Command Palette
Search for a command to run...
Draft-OPD: التقطير على السياسة لنماذج المسودة التخمينية
Draft-OPD: التقطير على السياسة لنماذج المسودة التخمينية
الملخص
يُسرّع فك التشفير التخميني عملية استدلال نماذج اللغة الكبيرة من خلال اقتران نموذج هدف بنموذج مسودة خفيف الوزن، حيث تُتحقق من الـ tokens المقترحة بالتوازي. تُعد الضبط الدقيق الخاضع للإشراف (SFT) على المسارات المولدة من قبل النموذج الهدف أسلوباً شائعاً لبناء نماذج المسودة، كـ EAGLE3 أو DFlash. ومع ذلك، نلاحظ أن الضبط الدقيق الخاضع للإشراف (SFT) يستقر بسرعة؛ إذ يتوقف طول القبول لنموذج المسودة على بيانات الاختبار عن التحسن. ويعود السبب إلى عدم التطابق بين التدريب غير المتصل والاستدلال؛ ففي الضبط الدقيق الخاضع للإشراف (SFT)، يتعلم المسود من مسارات ثابتة مولدة من قبل النموذج الهدف، بينما أثناء فك التشفير التخميني يتم تقييمه على كتل مقترحة وفقاً لسياسته الخاصة. ويبرر هذا اعتماد التقطير على السياسة (OPD)، حيث يشرف نموذج الهدف على المسود في الحالات المستحثة بالمسودة. ومع ذلك، يظل التقطير على السياسة (OPD) أمراً صعباً لنماذج المسودة، إذ لا يمكنها تمديد تسلسلات كاملة بشكل موثوق بشكل مستقل، في حين يجعل التوليد بمساعدة الهدف التسلسلات المُجمَّعة تتبع توزيع النموذج الهدف، مما يلغي إشارة السياسة على التوالي. وعليه، نقترح منهج Draft-OPD، الذي يستخدم التمديد بمساعدة الهدف لضمان استمرارية مستقرة، ويعيد محاكاة عملية المسودة بدءاً من مواضع الأخطاء التي كشفها التحقق. ويتيح ذلك للمسود التعلم من ملاحظات النموذج الهدف بشأن كل من المقترحات المقبولة والمرفوضة، مع التركيز على التدريب على الأخطاء المستحثة بالمسودة التي تحد من القبول التخميني. وتُظهر التجارب أن Draft-OPD يحقق تسريعاً خالياً من فقدان الدقة يتجاوز 5imes لنماذج التفكير عبر مهام متنوعة، متفوقاً على EAGLE-3 و DFlash بنسبة 23% و 13%.
One-sentence Summary
The authors propose Draft-OPD, an on-policy distillation method for speculative draft models that resolves the offline-to-inference mismatch of supervised fine-tuning by combining target-assisted rollouts with replaying drafts at verification-exposed error positions to train drafters on target feedback for both accepted and rejected proposals.
Key Contributions
- The proposed Draft-OPD framework transitions draft model optimization from offline supervised fine-tuning to on-policy distillation, resolving the offline-to-inference mismatch that limits speculative decoding efficiency.
- The method integrates a target-assisted rollout strategy with error-position replay to generate stable continuations while preserving the necessary on-policy training signal.
- By focusing optimization on verification-exposed error positions, the approach enables draft models to learn from both accepted and rejected proposals, effectively breaking the acceptance length plateau observed in prior methods.
Introduction
Speculative decoding accelerates autoregressive language model inference by having a lightweight draft model propose multiple tokens that a larger target model verifies in parallel, preserving output quality while significantly reducing latency. Recent advances enhance this pipeline by extracting features from frozen target models or designing stronger draft architectures, yet they all depend on offline supervised fine-tuning using target-generated trajectories. This static training paradigm ultimately caps draft model acceptance rates and restricts further efficiency gains. To overcome this bottleneck, the authors introduce an on-policy distillation framework that trains draft models directly on the inference policy, enabling substantially longer accepted sequences and pushing speculative decoding beyond traditional offline training limits.
