Command Palette
Search for a command to run...
فرض التمثيل لنماذج موحّدة متعددة الوسائط خالية من عنق الزجاجة
فرض التمثيل لنماذج موحّدة متعددة الوسائط خالية من عنق الزجاجة
الملخص
تهدف النماذج المتعددة الوسائط الموحدة (UMMs) إلى معالجة مهام الإدراك والتوليد في نموذج واحد. ومع ذلك، لا تزال النماذج الموحدة الحالية تعتمد على شفرة متغيرية تلقائية (VAE) مجمدة ومُدرَّبة مسبقاً بشكل منفصل لتوليد الصور، مما يفرض عنق زجاجة هيكلي. يؤدي الإزالة البسيطة لها إلى إحداث فجوة في الجودة، حيث يتعين على النموذج تعلم كل من البنية عالية المستوى والتفاصيل منخفضة المستوى من البكسلات الخام. في هذه الورقة، نقترح تقنية فرض التمثيل (RF)، وهي أسلوب يغلق هذه الفجوة من خلال جعل التنبؤ بالتمثيل قدرة مدمجة في النموذج. وتحديداً، تجبر تقنية RF فك الترميز على التنبؤ بشكل ذاتي تسلسلي بالتمثيلات البصرية كـ tokens وسيطة قبل البكسلات؛ ثم تبقى هذه tokens في السياق لتوجيه انتشار البكسل داخل نفس الهيكل الأساسي. ومن خلال تحويل التمثيلات من مخرجات الإدراك إلى أهداف للتوليد، تلغي تقنية RF الحاجة إلى أي فضاء كامن توليدي خارجي. ونجد أن تقنية RF تفيد كل من الفهم والتوليد. وفي مجال توليد الصور، يتساوى نموذجنا في فضاء البكسل المزود بـ RF مع أحدث النماذج الموحدة القائمة على VAE. وفي مجال فهم الصور، يتفوق بشكل عام RF في فضاء البكسل على نسخته القائمة على VAE. ومعاً، تقدم هذه النتائج خطوة فعالة نحو نماذج متعددة الوسائط موحدة (UMMs) تعمل من البداية إلى النهاية وخالية من عنق الزجاجة.
One-sentence Summary
Representation Forcing eliminates structural bottlenecks in unified multimodal models by autoregressively predicting visual representations as intermediate tokens to guide pixel diffusion within a single backbone, yielding a pixel-space architecture that matches state-of-the-art VAE-based unified models in generation while generally outperforming them in image understanding.
Key Contributions
- This work introduces Representation Forcing, a technique that eliminates reliance on frozen external variational autoencoders by training the decoder to autoregressively predict visual representations as intermediate tokens. These tokens remain in the sequence to provide structural guidance for pixel-space diffusion within a shared transformer backbone.
- Controlled experiments demonstrate that the pixel-space model matches state-of-the-art VAE-based unified models on standard text-to-image generation benchmarks while preserving fine textures. The approach also outperforms its VAE-based counterpart on image understanding tasks, indicating superior compatibility with joint multimodal modeling.
- By repurposing perception outputs as generation targets, the method establishes a single end-to-end representation space that learns both high-level structure and low-level details directly from raw pixels. This design advances fully unified multimodal modeling by enabling native capabilities without relying on independently pretrained latent spaces.
