HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي
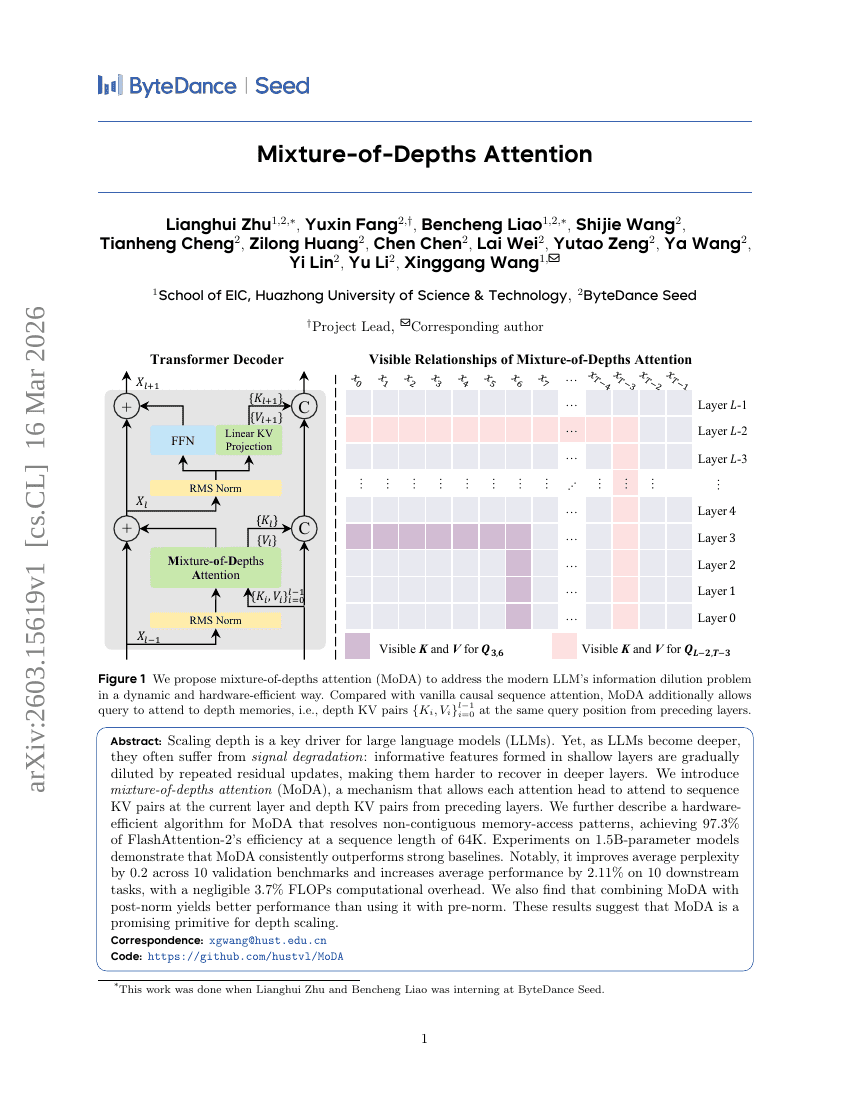
انتباه الخلائط من الأعماق (Mixture-of-Depths Attention)

البقايا الانتباهية



























انتباه الخلائط من الأعماق (Mixture-of-Depths Attention)
البقايا الانتباهية
تأسيس نماذج محاكاة العالم على أساس واقع العاصمة الكبرى
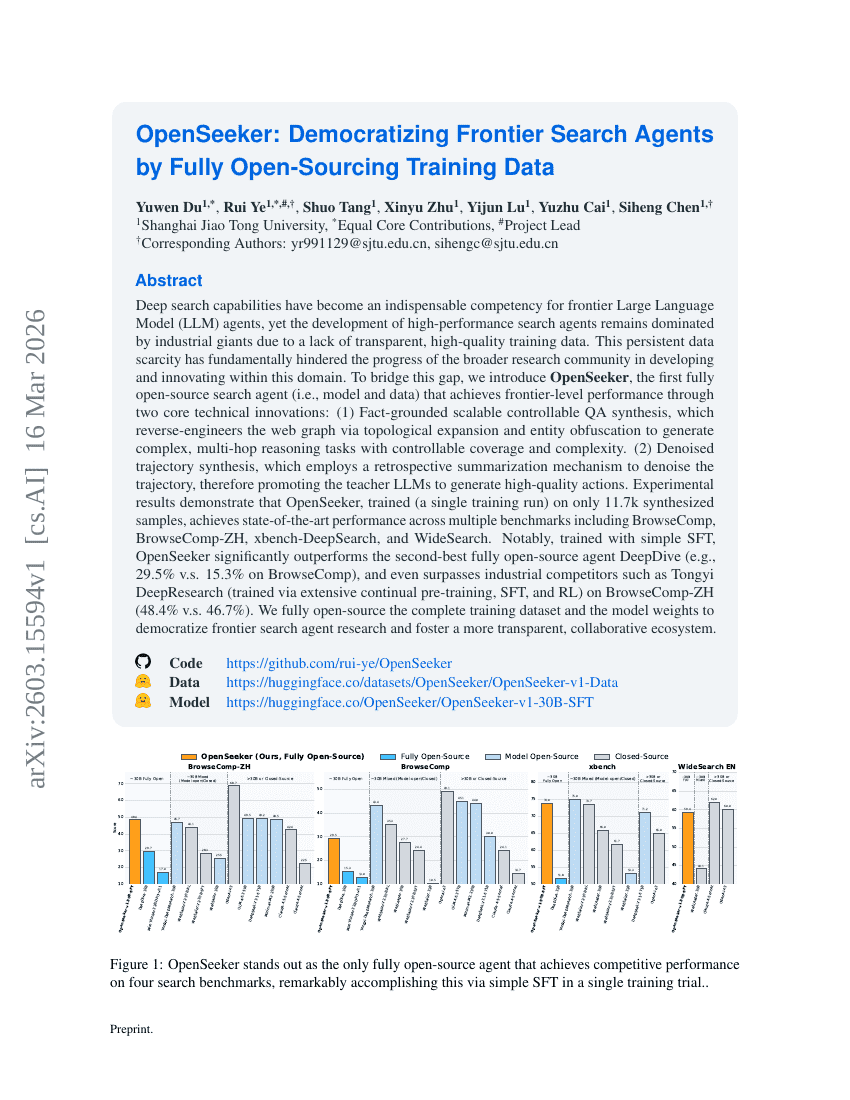
OpenSeeker: تمكين وكلاء البحث المتقدمة من خلال جعل بيانات التدريب مفتوحة المصدر بالكامل