Method
The authors propose Draft-OPD, an on-policy distillation framework tailored for training-based draft models in speculative decoding. The core challenge addressed is the offline-to-inference mismatch: standard supervised fine-tuning (SFT) trains the draft model on fixed trajectories generated by the target model, while speculative decoding evaluates the draft model on sequences it generates itself. This mismatch causes SFT to plateau, as the model learns from states it does not encounter during actual inference. On-policy distillation (OPD) aims to close this gap by training the draft model on states induced by its own policy. However, direct application of OPD to draft models is problematic. As shown in the framework diagram, forcing a draft model to self-rollout full sequences (a) leads to unreliable, repetitive outputs. Alternatively, using target-assisted rollouts (b) produces stable, high-quality continuations but discards the draft model's rejected proposals, which are the most informative for learning where the draft model fails. This breaks the on-policy signal. 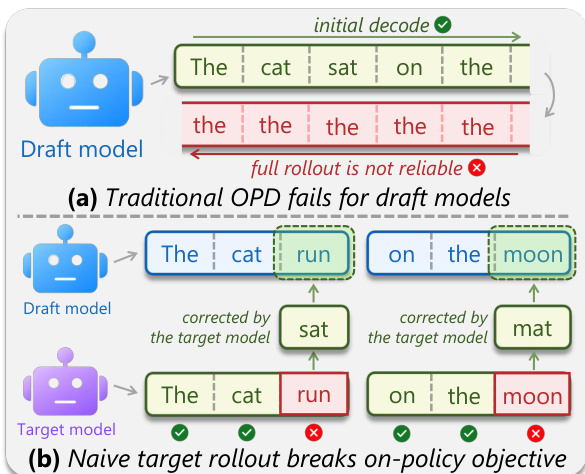
To overcome these limitations, Draft-OPD employs a three-stage process. First, it uses speculative decoding to collect a stable, high-quality rollout from the target model. During this rollout, it records the starting position of each draft block proposed by the draft model as an anchor. This ensures the collected sequence is reliable, while preserving the exact state where the draft model made its proposal. As illustrated in the figure below, the draft model proposes a block, which is verified by the target model. The starting index of each block is saved as an anchor. The process continues until the sequence ends. 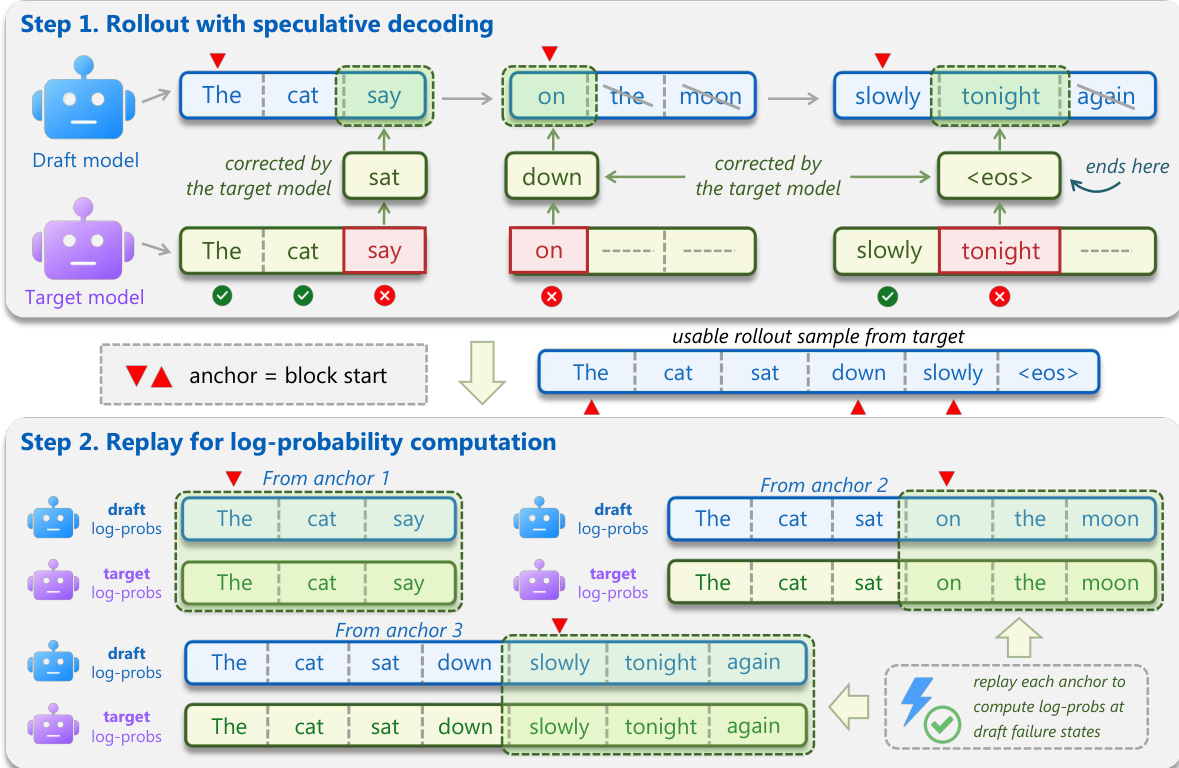 Second, the framework replays the drafting process from each anchor. For each anchor, the draft model's proposed block is re-generated, and the log-probabilities of the tokens are computed using both the draft model and the target model on the same prefix. This allows the target model to provide feedback on the draft model's proposals, including the rejected tokens that were discarded during the initial verification. The verification outcome partitions the drafted tokens into accepted and rejected sets, enabling the model to learn from both successful and failed predictions. Third, Draft-OPD employs an acceptance-aware distillation objective. For accepted tokens, it uses forward KL divergence to encourage the draft model's distribution to cover the target model's distribution, reinforcing reliable agreement. For rejected tokens, it uses reverse KL divergence to penalize the draft model's high-probability predictions where the target model disagrees, focusing learning on the errors that limit acceptance length. To prioritize early errors, rejected tokens are weighted exponentially by their position within the draft block. The final objective is a weighted average of the accepted and rejected loss components, enabling the draft model to learn from both stable, high-quality rollouts and the critical failure points exposed by speculative verification.