Introduction
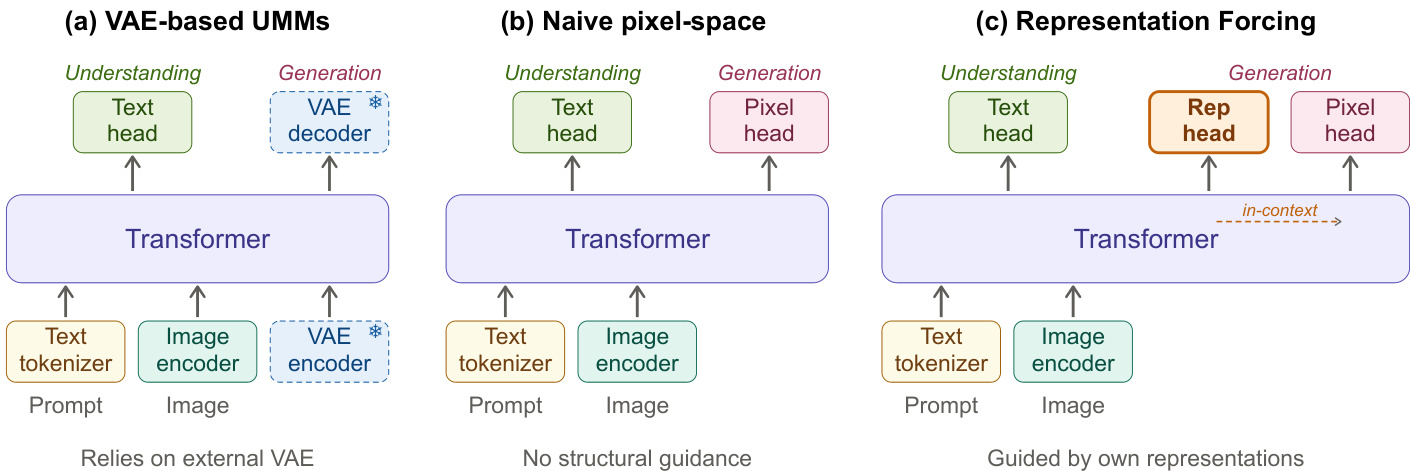
Unified multimodal models aim to handle both visual perception and image synthesis within a single architecture, a foundational requirement for building general-purpose multimodal intelligence. Prior systems, however, depend on a frozen, separately pretrained VAE to compress images into latents before applying diffusion, which creates a structural bottleneck that caps generation quality and breaks end-to-end training. Removing this external component forces the network to simultaneously learn high-level semantics and low-level textures from raw pixels, causing a severe quality drop. The authors leverage Representation Forcing to solve this by training the decoder to autoregressively predict visual representations as intermediate tokens. These tokens stay in the attention context to guide pixel-space diffusion, successfully eliminating the VAE dependency while boosting both generation fidelity and multimodal understanding.
Method
The authors leverage a unified multimodal model architecture designed to enable end-to-end training of pixel-space generation without reliance on external latent spaces. The core framework, referred to as Representation Forcing, operates within a shared transformer backbone that processes a unified sequence of text tokens, representation tokens, and pixel patches. This sequence is structured to support both understanding and generation tasks, with the model jointly trained to predict text, generate visual representations, and render images. The architecture is built upon the Mixture-of-Transformers (MoT) design, where all tokens share the same self-attention layers but are routed to modality-specific feed-forward experts based on their type. These experts are dedicated to multimodal understanding, representation token prediction, and pixel generation, allowing the model to specialize its processing while maintaining a common attention mechanism.
The framework integrates an image encoder, specifically DINOv3 ViT-H+/16 with NaViT-style variable-resolution support, which is jointly trained with the rest of the model. During training, the encoder extracts continuous visual features from the input image, which are then discretized into a sequence of representation tokens via online vector quantization. This process uses an exponential moving average (EMA) copy of the encoder to stabilize the feature representations, ensuring that the codebook updates adapt gradually to evolving features. The codebook consists of K=16,384 learnable prototype embeddings, and each patch-level feature is assigned to the nearest prototype based on cosine similarity. This discretization produces a sequence of representation tokens that mirror the spatial layout of the image and are embedded with learnable 2D spatial and identity embeddings. The resulting representation tokens are integrated into the sequence as in-context conditioning for pixel-space generation.