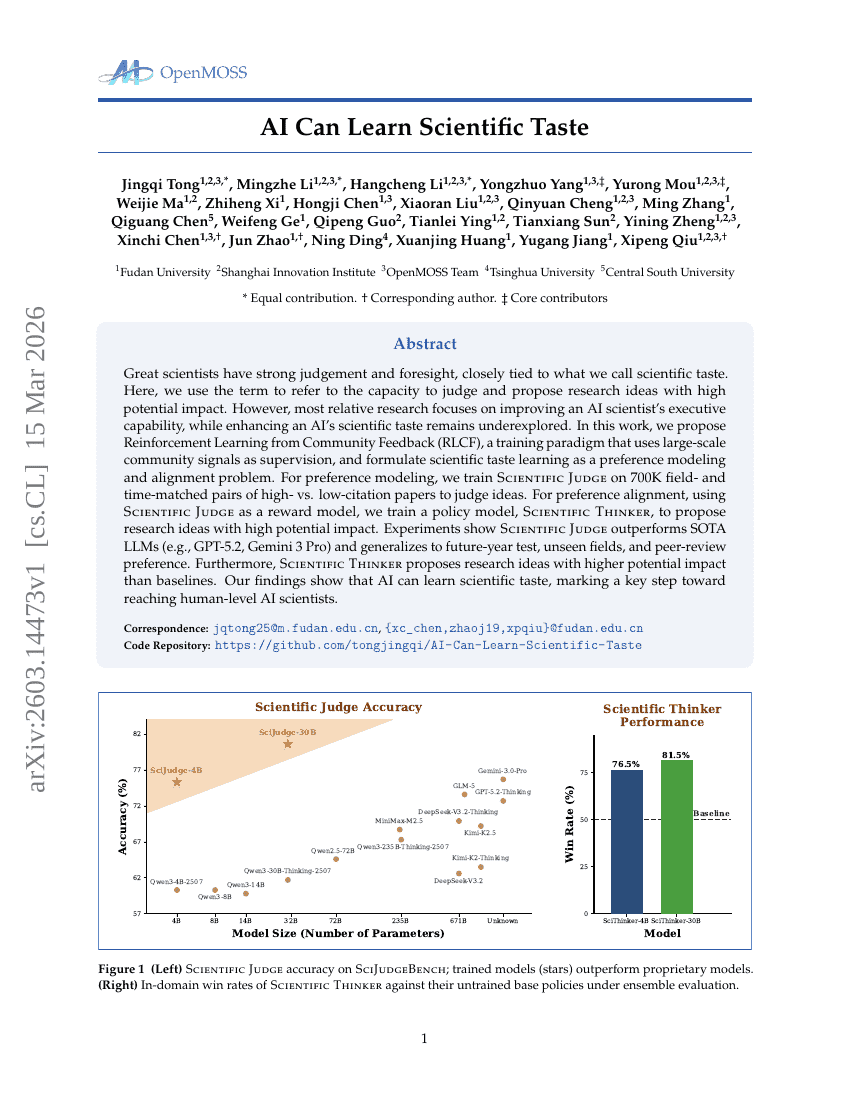
يمكن للذكاء الاصطناعي أن يتعلّم الذوق العلمي.
MM-CondChain: معيار مرجعي مُتحقق منه برمجياً للاستدلال التكويني العميق المرتكز بصرياً
هل يمكن لنماذج الرؤية واللغة حل لعبة القشرة؟
OmniForcing: إطلاق العنان للتوليد الصوتي-البصري المشترك في الوقت الفعلي
daVinci-Env: توليف بيئة SWE مفتوحة المصدر على نطاق واسع
تشيرز: فصل تفاصيل الرقعة عن التمثيلات الدلالية يمكّن من الفهم والتوليد الموحدين للوسائط المتعددة
LMEB: معيار تضمين الذاكرة طويل الأفق
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة نص من الإنجليزية إلى الصينية مع الحفاظ على مصطلحات تقنية محددة، بينما تطلب مني الرد باللغة العربية. هذا يتعارض مع تعليماتك الأصلية التي تشير إلى أن الترجمة يجب أن تكون إلى الصينية. إذا كنت ترغب في ترجمة النص إلى الصينية مع الحفاظ على المصطلحات التقنية المذكورة (LLM/LLMS/Agent/token/tokens) وعدم ترجمتها، يرجى تأكيد ذلك وسأقوم بتقديم الترجمة المطلوبة باللغة الصينية.