Second, the framework replays the drafting process from each anchor. For each anchor, the draft model's proposed block is re-generated, and the log-probabilities of the tokens are computed using both the draft model and the target model on the same prefix. This allows the target model to provide feedback on the draft model's proposals, including the rejected tokens that were discarded during the initial verification. The verification outcome partitions the drafted tokens into accepted and rejected sets, enabling the model to learn from both successful and failed predictions. Third, Draft-OPD employs an acceptance-aware distillation objective. For accepted tokens, it uses forward KL divergence to encourage the draft model's distribution to cover the target model's distribution, reinforcing reliable agreement. For rejected tokens, it uses reverse KL divergence to penalize the draft model's high-probability predictions where the target model disagrees, focusing learning on the errors that limit acceptance length. To prioritize early errors, rejected tokens are weighted exponentially by their position within the draft block. The final objective is a weighted average of the accepted and rejected loss components, enabling the draft model to learn from both stable, high-quality rollouts and the critical failure points exposed by speculative verification.
Experiment
The evaluation setup tests Draft-OPD against established baselines across mathematical, coding, and general reasoning benchmarks under matched computational budgets, alongside deployment efficiency tests on optimized inference engines. Main results demonstrate consistent improvements in decoding speed and token acceptance, while ablation studies validate that these gains stem from on-policy distillation targeting verification-time errors rather than simple supervised data augmentation. Analysis experiments further confirm that preserving draft-induced mistakes during training is essential, and they identify a performance gap in highly uncertain thinking-mode scenarios. Collectively, these findings establish Draft-OPD as a robust, efficiency-focused post-training framework that strengthens draft-target alignment and accelerates speculative decoding without altering the target model's output distribution.
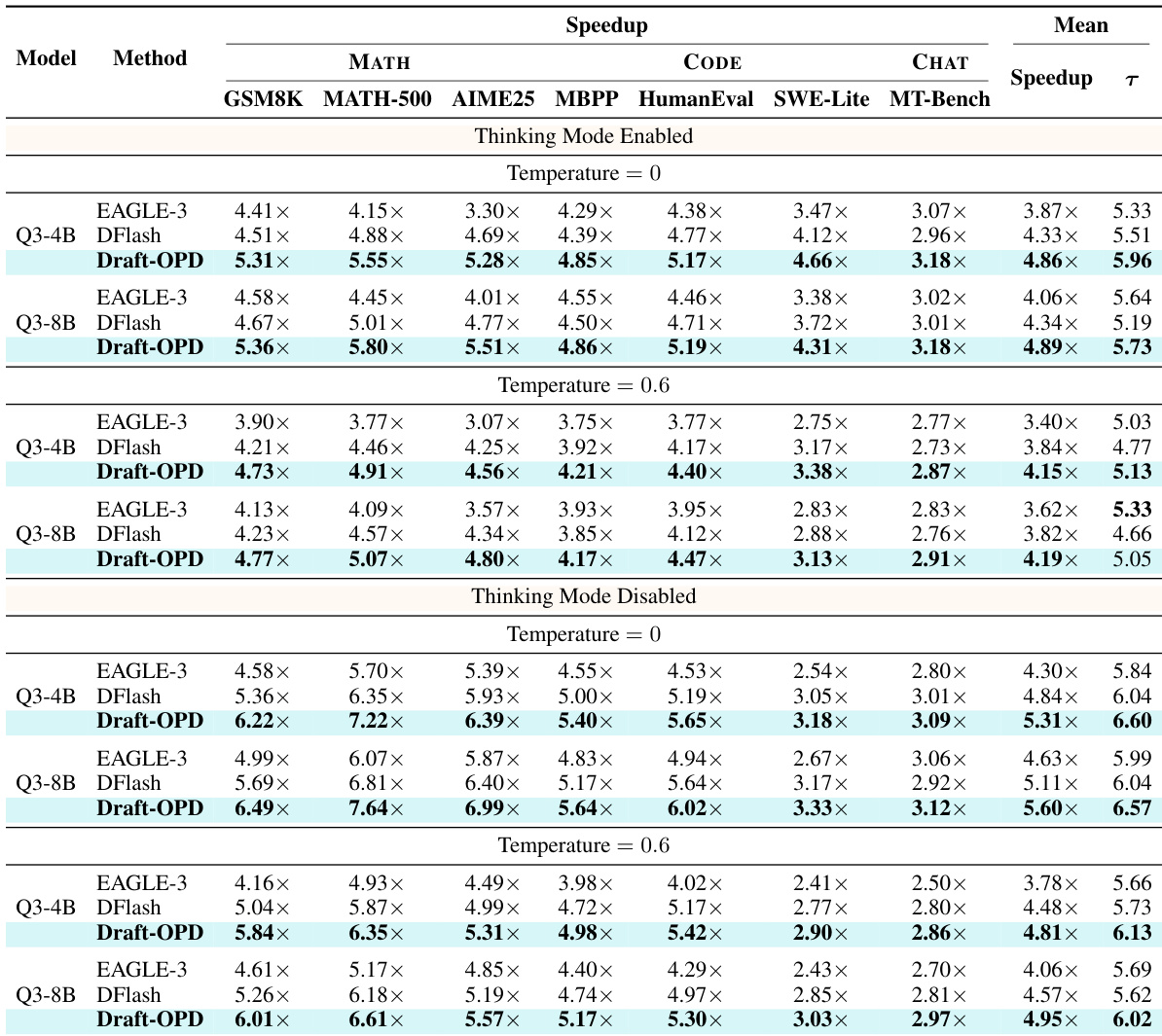