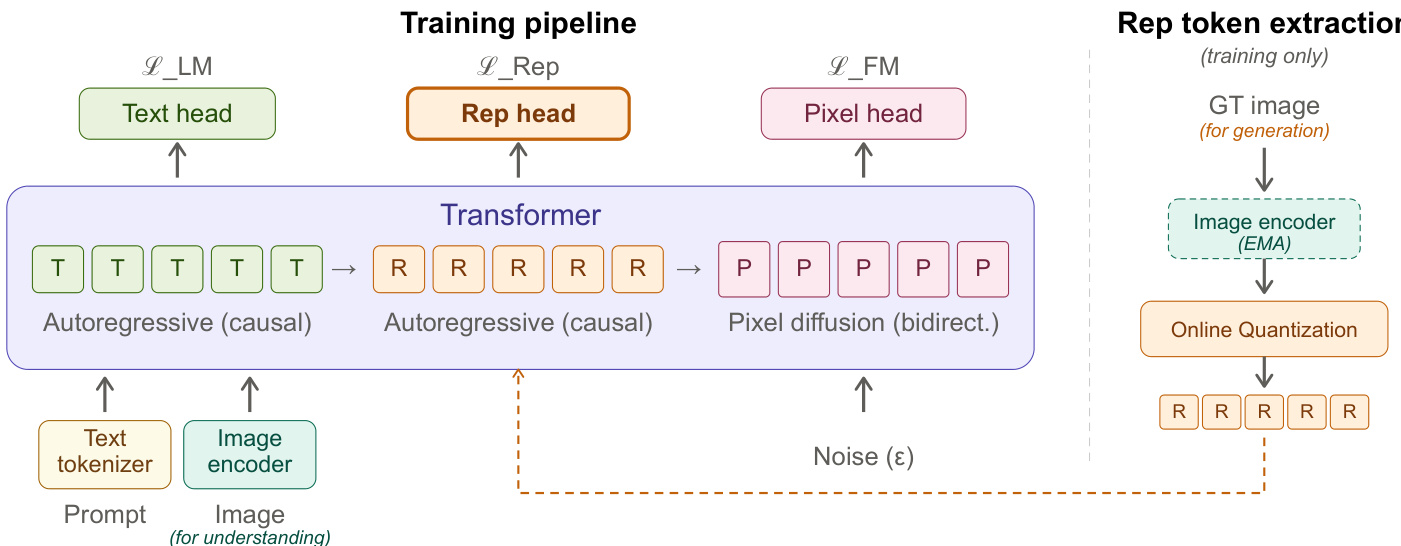
The model is trained end-to-end with a combined objective that includes three components: a language modeling loss LLM for text prediction, a representation prediction loss LRep for predicting the discretized visual representations, and a flow-matching loss LFM for pixel generation. The flow-matching loss is formulated using x-prediction with velocity loss, where the decoder predicts the clean image patches from noisy inputs at time t, given by zt=tx+(1−t)ϵ. The loss is defined as LFM=E∥vθ−v∥2, with v=x−ϵ and vθ=(xθ−zt)/(1−t). During training, the representation tokens are provided as ground-truth targets, while at inference, the decoder generates them autoregressively from the text prompt alone. These predicted representation tokens remain in the sequence and act as in-context conditioning for the pixel-space diffusion process. The attention mechanism ensures that the high-level structure encoded in the representation tokens influences pixel generation through standard self-attention, without requiring additional cross-attention modules. The training pipeline supports classifier-free guidance by independently dropping the text conditioning and representation token sequence with a probability of 0.1 during training.
Experiment
The evaluation compares a novel pixel-space model enhanced with Representation Forcing against established VAE-based and unified multimodal architectures across standard text-to-image and visual understanding benchmarks. Generation tests demonstrate that this approach successfully bridges the quality gap between pixel-space and VAE-based methods, achieving competitive performance in compositional generation and dense prompt following. Understanding evaluations reveal that Representation Forcing consistently boosts high-level visual comprehension, with the pixel-space variant ultimately outperforming VAE-based counterparts by eliminating latent bottlenecks and enabling tighter alignment between multimodal representations. Collectively, these results validate the effectiveness of end-to-end pixel-space unified models in delivering both strong generative quality and robust visual understanding.