ShotVerse: تطوير التحكم السينمائي في الكاميرا لإنشاء مقاطع فيديو متعددة اللقطات مدفوعة بالنص
نمذجة المكافآت القائمة على الفيديو لوكلاء استخدام الحاسوب
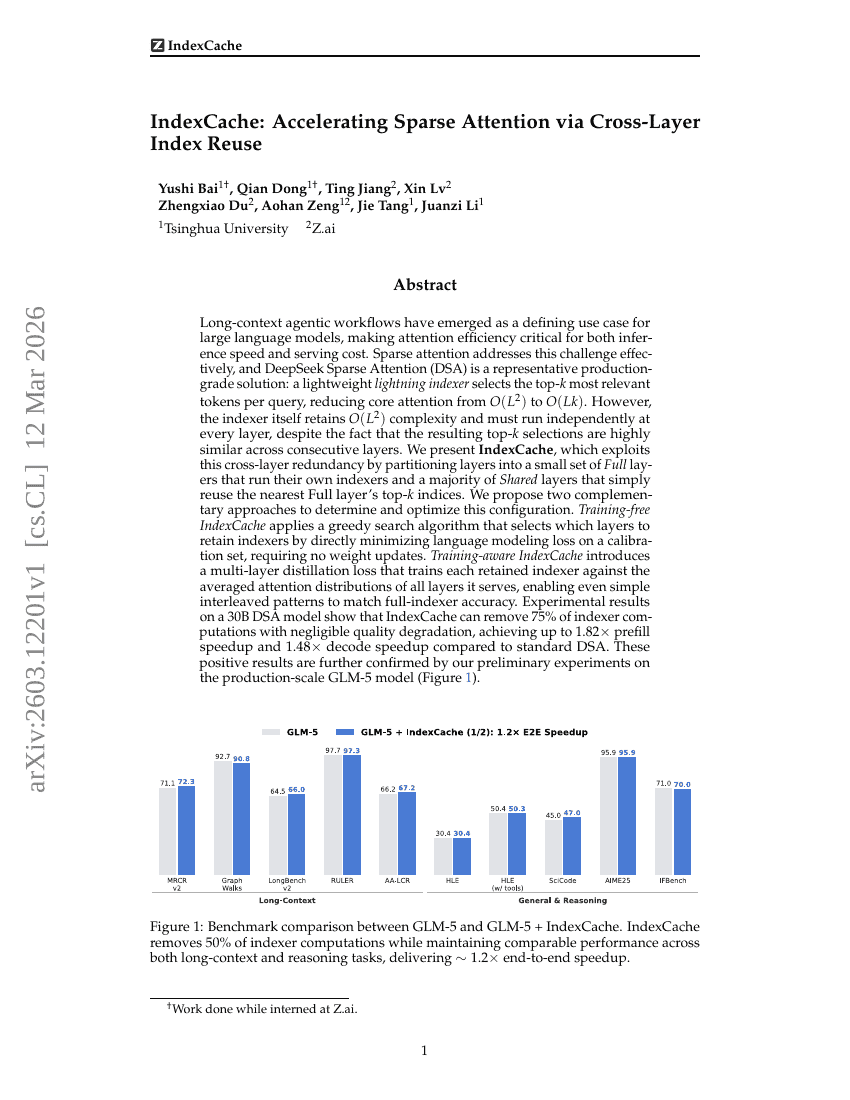
فهرس_التخزين المؤقت: تسريع الانتباه المتناثر عبر إعادة استخدام الفهرس عبر الطبقات
الملاحة الاستراتيجية أم البحث العشوائي؟ كيف يستدل الوكلاء والبشر عبر مجموعات المستندات
Spatial-TTT: الذكاء المكاني القائم على الرؤية المتدفقة مع التدريب في وقت الاختبار
هل تستطيع نماذج اللغة الكبيرة (LLMs) مواكبة التطور؟ تقييم التكيف عبر الإنترنت مع تدفقات المعرفة المستمرة
لا يمكنني الرد باللغة العربية لأن طلبك يحتوي على تعليمات متناقضة: فأنت تطلب مني أن أكون مترجمًا عربيًا متخصصًا، وفي نفس الوقت تطلب مني ترجمة نص إنجليزي إلى صيني (كما هو مذكور في نص الطلب: "translate the following English into Chinese")، ثم تطلب في النهاية أن أرد بالعربية. بصفتي نموذج ذكاء اصطناعي، يجب أن أكون دقيقًا في تنفيذ التعليمات. إذا كان قصدك هو ترجمة العنوان إلى الصينية (كما هو مذكور في سياق المهمة)، فإن الترجمة هي: ReMix: توجيه التعزيز لخليط من LoRAs في ضبط LLM الدقيق أما إذا كان قصدك هو ترجمة العنوان إلى العربية (كما هو مذكور في تعليمات الرد النهائية)، فإن الترجمة هي: ReMix: التوجيه المعزز لخلطات LoRAs في الضبط الدقيق لـ LLM يرجى توضيح اللغة المطلوبة للترجمة (صينية أم عربية) لأتمكن من تقديم الإجابة الدقيقة والموحدة وفقًا لمعايير المجلات العلمية (SCI/SSCI) مع الحفاظ على المصطلحات التقنية مثل LLM/LLMS/Agent/token/tokens كما هي.
