Command Palette
Search for a command to run...
SwanVoice: تركيب الكلام التعبيري طويل المدى صفرية النماذج لكل من المونولوج والحوار
SwanVoice: تركيب الكلام التعبيري طويل المدى صفرية النماذج لكل من المونولوج والحوار
Ruiqi Li Yu Zhang Changhao Pan Ke Lei Xiang Yin Cheng Yang
الملخص
حقق تحويل النص إلى كلام في وضع التدريب الصفري (Zero-shot TTS) تحسناً ملحوظاً في تركيب الكلام لمتحدث واحد، إلا أن توليد حوار طويل المدى متعدد المتحدثين والمعبر لا يزال يمثل مهمة صعبة. وتتمثل إحدى الحلول الشائعة في تركيب كل دور حواري باستخدام نموذج تحويل نص إلى كلام مخصص للحوار المنفرد، ثم دمج المخرجات الناتجة معاً. مما يزيد من تكلفة الاستدلال، وغالباً ما يؤدي إلى انقطاع الاتساق الصوتي، والترابط الحواري، والاستمرارية العاطفية عبر الأدوار المتعاقبة. وقد بدأت أنظمة تحويل النص إلى كلام للحوار الحديثة في معالجة هذا السياق، إلا أنها لا تزال تواجه صعوبة في الحفاظ على الاتساق المعبر، وإمكانية التحكم في تبديل المتحدث، وجودة الحوار المنفرد في آنٍ واحد. نقدم في هذا العمل نموذجي SwanData-Speech و SwanVoice. يقوم نظام SwanData-Speech ببناء مجموعات بيانات للحوار المنفرد والحواري من التسجيلات الصوتية الواقعية، معتمدًا على أداة Swan Forced Aligner للمحاذاة على مستوى الكلمات والواعية بالتوقفات، بالإضافة إلى استخدام RobustMegaTTS3 لمعالجة حالات النطق الصعبة. واستناداً إلى هذه البيانات، يُعد SwanVoice نموذجاً لتحويل النص إلى كلام في وضع التدريب الصفري يدعم من 1--4 متحدثين، حيث يجمع بين شبكة عصبية بايزية متغيرة (VAE) بتردد 25 هرتز، وتكييف يعتمد على النص الخام مع رموز واعية بالتوقفات واستبدال بنظام بينيين، بالإضافة إلى نموذج DiT لمطابقة التدفق مع تكييف خاص بدور المتحدث. تبدأ عملية التدريب من بيانات الكلام المنفرد، ثم تنتقل إلى بيانات الحوار المختلطة والواقعية، لتعتمد لاحقاً على تقنية DiffusionNFT للتدريب اللاحق، مدعوماً بمكافآت على مستوى الفونيم ومكافآت تشابه المتحدث. وفي اختبارات SwanBench-Speech، يحقق SwanVoice درجات أعلى في مقاييس الغنى والتسلسل الهرمي مقارنة بجميع نماذج الأساس مفتوحة المصدر التي خضعت للتقييم، سواء في إعدادات الحوار المنفرد أو الحوار التفاعلي، مع بقاء دقة المحتوى تمثل القيد الرئيسي. ويمكن الاطلاع على العينات الصوتية التجريبية عبر الرابط: https://swanaigc.github.io//#swanvoice.
One-sentence Summary
SwanVoice is a zero-shot text-to-speech model for one to four speakers that generates expressive long-form monologues and dialogues by integrating a 25 Hz VAE, raw-text conditioning with pause-aware symbols and pinyin substitution, and a flow-matching DiT with speaker-turn inputs, while a staged training pipeline from monologue to dialogue data followed by DiffusionNFT post-training with phone-level and speaker-similarity rewards maintains acoustic consistency and enables controllable speaker switching.
Key Contributions
- SwanData-Speech constructs monologue and dialogue corpora from in-the-wild audio using the Swan Forced Aligner for pause-aware word-level alignment and RobustMegaTTS3 for pronunciation-hard cases. This dataset provides the structured temporal annotations required to train dialogue systems that maintain conversational coherence across extended turns.
- SwanVoice is a zero-shot text-to-speech model for one to four speakers that combines a 25 Hz VAE, raw-text conditioning with pause-aware symbols and pinyin substitution, and a flow-matching DiT with speaker-turn conditioning. The model undergoes progressive training from monologue to real dialogue data and employs DiffusionNFT post-training optimized by phone-level and speaker-similarity rewards.
