融实验验证了冷启动SFT、强化学习(RL)及分层奖励机制的必要性,并分析了RL数据规模扩展对性能的影响。
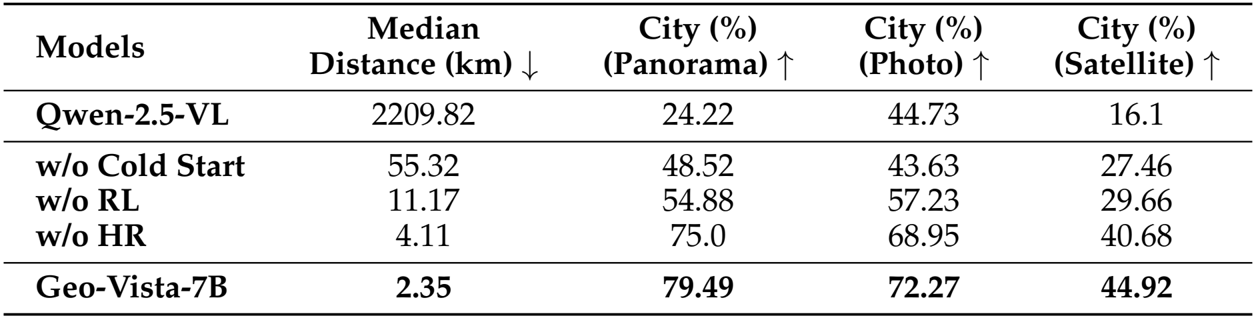
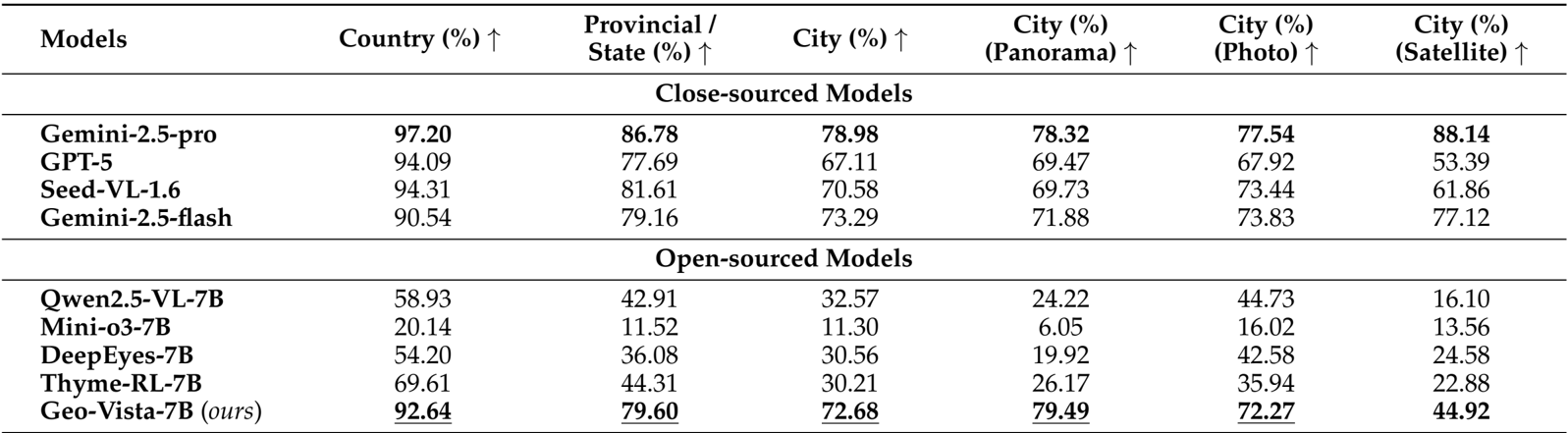
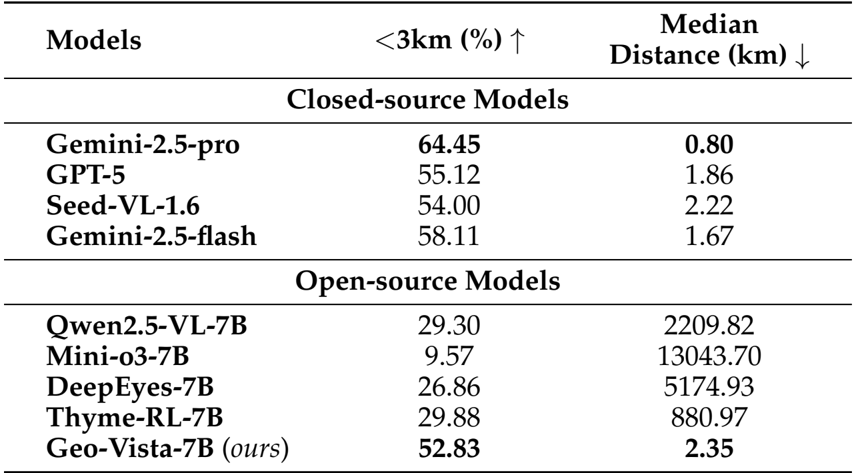
- 核心性能指标:GeoVista在GeoBench各项指标上均取得了开源模型中的SOTA性能(如国家级准确率92.64%,市级准确率72.68%),在多数指标上与闭源模型能力相当;在细粒度评估中,其预测位置与真实位置距离小于3km的比例达到52.83%,中位距离仅为2.35km,显著优于中位距离数千公里的其他同量级开源模型。
- 机制验证结果:实验证实了SFT是多轮工具使用的基础,而RL则是增强推理能力的关键,且分层奖励机制不可或缺;此外,随着RL训练数据量从1.5k增加至12k,模型性能呈现出近乎完美的对数线性增长趋势,且工具调用的错误率随训练过程自动显著下降。
作者利用GeoBench对GeoVista与其他闭源和开源模型进行了多层级的地理定位性能评估,结果显示GeoVista在国家、省/州和城市级别的准确率上均达到或接近最优水平,尤其在城市级别上显著优于其他开源模型。在细粒度的地理定位评估中,GeoVista在3公里内预测准确率和中位哈弗辛距离两个指标上也表现突出,尽管与闭源模型如Gemini-2.5-pro仍存在差距,但其性能已接近部分闭源模型,证明了其在有限参数规模下具备强大的推理能力。