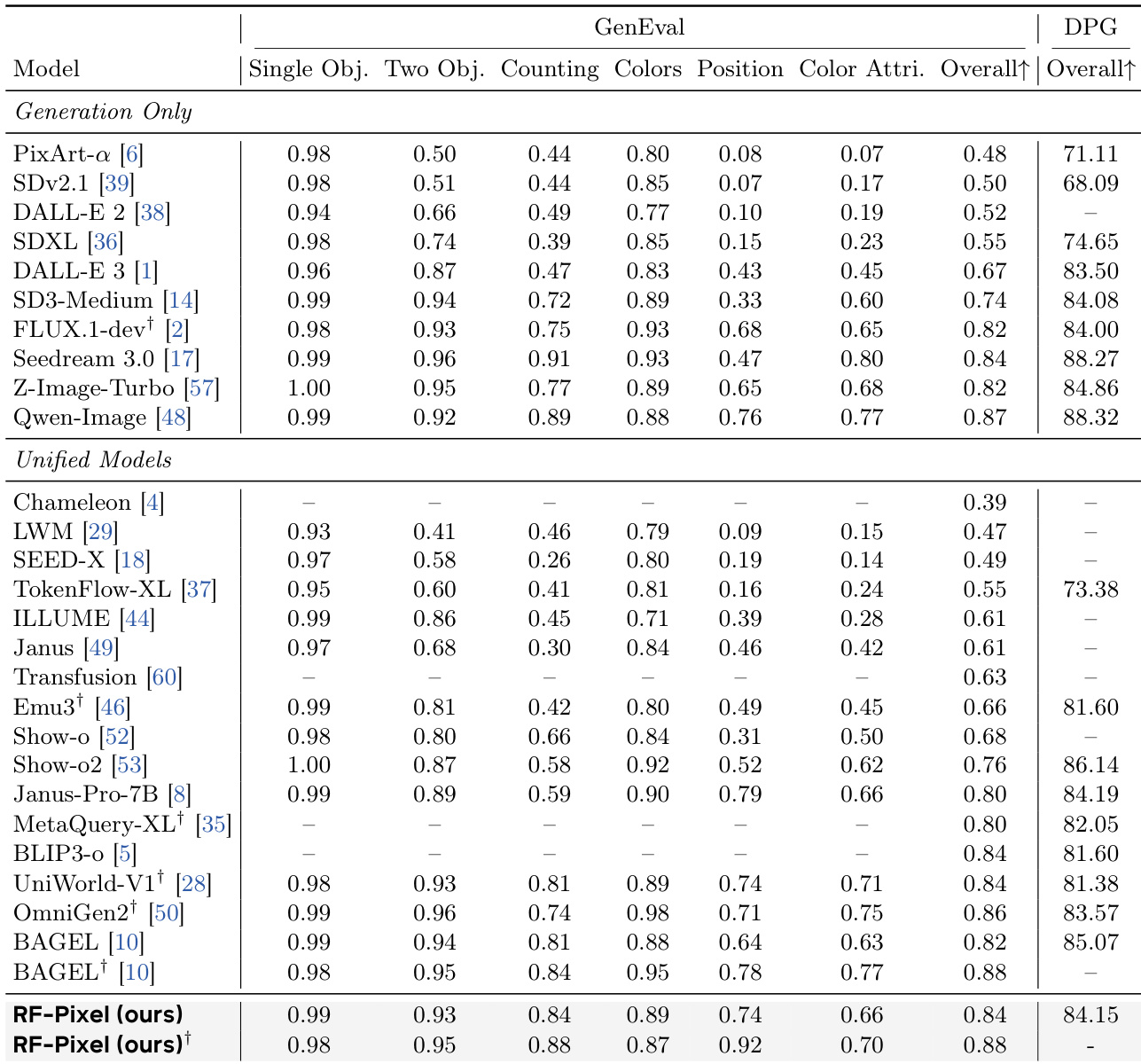
The authors evaluate a pixel-space model on text-to-image benchmarks, comparing its performance against existing models that rely on pretrained generative components. Results show that the model achieves competitive generation quality and improves understanding across multiple benchmarks, with greater gains observed in pixel-space settings compared to VAE-based approaches. Representation Forcing improves both generation and understanding performance across different model architectures. Pixel-space models with Representation Forcing outperform VAE-based models on most visual understanding benchmarks. Representation Forcing leads to significant improvements in high-level visual understanding tasks but shows minor reductions in document-oriented comprehension.

The authors evaluate their pixel-space model on text-to-image benchmarks and compare its performance with existing models. Results show that the model achieves competitive scores on GenEval, with improvements when using a language model rewriter, and demonstrates strong performance on image understanding tasks, particularly in general visual understanding, where it outperforms VAE-based approaches. The model achieves comparable or better performance than state-of-the-art unified models on compositional generation tasks. Representation Forcing improves understanding across multiple benchmarks, especially in general visual understanding. Pixel-space generation with Representation Forcing outperforms VAE-based generation on most evaluation tasks, indicating benefits from a unified representation space.