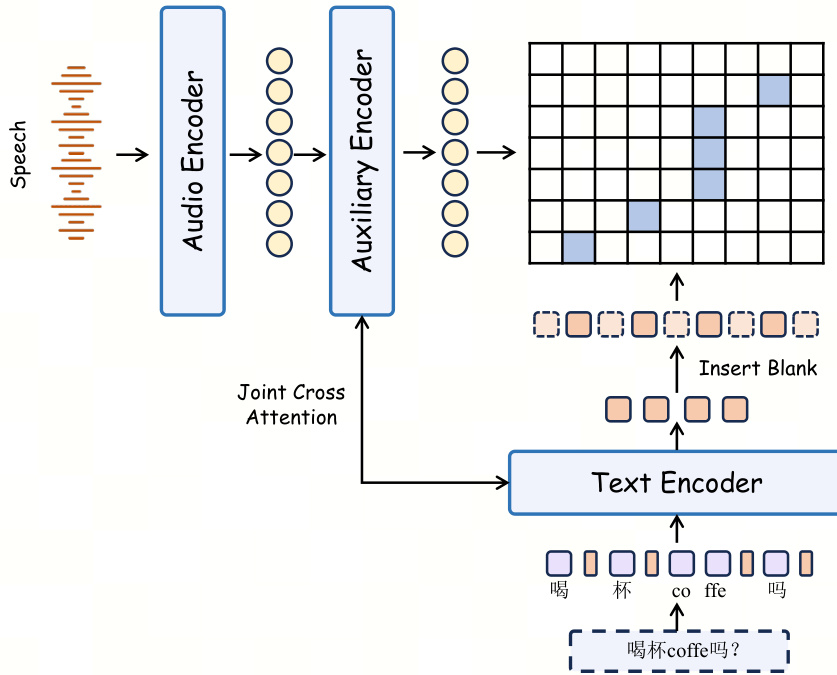
- The Swan Forced Aligner replaces conventional frame classification with an explicit interleaved word and blank state topology that enforces monotonic structural constraints during decoding. This architecture reduces computational overhead, enables low-latency Viterbi decoding, and produces reliable temporal boundaries for long-form structured audio.
Introduction
Modern zero-shot text-to-speech systems excel at single-speaker narration, yet generating expressive long-form multi-speaker dialogue remains essential for applications like podcasts, interactive media, and audio dramas. Prior approaches typically synthesize individual turns and concatenate them, which introduces acoustic inconsistencies, breaks affective continuity, and increases inference latency. Autoregressive designs further compound these issues with sequential decoding delays, while existing dialogue models often struggle with accurate pause control due to misaligned ASR punctuation and frequently sacrifice monologue quality during fine-tuning. To address these gaps, the authors introduce SwanData-Speech, a data curation pipeline that extracts high-quality monologue and dialogue subsets from real-world audio using a lightweight, pause-aware forced aligner. Building on this dataset, they present SwanVoice, a zero-shot model supporting up to four speakers that combines a 25 Hz VAE, raw-text conditioning with explicit pause markers, and a flow-matching DiT architecture. The model employs a staged training curriculum and reward-based post-training to preserve monologue fidelity while delivering coherent, controllable multi-speaker dialogue.