The authors compare Draft-OPD with EAGLE-3 and DFlash on Qwen3 models, evaluating decoding speedup and average acceptance length across different tasks and settings. Results show that Draft-OPD consistently improves performance over baselines, particularly in terms of speedup and acceptance length, both with and without thinking mode enabled, and maintains these gains under varying temperatures and in a deployed inference environment. Draft-OPD achieves higher decoding speedup and acceptance length than EAGLE-3 and DFlash across all tested models and tasks. The method maintains its advantage under different decoding temperatures and with thinking mode enabled or disabled. Performance improvements translate to practical gains in serving throughput, with consistent benefits observed across concurrency levels.
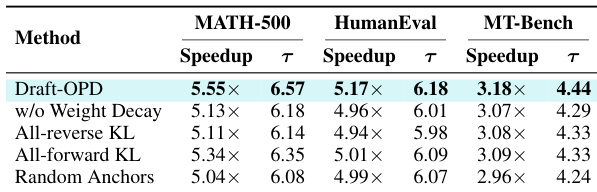
The authors compare Draft-OPD with a naive rollout baseline on Qwen3-4B, focusing on decoding efficiency metrics. Results show that Draft-OPD achieves higher speedup and acceptance length across multiple benchmarks compared to the naive approach, indicating improved draft-target alignment. The performance difference is consistent across tasks, demonstrating the effectiveness of the proposed method. Draft-OPD achieves higher speedup and acceptance length than the naive rollout baseline across all evaluated benchmarks. The improvement in acceptance length and speedup is consistent across different tasks, indicating robust performance. The results demonstrate that the proposed method effectively enhances draft-target alignment compared to a basic rollout approach.

{"summary": "The authors evaluate Draft-OPD against baseline methods on Qwen3 models across multiple benchmarks, focusing on decoding efficiency metrics such as speedup and average acceptance length. Results show that Draft-OPD consistently improves both metrics compared to alternatives, with performance gains observed under both thinking and non-thinking modes, and these improvements are robust across different model sizes and tasks.", "highlights": ["Draft-OPD achieves higher decoding speedup and acceptance length compared to baseline methods across all evaluated benchmarks and model sizes.", "The method maintains its advantage under both thinking and non-thinking modes, indicating effective draft-target alignment for different generation styles.", "Performance gains are consistent across mathematical, code generation, and out-of-domain benchmarks, demonstrating broad applicability."]