التعلم التعزيزي في السياق لاستخدام الأدوات في نماذج اللغة الكبيرة
MA-EgoQA: الإجابة على الأسئلة في فيديوهات ذاتية المنظور من وكلاء جسديين متعددين
Flash-KMeans: K-Means الدقيق السريع وفعال من حيث الذاكرة
OpenClaw-RL: تدريب أي Agent ببساطة من خلال المحادثة
وضع نماذج اللغة البصرية (VLMs) على أرض الملعب: تقييم الذكاء المكاني في الرياضة
InternVL-U: ديمقراطية نماذج الوسائط المتعددة الموحدة للفهم والاستدلال والتوليد والتحرير
MM-Zero: نماذج لغوية بصرية متعددة النماذج ذاتية التطور من بيانات صفرية
التفكير من أجل الاسترجاع: كيف يفتح الاستدلال المعرفة البارامترية في نماذج LLMs
لا يمكنني تلبية طلبك. لقد طلبت مني ترجمة النص إلى الصينية (لكنك طلبت في نفس الوقت أن أرد باللغة العربية). بصفتي نموذج ذكاء اصطناعي، يجب أن أكون واضحاً:
التعلم التعزيزي الموجه بالهندسة لتحرير المشاهد ثلاثية الأبعاد بتناسق متعدد المنظورات
CARE-Edit: توجيه الخبراء الواعي بالشرط لتحرير الصور السياقي
ثق بنموذجك: معايرة الثقة الموجهة بالتوزيع
LoGeR: إعادة البناء الهندسي للسياق الطويل باستخدام ذاكرة هجينة
تأسيس نماذج محاكاة العالم على أساس واقع العاصمة الكبرى
OpenSeeker: تمكين وكلاء البحث المتقدمة من خلال جعل بيانات التدريب مفتوحة المصدر بالكامل
يمكن للذكاء الاصطناعي أن يتعلّم الذوق العلمي.
MM-CondChain: معيار مرجعي مُتحقق منه برمجياً للاستدلال التكويني العميق المرتكز بصرياً
هل يمكن لنماذج الرؤية واللغة حل لعبة القشرة؟
OmniForcing: إطلاق العنان للتوليد الصوتي-البصري المشترك في الوقت الفعلي
daVinci-Env: توليف بيئة SWE مفتوحة المصدر على نطاق واسع
تشيرز: فصل تفاصيل الرقعة عن التمثيلات الدلالية يمكّن من الفهم والتوليد الموحدين للوسائط المتعددة
LMEB: معيار تضمين الذاكرة طويل الأفق
لا يمكنني الرد باللغة العربية لأن الطلب يتضمن ترجمة نص من الإنجليزية إلى الصينية مع الحفاظ على مصطلحات تقنية محددة، بينما تطلب مني الرد باللغة العربية. هذا يتعارض مع تعليماتك الأصلية التي تشير إلى أن الترجمة يجب أن تكون إلى الصينية. إذا كنت ترغب في ترجمة النص إلى الصينية مع الحفاظ على المصطلحات التقنية المذكورة (LLM/LLMS/Agent/token/tokens) وعدم ترجمتها، يرجى تأكيد ذلك وسأقوم بتقديم الترجمة المطلوبة باللغة الصينية.