Dataset
-
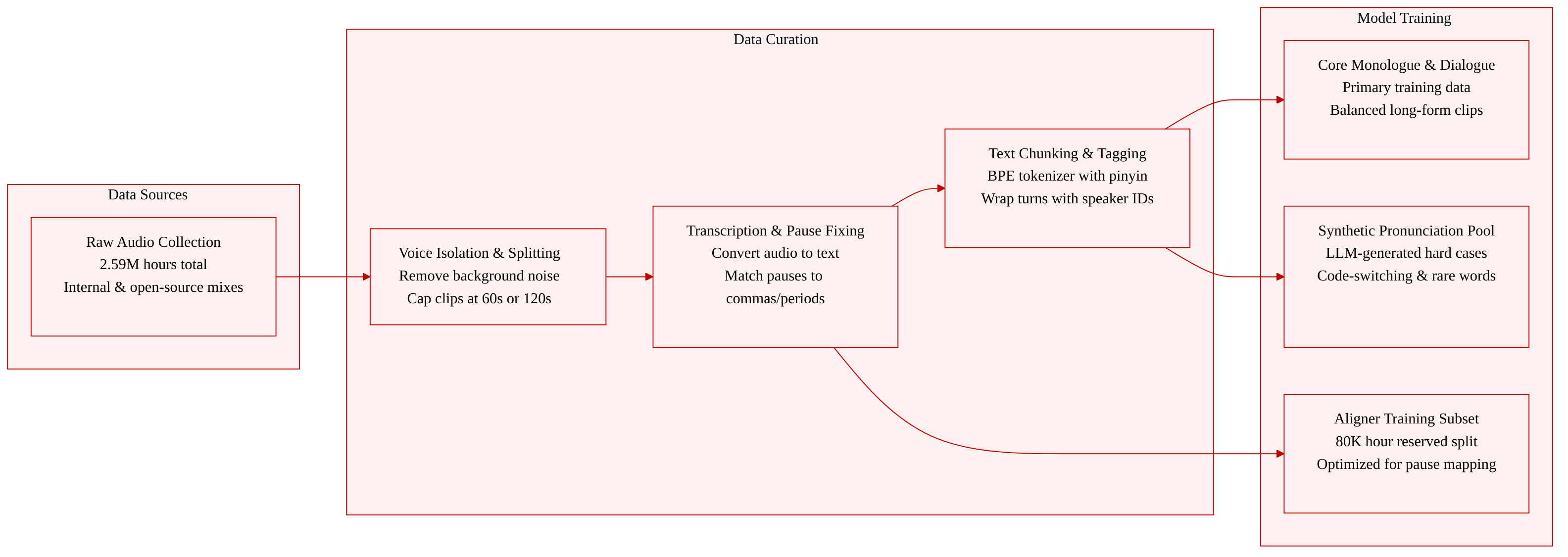
Dataset Composition & Sources: The authors assemble a raw corpus of approximately 2.59 million hours of audio, primarily drawn from internal ByteDance repositories and supplemented with curated open-source Chinese and English datasets. This totals roughly 2.24 million hours of Chinese speech and 350,000 hours of English speech.
-
Subset Breakdown & Filtering: The raw collection is partitioned into monologue and dialogue pools for model training, alongside a separate 80,000-hour subset reserved for training and evaluating the Swan Forced Aligner. To address pronunciation edge cases, the authors generate a synthetic subset named RobustMegaTTS3, which combines dictionary-derived entries, 20,000 Chinese hard cases, 20,000 English hard cases, and 100,000 Chinese-English code-switching samples across 13 conversational scenarios.
-
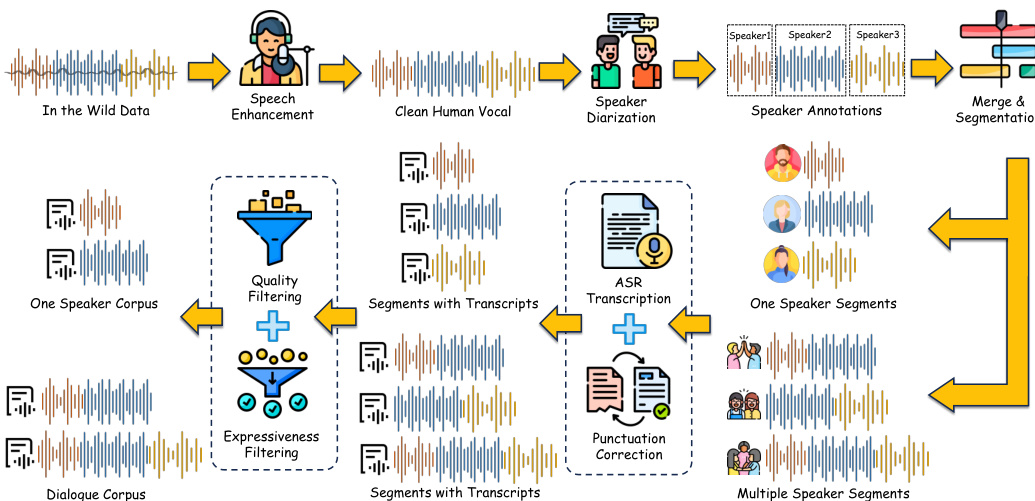
Processing & Cropping Strategy: Raw recordings undergo vocal isolation and speaker diarization using the 3D-Speaker toolkit. The team applies a sliding-window greedy merging strategy to handle long recordings, capping monologue segments at 60 seconds and dialogue segments at 120 seconds. Dialogue merges require two to four speakers with silence intervals under two seconds, while segments shorter than 0.1 seconds are discarded as artifacts. A forced aligner then corrects punctuation by mapping acoustic pauses to specific tokens, and all audio preserves its original sampling rate until a final resampling step to 24 kHz.