作者利用GeoBench对GeoVista与多个闭源和开源模型进行了对比实验,结果显示GeoVista在国家、省级和城市级别的准确率上均达到或接近最优水平,尤其在城市级别 panoramas 和 photo 数据上的准确率显著优于其他开源模型。在细粒度定位评估中,GeoVista在3公里内预测准确率和中位数距离指标上也大幅领先于其他开源模型,表现出接近闭源模型的高精度地理定位能力。
作者利用GeoBench对模型进行了细粒度评估,结果显示GeoVista在<3km准确率和中位距离两个指标上均显著优于其他开源模型,其52.83%的<3km准确率和2.35km的中位距离表现接近闭源模型水平,尤其在中位距离上大幅优于其他开源模型。尽管GeoVista的参数规模远小于闭源模型,但其在细粒度地理定位任务上的性能表明,其通过强化学习获得的推理能力有效提升了定位精度。
作者通过消融实验验证了不同训练组件对模型性能的影响,结果显示,移除冷启动微调(SFT)会导致模型在GeoBench上的性能崩溃,表明冷启动SFT对于多轮工具调用至关重要;移除强化学习(RL)后,模型性能显著下降,说明仅靠SFT无法充分激发模型的推理能力;而移除分层奖励(HR)后,模型在城市级准确率和中位距离上均出现明显退化,进一步证明了分层奖励机制在提升模型定位精度中的关键作用。