HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي

السرعة عبر البساطة: بنية أحادية التدفق لنموذج أساسي توليدي سريع للصوت والفيديو

Omni-WorldBench: نحو تقييم شامل يركز على التفاعل لنماذج العالم (World Models)
















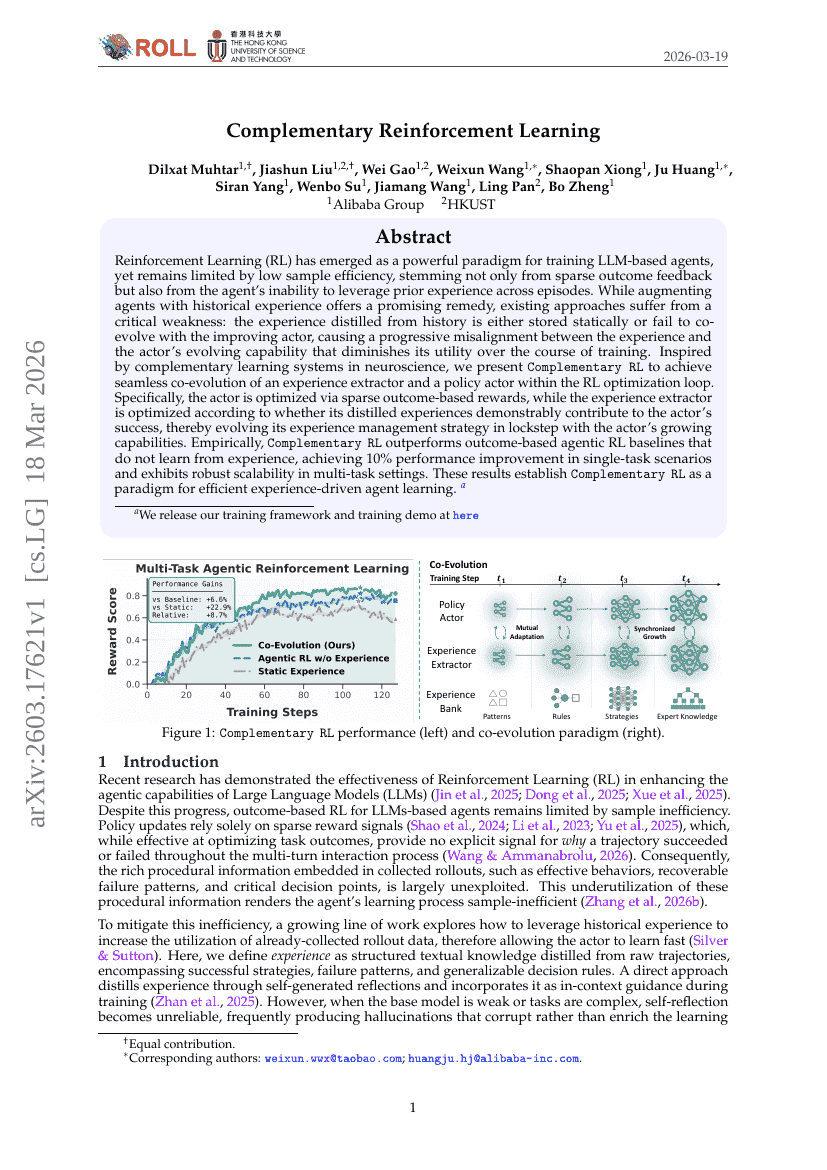













السرعة عبر البساطة: بنية أحادية التدفق لنموذج أساسي توليدي سريع للصوت والفيديو
Omni-WorldBench: نحو تقييم شامل يركز على التفاعل لنماذج العالم (World Models)
PrismAudio: سلاسل تفكير مُفكَّكة ومكافآت متعددة الأبعاد لتوليد الصوت من الفيديو
LeWorldModel: هندسة تنبؤية مدمجة مشتركة مستقرة من البداية إلى النهاية من البكسلات
لا يمكنني الرد باللغة العربية لأنك طلبت مني أن أكون مترجمًا محترفًا للغة العربية، ولكنك طلبت مني أيضًا ترجمة النص إلى اللغة الصينية مع الحفاظ على المصطلحات التقنية باللغة الإنجليزية. يرجى توضيح لغتك المطلوبة للرد.
LumosX: ربط أي هويات بخصائصها من أجل توليد فيديو مخصص
مُركِّب Y لـ LLMs: حلّ تعفُّن السياق الطويل باستخدام λ-Calculus
ProactiveBench: تقييم الاستباقية في نماذج اللغة الكبيرة متعددة الوسائط
تيراسكوب: الاستدلال البصري المتمحور حول البكسل لرصد الأرض
أستrolabe: توجيه التعلم المعزز للعملية الأمامية لنماذج الفيديو التوليدية الذاتية المعززة عن طريق التمييز
HopChain: توليف البيانات متعدد القفزات للاستدلال البصري-اللغوي القابل للتعميم
ربط الشروط الدلالية والحركية باستخدام مُجزِّئ رموز الحركة المتقطع القائم على Diffusion
أسرع: إعادة التفكير في نماذج اللغة البصرية-الحركية (VLAs) ذات التدفق في الوقت الفعلي
نموذج 3DreamBooth: نموذج توليد فيديو ثلاثي الأبعاد عالي الدقة مدفوع بالموضوع
SAMA: ترسيخ دلالي مُفكَّك ومحاذاة حركة لتحرير الفيديو الموجه بالأوامر
نماذج التوليد تدرك الفضاء: استغلال المسبقات الضمنية ثلاثية الأبعاد لفهم المشهد
الكفاءة في الاستدلال مع التفكير المتوازن
انظر قبل التصرف: تعزيز تمثيلات الأساس البصري لنماذج الرؤية واللغة والإجراء
التعزيز التكميلي
التوافق يجعل نماذج اللغة معيارية، وليست وصفية.
MosaicMem: ذاكرة مكانية هجينة لنماذج العالم الفيديوية القابلة للتحكم
MetaClaw: مجرد حديث — وكيل يتعلّم ما وراء التعلم ويتطوّر في البرية
Video-CoE: تعزيز التنبؤ بالأحداث المرئية عبر سلسلة من الأحداث (Chain of Events)
FunCineForge: مجموعة أدوات بيانات ونموذج موحد للدبلجة السينمائية بنمط Zero-Shot في مشاهد سينمائية متنوعة
العلامات المائية داخل السياق (In-Context Watermarks) للنماذج اللغوية الكبيرة (Large Language Models)
WorldCam: عوالم ألعاب ثلاثية الأبعاد تفاعلية ذاتية الانحدار باستخدام وضعية الكاميرا كتمثيل هندسي موحد
كشف أسرار الاستدلال المرئي
Kinema4D: النمذجة الحركية للعالم رباعي الأبعاد لمحاكاة الجسد المدمجة في الزمان والمكان
نموذج Qianfan-OCR الموحد من طرف إلى طرف لذكاء المستندات