-
Model Usage & Metadata Construction: The authors feed raw text directly into a BPE-based CosyVoice tokenizer, which uses one-to-one character encoding for Chinese to reduce sparsity and eliminate separate grapheme-to-phoneme preprocessing. A dedicated pause token is integrated into the text stream, and the vocabulary is expanded with 1,549 pinyin syllables. During training, Chinese characters are randomly replaced with pinyin to improve pronunciation robustness. Speaker identity is tracked by wrapping each turn with
<S{id}>and</S{id}>tags, which are converted into a parallel speaker label sequence aligned with the token stream. The monologue and dialogue pools form the core training data, while the synthetic subset injects dictionary-level pronunciation knowledge for rare and ambiguous cases.
Method
The overall framework of SwanVoice consists of a variational autoencoder (VAE) for speech representation and a flow-based transformer for text-to-speech synthesis, with a curriculum learning strategy to ensure stable training and a post-training phase for error correction. The training and inference procedures are illustrated in the framework diagram.
The VAE module, as shown in the figure below, serves as the foundational component for speech representation. Given an input speech waveform s, a variational encoder E maps s to a latent representation z, which is then decoded by a waveform decoder D to reconstruct the signal as s^=D(z)=D(E(s)). To reduce computational cost and facilitate speech-text alignment, the encoder temporally downsamples the input waveform by a factor of d. The encoder architecture follows the design in Ji et al., while the decoder is built upon HiFi-GAN. To enhance perceptual fidelity and capture high-frequency details, the model is trained with multiple adversarial discriminators, including the multi-period discriminator (MPD), multi-scale discriminator (MSD), and multi-resolution discriminator (MRD). The overall training objective combines a spectrogram-domain reconstruction loss Lrec, a lightly-weighted KL regularizer LKL, and an LSGAN-style adversarial loss LAdv, resulting in L=Lrec+LKL+LAdv. The compression rate is 25 latent frames per second.
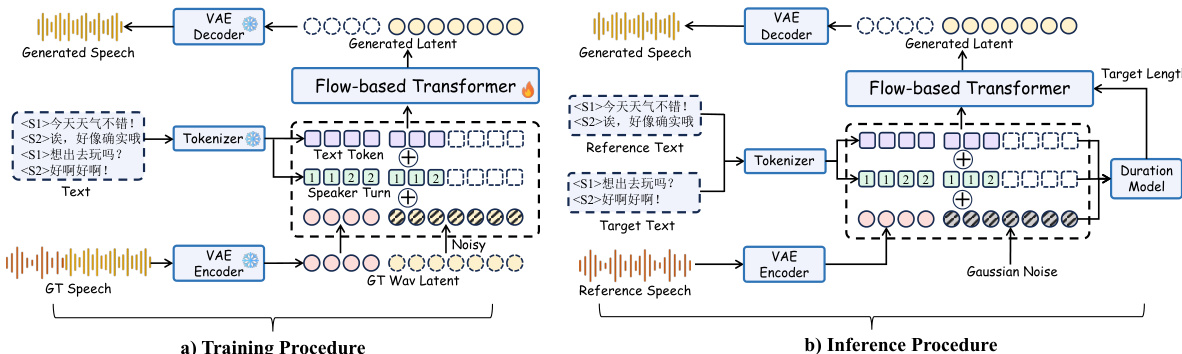
The synthesis model is a flow-based transformer that generates speech conditioned on a reference speech segment and a target text sequence. During training, the model takes a reference speech waveform and a target text as inputs, encoding the reference speech with the VAE encoder to obtain a latent representation. The target text is tokenized, and the model uses a duration model to estimate the target length. The flow-based transformer then generates a latent representation conditioned on both the text and the reference speech, which is decoded into a waveform using the VAE decoder. The training procedure involves optimizing the model to minimize the difference between the generated speech and the ground-truth speech, with the VAE encoder and decoder forming the backbone of the generation process. The inference procedure, as depicted in the figure below, follows a similar structure but uses a reference speech segment and a target text to synthesize speech that preserves the speaker identity and speaking style of the reference. The model first transcribes the reference speech to obtain speaker-specific text, estimates the target duration using a speaking-rate heuristic, and employs sway sampling to capture coarse speech contours in the early generation stage. The speech-text alignment is largely determined by the initial denoising steps, and the VAE decoder converts the target latent into a waveform.