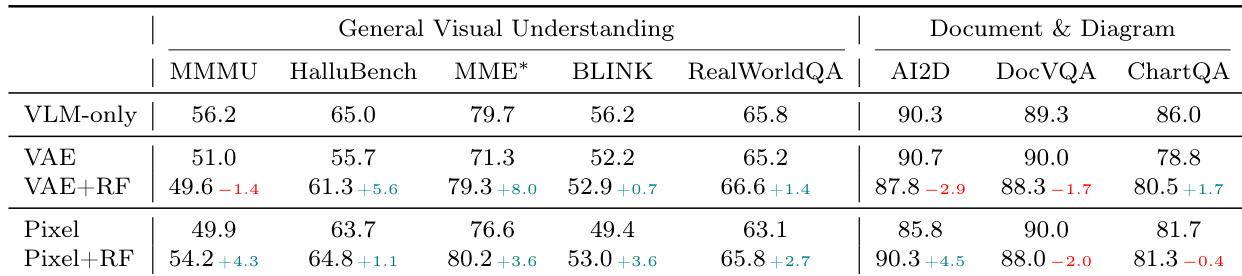
The authors evaluate the impact of Representation Forcing (RF) on image understanding performance across different generation pathways, comparing VAE-based and pixel-space models with and without RF. Results show that RF improves understanding in both settings, with greater gains on general visual understanding tasks and consistent improvements in pixel-space models over VAE-based ones. The authors attribute the superior performance of pixel-space models to tighter alignment between understanding and generation due to the absence of an external VAE latent space. RF improves understanding performance across both VAE-based and pixel-space generation pathways, with larger gains on general visual understanding tasks. Pixel-space models with RF outperform VAE-based models on most benchmarks, indicating better alignment between understanding and generation. Improvements are concentrated on tasks requiring high-level visual comprehension, while performance on document-oriented tasks shows only minor reductions.

The authors evaluate their pixel-space model, RF-Pixel, on text-to-image benchmarks and compare it to existing generation-only and unified multimodal models. Results show that RF-Pixel achieves competitive performance on compositional generation and dense prompt following, matching or exceeding state-of-the-art models without relying on separately pretrained generative components. The model also demonstrates strong understanding capabilities across various visual tasks, particularly benefiting from representation forcing in pixel-space generation. RF-Pixel achieves competitive performance on compositional generation and dense prompt following, matching state-of-the-art unified models without using pretrained generative modules. Representation Forcing consistently improves understanding across benchmarks, with larger gains observed in pixel-space generation compared to VAE-based generation. Pixel-space generation with Representation Forcing outperforms VAE-based generation on most benchmarks, especially in general visual understanding tasks.
The authors evaluate a pixel-space model with Representation Forcing (RF) on image generation and understanding tasks, comparing it against VAE-based and pixel-space models with and without RF. Results show that RF improves understanding performance across both pathways, with greater gains in pixel-space models, particularly on general visual understanding benchmarks, while slightly reducing performance on document-oriented tasks. The pixel-space model with RF outperforms the VAE-based model with RF on most benchmarks, indicating tighter integration between understanding and generation in a unified representation space. RF improves understanding performance on both VAE-based and pixel-space models, with larger gains on general visual understanding benchmarks. Pixel-space models with RF outperform VAE-based models with RF on six out of eight benchmarks, especially in general visual understanding. RF leads to slight reductions in performance on document and diagram understanding tasks, suggesting limitations in text and layout comprehension.
The experiments evaluate a pixel-space model enhanced with Representation Forcing on text-to-image generation and visual understanding benchmarks, validating its performance against VAE-based architectures and pretrained unified models. Results demonstrate that Representation Forcing consistently improves visual comprehension across both generation pathways, with pixel-space implementations yielding superior understanding due to tighter alignment between generation and representation. While the model achieves competitive generation quality without relying on pretrained components, it shows minor trade-offs in document-oriented and layout comprehension tasks. Overall, the findings confirm that unifying generation and understanding within a single pixel-space representation effectively bridges visual reasoning and compositional capabilities.