إنكودر-32بي: نموذج أساسي للبرمجة مخصص للسيناريوهات الصناعية
ميرو ثينكر-1.7 و H1: نحو وكلاء بحثية ذات قدرات ثقيلة عبر التحقق
HSImul3R: إعادة بناء تفاعلات الإنسان-المشهد الجاهزة للمحاكاة مع دمج الفيزياء في الحلقة
PrismAudio: سلاسل تفكير مُفكَّكة ومكافآت متعددة الأبعاد لتوليد الصوت من الفيديو
LeWorldModel: هندسة تنبؤية مدمجة مشتركة مستقرة من البداية إلى النهاية من البكسلات
لا يمكنني الرد باللغة العربية لأنك طلبت مني أن أكون مترجمًا محترفًا للغة العربية، ولكنك طلبت مني أيضًا ترجمة النص إلى اللغة الصينية مع الحفاظ على المصطلحات التقنية باللغة الإنجليزية. يرجى توضيح لغتك المطلوبة للرد.
LumosX: ربط أي هويات بخصائصها من أجل توليد فيديو مخصص
مُركِّب Y لـ LLMs: حلّ تعفُّن السياق الطويل باستخدام λ-Calculus
ProactiveBench: تقييم الاستباقية في نماذج اللغة الكبيرة متعددة الوسائط
تيراسكوب: الاستدلال البصري المتمحور حول البكسل لرصد الأرض
أستrolabe: توجيه التعلم المعزز للعملية الأمامية لنماذج الفيديو التوليدية الذاتية المعززة عن طريق التمييز
HopChain: توليف البيانات متعدد القفزات للاستدلال البصري-اللغوي القابل للتعميم
ربط الشروط الدلالية والحركية باستخدام مُجزِّئ رموز الحركة المتقطع القائم على Diffusion
أسرع: إعادة التفكير في نماذج اللغة البصرية-الحركية (VLAs) ذات التدفق في الوقت الفعلي
نموذج 3DreamBooth: نموذج توليد فيديو ثلاثي الأبعاد عالي الدقة مدفوع بالموضوع
SAMA: ترسيخ دلالي مُفكَّك ومحاذاة حركة لتحرير الفيديو الموجه بالأوامر
نماذج التوليد تدرك الفضاء: استغلال المسبقات الضمنية ثلاثية الأبعاد لفهم المشهد
الكفاءة في الاستدلال مع التفكير المتوازن
انظر قبل التصرف: تعزيز تمثيلات الأساس البصري لنماذج الرؤية واللغة والإجراء
التعزيز التكميلي
التوافق يجعل نماذج اللغة معيارية، وليست وصفية.
MosaicMem: ذاكرة مكانية هجينة لنماذج العالم الفيديوية القابلة للتحكم
MetaClaw: مجرد حديث — وكيل يتعلّم ما وراء التعلم ويتطوّر في البرية
Video-CoE: تعزيز التنبؤ بالأحداث المرئية عبر سلسلة من الأحداث (Chain of Events)
FunCineForge: مجموعة أدوات بيانات ونموذج موحد للدبلجة السينمائية بنمط Zero-Shot في مشاهد سينمائية متنوعة
العلامات المائية داخل السياق (In-Context Watermarks) للنماذج اللغوية الكبيرة (Large Language Models)
WorldCam: عوالم ألعاب ثلاثية الأبعاد تفاعلية ذاتية الانحدار باستخدام وضعية الكاميرا كتمثيل هندسي موحد
كشف أسرار الاستدلال المرئي
Kinema4D: النمذجة الحركية للعالم رباعي الأبعاد لمحاكاة الجسد المدمجة في الزمان والمكان
نموذج Qianfan-OCR الموحد من طرف إلى طرف لذكاء المستندات
إنكودر-32بي: نموذج أساسي للبرمجة مخصص للسيناريوهات الصناعية
ميرو ثينكر-1.7 و H1: نحو وكلاء بحثية ذات قدرات ثقيلة عبر التحقق
HSImul3R: إعادة بناء تفاعلات الإنسان-المشهد الجاهزة للمحاكاة مع دمج الفيزياء في الحلقة