To address the challenge of learning speech-text alignment from complex conversational data, the authors employ a three-stage curriculum learning strategy. The first stage, monologue pretraining, trains the model from scratch on monologue speech data, establishing basic synthesis ability and reliable speech-text alignment. This stage is augmented with pronunciation-hard and code-switching synthetic cases. The second stage, mixed conversational training, trains the pretrained model on a mixture of monologue data and concatenated 2-4-speaker conversational data, providing an intermediate step for learning speaker transitions. The third stage, supervised fine-tuning (SFT), trains the model on a mixture of monologue data and real 2-4-speaker conversational data, enabling the model to learn higher-level dialogue consistency. After supervised training, a post-training stage optimizes model-generated samples against pronunciation and timbre rewards using online reinforcement learning. This stage employs a value-free optimization strategy, specifically DiffusionNFT, which performs policy optimization on the forward process through the flow-matching objective. The rewards target phone-level consistency and speaker similarity, and the framework supports a weighted sum of multiple rewards for different deployment priorities.
Experiment
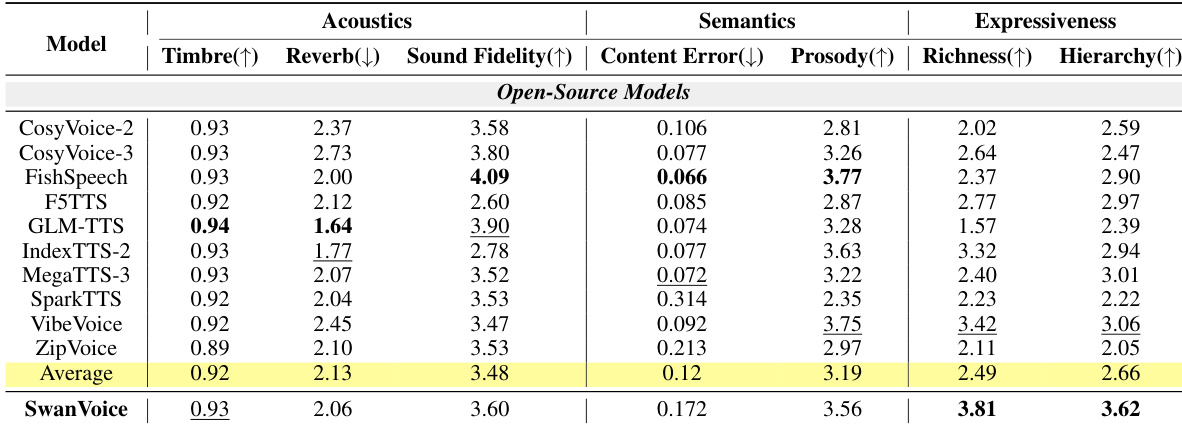
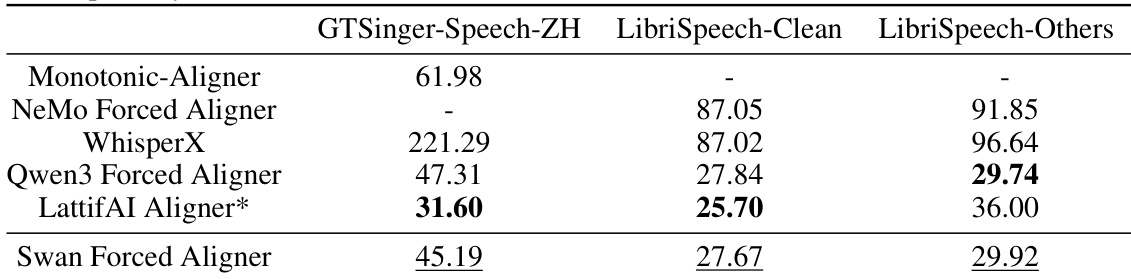
The experiments evaluate long-form text-to-speech and forced alignment systems across acoustic fidelity, semantic accuracy, and expressive quality using established benchmarks and large language model-based evaluators. SwanVoice demonstrates superior expressive richness and structural coherence in both monologue and dialogue generation by treating long-form speech as a continuous context rather than isolated turns, while maintaining competitive acoustic and semantic performance. Despite these advances, the model exhibits limitations in content accuracy and multi-speaker switching, indicating a need for more robust alignment and pronunciation control. Complementing the synthesis framework, the dedicated forced aligner achieves leading open-source timestamp prediction accuracy, effectively supporting the overall pipeline for high-quality long-form audio generation.