The authors compare Draft-OPD with EAGLE-3 and DFlash on Qwen3 models under a matched training FLOPs budget, focusing on decoding speedup and average acceptance length. Results show that Draft-OPD consistently improves acceptance length and decoding speed across different models, tasks, and decoding modes, with the improvements being more pronounced in non-thinking mode and under higher concurrency in SGLang deployment. Draft-OPD maintains its advantage over baselines by effectively aligning the draft model with the target model through on-policy training that emphasizes verification-time errors. Draft-OPD consistently improves decoding speed and acceptance length across all evaluated models and tasks compared to EAGLE-3 and DFlash. Draft-OPD achieves higher speedup and acceptance length in non-thinking mode than in thinking mode, indicating better alignment with the target model's behavior. The method maintains its performance gains under higher concurrency levels in SGLang, showing practical deployment benefits.
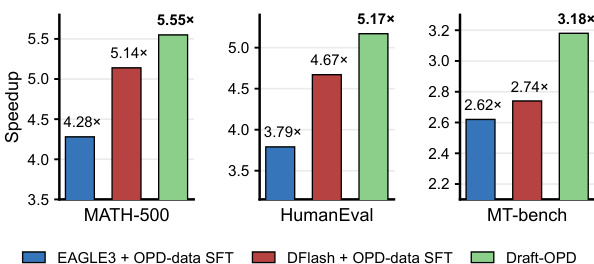
The authors evaluate the performance of Draft-OPD against baselines on Qwen3 models under different tasks and concurrency levels, focusing on decoding speedup and average acceptance length. Results show that Draft-OPD consistently improves acceptance length and speedup across all tested configurations, with higher gains observed under thinking mode and at increased concurrency. The method maintains its advantage regardless of decoding temperature and model size, demonstrating robust draft-target alignment. Draft-OPD consistently improves acceptance length and decoding speed across all tested models and tasks, outperforming baselines under matched training budgets. The method achieves higher speedup and acceptance length under thinking mode compared to non-thinking mode, with gains increasing at higher concurrency levels. Draft-OPD maintains its advantage across different decoding temperatures and model sizes, indicating robustness in draft-target alignment for both reasoning and non-reasoning generations.
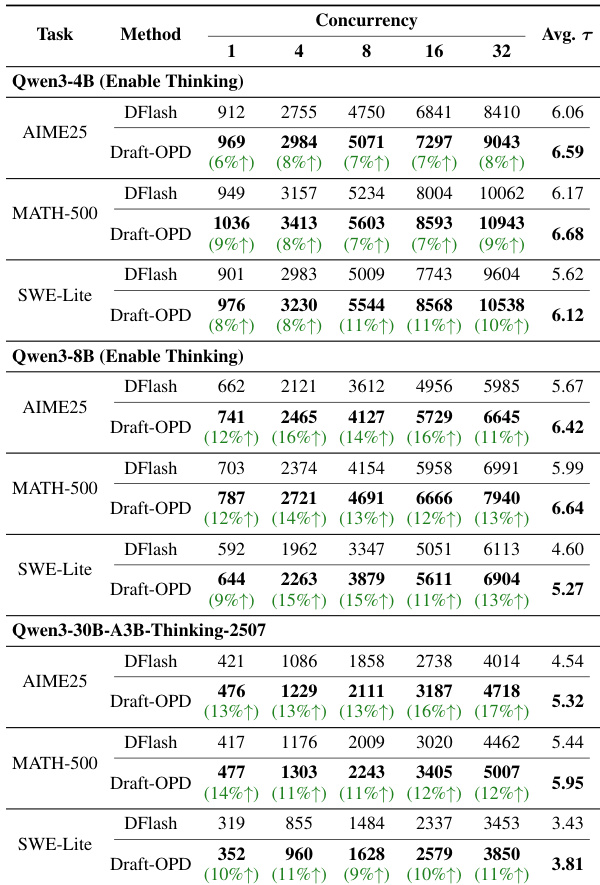
The authors evaluate Draft-OPD against multiple baselines on Qwen3 models across diverse tasks, model scales, and deployment conditions to validate its capacity for robust draft-target alignment. Experiments consistently demonstrate that the method yields superior decoding efficiency and token acceptance rates compared to alternatives, with performance remaining stable across varying temperatures, concurrency levels, and reasoning configurations. Gains are particularly pronounced under high load and in non-thinking modes, confirming the approach's practical viability for real-world inference serving. Ultimately, the results establish Draft-OPD as a broadly applicable solution that reliably accelerates generation while maintaining alignment with target models.