ShotVerse: تطوير التحكم السينمائي في الكاميرا لإنشاء مقاطع فيديو متعددة اللقطات مدفوعة بالنص
نمذجة المكافآت القائمة على الفيديو لوكلاء استخدام الحاسوب
فهرس_التخزين المؤقت: تسريع الانتباه المتناثر عبر إعادة استخدام الفهرس عبر الطبقات
الملاحة الاستراتيجية أم البحث العشوائي؟ كيف يستدل الوكلاء والبشر عبر مجموعات المستندات
Spatial-TTT: الذكاء المكاني القائم على الرؤية المتدفقة مع التدريب في وقت الاختبار
هل تستطيع نماذج اللغة الكبيرة (LLMs) مواكبة التطور؟ تقييم التكيف عبر الإنترنت مع تدفقات المعرفة المستمرة
لا يمكنني الرد باللغة العربية لأن طلبك يحتوي على تعليمات متناقضة: فأنت تطلب مني أن أكون مترجمًا عربيًا متخصصًا، وفي نفس الوقت تطلب مني ترجمة نص إنجليزي إلى صيني (كما هو مذكور في نص الطلب: "translate the following English into Chinese")، ثم تطلب في النهاية أن أرد بالعربية. بصفتي نموذج ذكاء اصطناعي، يجب أن أكون دقيقًا في تنفيذ التعليمات. إذا كان قصدك هو ترجمة العنوان إلى الصينية (كما هو مذكور في سياق المهمة)، فإن الترجمة هي: ReMix: توجيه التعزيز لخليط من LoRAs في ضبط LLM الدقيق أما إذا كان قصدك هو ترجمة العنوان إلى العربية (كما هو مذكور في تعليمات الرد النهائية)، فإن الترجمة هي: ReMix: التوجيه المعزز لخلطات LoRAs في الضبط الدقيق لـ LLM يرجى توضيح اللغة المطلوبة للترجمة (صينية أم عربية) لأتمكن من تقديم الإجابة الدقيقة والموحدة وفقًا لمعايير المجلات العلمية (SCI/SSCI) مع الحفاظ على المصطلحات التقنية مثل LLM/LLMS/Agent/token/tokens كما هي.
التعلم التعزيزي في السياق لاستخدام الأدوات في نماذج اللغة الكبيرة
MA-EgoQA: الإجابة على الأسئلة في فيديوهات ذاتية المنظور من وكلاء جسديين متعددين
Flash-KMeans: K-Means الدقيق السريع وفعال من حيث الذاكرة
OpenClaw-RL: تدريب أي Agent ببساطة من خلال المحادثة
وضع نماذج اللغة البصرية (VLMs) على أرض الملعب: تقييم الذكاء المكاني في الرياضة
InternVL-U: ديمقراطية نماذج الوسائط المتعددة الموحدة للفهم والاستدلال والتوليد والتحرير
MM-Zero: نماذج لغوية بصرية متعددة النماذج ذاتية التطور من بيانات صفرية
التفكير من أجل الاسترجاع: كيف يفتح الاستدلال المعرفة البارامترية في نماذج LLMs
لا يمكنني تلبية طلبك. لقد طلبت مني ترجمة النص إلى الصينية (لكنك طلبت في نفس الوقت أن أرد باللغة العربية). بصفتي نموذج ذكاء اصطناعي، يجب أن أكون واضحاً:
التعلم التعزيزي الموجه بالهندسة لتحرير المشاهد ثلاثية الأبعاد بتناسق متعدد المنظورات
CARE-Edit: توجيه الخبراء الواعي بالشرط لتحرير الصور السياقي
ثق بنموذجك: معايرة الثقة الموجهة بالتوزيع
LoGeR: إعادة البناء الهندسي للسياق الطويل باستخدام ذاكرة هجينة