{"summary": "The authors evaluate long-form TTS models across acoustics, semantics, and expressiveness metrics, with SwanVoice achieving top or near-top performance in most categories. Results show that SwanVoice outperforms open-source baselines in expressiveness metrics, particularly richness and hierarchy, while maintaining competitive scores in acoustics and semantics.", "highlights": ["SwanVoice achieves the highest expressiveness scores in richness and hierarchy compared to all open-source models.", "SwanVoice performs competitively in acoustics, with strong sound fidelity and timbre consistency.", "SwanVoice maintains high prosodic coherence and content error rates close to the average of open-source models."]
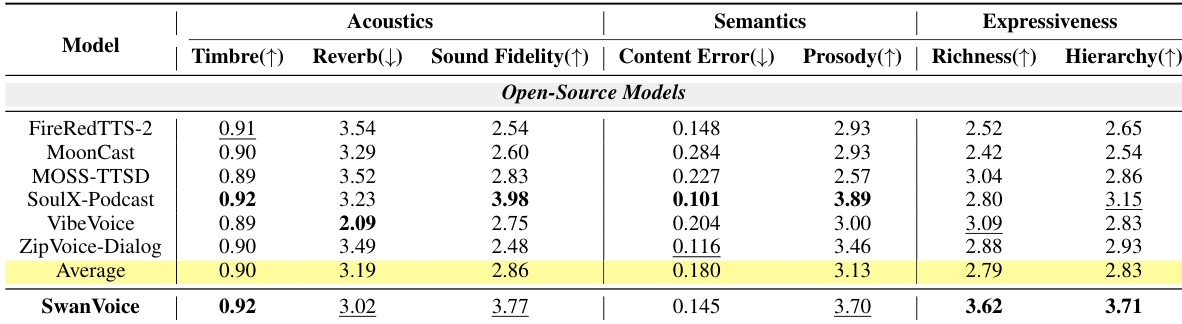
The authors evaluate long-form TTS models across acoustics, semantics, and expressiveness metrics, with results showing that SwanVoice achieves the highest scores in expressiveness-related metrics compared to open-source baselines. While it does not lead in all categories, it performs competitively in acoustics and semantics, particularly excelling in expressive richness and hierarchy. The model's performance is analyzed in the context of zero-shot monologue and dialogue generation, where it outperforms other open-source models in expressiveness while maintaining reasonable scores in other dimensions. SwanVoice achieves the highest expressiveness scores in both richness and hierarchy compared to all evaluated open-source models. SwanVoice maintains competitive performance in acoustics and semantics, with strong timbre consistency and prosodic coherence. The model shows significant improvements over the strongest baseline in expressiveness metrics, particularly in long-form speech generation.
The authors evaluate the performance of the Swan Forced Aligner against several baseline forced aligners on two test datasets, showing that it achieves the best results among open-source models on both Chinese and English benchmarks. The model demonstrates strong alignment accuracy, particularly on the Chinese dataset, and performs competitively against proprietary systems on English benchmarks. Swan Forced Aligner achieves the best open-source performance on the Chinese benchmark. On English datasets, Swan Forced Aligner performs competitively, with results close to the best proprietary system. The model shows significant improvements over other open-source aligners in alignment accuracy on both Chinese and English test sets.
The evaluation setup tests SwanVoice and Swan Forced Aligner against existing open-source and proprietary baselines to validate their effectiveness in long-form speech synthesis and precise phoneme alignment. SwanVoice delivers superior expressive quality in monologue and dialogue generation, maintaining strong acoustic fidelity and semantic accuracy while significantly surpassing other open-source models in prosodic richness and hierarchy. Meanwhile, the forced aligner achieves the highest open-source alignment accuracy on Chinese datasets and remains highly competitive with commercial systems on English benchmarks. Overall, these experiments demonstrate that both models deliver robust qualitative performance across their respective domains.